







目录
一、labelme 简介
Labelme是一个开源的图像标注工具,由麻省理工学院的计算机科学和人工智能实验室(CSAIL)开发。它主要用于创建计算机视觉和机器学习应用所需的标记数据集。LabelMe让用户可以在图片上标注对象和区域,为机器学习模型提供训练数据。它支持多种标注类型,如矩形框、多边形和线条等。它是用 Python 编写的,并使用 Qt 作为其图形界面。
二、Anaconda 安装
参考这个教程:http://t.csdnimg.cn/zeXIw(内附超级详细教程,请仔细观看!)
三、Labelme 安装
一键运行包:Labelme v5.3.1(点击下载免费资源即可使用!)
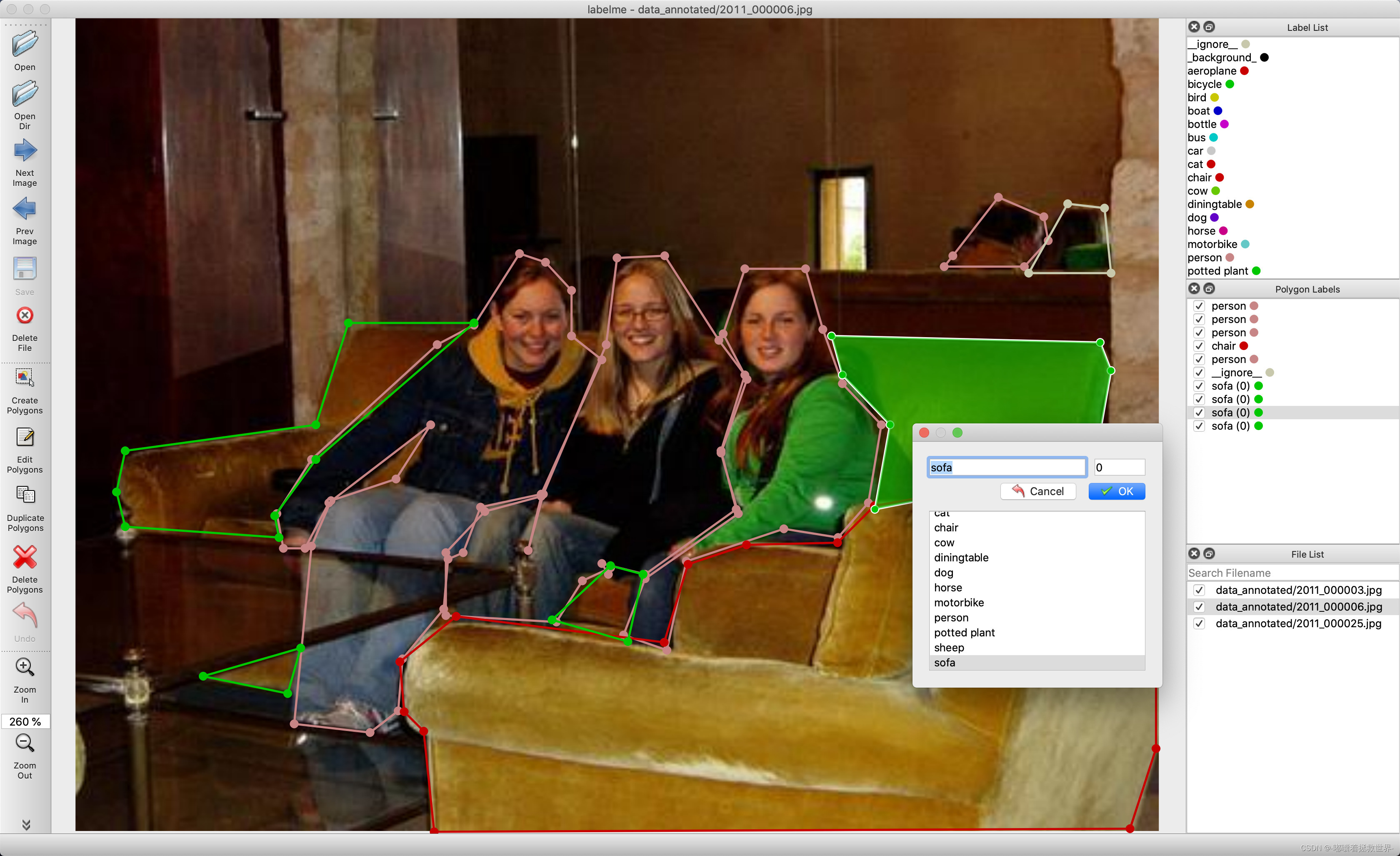
四、Labelme 简单使用教程
首先双击打开Labelme软件。
Labelme的操作界面如下:

