






目录
Epsilon Greedy 策略(学习样本时如何选择动作)
无监督学习
主要包含聚类和异常检测
K-means聚类
K-means是最常用的聚类算法
K-means聚类算法原理
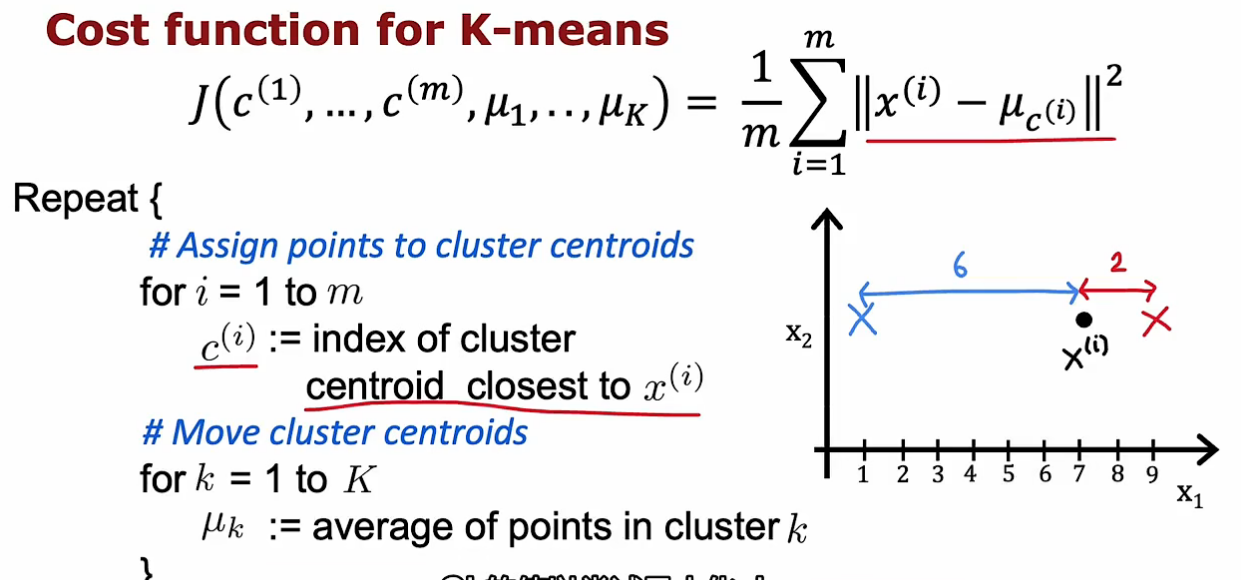
随机确定每个簇的中心(簇中心又叫簇质心)(如何确定要分几个簇后面讲),然后重复执行两个步骤:
1-遍历每个点,将点分配给簇中心(离哪个簇质心近就分配给谁);

2-遍历分配后每个簇中的点,取平均值,再把簇中心移动到平均位置上

不断循环这两个步骤,直到点的颜色和簇质心位置不再变化
K-means算法实现
伪代码:

假设要分为K个族,随机设置簇中心μ,然后分两步走:
1-遍历m个样本点, 判定每个点离那个簇中心近(距离也是二范数,但一般用平方差,不开根号)
2-遍历K个簇,计算每个簇中各特征的平均值,再赋给簇中心(如公式中,x为向量,若有两个特征,则μ也有两个特征)
如果某簇没有分配到点,则会取消该簇(更常见)或重新随机取簇中心
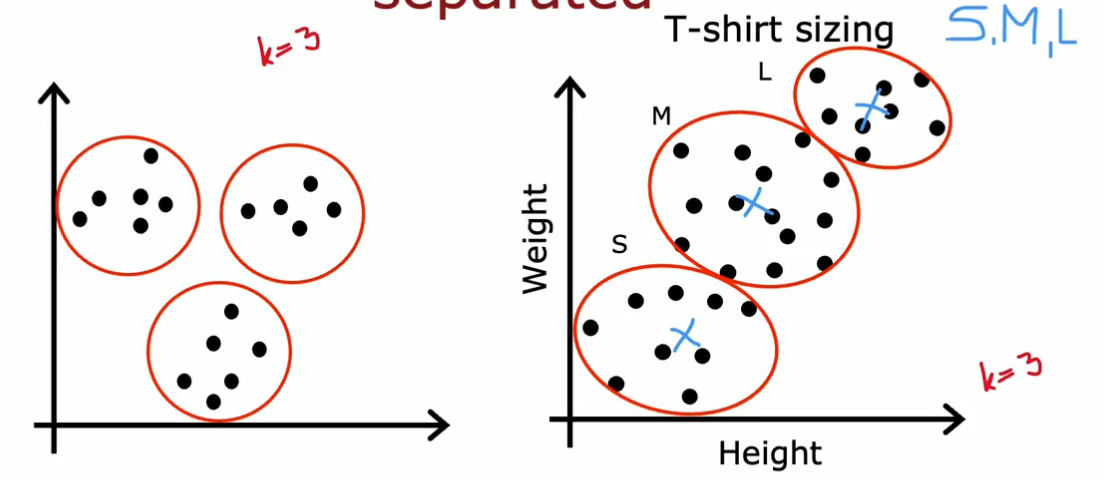
如果数据分离不太明显,K-means依然能起作用并给出具有参考价值的结果。如下图中右面的尺寸划分(给定K=3就会划出三个簇)
 优化目标(k-means的代价函数)
优化目标(k-means的代价函数)
x为样本特征值,μ_c(i)代表x_i这个样本被分到的簇中心的特征值,二范数平方也就是每个特征都分别做平方差再相加。
在代价函数中x(i)是不变的,调整的只能是μ_c(i)。一是调整样本点被分到哪个簇(分配到最近的簇,会使代价函数最小化);二是调整簇中心位置
即第一步是变c1~cm不变μ(把每个样本分配到最近的簇质心),第二步变μ不变c(移动簇质心)
因为每一步都是让代价函数下降,所以代价函数不可能上升,出现了就是代码有问题
簇质心初始值的选择
如何更好随机初始化簇质心?
一般做法是从m个样本中随机选K个样本,作为K个簇质心的初始值
但如果随机选的不幸运,很可能陷入局部最小值,如下图中下面两个例子
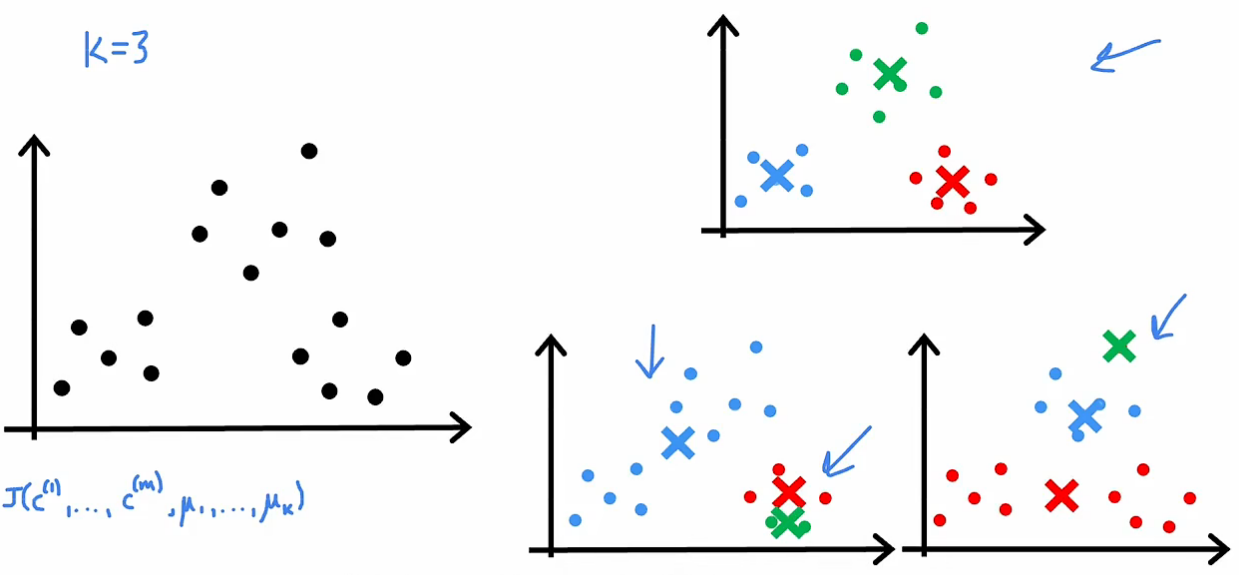
解决方法是多次运行K-means算法(每次初始值都是随机的),每次都能得到一种方案,然后分别计算代价函数,看哪个最小(上图中上面的簇会比下面两个的代价函数小)
最终算法伪代码:

