







course 1 线性回归
监督学习与无监督学习
监督学习
定义
给算法一个数据集,其中包含了“正确答案”,算法的目的是给出更多的正确答案
重要前提
-
监督学习假设数据是独立同分布产生的
-
监督学习假设输入 X 与输出 Y 遵循联合概率分布 P(X, Y)
-
监督学习与非监督学习的主要区别是, 在非监督学习中,类别信息是不被提前知道的,在学习的过程中使用的训练样本通常不具有标记信息
无监督学习
定义:
只给算法一个数据集,但是不给数据集的正确答案,由算法自行分类。
无监督学习中没有任何的标签或者是只有有相同的标签。所以我们已知数据集,却不知如何处理,也未告知每个数据点是什么。
针对数据集,无监督学习就能判断出数据有两个不同的聚集簇。这是一个,那是另一个,二者不同。是的,无监督学习算法可能会把这些数据分成两个不同的簇,所以也叫做聚类算法。
线性回归算法
回归这个词的意思是,我们在试着推测出这一系列的数据是连续值属性。
ℎ𝜃(𝑥) = 𝜃0 + 𝜃1𝑥,因为只含有一个特征/输入变量,这样的问题叫作单变量线性回归问题。
损失函数:在线性回归问题中,平方误差函数是最常用的手段。
特征,目标变量,训练样本
目标: 最小化代价函数,即minimize J(θ0, θ1)
训练,测试
训练/测试是一种测量模型准确性的方法。
训练模型意味着创建模型。
测试模型意味着测试模型的准确性。
线性模型
怎样区分线性和非线性:
1、线性linear指量与量之间按比例、成直线的关系,在数学上可以理解为一阶导数为常数的函数;
非线性non-linear则指不按比例、不成直线的关系,一阶导数不为常数。
2、线性的可以认为是1次曲线,比如y=ax+b ,即成一条直线;
非线性的可以认为是2次以上的曲线,比如y=ax2+bx+c,(x2是x的2次方),即不为直线的也可。
3、“线性”与“非线性”,常用于区别函数 y = f(x) 对自变量x的依赖关系。
线性函数即一次函数,其图像为一条直线。其它函数则为非线性函数,其图像不是直线。
线性模型和非线性模型区别:
1、线性模型可以是用曲线拟合样本,但是分类的决策边界一定是直线的,例如logistics模型。
2、区分是否为线性模型,主要是看一个乘法式子中自变量x前的系数w,如果w只影响一个x,那么此模型为线性模型。或者判断决策边界是否是线性的。
3.如果自变量x被两个以上的参数影响,那么此模型是非线性的!如:
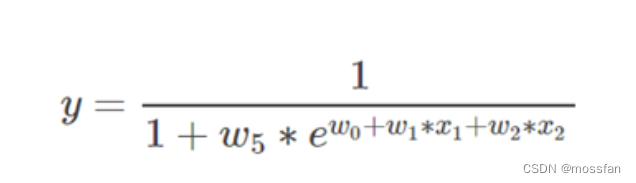
此模型是非线性模型,观察到x1不仅仅被参数w1影响,还被w5影响
线性模型与非线性模型图像:
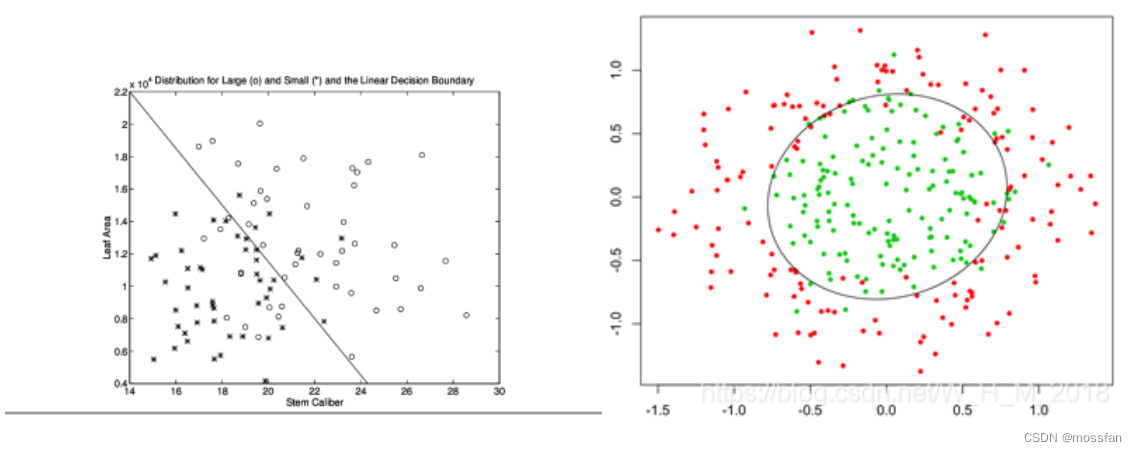
https://blog.csdn.net/W_H_M_2018/article/details/89343994
损失(代价)函数也被称为平方误差函数或者平方误差代价函数。
矩阵型损失函数:

梯度下降法
百度百科:
梯度下降是迭代法的一种,可以用于求解最小二乘问题(线性和非线性都可以)。在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法。在求解损失函数的最小值时,可以通过梯度下降法来一步步的迭代求解,得到最小化的损失函数和模型参数值。反过来,如果我们需要求解损失函数的最大值,这时就需要用梯度上升法来迭代了。在机器学习中,基于基本的梯度下降法发展了两种梯度下降方法,分别为随机梯度下降法和批量梯度下降法。
梯度:梯度实际上就是多变量微分的一般化。
如下图所示:
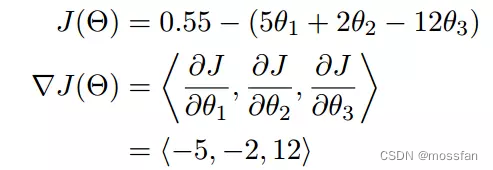
单变量函数的梯度下降:
我们假设有一个单变量的函数
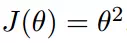
函数的微分
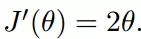
初始化,起点为
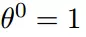
学习率为
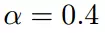
我们开始进行梯度下降的迭代计算过程:
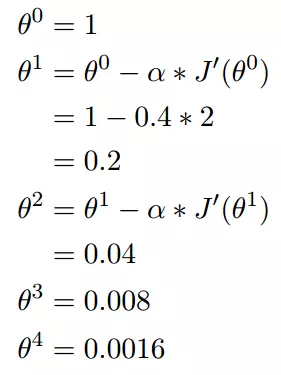
多变量函数的梯度下降:
我们假设有一个目标函数
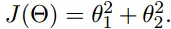
现在要通过梯度下降法计算这个函数的最小值。我们通过观察就能发现最小值其实就是 (0,0)点。但是接下来,我们会从梯度下降算法开始一步步计算到这个最小值
我们假设初始的起点为:
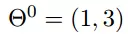
初始的学习率为: a = 0.1
函数的梯度为:
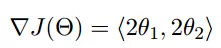
进行多次迭代:

矩阵向量化梯度下降
输入数据类型:
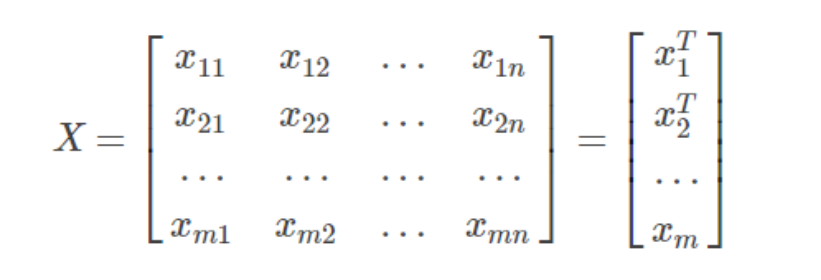
所以预测值为y ^ :
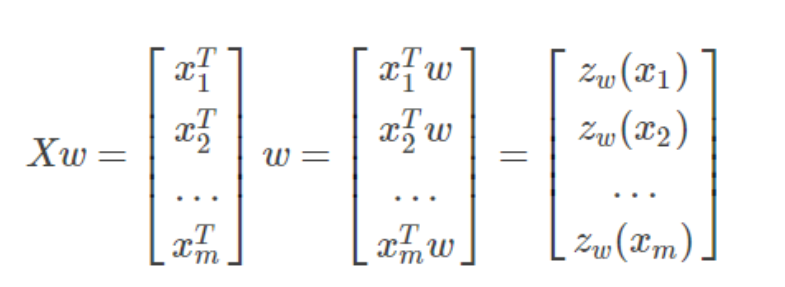
因此,预测值y^与真实值y之间的均方误差为:
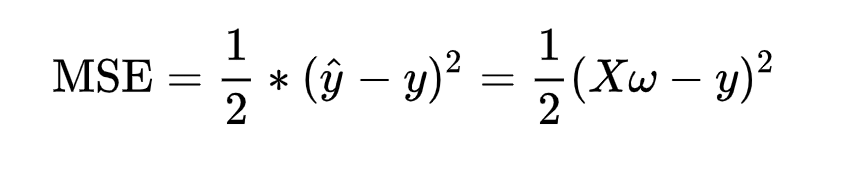
注:乘上1/2是为了后面求导的方便




https://blog.csdn.net/qq_41670466/article/details/89053810
https://www.jianshu.com/p/af118278955e
批量梯度下降算法
BGD是最原始的梯度下降算法,每一次迭代使用全部的样本,即权重的迭代公式中(公式中用θ代替θi),这里的m代表所有的样本,表示从第一个样本遍历到最后一个样本。
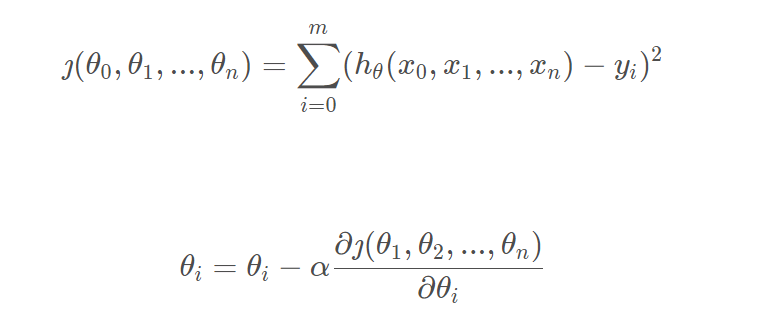
特点:
能达到全局最优解,易于并行实现
当样本数目很多时,训练过程缓慢
随机梯度下降算法