Labelme快捷键如下:
| A | 切换到上一张图片 |
| D | 切换到下一张图片 |
| Ctrl+E | 选中标注框或标签时按下可打开编辑窗口 |
| ctrl+R | 创建两点矩形框 |
| Ctrl+鼠标滚轮 | 放大/缩小当前图片 |
| Ctrl+F | 还原尺寸 |
| Ctrl+J | 切换到编辑模式 |
| Ctrl+S | 保存文件 |
生成好的文件如下示例:

五、json转voc格式
首先将json和图片分开成两个文件夹。

然后复制下方这份代码到编辑器,修改最后三行代码的路径,然后运行。
(运行可能会报错,只需要安装好对应的依赖就好)
import cv2
import json
import os
import os.path as osp
import shutil
import chardet
def get_encoding(path):
f = open(path, 'rb')
data = f.read()
file_encoding = chardet.detect(data).get('encoding')
f.close()
return file_encoding
def is_pic(img_name):
valid_suffix = ['JPEG', 'jpeg', 'JPG', 'jpg', 'BMP', 'bmp', 'PNG', 'png']
suffix = img_name.split('.')[-1]
if suffix not in valid_suffix:
return False
return True
class X2VOC(object):
def __init__(self):
pass
def convert(self, image_dir, json_dir, dataset_save_dir):
"""转换。
Args:
image_dir (str): 图像文件存放的路径。
json_dir (str): 与每张图像对应的json文件的存放路径。
dataset_save_dir (str): 转换后数据集存放路径。
"""
assert osp.exists(image_dir), "The image folder does not exist!"
assert osp.exists(json_dir), "The json folder does not exist!"
if not osp.exists(dataset_save_dir):
os.makedirs(dataset_save_dir)
# Convert the image files.
new_image_dir = osp.join(dataset_save_dir, "JPEGImages")
if osp.exists(new_image_dir):
raise Exception(
"The directory {} is already exist, please remove the directory first".
format(new_image_dir))
os.makedirs(new_image_dir)
for img_name in os.listdir(image_dir):
if is_pic(img_name):
shutil.copyfile(
osp.join(image_dir, img_name),
osp.join(new_image_dir, img_name))
# Convert the json files.
xml_dir = osp.join(dataset_save_dir, "Annotations")
if osp.exists(xml_dir):
raise Exception(
"The directory {} is already exist, please remove the directory first".
format(xml_dir))
os.makedirs(xml_dir)
self.json2xml(new_image_dir, json_dir, xml_dir)
class LabelMe2VOC(X2VOC):
"""将使用LabelMe标注的数据集转换为VOC数据集。
"""
def json2xml(self, image_dir, json_dir, xml_dir):
import xml.dom.minidom as minidom
i = 0
for img_name in os.listdir(image_dir):
img_name_part = osp.splitext(img_name)[0]
json_file = osp.join(json_dir, img_name_part + ".json")
i += 1
if not osp.exists(json_file):
os.remove(osp.join(image_dir, img_name))
continue
xml_doc = minidom.Document()
root = xml_doc.createElement("annotation")
xml_doc.appendChild(root)
node_folder = xml_doc.createElement("folder")
node_folder.appendChild(xml_doc.createTextNode("JPEGImages"))
root.appendChild(node_folder)
node_filename = xml_doc.createElement("filename")
node_filename.appendChild(xml_doc.createTextNode(img_name))
root.appendChild(node_filename)
with open(json_file, mode="r", \
encoding=get_encoding(json_file)) as j:
json_info = json.load(j)
if 'imageHeight' in json_info and 'imageWidth' in json_info:
h = json_info["imageHeight"]
w = json_info["imageWidth"]
else:
img_file = osp.join(image_dir, img_name)
im_data = cv2.imread(img_file)
h, w, c = im_data.shape
node_size = xml_doc.createElement("size")
node_width = xml_doc.createElement("width")
node_width.appendChild(xml_doc.createTextNode(str(w)))
node_size.appendChild(node_width)
node_height = xml_doc.createElement("height")
node_height.appendChild(xml_doc.createTextNode(str(h)))
node_size.appendChild(node_height)
node_depth = xml_doc.createElement("depth")
node_depth.appendChild(xml_doc.createTextNode(str(3)))
node_size.appendChild(node_depth)
