









 本文详细介绍了如何使用Labelme工具进行关键点检测数据集的标注,并将其转换为YOLO所需的.json格式,包括yolo关键点检测数据集的结构说明和Labelme的安装与使用方法。
本文详细介绍了如何使用Labelme工具进行关键点检测数据集的标注,并将其转换为YOLO所需的.json格式,包括yolo关键点检测数据集的结构说明和Labelme的安装与使用方法。
有任何问题我们一起交流,让我们共同学习
标注的json格式以及转换后的yolo格式示例
如果您的json标签格式如下,进行较为轻松的修改即可使用
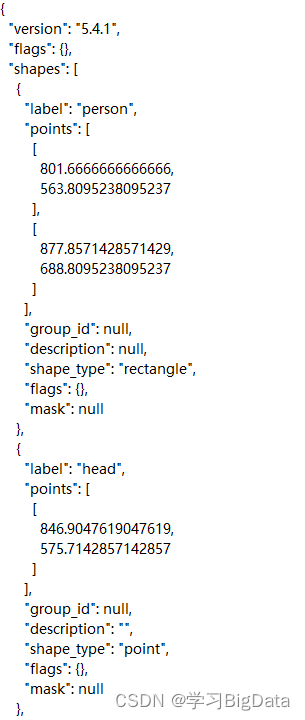
转换标签:

yaml文件:
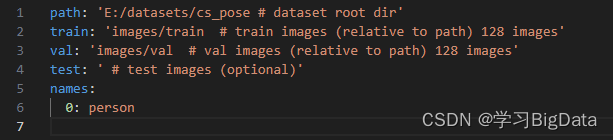
希望得到您的指导
非常感谢您观看我的博客,我写博客的目的是为了记录我的学习过程同时保留我的某些可重复利用代码以方便下次使用。如果您对我的内容有任何建议还请您不吝指出,非常感谢您对我的指导。
背景及代码可用范围
- 如果你要标注的仅是矩形框,可以有直接导出为yolo格式的标注工具。如:make sense 或labelimg
- 本博客仅针对于使用labelme标注用于yolo的json格式关键点检测数据集
一、yolo关键点检测数据集格式
yolo官网
用于训练YOLO 姿态模型的数据集标签格式如下:
每幅图像一个文本文件:数据集中的每幅图像都有一个相应的文本文件,文件名与图像文件相同,扩展名为".txt"。
每个对象一行:文本文件中的每一行对应图像中的一个对象实例。
每行对象信息:每行包含对象实例的以下信息
对象类别索引:代表对象类别的整数(如 0 代表人,1 代表汽车等)。
对象中心坐标:对象中心的 x 和 y 坐标,归一化为 0 和 1 之间。
对象宽度和高度:对象的宽度和高度,标准化后介于 0 和 1 之间。
对象关键点坐标:对象的关键点,归一化为 0 至 1。
格式为DIM = 2
<class-index> <x> <y> <width> <height> <px1> <py1> <px2> <py2> ... <pxn> <pyn>
# 采用这种格式、 <class-index> 是对象的类索引、<x> <y> <width> <height> 是边界框的坐标及宽和高,而 <px1> <py1> <px2> <py2> ... <pxn> <pyn> 是关键点的像素坐标。坐标之间用空格隔开。
格式为DIM = 3
<class-index> <x> <y> <width> <height> <px1> <py1> <p1-visibility> <px2> <py2> <p2-visibility> <pxn> <pyn> <p2-visibility>
<pn-visibility>:0代表不可见、1代表遮挡、2代表可见
