







文章目录
这是参加datawhale的学习打卡活动的学习笔记
学习链接: http://joyfulpandas.datawhale.club/Content/%E5%8F%82%E8%80%83%E7%AD%94%E6%A1%88.html
文件读取与写入
文件读取
| 方法 | 作用 |
|---|---|
| read_csv | 读取csv |
| read_table | 读取txt |
| read_excel | 读取excel |
常用的公共参数
| 参数 | 描述 |
|---|---|
| header | 第一行是否作为列名,指定为None则不作为列名 |
| index_col | 指定列作为索引,输入列名或者列对应的索引 |
| usecols | 表示读取列的集合,输入列名或者列对应的索引 |
| parse_dates | 表示需要转化为时间的列,输入列名或者列对应的索引 |
| nrows | 表示读取的行数,输入列名或者列对应的索引 |
note:在读取txt文件时,常常需要使用sep参数指定文件的分隔符
文件写入
使用to_csv,to_excel写入数据,一般将index设为False
基本数据结构
Series
Series是单列数据结构,常用属性为:
| 属性 | 描述 |
|---|---|
| values | 值 |
| index | 索引 |
dtype |
数据类型 |
names |
名称 |
| shape | 表的行数 |
DataFrame
| 属性 | 描述 |
|---|---|
| values | 值 |
| index | 索引 |
columns |
列名 |
dtypes |
数据类型 |
| name | 名称 |
| shape | 表的行数 |
| T | 转置 |
常用函数
汇总函数
| 函数 | 描述 |
|---|---|
| head | 返回表格前几行,默认5行 |
| tail | 返回表格末尾几行,默认5行 |
| info | 返回列名,非缺失值个数 |
| describe | 返回一系列统计值 |
统计特征函数
可以调用sum, mean, median, var, std, max, min等常用统计特征函数。
同时,需要注意的还有quantile,count,idxmax它们分别返回的是分位数、非缺失值个数、最大值对应的索引
唯一值函数
对序列使用unique和nunique分别得到值列表以及唯一值个数。
print(df['School'].unique())
print(df['School'].nunique())
out:
['Shanghai Jiao Tong University' 'Peking University' 'Fudan University'
'Tsinghua University']
4
value_counts可以得到唯一值和其对应的频数
df['School'].value_counts()
out:
Tsinghua University 69
Shanghai Jiao Tong University 57
Fudan University 40
Peking University 34
Name: School, dtype: int64
如果想要观察多个列组合的唯一值,可以使用drop_duplicates
df_demo = df[['Gender','Transfer','Name']]
df_demo.drop_duplicates(['Gender', 'Transfer'])
其中的关键参数是keep,默认值first表示每个组合保留第一次出现的所在行,last表示保留最后一次出现的所在行,False表示把所有重复组合所在的行剔除。
替换函数
replace
传入两个列表,第一个是原来的标签,第二个则是要替换的标签,也可以传入一个字典,原值做键,新值做键对值
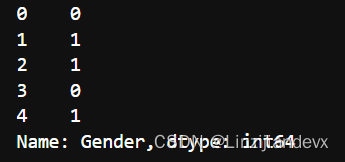
df['Gender'].replace(['Female','Male'],[0,1]).head()
# df['Gender'].replace({'Female':0, 'Male':1}).head()
out:
where与mask:
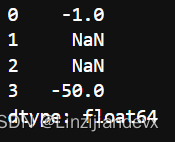
逻辑替换包括了where和mask,这两个函数是完全对称的:where函数在传入条件为False的对应行进行替换,而mask在传入条件为True的对应行进行替换,当不指定替换值时,替换为缺失值。
s = pd.Series([-1, 1.2345, 100, -50])
s.where(s<0)
out:
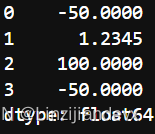
s.mask(s<0, -50)
round, abs, clip
数值替换包含了round, abs, clip方法,它们分别表示按照给定精度四舍五入、取绝对值和截断: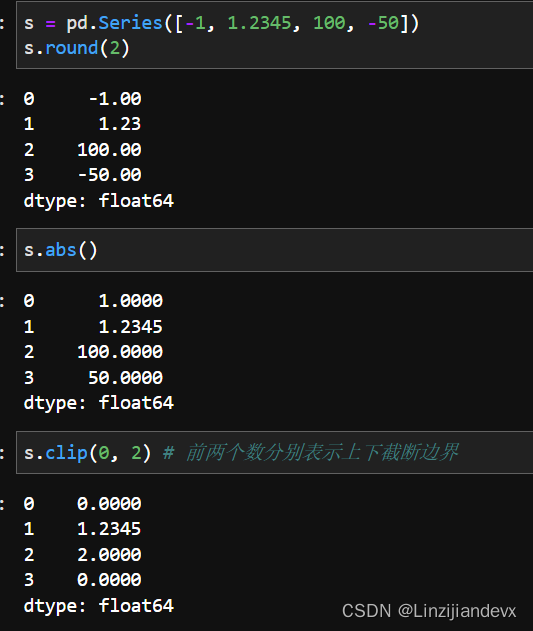
排序函数
有两种排序方法sort_values以及sort_index,默认升序,ascending控制是否升序,当多重索引或者对多列数据进行排列时,ascending要传入一个布尔列表。
df.sort_values('Height',ascending= 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5024
5024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