1-随机选取k个样本为簇质心初始值;2-运行k-means算法至收敛;3-计算该方案的代价函数
重复运行100次(一般在50-1000次之间),最终选择代价函数最低的方案
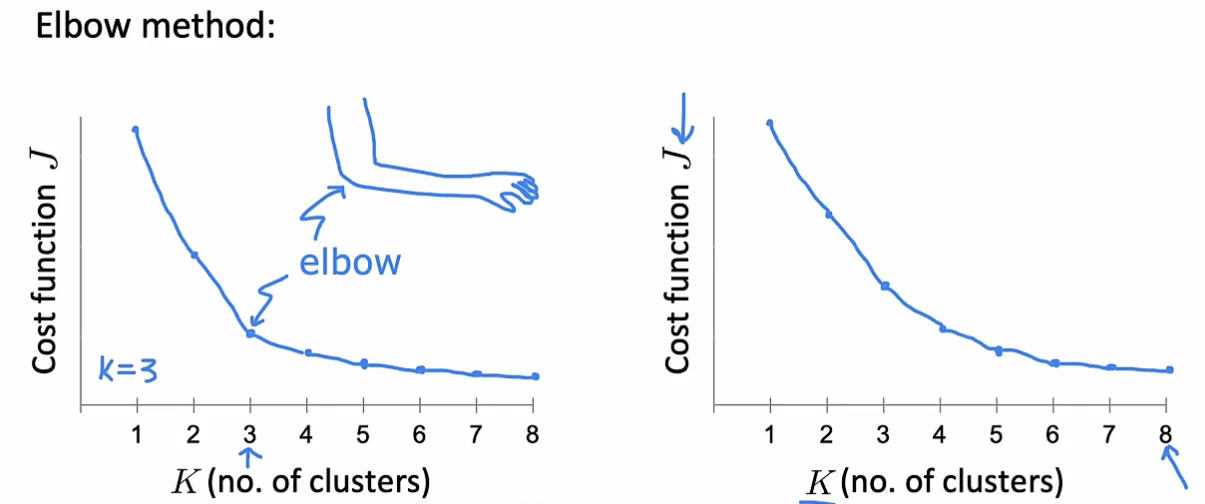
如何确定簇的数量K
一种方法为肘部方法:选取不同的K值,分别计算代价函数,找转折点
一般在使用是要看下游任务的需求是什么
异常检测
问题描述与检测思路
先给一定的训练数据集,然后给新的样本判断它是否正常
进行异常检测的最常用方法——密度估计(density estimation)
通过已有的训练数据集建立模型,划分概率高和概率低的区域,当获得测试样本时,看它属于哪个区域(正常的概率是多少)
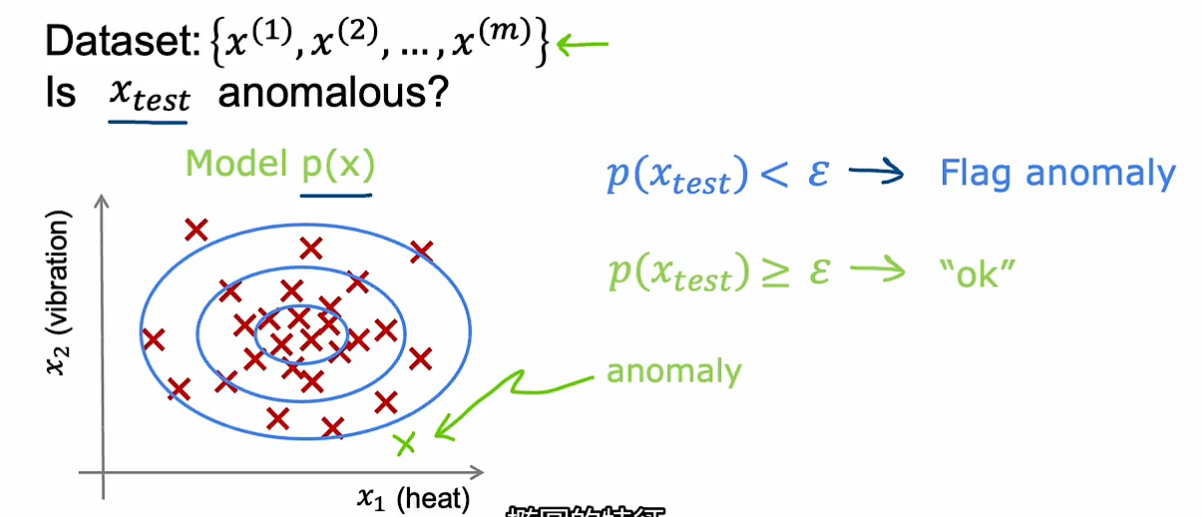
异常检测可用于金融安全(金融欺诈行为)、制造业、监控计算机是否异常(CPU GPU作为特征)
高斯正态分布(对p(x)进行建模)
异常检测建模方法通常使用高斯分布(又叫正态分布)
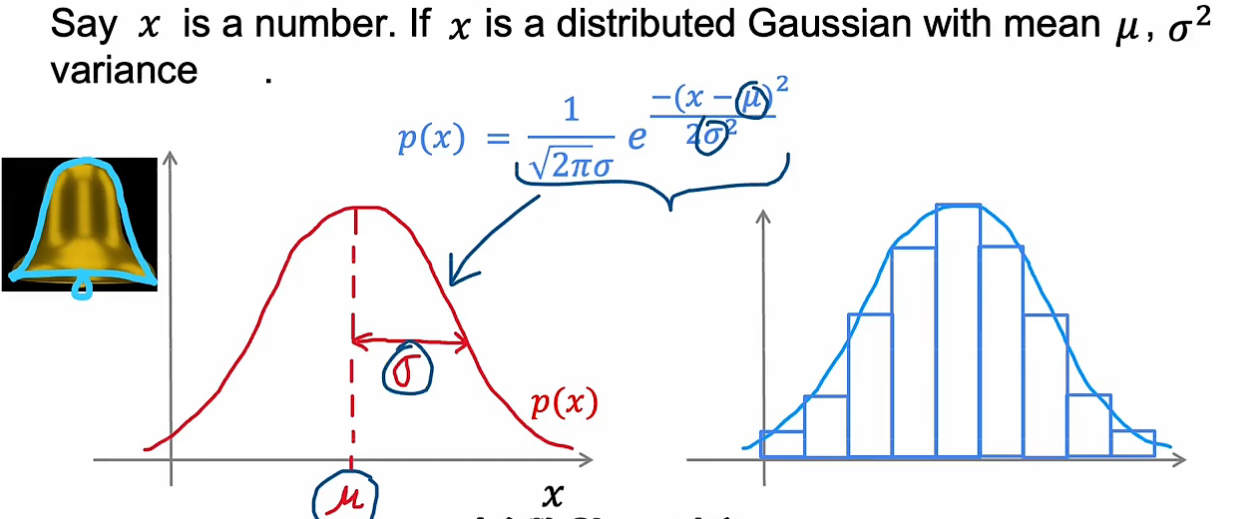
高斯分布有两个参数,μ均值决定对称中心,标准差决定宽度
p(x)与x轴形成面积等于1,所以宽的必定矮,窄的必定高
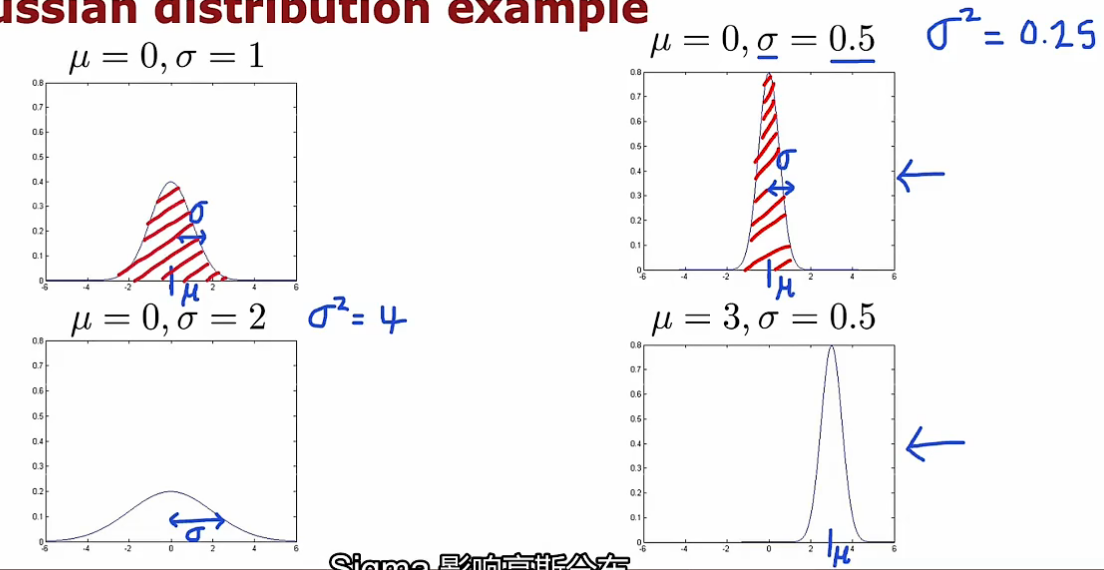
参数估计:在样本集中计算均值μ,和方差,就可得到p(x)公式,也可画出高斯分布图像。当有一个新样本值时,就可估计其概率p(x)

异常检测算法
假设样本具有n个特征,分别计算每个特征上的均值和方差,把各特征上的概率p都计算出来再相乘就是总的(默认是各特征相互独立的前提,即使有的不独立,结果也不错)

第j个特征上的均值和方差计算公式如下,也可用向量化,用一个向量代表n个特征上的参数(m*n的样本得到1*n的均值和方差(或者说n维向量))

当给测试样本值时,按照公式其各特征上的概率,再连乘,如果小于阈值,则认为异常(一个特征上的低概率会导致总的低概率)

以两个特征为例,举例子:分别计算两个特征上的样本均值和方差

开发与评估异常检测系统(如何选择阈值ɛ)
通常,我们也会掌握部分的已知异常数据,也算是有标签数据,一般放在交叉验证集和测试集中。在训练集中依然没有标签,训练好后在交叉验证集中跑,看有多少好的数据被预测错了、异常的数据没检测出来。进而调整阈值。

当异常数据量很少时,会取消测试集,只用交叉验证集。
算法评估:看模型在交叉验证集中的效果,评判标准可利用真假阳阴性、精确度、召回率、F1评分,从而选择更好的阈值。

