







 SSD网络backbone由VGG16网络的全部卷积层,即到conv5为止,去掉之后的全连接层。如下图:
SSD网络backbone由VGG16网络的全部卷积层,即到conv5为止,去掉之后的全连接层。如下图:

然后是
conv6:3x3x1024;
conv7:1x1x1024;
conv8:1x1x256,stride=1,3x3x512,stride=2,padding=1;
conv9:1x1x128,stride=1,3x3x256,stride=2,padding=1;
conv10:1x1x128,stride=1,3x3x256,stride=1,padding=0;
conv11:1x1x128,stride=1,3x3x256,stride=1,padding=0;
其中conv4,7,8,9,10,11作为多尺度特征图,再分别进行3x3xp的卷积提取检测结果。
其中p=( ratio数量x ( 类别数(21)+预测框参数个数(4) ) )
ratio数量 conv7,8,9 为6个,其他为4个,具体原因在稍后讲到。
default box
对于之前的每一个特征图,特征图上的每一个像素点cell都会生成一系列default box,每一个default box按特征图和原图的比例映射到原图,就能获得不同大小的框,来识别不同大小的目标。
每个feature map 的大小分别为
38x38、19x19、10x10、5x5、3x3、1x1
每个特征层经过卷积之后,在channel方向,就有每个小像素点对应ratio组defaultbox的信息,每一组包括21个类别概率,4个预测框回归参数。
defaultbox大小的选取
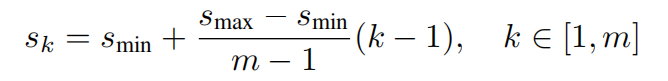
Sk可以简单理解为default box面积 与 原图的比例,Smax原文取0.9,Smin原文取0.2,m是特征图的数量,backbone里的conv4不算,所以m=5,k是第k个特征图。k=1时,取Sk=0.1。
所以default box的大小(面积开根号)为
300 * 0.1,300*0.2,*300[0.2+(0.7/4)*(2-1)],等等
即
30,60,111,162,213,264
实际上很多复现,并没有按这个来~
大小确定,确定ratio,即default box的形状
conv7,8,9 有 6种形状
1:1 、1:1(大小为Sk’)、1:2、2:1、1:3、3:1
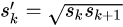
conv4,conv10,conv11有4种形状
1:1 、1:1(大小为Sk’)、1:2、2:1、
也就是之前3x3xp卷积的p中的不同
default box中心点的定义
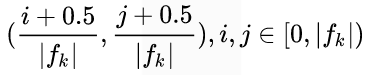
fk为特征图的长度,其实中心点就定义在每个像素点的中间
正负样本的选取
正样本:
首先ground truth匹配每个和它iou最大的boundingbox,将这些boundingbox选为正样本。
bounding box与某个ground truth的IOU大于某个阈值(0.5)设为正样本。
负样本:
其他都为负样本
由于负样本太多,所以会对负样本进行排序,取负样本中概率为背景较大的一些,保持 负样本:正样本 接近 3:1。
损失函数
损失函数定义为位置误差(loc)与置信度误差(conf)的加权和
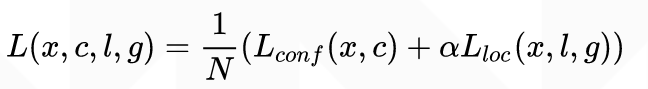
位置误差采用Smooth L1 loss