root.appendChild(node_size)
for shape in json_info["shapes"]:
if 'shape_type' in shape:
if shape["shape_type"] != "rectangle":
continue
(xmin, ymin), (xmax, ymax) = shape["points"]
xmin, xmax = sorted([xmin, xmax])
ymin, ymax = sorted([ymin, ymax])
else:
points = shape["points"]
points_num = len(points)
x = [points[i][0] for i in range(points_num)]
y = [points[i][1] for i in range(points_num)]
xmin = min(x)
xmax = max(x)
ymin = min(y)
ymax = max(y)
label = shape["label"]
node_obj = xml_doc.createElement("object")
node_name = xml_doc.createElement("name")
node_name.appendChild(xml_doc.createTextNode(label))
node_obj.appendChild(node_name)
node_diff = xml_doc.createElement("difficult")
node_diff.appendChild(xml_doc.createTextNode(str(0)))
node_obj.appendChild(node_diff)
node_box = xml_doc.createElement("bndbox")
node_xmin = xml_doc.createElement("xmin")
node_xmin.appendChild(xml_doc.createTextNode(str(xmin)))
node_box.appendChild(node_xmin)
node_ymin = xml_doc.createElement("ymin")
node_ymin.appendChild(xml_doc.createTextNode(str(ymin)))
node_box.appendChild(node_ymin)
node_xmax = xml_doc.createElement("xmax")
node_xmax.appendChild(xml_doc.createTextNode(str(xmax)))
node_box.appendChild(node_xmax)
node_ymax = xml_doc.createElement("ymax")
node_ymax.appendChild(xml_doc.createTextNode(str(ymax)))
node_box.appendChild(node_ymax)
node_obj.appendChild(node_box)
root.appendChild(node_obj)
with open(osp.join(xml_dir, img_name_part + ".xml"), 'w') as fxml:
xml_doc.writexml(
fxml,
indent='\t',
addindent='\t',
newl='\n',
encoding="utf-8")
def convert(pics,anns,save_dir):
"""
将使用labelme标注的数据转换为VOC格式
请将labelme标注的文件中,所有img文件保存到pics文件夹中,所有xml文件保存到anns文件夹中,结构如下:
--labelmedata
---pics
----img0.jpg
----img1.jpg
----......
---anns
----img0.mxl
----img1.xml
----......
:param pics: img文件所在文件夹的路径
:param anns: xml文件所在文件夹的路径
:param save_dir: 输出VOC格式数据的保存路径
:return:
"""
labelme2voc = LabelMe2VOC().convert
labelme2voc(pics, anns, save_dir)
if __name__=="__main__":
convert(pics=r"JPEGImages", # 修改图片路径
anns=r"json", # 修改json格式文件路径
save_dir=r"VOC") # 保存VOC格式的路径
六、VOC转YOLO格式
如果想要VOC转YOLO格式,用于YOLO代码训练当中的,可以参考下方这份代码。只需修改最底下的路径就可以直接运行。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
def convert(size, box):
x_center = (box[0] + box[1]) / 2.0
y_center = (box[2] + box[3]) / 2.0
x = x_center / size[0]
y = y_center / size[1]
w = (box[1] - box[0]) / size[0]
h = (box[3] - box[2]) / size[1]
return (x, y, w, h)
def convert_annotation(xml_files_path, save_txt_files_path, classes):
xml_files = os.listdir(xml_files_path)
print(xml_files)
for xml_name in xml_files:
print(xml_name)
xml_file = os.path.join(xml_files_path, xml_name)
out_txt_path = os.path.join(save_txt_files_path, xml_name.split('.')[0] + '.txt')
out_txt_f = open(out_txt_path, 'w')
tree = ET.parse(xml_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
# b=(xmin, xmax, ymin, ymax)
print(w, h, b)
bb = convert((w, h), b)
out_txt_f.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == "__main__":
# 需要转换的类别,需要一一对应
classes1 = ['boat', 'cat']
# 2、voc格式的xml标签文件路径
xml_files1 = r'C:\Users\86159\Desktop\VOC2007\Annotations'
# 3、转化为yolo格式的txt标签文件存储路径
save_txt_files1 = r'C:\Users\86159\Desktop\VOC2007\label'
convert_annotation(xml_files1, save_txt_files1, classes1)















 1262
1262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