异常检测与监督学习对比
异常检测通常也会用到已知异常的数据(大量负样本,少量正样本),那为什么不采用监督学习呢?
异常检测VS监督学习:
1-当正样本数量很少时(y=1),更适合异常检测(正样本只在交叉验证集中)。当正负样本数量都很多时,更适合监督学习。
2-异常检测的很大优势在于,未来可能出现的异常并不一定在现有异常中,而异常检测却很有可能检测出未出现过的异常,而监督学习不行。(异常检测是排除法找异常,监督学习是观察异常(正样本)有哪些特征)
异常检测应用:1-欺诈检测(是否存在欺诈行为);2-制造业中,用于学着从未曾出现的缺陷或异常;3-监控计算机是否出现异常
监督学习应用:1-垃圾邮件分类;2-制造业中,寻找已知的缺陷问题(目标较明确);3-天气类型预测;4-疾病诊断
如何选择特征
异常检测要从没有标签的数据中学习,所以对特征非常敏感
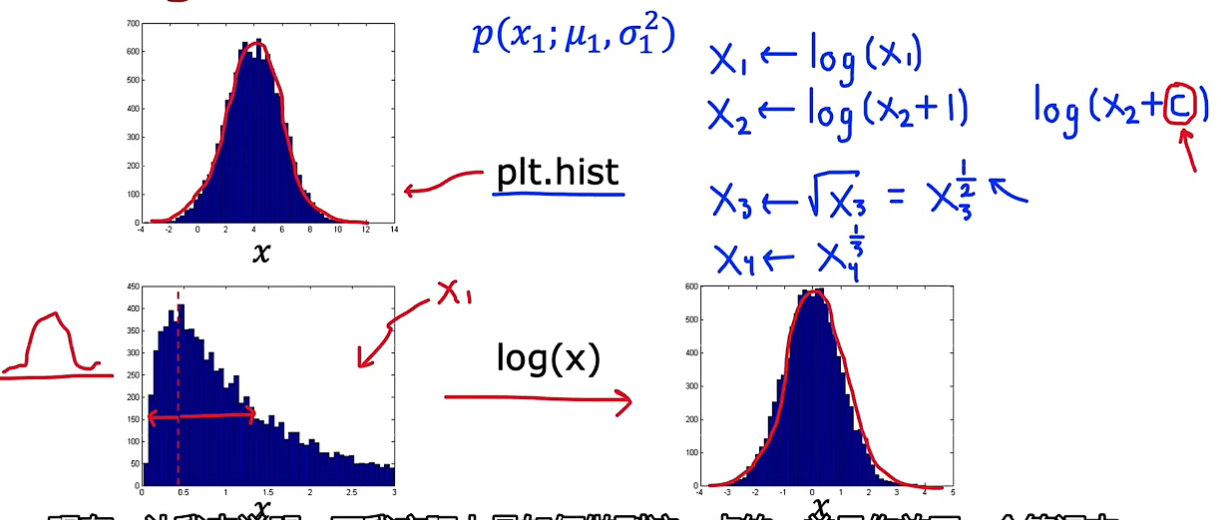
要尽量让特征具有高斯特征(绘制样本在该特征的分布直方图 plt.hist)。如果其分布直方图看起来不高斯,就通过特征转换使该特征更高斯。有一些自动匹配的方法,但效果不太理想,一般自己尝试几个取对数、取指数,效果就很好了
如果模型在交叉验证集上效果不好,则应进行误差分析
常见的情况是异常样本的p(x)也很大,要去分析这种样本有什么特别的地方,是否有新特征
有时也会把旧特征组合起来创建新特征(例如两特征比率)
推荐系统
推荐系统是商业化中最成功的应用
问题描述与思路
如根据用户对电影打分,推荐用户可能感兴趣的电影。n_u表示用户数量,n_m表示电影数量。r表示某用户与某电影是否有关联(是否打分),y表示分值(当r为1时才有y)
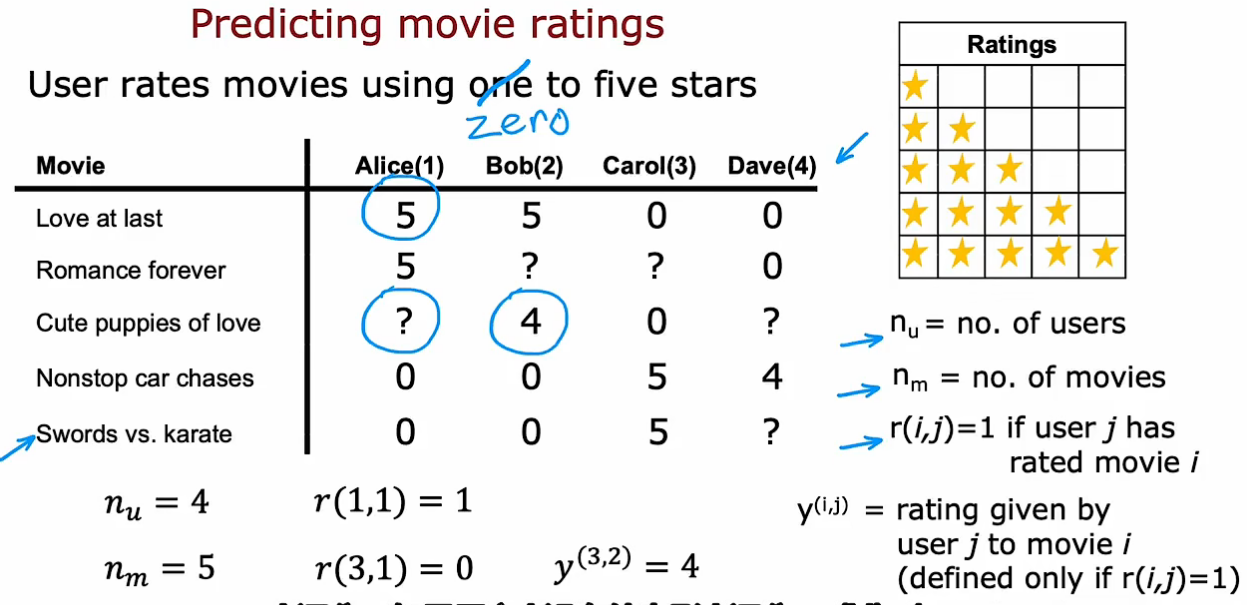 目标是向用户推荐他们可能会打5分的电影
目标是向用户推荐他们可能会打5分的电影
假设,除了用户打分,有一些其他特征,如该电影的浪漫类型程度和动作类型程度
对于一个用户而言,训练过程像线性回归,一个用户用一组参数,通过输入特征,预测打分情况
w_j, b_j代表第j个用户的参数,x_i代表第i个电影的特征
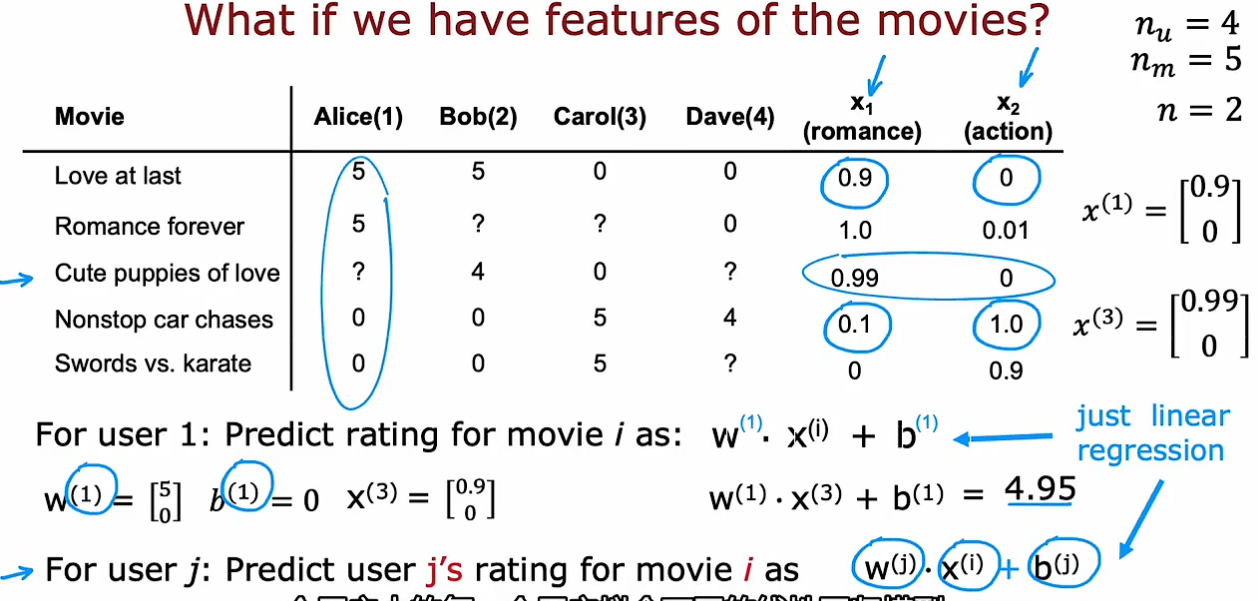
目标是学习每一个用户所对应的每一组w,b参数,代价函数为:(只考虑已打分的电影)
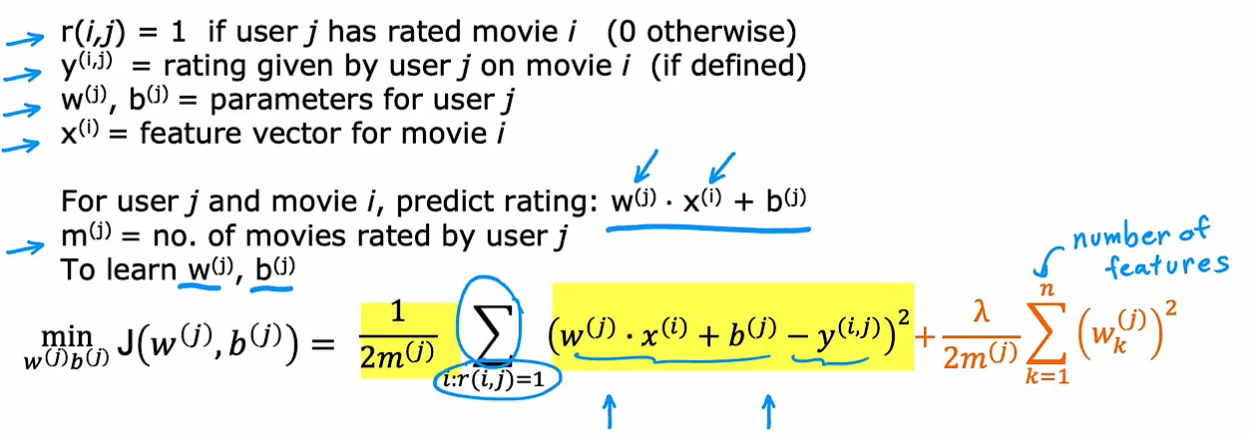
m_j只是个常数,取消掉也不会影响第j个用户的参数
为n_u里的每一个用户训练出不同的线性回归模型:

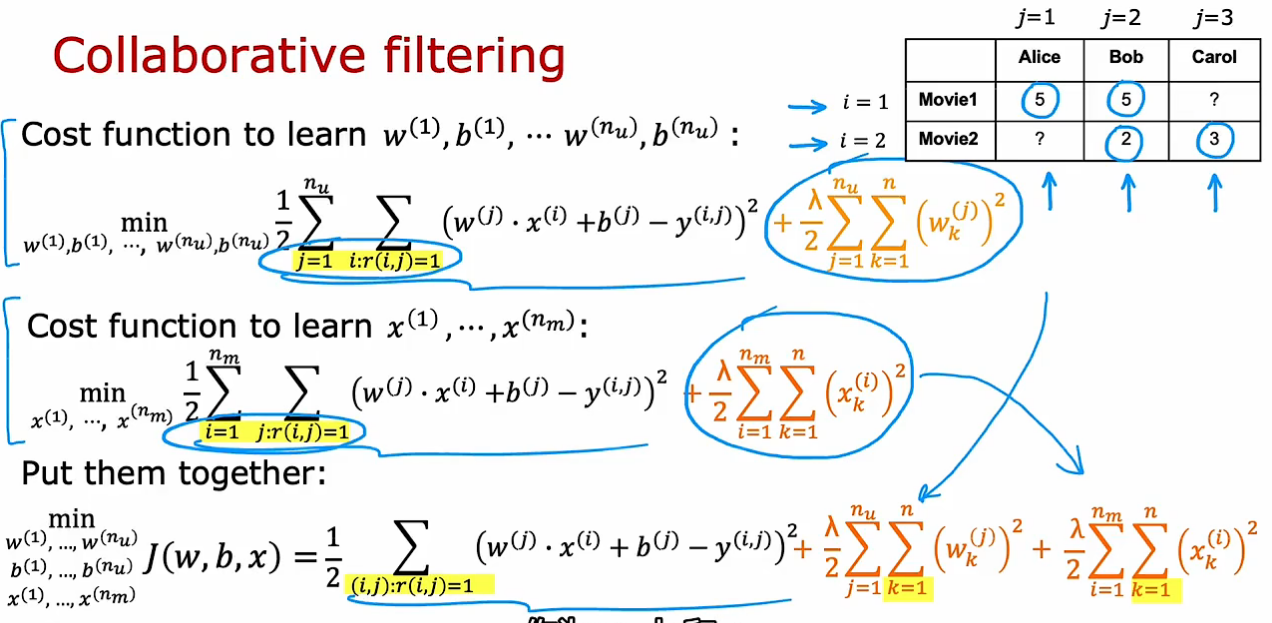
协同过滤算法
在没有额外特征时,可通过多个用户的w,b参数及打分结果来推测电影的特征
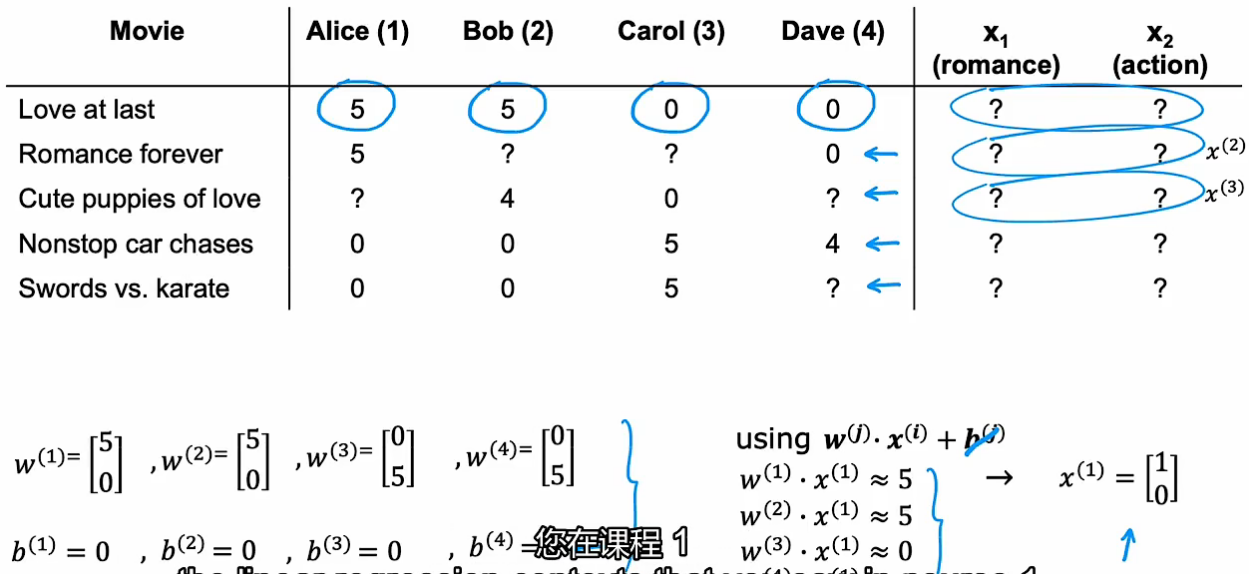
构建电影特征x_i的代价函数(所有用户对该电影的评分 平方差)(此时w_j, b_j已知)
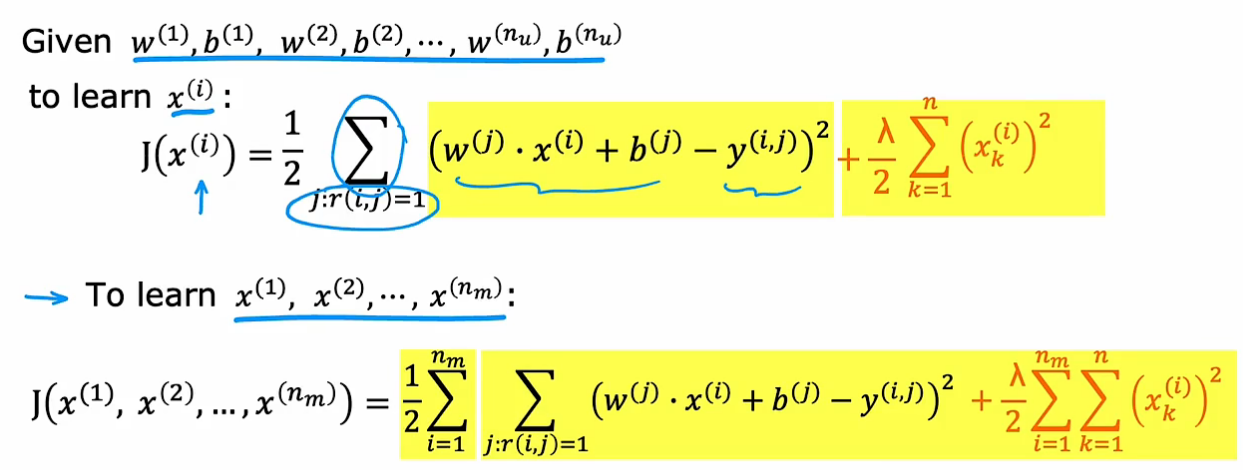
协同过滤(把特征x也当作参数):
代价函数1是对每个用户看过的电影进行计算,代价函数2是针对每个电影,利用所有用户对该电影的打分数据。
所以总代价函数是考虑所有电影和用户,寻找使整体代价函数最小的w,b,x
利用梯度下降的方法不断优化参数(把特征x也当作参数):
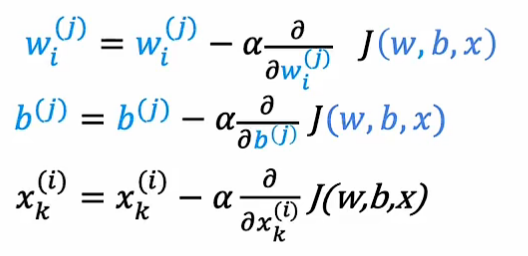
协同过滤的特点与优势:利用全部用户的数据来给每个电影定性,当预测某一用户对某一电影的打分时,再利用该用户对其他电影评分所形成的参数及该电影本身特点(其他用户数据得到的),进行预测
二元标签协同过滤
很多时候y并不是打分,而是二进制标签(喜欢/不喜欢)
从上面打分的协同过滤算法到二进制标签的算法,就像是从线性回归到逻辑回归(外面套一个sigmoid函数,使其在0~1之间,表明感兴趣的概率)
代价函数:

均值归一化(优化算法细节)
当出现尚未对任何电影进行评分的新用户时,可利用均值归一化为新用户进行预测(若按照之前的代价函数,第一项为0,所以为使整体最小,该用户的w会变成0,这样预测该用户看所有电影都会是0,所以引入均值归一化)
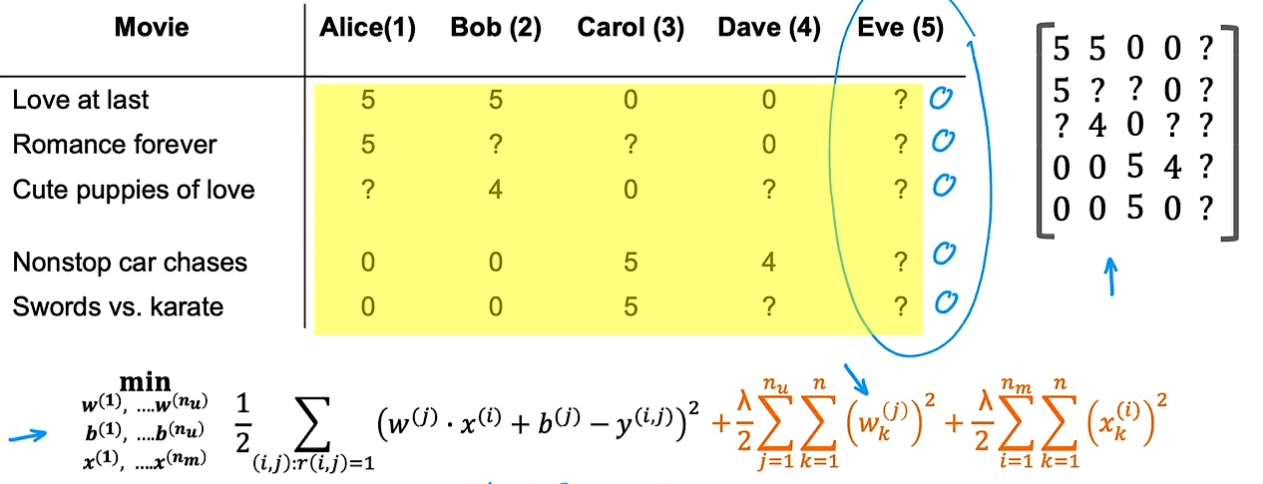
把所有评分建立矩阵,计算每部电影的平均得分,用原始得分分别减去平均得分,然后利用该矩阵作为y_i,j进行训练得到w,b,x。但在预测时要记得加上第i部电影的均值μ_i:
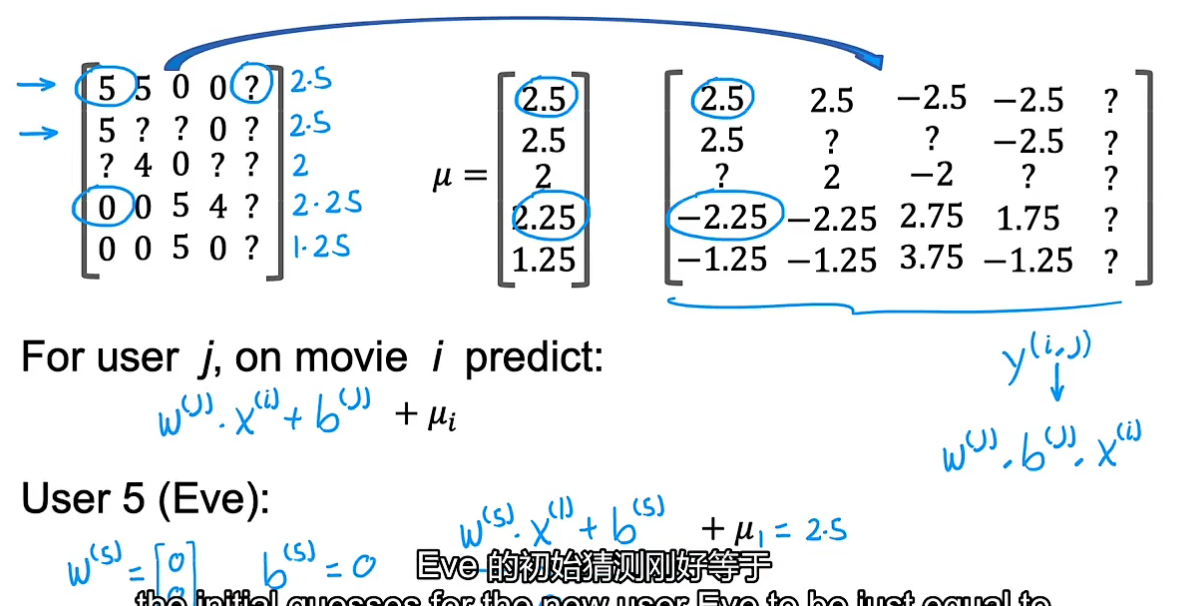
如此,出现新用户时,就不会把所有电影评分预测为0,而是预测为其他用户的平均值
均值归一化会使算法运行更快,并能对新用户有更加合理预测
TensorFlow实现协同过滤
利用tensorFlow可实现自动求导:例子中设b=0,w初始值为3开始梯度下降