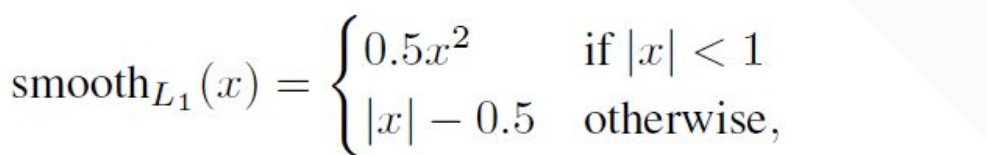
l为预测的位置参数,g为真实的位置参数,d为default box的位置参数,x,y是中心坐标,w,h是box的宽和高,xij=1,第i个预测box与第j个ground truth所匹配。
我个人认为学习的是default box 和 ground truth的偏移量,并且只关心位置,不关心类别。
置信度误差
采用softmax,0表示为背景的概率
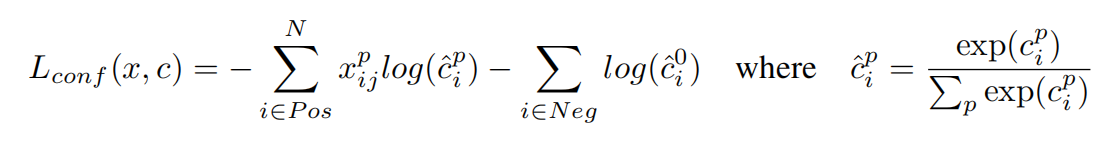
大概就是这样了,之后遇到什么问题再补充
2021.5.8
SSD300框架
import torch
import torch.nn as nn
from Basic_Net.VGG import VGG
class SSD (nn.Module):
def __init__(self,num_class=21):
super(SSD, self).__init__()
self.num_class = num_class
self.backbone = VGG()
# todo 把backbone的maxpool改为向上取整 ceil_mode = True
# 去掉最后一个maxpool
self.backbone_all = list(self.backbone.children())[0][0:-1]
# 去掉conv5 提取特征
self.backbone_conv4 = nn.Sequential(*list(self.backbone.children())[0][0:23])
print(list(self.backbone.children())[0][0:23])
self.backbone = nn.Sequential(*list(self.backbone_all))
#
self.conv_6_7 = nn.Sequential(
nn.Conv2d(512,1024,kernel_size=3,padding=1),
nn.BatchNorm2d(1024),
nn.ReLU(True),
nn.Conv2d(1024,1024,kernel_size=1),
nn.BatchNorm2d(1024),
nn.ReLU(True),
)
self.conv_8 = nn.Sequential(
nn.Conv2d(1024,256,kernel_size=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.Conv2d(256,512,kernel_size=3,stride=2,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
)
self.conv_9 = nn.Sequential(
nn.Conv2d(512,128,kernel_size=1,stride=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.Conv2d(128,256,kernel_size=3,stride=2,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
)
self.conv_10 = nn.Sequential(
nn.Conv2d(256,128,kernel_size=1,stride=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.Conv2d(128,256,kernel_size=3,stride=1,padding=0),
nn.BatchNorm2d(256),
nn.ReLU(True),
)
self.conv_11 = nn.Sequential(
nn.Conv2d(256,128,kernel_size=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.Conv2d(128,256,kernel_size=3,stride=1,padding=0),
# 1x1矩阵就不需要BN啦
nn.ReLU(True),
)
# 提取特征层
inchannel = [512,1024,512,256,256,256]
self.conv_featrue = []
for i,channel in enumerate(inchannel):
if i in[1,2,3]:
ratio = 6
else:
ratio = 4
print(ratio)
# 位置
conv_loc = nn.Sequential(
nn.Conv2d(channel, ratio * 4, kernel_size=3, stride=1,padding=1),
)
# 分类置信度
conv_cof = nn.Sequential(
nn.Conv2d(channel, ratio * num_class, kernel_size=3, stride=1,padding=1),
)
self.conv_featrue.append((conv_loc,conv_cof))
#self.conv_featrue = nn.ModuleList(self.conv_featrue)
def forward(self,x):
self.feature_extra = []
# 先把特征图1拿出来
feature_1 = self.backbone_conv4(x)
self.feature_extra.append(feature_1)
x = self.backbone(x)
x = self.conv_6_7(x)
self.feature_extra.append(x)
x = self.conv_8(x)
self.feature_extra.append(x)
x = self.conv_9(x)
self.feature_extra.append(x)
x = self.conv_10(x)
self.feature_extra.append(x)
x = self.conv_11(x)
self.feature_extra.append(x)
# batch,channel,w,h w*h 个点 每个点的channel方向是一组 不同形状的box的类别和位置偏移信息
self.loc,self.conf = self.get_feature(self.feature_extra)
# (batch,4,box_num)
return self.loc,self.conf
def get_feature(self,feature_list):
# nn.ModuleList 使list可以调用Module的方法
# self.feature_list = nn.ModuleList(feature_list)
locs = []
confs = []
self.feature_list = feature_list
for (x,conv) in zip(self.feature_list,self.conv_featrue):
# conv_feature : tuple(loc_conv2d,confi_conv2d)
conv_loc,conv_conf = conv
loc = conv_loc(x)
conf = conv_conf(x)
# (batch,ratio_num*4,w,h) => (batch,4,box_num)
loc = loc.reshape((loc.size(0),4,-1))
# => (batch, 21, box_num)
conf = conf.reshape((conf.size(0),self.num_class,-1))
locs.append(loc)
confs.append(conf)
# 所有的cat在一起,cat在哪个维度,哪个维度东西变多
loc = torch.cat(locs,2)
conf = torch.cat(confs,2)
return loc,conf















 6347
6347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