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco8-pose # dataset root dir
train: images/train # train images (relative to 'path') 4 images
val: images/val # val images (relative to 'path') 4 images
test: # test images (optional)
# Keypoints
kpt_shape: [17, 3] # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible)
#17个关键点,3维
flip_idx: [0, 2, 1, 4, 3, 6, 5, 8, 7, 10, 9, 12, 11, 14, 13, 16, 15]
#反转后关键点的对应关系
# Classes dictionary
names:
0: person
根据官方文档,标注文件时首先要标注一个矩形框将目标框起来,然后再标注关键点数据
二、labelme的安装和使用
(一)labelme的安装
中文labelme的百度网盘
链接:https://pan.baidu.com/s/1puJdLZO-z4CPOIbiq4tFvA?pwd=1111
提取码:1111
界面如图所示
(二)labelme的使用
A:上一个图片
D:下一个图片
根据官方文档,标注文件时首先要标注一个矩形框将目标框起来,然后再标注关键点数据
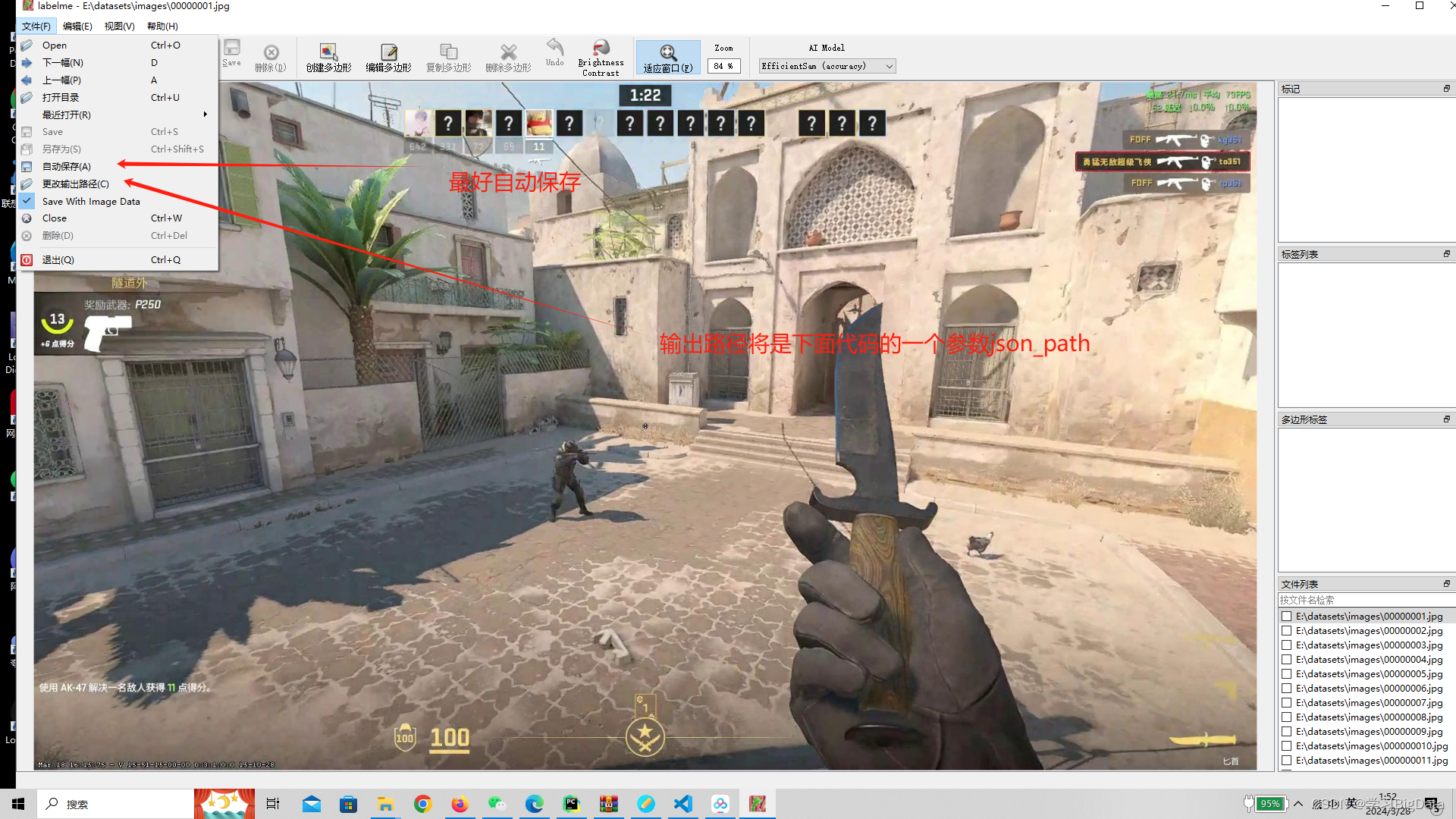
根据官方文档,标注文件时首先要标注一个矩形框将目标框起来,然后再标注关键点数据
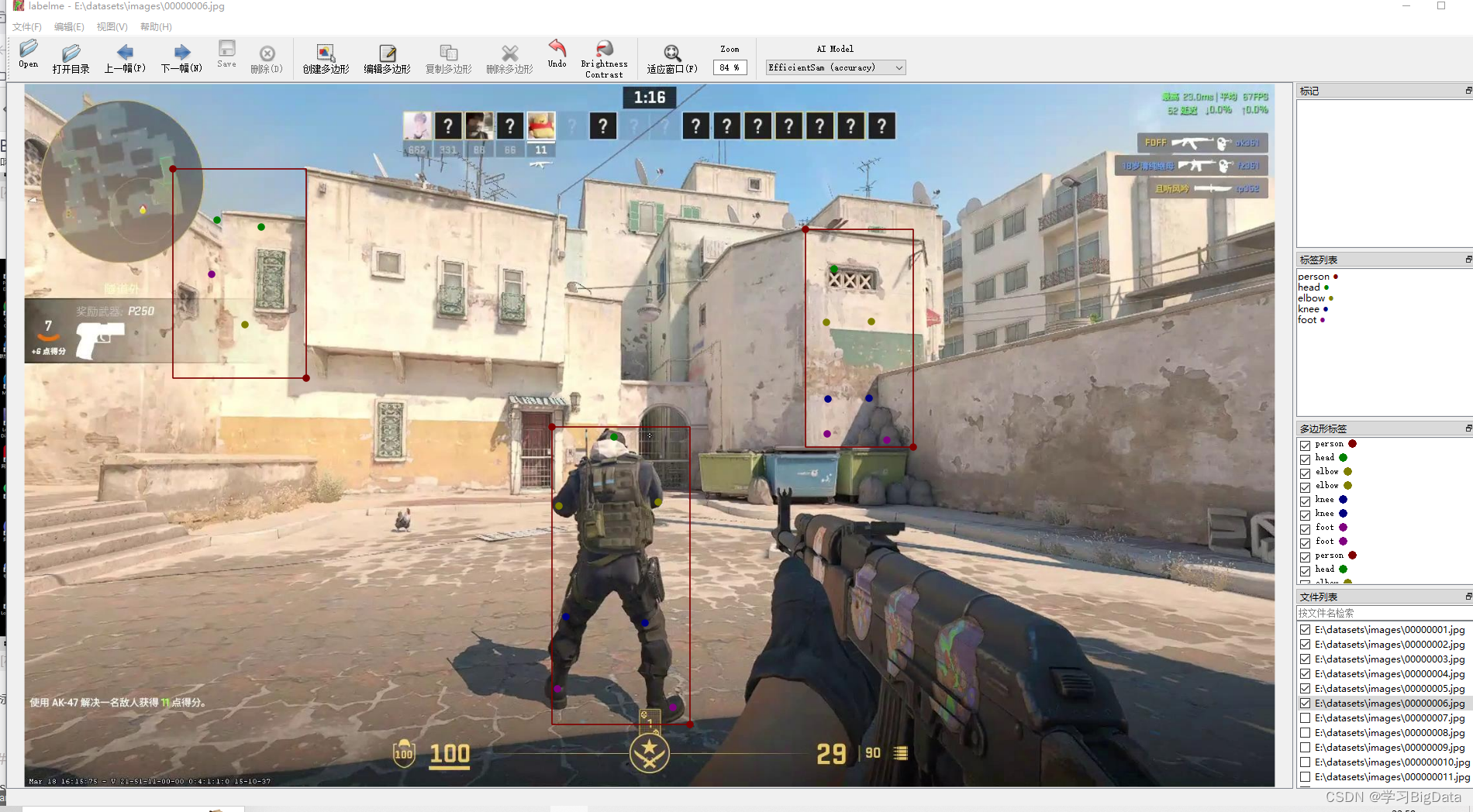
 标注后类似
标注后类似
根据官方文档,标注文件时首先要标注一个矩形框将目标框起来,然后再标注关键点数据
三、json2yolo
json_path:标注的json文件所在位置
yolo_path:转换后的yolo文件存放位置
image_path:标注的图片所在位置
import json
import os
from pathlib import Path
import requests
import yaml
from PIL import Image
from tqdm import tqdm # 进度条
def count_inner_list(nested_list):
count = 0
for lst in nested_list:
if isinstance(lst,list):
# 检查对象是否为指定类型
count += 1
return count
def output_label(json_path,yolo_path,image_path):