TensorFlow实现协同过滤:
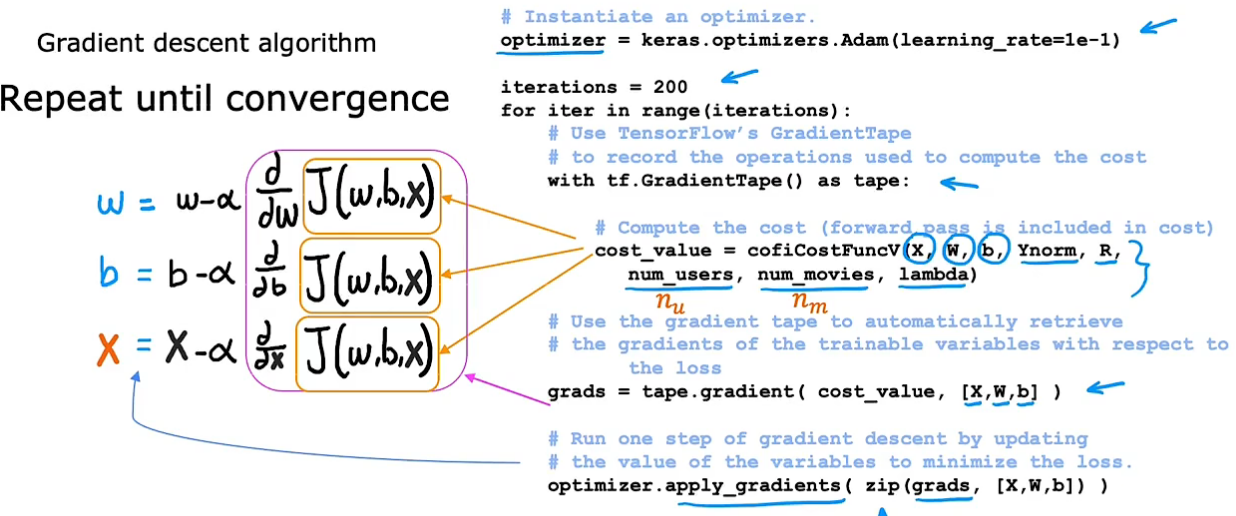
使用Adam代替梯度下降(学习率自动调整)。计算代价函数时,除了输入X,W,b以外,Ynorm表示评分均值归一化,R(r_ij)表示哪些电影有评分,用户数量,电影数量,正则项系数
grads是求到的偏导数,再利用优化器,使用Adam算法进行优化。zip()是把两个对象中的元素对应打包成元组,返回一个以元组为元素的列表
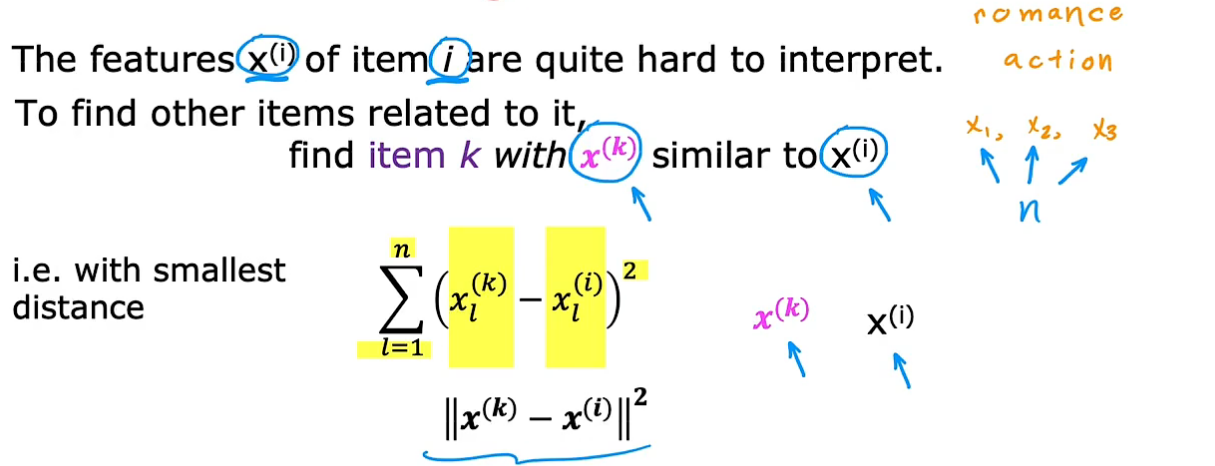
推荐其他电影
在n部电影中,找到与当前用户正在看的电影或非常感兴趣的电影的特征x_i,从所有电影中找特征最相近的x_k(n代表特征个数)
对于协同过滤,有两点限制:
- 存在冷启动问题(出现新用户、新电影时,效果不好)
- 不能提供一种自然的方式来使用关于项目或用户的附加信息(例如一部电影:电影的投资、明星、电影类型;对于用户:年龄、性别、地址),这些信息都没有很好利用进去
所以要使用基于内容的过滤算法来解决这两点限制
内容过滤
内容过滤与协同过滤对比
协同过滤是根据其他评分和你相近的用户的评分,推荐商品
内容过滤是根据用户和商品的特点去寻找更优匹配
内容过滤:分别构建用户和项目的特征,目标是进行匹配(让w*x有个好效果)
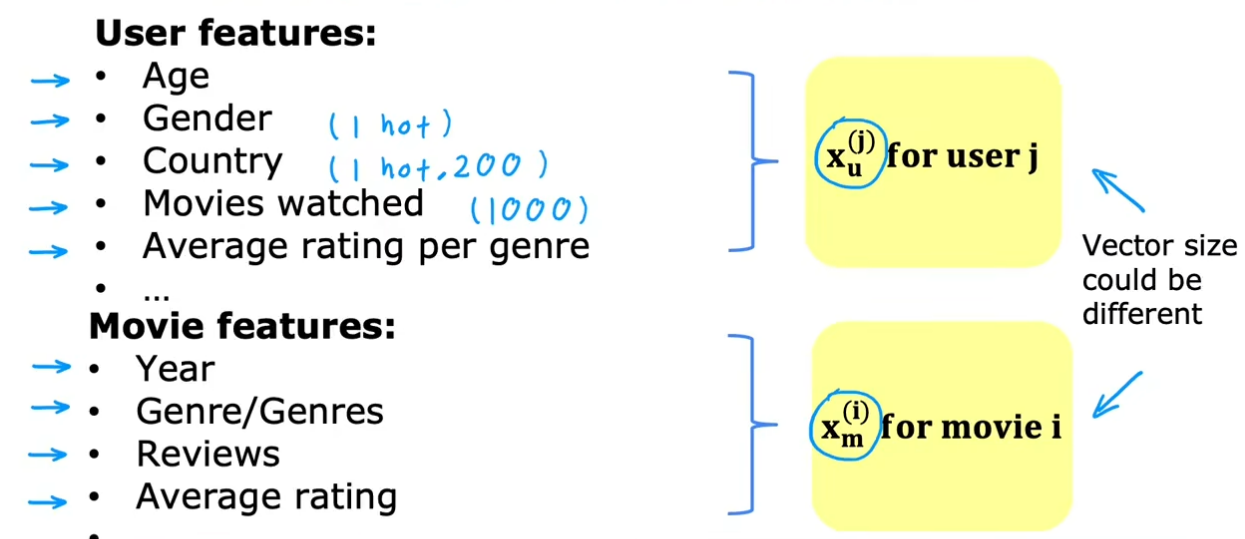
对于用户,从特征X_u中提取出用户向量V_u,对于电影,从特征X_m中提取电影向量V_m。X_u和X_m的数量可能相差很大,但用户向量V_u和电影向量V_m内的元素个数必须相等,这样才能点乘,计算评分
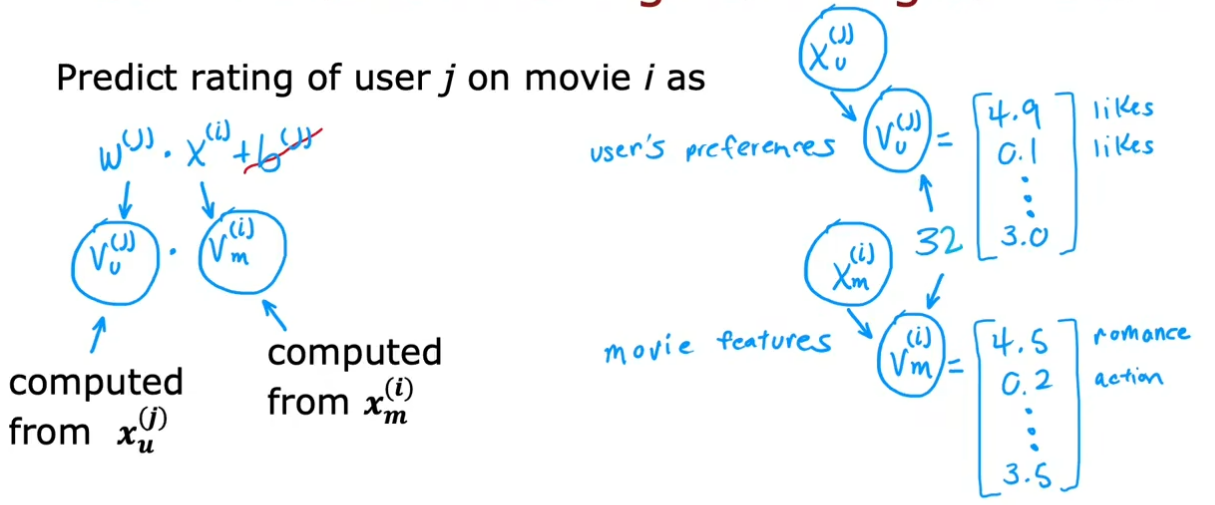
基于内容过滤的深度学习方法
从用户特征到用户向量、从电影特征到电影向量,可采用神经网络,如全连接层,使输出V_u,V_m向量维度相同(中间隐藏层神经单元数不一定一样,输出层神经单元数必须一样)。在进行预测时如果是二进制标签,则外面套一个sigmoid函数。

