







目录
2.2 强化学习(Reinforcement Learning)
1 引言
首先,我们给出四个机器学习任务
- 教计算机下棋
- 垃圾邮件识别,判断是否是垃圾邮件
- 人脸识别,识别这个人是谁
- 无人驾驶,从一个地点到达另一个地点
以上四个任务,可以把它分成两类,你会怎么分呢?分类的标准又是什么呢?
我们可以将以上四个任务分为两类。仔细想想这四个任务,其实我们很容易想到1、4为一类,2、3为一类。那么我们的分类标准又是什么呢?根据我们上一节介绍的定义机器学习的三个量有任务T、性能指标P和经验E(见此篇文章的逻辑定义)。在上面的三个量中,我们只能根据经验E来进行分类。
2 机器学习分类
2.1 监督学习(Supervised Learning)
在任务2和3中,我们需要进行垃圾邮件识别和人脸识别,经验E即为垃圾邮件数据和人脸数据,而这些数据都是通过人工收集的并输入到计算机中的。
在垃圾邮件识别中,我们需要收集大量的垃圾邮件和非垃圾邮件数据(我们所称的训练数据),并告诉计算机这是垃圾邮件,这不是垃圾邮件,即给我们收集的数据打标签。最后在输入到计算机中。同样的,对于人脸识别,我们也需要大量人脸数据并告诉计算机这个人是谁(给数据打标签)最后在输入到计算机中。通过以上例子,我们也可以得到经验E就是训练数据样本以及对应数据标签的合集。
我们把这类由人工采集数据以及相应标签输入计算机的机器学习方法称为监督学习。
对于监督学习,我们还可以根据数据标签是否存在将其分为传统监督学习、非监督学习、半监督学习三类。
2.1.1 传统监督学习
每一个数据都有对应标签,即称为传统监督学习。对于传统监督学习中,我们会学到的算法主要包括:
- 支持向量机(Support Vector Machine)
- 人工神经网络(Neural Networks)
- 深度神经网络(Deep Neural Networks)
但不仅仅局限于这几种算法。
2.1.2 非监督学习
所有的数据都没有对应的标签,即称为非监督学习。为什么没有标签的数据也能进行分类呢?这里举一个简单的例子。