SGD的思想是更新每一个参数时都使用一个样本来进行更新,即上公式中m为1。每次更新参数都只使用一个样本,进行多次更新。这样在样本量很大的情况下,可能只用到其中的一部分样本就能得到最优解了。
但是,SGD伴随的一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向。
特点:
训练速度快
准确度下降,并不是最优解,不易于并行实现
小批量梯度下降算法
MBGD的算法思想就是在更新每一参数时都使用一部分样本来进行更新,也就是上公式中的m的值大于1小于所有样本的数量。
相对于随机梯度下降,Mini-batch梯度下降降低了收敛波动性,即降低了参数更新的方差,使得更新更加稳定。相对于批量梯度下降,其提高了每次学习的速度。并且其不用担心内存瓶颈从而可以利用矩阵运算进行高效计算。一般而言每次更新随机选择[50,256]个样本进行学习,但是也要根据具体问题而选择,实践中可以进行多次试验,选择一个更新速度与更次次数都较适合的样本数。mini-batch梯度下降可以保证收敛性,常用于神经网络中。
https://blog.csdn.net/Frank_LJiang/article/details/88931592
https://blog.csdn.net/Gamer_gyt/article/details/78806156
标题用均方差做损失函数
过拟合,欠拟合
对于深度学习或机器学习模型而言,我们不仅要求它对训练数据集有很好的拟合(训练误差),同时也希望它可以对未知数据集(测试集)有很好的拟合结果(泛化能力),所产生的测试误差被称为泛化误差。度量泛化能力的好坏,最直观的表现就是模型的过拟合(overfitting)和欠拟合(underfitting)。
欠拟合:
欠拟合是指模型不能在训练集上获得足够低的误差。换句换说,就是模型复杂度低,模型在训练集上就表现很差,没法学习到数据背后的规律。
解决欠拟合:
欠拟合基本上都会发生在训练刚开始的时候,经过不断训练之后欠拟合应该不怎么考虑了。但是如果真的还是存在的话,可以通过增加网络复杂度或者在模型中增加特征,这些都是很好解决欠拟合的方法。
过拟合:
过拟合是指训练误差和测试误差之间的差距太大。换句换说,就是模型复杂度高于实际问题,模型在训练集上表现很好,但在测试集上却表现很差。模型对训练集"死记硬背"(记住了不适用于测试集的训练集性质或特点),没有理解数据背后的规律,泛化能力差。
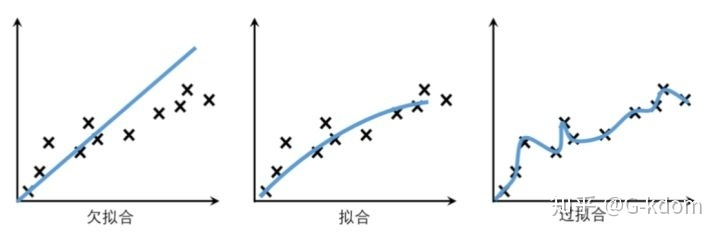
造成过拟合原因主要有以下几种:
1、训练数据集样本单一,样本不足。如果训练样本只有负样本,然后那生成的模型去预测正样本,这肯定预测不准。所以训练样本要尽可能的全面,覆盖所有的数据类型。
2、训练数据中噪声干扰过大。噪声指训练数据中的干扰数据。过多的干扰会导致记录了很多噪声特征,忽略了真实输入和输出之间的关系。
3、模型过于复杂。模型太复杂,已经能够“死记硬背”记下了训练数据的信息,但是遇到没有见过的数据的时候不能够变通,泛化能力太差。我们希望模型对不同的模型都有稳定的输出。模型太复杂是过拟合的重要因素。