实际应用中,也可把两个神经网络合二为一,可加正则项

训练之后,也可用协同过滤来找相似的项目(为每部电影找到其相似电影)。计算每部电影Vm(k)与目标电影Vm(i)的二范数,找最小的,这就相当于之前协同过滤中的X(k)-X(i)的最小二范数

内容过滤扩展到大项目库
大规模的推荐系统实现步骤:数据检索(生成候选项目)和排名
在数据检索中生成候选的项目,例如,根据用户看过的电影找相关电影;根据用户看过最多的电影类型,推荐类型中前十电影;用户所在国家地区的前二十部电影。然后删除重复项及用户已购买项。列表可能生成数百个候选电影。
利用上一节中学习好的模型对候选的电影分别计算得分,然后排名(针对每部电影的V_m一般是提前计算好的,存在库中,只要针对用户计算V_u就行)
如何确定候选条目?推荐进行离线实验。关键是看候选项能否在排名时得到更高的分数,如果有的检索条件检索出的候选项在排名时很靠后,就可考虑去掉
基于内容过滤的TensorFlow实现
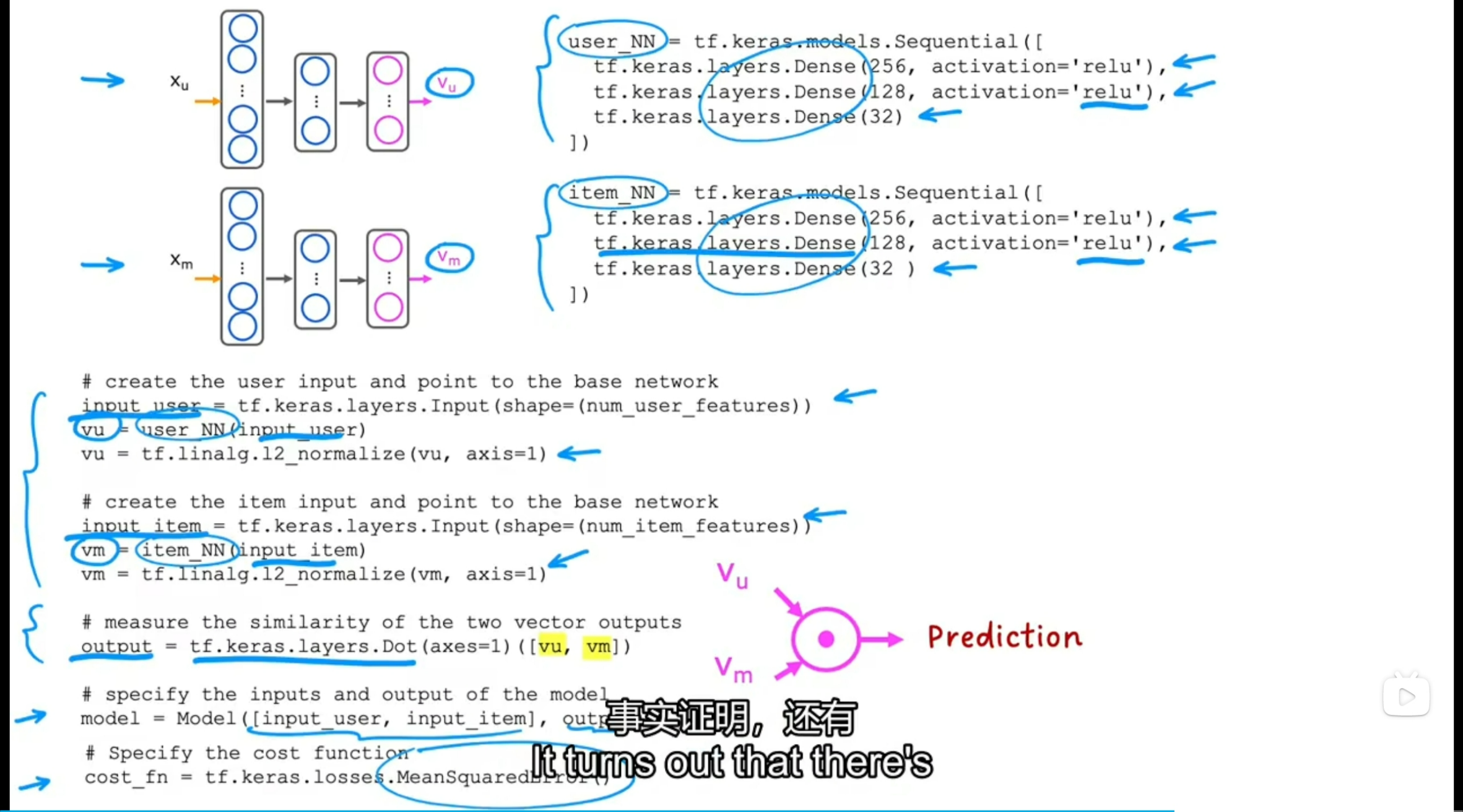
上面两部分是分别建立用户特征和项目特征的神经网络(全连接层,输出都是32个特征)
提取用户特征num_user_features赋值给user_NN网络,来计算用户向量vu,并进行归一化(归一化会提升整体性能)(可利用L2正则化进行归一化)。项目特征同样如此。然后计算点乘得最终预测结果output
表明模型的输入有用户特征、项目特征、预测结果output
训练模型用的代价函数是均方误差MSE
强化学习
在游戏人机中有很多应用
强化学习的关键输入是奖励函数。并没有告诉对象如何去做(没有标签),而是通过设立奖励函数让它自动计算,取得进步
应用:控制机器人、工厂优化(寻求更高效率和吞吐量)、金融交易(股票)、对抗类游戏
离散状态空间——以探测机器人为例
问题描述
在每个时间阶段中,机器人都处于某种状态s,它可以选择一个动作,并从而得到奖励R(s),状态随动作变为s'。注意,奖励R(s)是与状态s相关,而不是下一个状态s'相关
强化学习四要素:状态、动作、奖励、下一个状态
例子:

强化学习的回报
基于折扣系数和奖励值计算一套动作下来的总回报。折扣系数的作用就是让强化学习算法“不耐烦”,尽量少走几步结束。(更快获得奖励会获得更高的总回报值)

回报return由每一步的奖励reward决定,而奖励由状态和动作决定(对于每个状态,不同动作会导致不同reward)