# os.makedirs(yolo_path,exist_ok=True)
json_path = Path(json_path).resolve()
yolo_path = Path(yolo_path).resolve()
json_parentpath = json_path.parent
names_dict = {0: "person"}
flipped_names = {v: k for k, v in names_dict.items()}
for filename in tqdm(os.listdir(json_path),desc="Converting"):
if filename.endswith('.json'):
with open(os.path.join(json_path,filename), 'r',encoding='utf-8') as f:
data = json.load(f) # json files to dict:json_data
last_part = os.path.basename(data.get("imagePath"))
im_path = os.path.join(image_path,last_part)
img = Image.open(requests.get(im_path,stream=True).raw if im_path.startswith("http") else im_path)
width,height = img.size
# size属性获得图像宽度和高度的元组,通常形式为(width, height)
label_filename = last_part+"txt"
label_path = os.path.join(yolo_path,Path(label_filename).with_suffix(".txt"))
# 转换后标签存放路径
temp_str = ""
previous_person_data = ""
cnt = 0
for label in data.get("shapes"):
if label.get("label") == "person" :
cnt += 1
if cnt > 1:
current_person_data = f"{previous_person_data} {temp_str} \n"
previous_person_data = current_person_data
label_list = label.get("points")
x_1,y_1 = label_list[0]
x_2,y_2 = label_list[1]
x_centre = round(((x_1+x_2)/2)/width,2)
y_centre = round(((y_1+y_2)/2)/height,2)