防止过拟合:
要想解决过拟合问题,就要显著减少测试误差而不过度增加训练误差,从而提高模型的泛化能力。
- 获取和使用更多的数据(数据集增强)——解决过拟合的根本性方法
- 采用合适的模型(控制模型的复杂度)
- 降低特征的数量
- L1 / L2 正则化
- Dropout
- Early stopping(提前终止)
平方误差
https://zhuanlan.zhihu.com/p/72038532
普通线性回归和局部加权线性回归的差异
线性回归的一个问题是可能出现欠拟合现象。显而易见,模型欠拟合就不能取得好的预测效果,如下图,线性拟合并不能挖掘出数据的一些潜在规律。
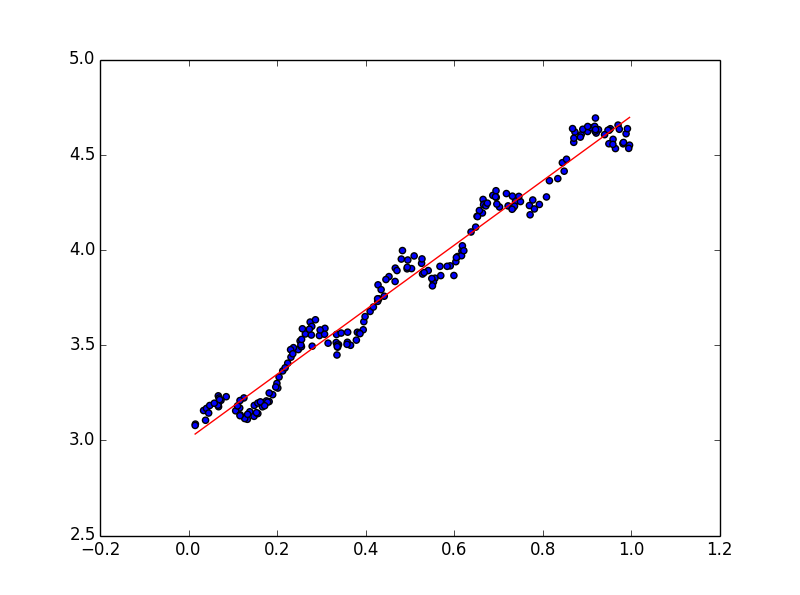
一个常见的解决方法是局部加权回归。该算法的思想是给待预测点附近的每一个点赋予一定的权重(离待预测点越近权重越大,越远权重越小,即以待预测点附近点的一个子集来进行普通的线性回归)

https://blog.csdn.net/u010561073/article/details/56835612
course 2 逻辑回归
逻辑回归算法
逻辑回归(Logistic Regression, LR)模型其实仅在线性回归的基础上,套用了一个逻辑函数,但也就由于这个逻辑函数,使得逻辑回归模型成为了机器学习领域一颗耀眼的明星,更是计算广告学的核心。
我们对线性回归的结果做一个在函数g上的转换,可以变化为逻辑回归。这个函数g在逻辑回归中我们一般取为sigmoid函数,形式如下:
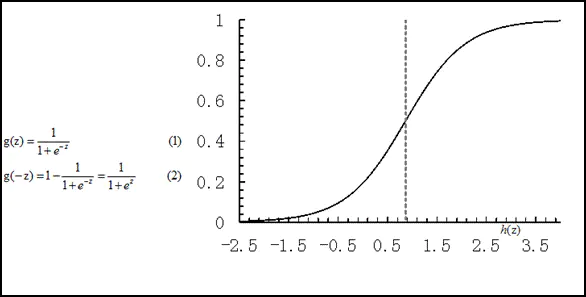
它有一个非常好的性质,即当z趋于正无穷时,g(z)趋于1,而当z趋于负无穷时,g(z)趋于0,这非常适合于我们的分类概率模型。
另外,它还有一个很好的导数性质: g′(z)=g(z)(1−g(z))。

https://www.jianshu.com/p/1fd6e5e8f0da
特征和标签
例如,如果我们试图为电子邮件建立一个垃圾邮件分类器,那么x(i)可能是一个电子邮件的一些特征,如果它是一个垃圾邮件,y可能是1,否则是0。0也被称为负类,1也被称为正类,它们有时也用符号“-”和“+”来表示。给定x(i),相应的y(i)也被称为训练示例的标签。
特点:数据标签离散非连续
逻辑损失函数求解步骤

似然函数,对数函数
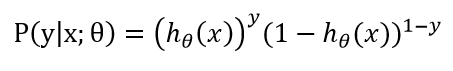
此公式便为伯努利分布,这里的y∈{0, 1}.
现在我们就可以把问题转化为求logistic回归的最佳回归系数。由于logistic回归可以被看作是一种概率模型,且输出y发生的概率与回归参数θ有关,因此我们可以对θ进行最大似然估计(Maximum Likelihood Estimate),使得y发生的概率最大,此时的θ便是最优的回归系数。对整个数据集求似然函数得:
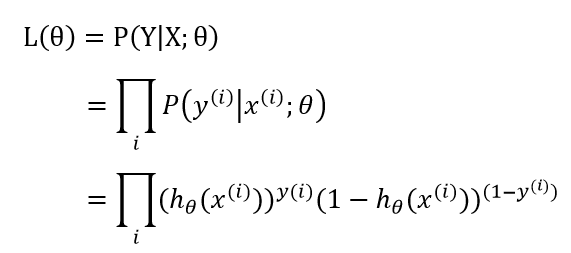
为了计算方便,取似然函数的对数函数:
最大似然函数:用于在已知一些参数的情况下,预测接下来在观测上所得到的结果
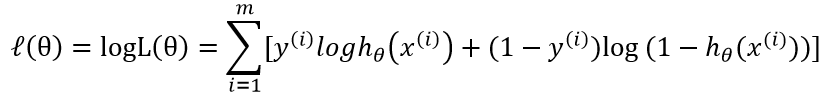
如此,我们就可以使用如下的式子进行梯度上升算法迭代更新θ的取值:
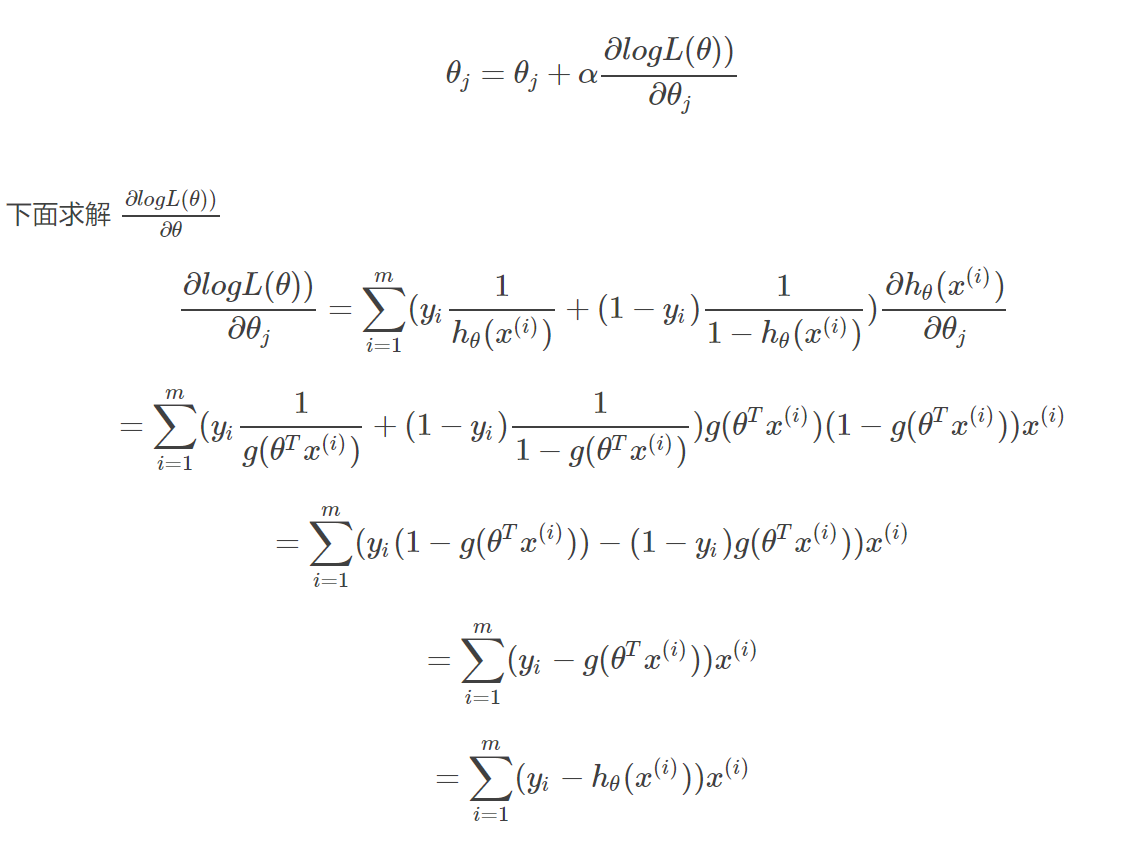
所以权重的迭代更新式为:
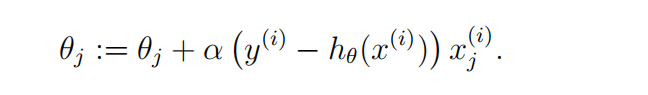
其中α为梯度上升步长(学习率),与梯度下降一样,决定了函数上升的快慢。
https://blog.csdn.net/HerosOfEarth/article/details/51988193
https://blog.csdn.net/u011197534/article/details/53492915
梯度上升
批量梯度上升
批量梯度上升每进行一次迭代更新就会计算所有样本,因此得到的模型正确率比较高,但同时计算复杂度高,算法耗时。计算过程如下:
1.首先根据权重和训练样本计算估计值
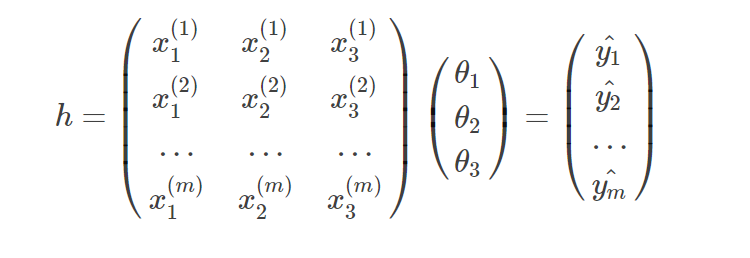
2.计算误差
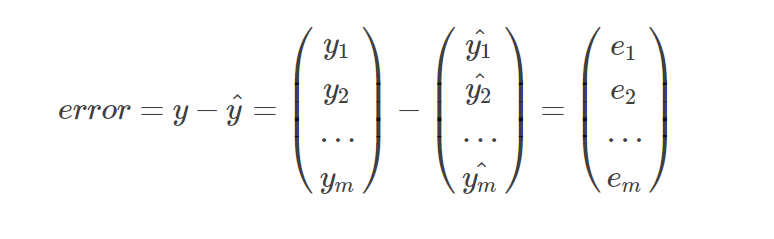
3.迭代更新
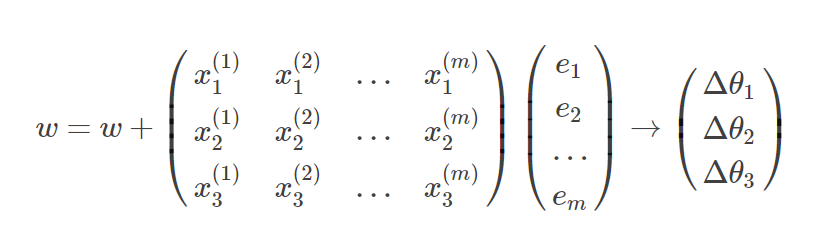
随机梯度上升
根据样本数量进行迭代,每计算一个样本就进行一次更新,过程如下:
1.计算x(i)样本对应的估计值
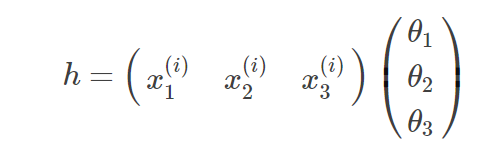
2.计算误差
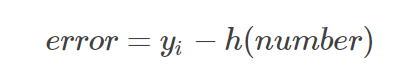
注意,此处的误差是个数,不再是个向量
3.迭代更新
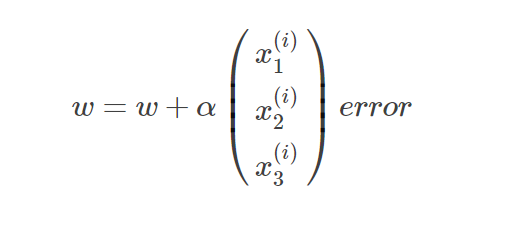
牛顿法
牛顿法是一种在实数域和复数域上近似求解方程的方法。方法使用函数f (x)的泰勒级数的前面几项来寻找方程f (x) = 0的根。
牛顿法最大的特点就在于它的收敛速度很快。

由于牛顿法是基于当前位置的切线来确定下一次的位置,所以牛顿法又被很形象地称为是"切线法"。牛顿法的搜索路径(二维情况)如下图所示:

本质上去看,牛顿法是二阶收敛,梯度下降是一阶收敛,所以牛顿法就更快。如果更通俗地说的话,比如你想找一条最短的路径走到一个盆地的最底部,梯度下降法每次只从你当前所处位置选一个坡度最大的方向走一步,牛顿法在选择方向时,不仅会考虑坡度是否够大,还会考虑你走了一步之后,坡度是否会变得更大。所以,可以说牛顿法比梯度下降法看得更远一点,能更快地走到最底部。(牛顿法目光更加长远,所以少走弯路;相对而言,梯度下降法只考虑了局部的最优,没有全局思想。)
https://zhuanlan.zhihu.com/p/158813090
问题
1.在逻辑损失函数求解步骤中L为什么是累乘而不可以是平方差?