策略函数
强化学习的目标是训练出一个策略函数,它以任意状态s为输入,映射为采取动作a(输出)
例如可以有4种策略,以最后一种策略为例,右边是策略函数
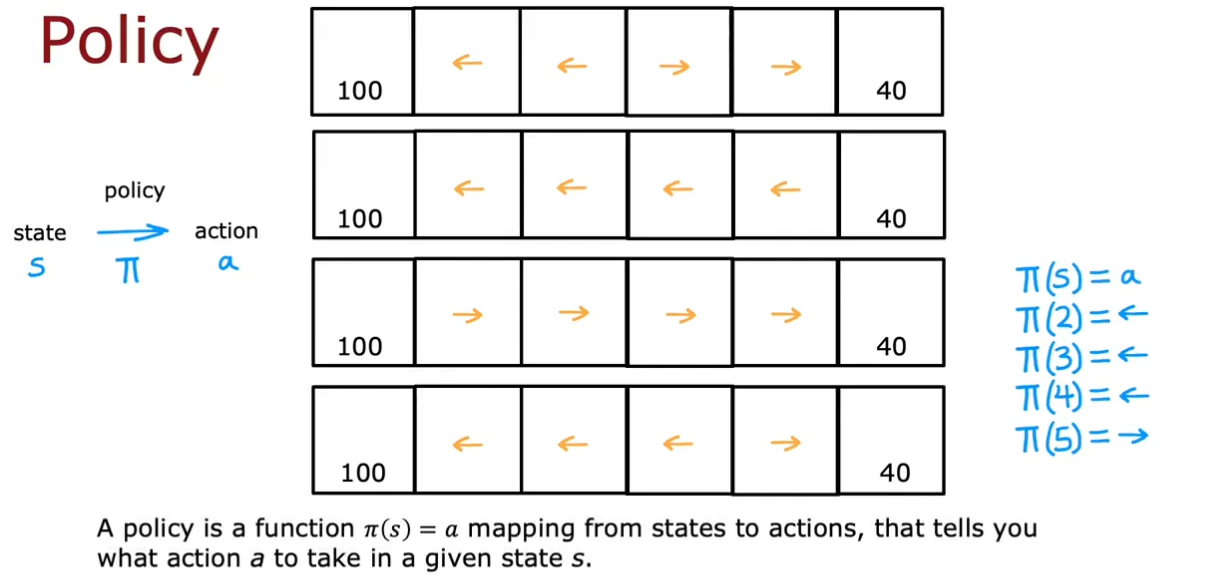
优化策略的目标是使回报最大化
马尔可夫决策过程
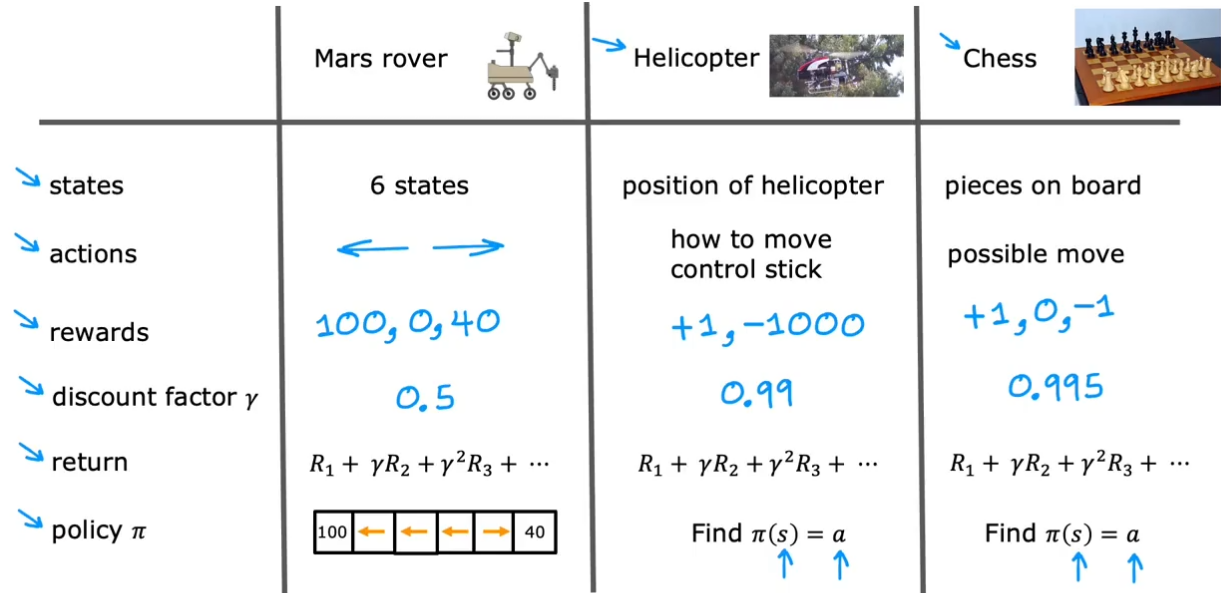
举了机器人、直升机、象棋三种例子,但这种形式是一样的,叫作马尔可夫决策过程(Markov Decision Process, MDP),指未来仅取决于当前状态,而不取决于当前状态之前发生的任何事情
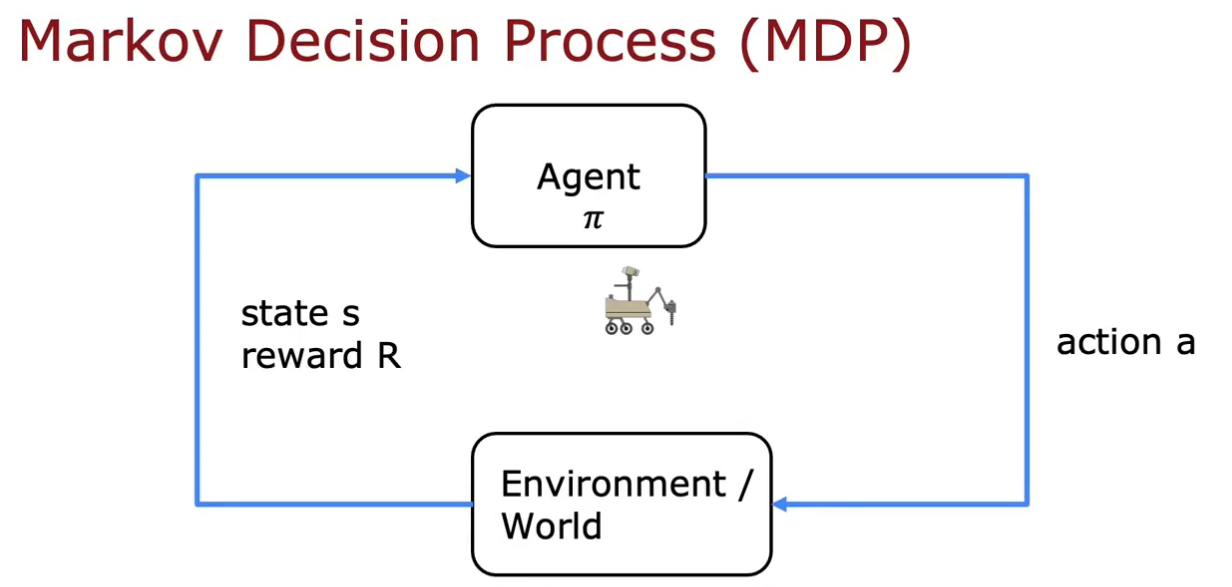
根据目标当前状态 s,基于策略选择动作a,世界或环境会发生变化,然后观察基于世界状态,目标的状态s及得到的奖励R
状态动作价值函数Q(s,a)
该函数基于状态s和动作a计算回报(假设其后面采取的都是最优策略,计算总回报)(至于为何能在获得最优策略前计算Q,后面会讲,会基于循环)。Q函数有时也叫Q*或最优Q函数(一个东西)
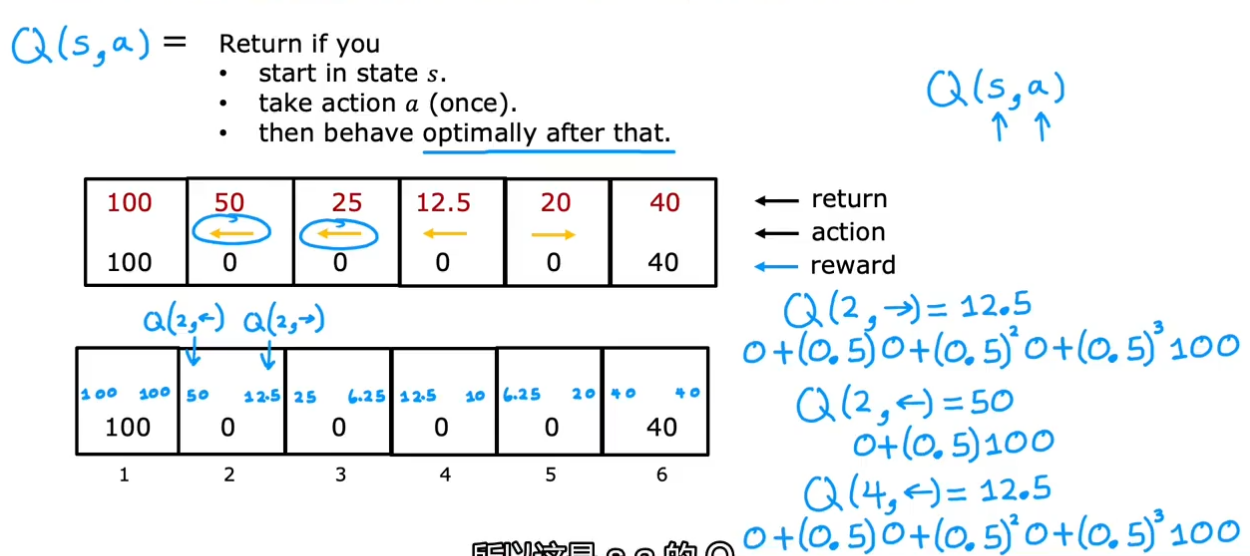
以状态2为例,如果向右,到状态3,那后面最优策略是一直向左走,所以计算是12.5
对每个状态,每个动作,都可计算得到Q
对于策略(基于状态选择动作),应选择能最大化Q(s,a)(总回报)的动作a
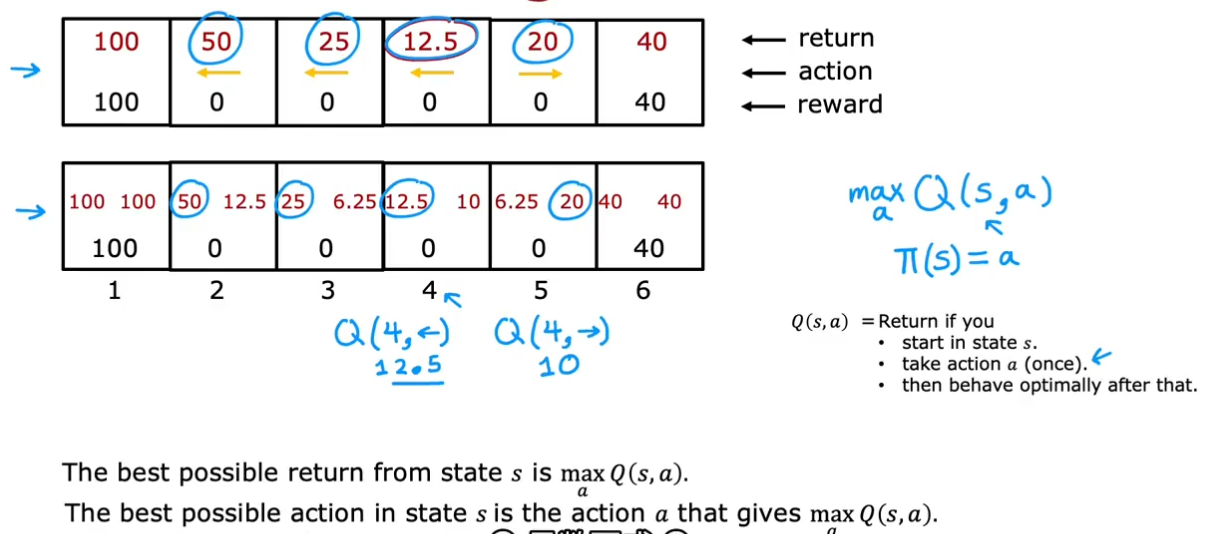
所以,Q计算和策略相对应,如果能基于s和a计算Q函数,就能得到策略
TensorFlow中实例
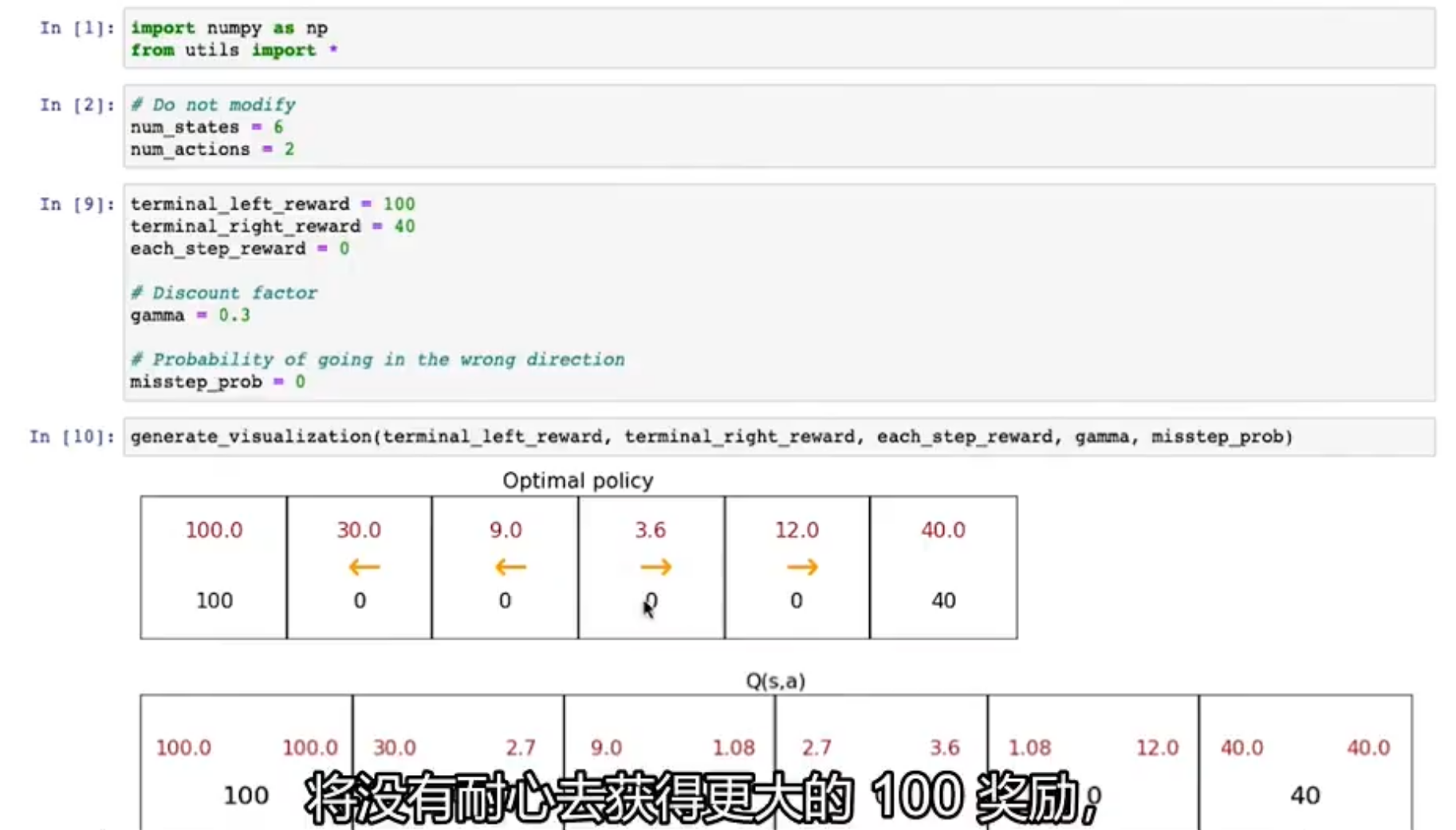
当折扣系数γ变大时,系统会变得有耐心去寻求更大奖励,当折扣系数小时,系统会没有耐心去寻求更大奖励而是用更少步骤获得奖励
贝尔曼方程(计算Q-强化学习最重要公式)
公式及计算方式:除了两头是直接等于R(s)