在一个二维空间中有一些样本点,我们不知道这些训练样本的数据类别,这里,我们需要假设一个条件:在空间中相聚更近的点即为一类,如果这个假设成立我们就可以根据样本空间的信息,设计算法将其聚集为两类,从而实现没有标签的机器学习,即无监督学习。主要用到的算法有:
- 聚类算法(Clustering)
- EM算法(Expectation-Maximization)
- 主成分分析(Principle Component Analysis)
但不仅仅局限于这几种算法。
2.1.3 半监督学习
一部分数据有标签,一部分数据没有标签,即称为半监督学习。半监督学习的运用非常广泛,随着互联网的不断发展,数据量不断增大。进行数据标签的成本也越来越大。因此,利用少量标注数据和大量没有标注的数据训练一个更好的机器学习算法,成为了机器学习领域的热点之一。
2.1.4 其它分类
另外,我们还可以根据标签的固有属性将监督学习分为两类。
- 分类(Classification):标签是离散的值
- 回归(Regression):标签是连续的值
对于分类,例如在人脸识别中,我们把两张图片是同一个人记为1,不是同一个人记为0,这些标签就是由离散的0和1组成的,因此是分类问题。
对于回归,标签是连续的值。例如设计算法预测房价走势、股票走势、预测温度等等都属于回归问题。其实在某种情况下,分类和回归的界限是非常模糊的,因为连续和离散之间的关系也是非常模糊的,它们二者可以相互转化。
2.2 强化学习(Reinforcement Learning)
在任务1和4中,经验E则不是人为进行数据收集获得的,而是由计算机与外界环境进行互动获得的。计算机随机的产生行为,同时获得改行为的结果,而我们的程序需要通过定义这些行为的收益函数,对行为进行奖励或者惩罚。例如计算机下棋,如果下赢了,我们就进行奖励;如果下输了,我们就进行惩罚。同样的对于自动驾驶,如果到达终点,我们就进行奖励;如果没有到达终点或者中途出了事故,我们就进行惩罚。
同时,我们需要设计算法让计算机自动的改变自己的行为模式来最大化收益函数,完成机器学习任务的过程。即通过计算机与环境的互动逐渐强化自己的行为模式达到一个最佳的效果,称之为强化学习。
3 总结
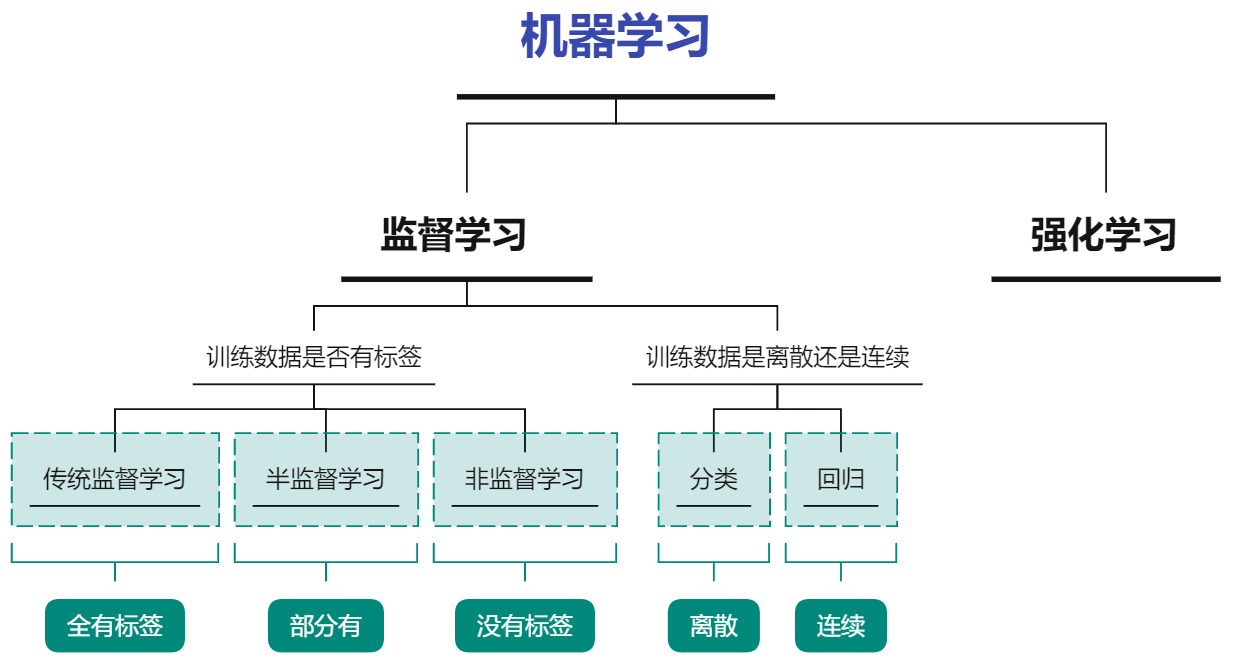
首先,根据任务是否需要与外界交互获得经验E,将机器学习分为两大类;一类是不需要与外界环境交互,人工收集数据的监督学习,另一类是需要与外界交互获得的强化学习。
其次,我们对监督学习进行了细致的分类。根据训练样本是否有标签我们将其分为三类:
- 训练数据全部都有对应标签——传统监督学习
- 训练数据全部都没有标签——非监督学习
- 训练数据一部分有标签,一部分没有标签——半监督学习
另外,监督学习还有另一种分类方法,根据标签是否是离散的可以分为两类:一类是训练数据对应标签,全部是离散的值,我们称为分类;另一类是其训练数据对应标签为连续的值,我们称为回归。
如有不对,敬请指正
觉得好的小伙伴就点个赞吧~~
















 5816
5816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