自己答:本质上是由线性回归和逻辑回归的区别带来的,损失函数是为了拟合最佳解决问题的方法。
2.可以用局部线性回归来完成逻辑回归吗?
course 3 无监督学习
无监督学习定义
在聚类问题中,我们给出一个训练集{x1,…,xm},期望将数据分成一些有凝聚力的“簇”。这里的xi通常属于实数;但是数据集并没有标签y给出,所以这就是一个无监督学习问题。
K-means算法
最常用的基于欧式距离的聚类算法,其认为两个目标的距离越近,相似度越大。
K的数量选择最好的办法:手动选择。
牧师-村民模型
K-means 有一个著名的解释:牧师—村民模型:
有四个牧师去郊区布道,一开始牧师们随意选了几个布道点,并且把这几个布道点的情况公告给了郊区所有的村民,于是每个村民到离自己家最近的布道点去听课。
听课之后,大家觉得距离太远了,于是每个牧师统计了一下自己的课上所有的村民的地址,搬到了所有地址的中心地带,并且在海报上更新了自己的布道点的位置。
牧师每一次移动不可能离所有人都更近,有的人发现A牧师移动以后自己还不如去B牧师处听课更近,于是每个村民又去了离自己最近的布道点……
就这样,牧师每个礼拜更新自己的位置,村民根据自己的情况选择布道点,最终稳定了下来。
我们可以看到该牧师的目的是为了让每个村民到其最近中心点的距离和最小。
算法原理
该算法的内环重复执行两个步骤:
(i)将每个训练示例x(i)“分配”到最近的聚类质心µj,
(ii)将每个聚类质心µj移动到分配给它的点的平均值。
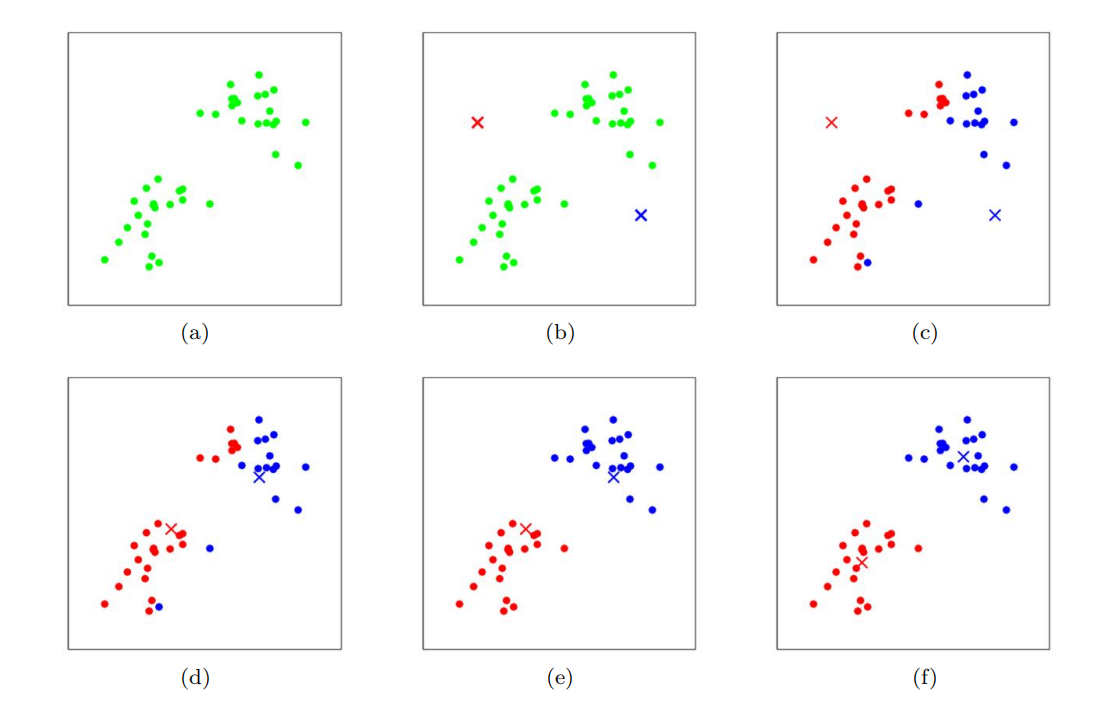
训练例子以点表示,簇质心以叉表示。(a)原始数据集。(b)随机初始聚类质心(在本例中,不选择等于两个训练示例)。(c-f)运行k-means的两次迭代的说明。在每次迭代中,我们将每个训练示例分配给最近的聚类质心(通过“绘制”训练示例与分配给的聚类质心相同的颜色显示);然后我们将每个聚类质心移动到分配给它的点的平均值。(最佳颜色颜色)
缺点
失真函数J是非凸函数,因此在J上的坐标下降不能保证收敛到全局最小值。换句话说,k-means可能容易受到局部最优值的影响。通常k-means可以正常工作,尽管如此,它还是能想出非常好的集群。但是,如果您担心陷入糟糕的局部最小值,一个常见的事情是运行k-均值多次(使用不同的随机初始值µj)。然后,从所有发现的不同的聚类中,选出失真J(c,µ)最低的一个。
算法流程

https://zhuanlan.zhihu.com/p/78798251
周志华《机器学习》
https://wuxian.blog.csdn.net/article/details/80107795
混合高斯算法(*未理解)
GMM模型
高斯混合模型(Gaussian Mixed Model)指的是多个高斯分布函数的线性组合,理论上GMM可以拟合出任意类型的分布,通常用于解决同一集合下的数据包含多个不同的分布的情况(或者是同一类分布但参数不一样,或者是不同类型的分布,比如正态分布和伯努利分布)。

EM算法(Expectation-Maximization algorithm):
EM算法是一种迭代算法,主要有两个步骤。应用于我们的问题,在e步中,它试图“猜测”z(i)的值。在m步中,它根据我们的猜测更新了我们模型的参数。因为在m步中,我们假装第一部分的猜测是正确的,所以最大化就变得容易了。
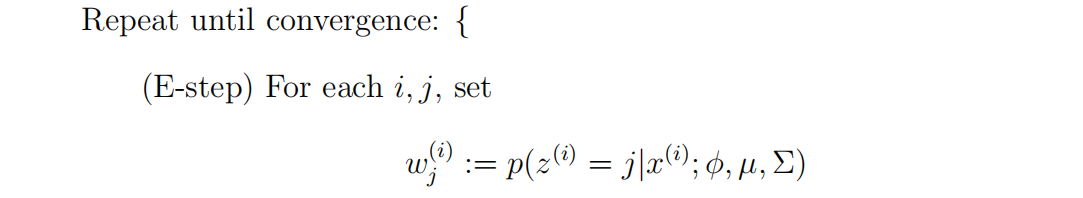