person_width = round(abs(x_1-x_2)/width,2)
person_height = round(abs(y_1-y_2)/height,2)
temp_str = (f"{flipped_names['person']} {x_centre} {y_centre} {person_width} {person_height} ")
else:
label_list = label.get("points")
x,y=label_list[0]
# 根据json文件的特征,points内部是双重列表,且内层只有一个列表,所以我们将第一个列表的值分别赋值给x,y
x = round(x/width,2)
y = round(y/height,2)
temp_str = (f"{temp_str} {x} {y} ")
current_person_data = f"{previous_person_data} {temp_str}"
with open(label_path,"a") as f:
f.write(current_person_data + "\n")
# Save dataset.yaml
d = {
"path": f"{json_parentpath} # dataset root dir".replace('\\','/'),
"train": f"{json_parentpath}/images/train # train images (relative to path) 128 images".replace('\\','/'),
"val": f"{json_parentpath}/images/val # val images (relative to path) 128 images".replace('\\','/'),
"test": " # test images (optional)",
"names": names_dict,
} # dictionary
file_path = os.path.join(json_parentpath, "data.yaml")
with open(file_path,"w",encoding='utf-8')as f:
yaml.dump(d,f,sort_keys=False)
print("Conversion completed successfully!")
if __name__ == '__main__':
output_label(r"E:\datasets\jsons",r"E:\datasets\labels",r"E:\datasets\images")

















 4826
4826

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