去捋一遍过程,就能发现实际上就是不断迭代的过程。

总回报包含两部分,一部分是马上得到的奖励R(s),第二部分是γ乘以下一状态s'的回报
随机马尔可夫决策
有时动作执行a会有部分概率没有按照预想的进行
在随机强化学习问题中,目标的不是最大化回报,而是要考虑随机失误的期望回报
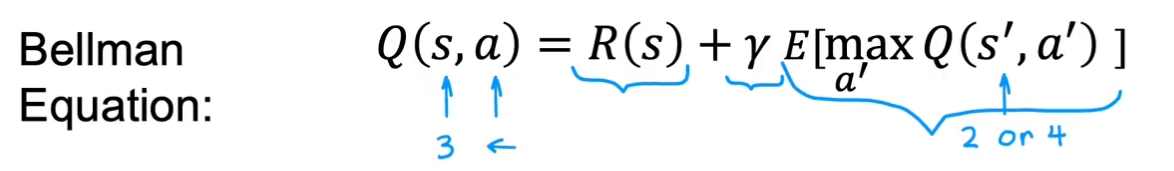
例如在状态3执行向左动作,有90%概率到2,10%概率到4,计算回报时就要计算期望
前面TensorFlow实例中,misstep_prob参数就表示失误概率。
连续状态空间应用——以登月器为例
例如在自动控制汽车、飞机中,状态s都是连续状态空间,包含x,y,z轴坐标,及各轴方向上速度、角速度等,这都是连续状态空间
简单问题描述
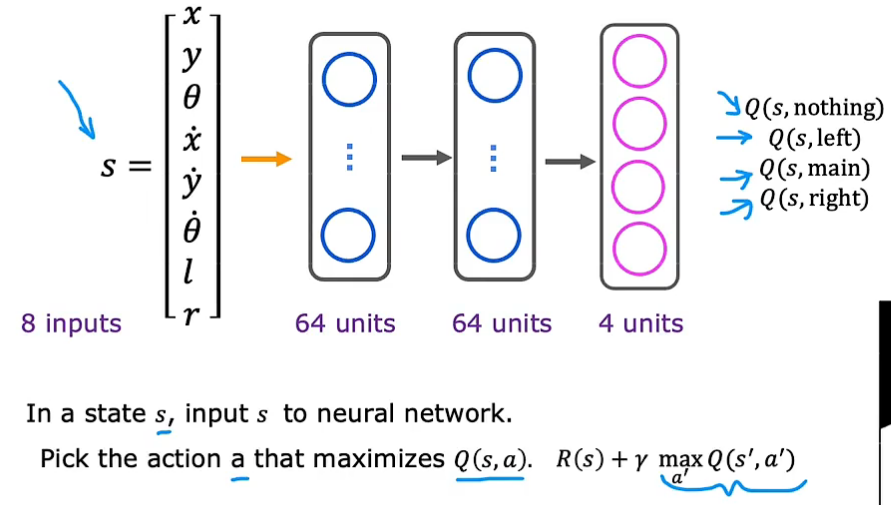
状态有8个量:x,y方向位移、速度,倾斜角、角速度,左脚落地l(0/1)、右脚落地r(0/1)
动作有4种:什么都不做,向下加速,向左加速,向右加速
目标是找到策略函数
学习状态值函数(强化学习中使用神经网络)
问题关键是训练神经网络来计算或近似状态动作价值函数Q(s,a)
训练模型:输入为状态8个数字+动作4个量(0/1 one-hot编码)

对每个状态s,使用神经网络分别计算4个动作下的Q,选取Q值最大的动作
训练模型的关键问题是x,y样本值如何获取(x为s和a,y为Q,主要是y的获取):把各种状态、各种动作都进行尝试。

输入x是s加上a,共12个数,输出y是由R(s)和s'计算而来,是一个数字。损失函数采用均方误差损失,尝试预测y
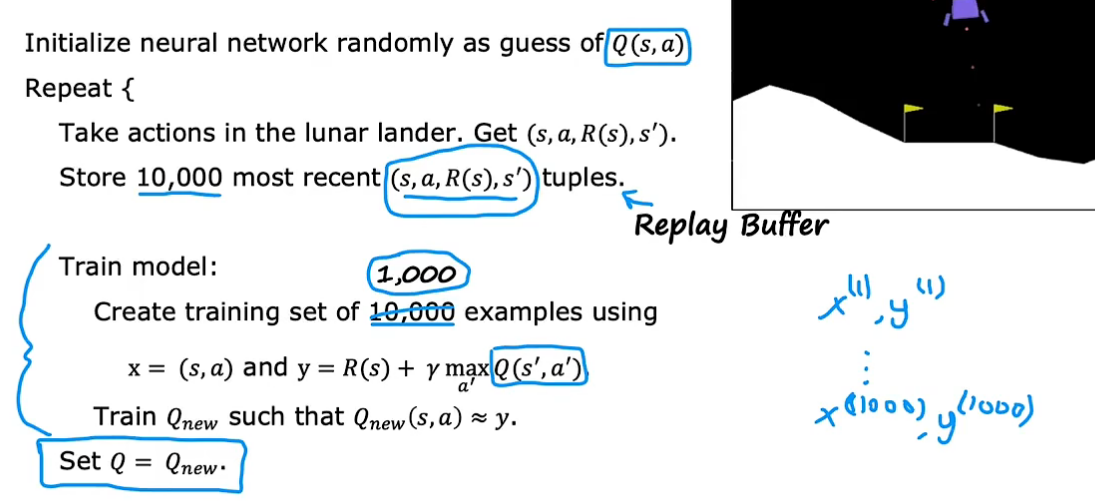
一开始,随机初始化神经网络,作为Q猜测(有点像在线性回归中,初始化参数,然后使用梯度下降来改进参数)
一开始,随机采取动作,存储最近的10000个不同s和a的元组信息 s,a,R(s),s'(回放缓冲区),y值计算中的Q最初是利用随机初始化的神经网络进行预测。然后利用这10000组样本数据训练神经网络模型(以x为输入,w b为参数的输出值去近似y),即新的Q预测,再利用新的Q去优化y值,再用于神经网络模型优化,从而不断提高对Q函数的猜测

该算法称为DQN算法(Deep Q-Network DQ网络),使用深度学习训练Q函数
算法改进:改进的神经网络架构
强化学习的神经网络输入是s,a,输出是回报Q
改进前,一个状态s,要分别计算4次的动作输入值12个,输出值1个

而改进为神经网络同时输出四个值会更加有效,且更方便选择最大值,可直接用于贝尔曼方程计算
Epsilon Greedy 策略(学习样本时如何选择动作)

方法2是更常用的方法(ε-贪婪策略)。在大多时候,选择使当前的Q(s,a)(神经网络训练出来的)最大化的动作a(贪婪行动),在极小情况下(偶尔)随机选择动作(探索行动)。
因为如果采用方法1,由于随机初始化的原因,可能始终不会尝试一些动作,但那些动作可能效果会很好。所以要用方法2,要把各动作都进行尝试。(神经网络可以逐步克服自己的刻板印象)
当ε=0.05时,贪婪动作占95%,探索动作占5%。
一般,学习刚开始时设置ε较大,一开始经常采取随机动作,然后逐渐减小ε,逐渐依赖对Q函数的改进估计来选择好的动作
在强化学习中,对参数选择更加挑剔,不合适的参数会使训练时间非常非常长
算法改进:小批量和软更新
使用小批量mini-batch可以提高算法运行速度,也可用于监督学习,软更新可以使强化学习更好的收敛
小批量:当样本数量非常大时,如果梯度下降的每一步都需要在全部样本中计算平均值,则运行很慢。使用小批量是每次梯度下降时,只关注一个batch的数据。当一个batch的样本数量少时,虽然一次更新时间更快,但很容易在迭代时向着错误的方向前进(噪声变大),远离全局最小值。

在强化学习中同样可以应用mini-batch,如虽然缓冲存储区中有10000个样本元组,但每次训练神经网络模型时可以只选取1000个(一个batch)来进行训练
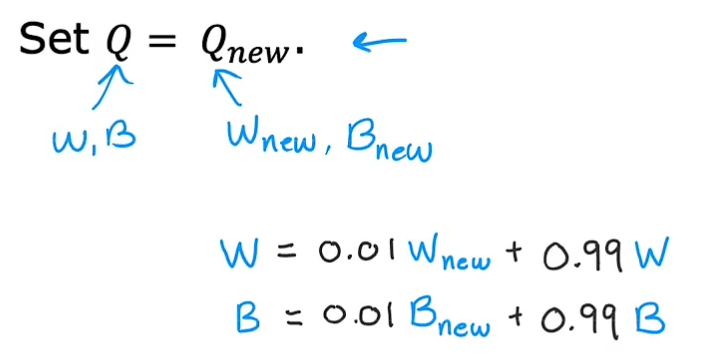
软更新:有可能新的神经网络Q函数效果还不如老的Q,软更新是将新模型和老模型的参数都考虑进来,根据权重相加,可以逐步更新Q,而不是一下让Q改变很多,这样降低了强化学习算法振荡或不收敛的可能性
强化学习发展现状
强化学习在模拟状态实现要比真实状态实现容易很多(环境问题)
应用要比监督学习和无监督学习少很多,但依然前景很大,是机器学习的支柱之一














 295
295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