在e步骤中,我们计算我们的参数z(i)的后验概率,给定x(i),并使用我们的参数的当前设置。
李航老师《统计学习方法》
https://blog.csdn.net/xmu_jupiter/article/details/50889023
两算法异同点
GMM:
- 先计算所有数据对每个分模型的响应度
- 根据响应度计算每个分模型的参数
- 迭代
K-means:
- 先计算所有数据对于K个点的距离,取距离最近的点作为自己所属于的类
- 根据上一步的类别划分更新点的位置(点的位置就可以看做是模型参数)
- 迭代
可以看出GMM和K-means还是有很大的相同点的。GMM中数据对高斯分量的响应度就相当于K-means中的距离计算,GMM中的根据响应度计算高斯分量参数就相当于K-means中计算分类点的位置。然后它们都通过不断迭代达到最优。不同的是:GMM模型给出的是每一个观测点由哪个高斯分量生成的概率,而K-means直接给出一个观测点属于哪一类。
https://blog.csdn.net/xmu_jupiter/article/details/50889023
簇
聚类是典型的无监督学习方法,通过无标记的训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础。常见的其他无监督学习任务还有密度估计、异常检测等。
聚类试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个“簇”(cluster)。通过这样的划分每个簇可能对应于一些潜在的概念,这些概念对聚类算法而言事先是未知的,聚类过程仅能自动形成簇结构,簇所对应的概念语义需由使用者来把握和命名。
https://zhuanlan.zhihu.com/p/70756804
高斯函数
正态分布是高斯概率分布。高斯概率分布是反映中心极限定理原理的函数,该定理指出当随机样本足够大时,总体样本将趋向于期望值并且远离期望值的值将不太频繁地出现。
高斯函数广泛应用于统计学领域,用于表述正态分布,在信号处理领域,用于定义高斯滤波器,在图像处理领域,二维高斯核函数常用于高斯模糊Gaussian Blur,在数学领域,主要是用于解决热力方程和扩散方程,以及定义Weiertrass Transform。
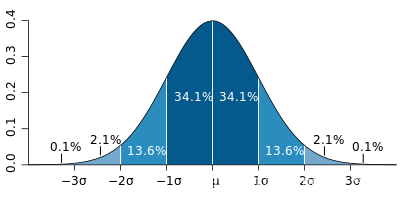
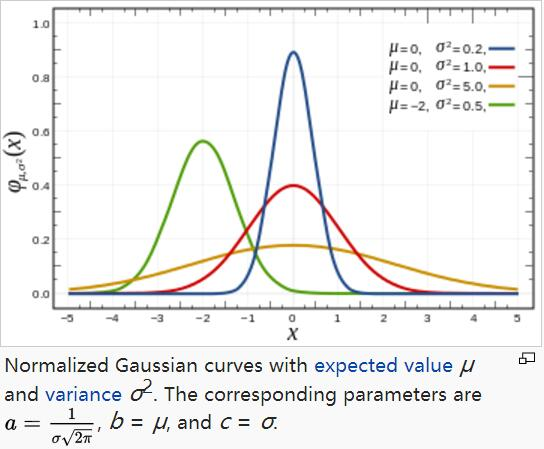
μ指的是期望,决定了正态分布的中心对称轴
σ指的是方差决定了正态分布的胖瘦,方差越大,正态分布相对的胖而矮
方差:(x指的是平均数)
标准差:方差开根号
任何正态分布的概率密度从负无穷到正无穷积分结果都为1
一维高斯函数
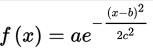
对于任意的实数a,b,c,是以著名数学家Carl Friedrich Gauss的名字命名的。高斯的一维图是特征对称“bell curve”形状,a是曲线尖峰的高度,b是尖峰中心的坐标,c称为标准方差,表征的是bell钟状的宽度。
二维高斯函数
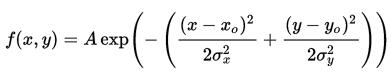
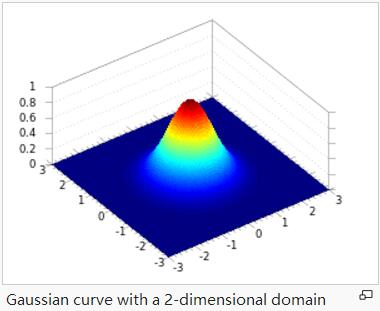
A是幅值,x。y。是中心点坐标,σx σy是方差,图示如下,A = 1, xo = 0, yo = 0, σx = σy = 1
https://blog.csdn.net/qinglongzhan/article/details/82348153
PCA算法(Principal components analysis)
主成分分析(PCA),它也试图识别数据近似所在的子空间。PCA将更直接地做到这一点,并且只需要一个特征向量计算(使用Matlab中的eig函数很容易完成),而不需要求助于EM。
PCA(Principal Component Analysis),即主成分分析方法,是一种使用最广泛的数据降维算法(非监督的机器学习方法)。
其最主要的用途在于“降维”,通过析取主成分显出的最大的个别差异,发现更便于人类理解的特征。也可以用来削减回归分析和聚类分析中变量的数目。
为什么要做主成分分析
在很多场景中需要对多变量数据进行观测,在一定程度上增加了数据采集的工作量。更重要的是:多变量之间可能存在相关性,从而增加了问题分析的复杂性。
如果对每个指标进行单独分析,其分析结果往往是孤立的,不能完全利用数据中的信息,因此盲目减少指标会损失很多有用的信息,从而产生错误的结论。
因此需要找到一种合理的方法,在减少需要分析的指标同时,尽量减少原指标包含信息的损失,以达到对所收集数据进行全面分析的目的。由于各变量之间存在一定的相关关系,因此可以考虑将关系紧密的变量变成尽可能少的新变量,使这些新变量是两两不相关的,那么就可以用较少的综合指标分别代表存在于各个变量中的各类信息。主成分分析与因子分析就属于这类降维算法。
步骤
步骤(1-2)忽略数据的平均值
可以忽略对于已知平均值为零的数据(例如,与语音或其他声学信号对应的时间序列)。
(3-4)重新调整每个坐标
使其具有单位方差,以确保不同的属性都在相同的“尺度”上被处理。例如,如果x1是汽车的最大速度,单位为每里(取高十或低百),x2是座位数量(取2-4左右),那么这种重正化重新调整不同的属性,使它们更具可比性。
如果我们预先知道不同的属性都在相同的尺度上,那么就可以省略步骤(3-4)。
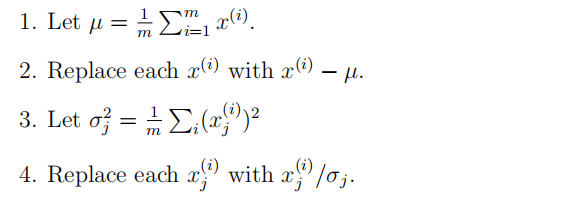
二维降一维
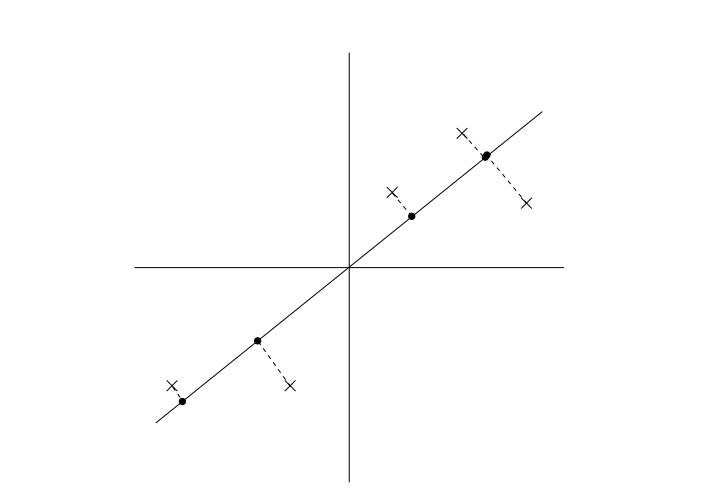
注意:与线性回归损失函数的区别
https://blog.csdn.net/weixin_43312354/article/details/10565330
多维向量降维
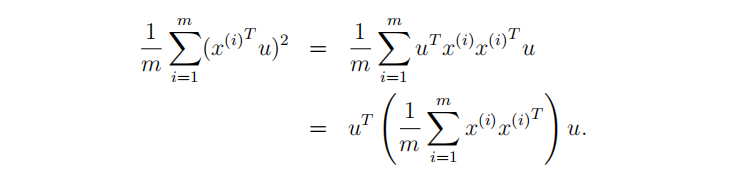
原理:线性代数–取m个n维向量的矩阵左乘其转置矩阵,得到m*m阶矩阵
course 4 强化学习
强化学习定义
强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。
在强化学习框架中,我们将只提供我们的算法一个奖励函数,它指示学习代理何时做得好,当它做得不好。然后,学习算法的工作将是找出如何随时间选择行动,从而获得巨大的奖励。
强化学习系统一般包括四个要素:策略(policy),奖励(reward),价值(value)以及环境或者说是模型(model)。
策略
策略定义了智能体对于给定状态所做出的行为,换句话说,就是一个从状态到行为的映射,事实上状态包括了环境状态和智能体状态,这里我们是从智能体出发的,也就是指智能体所感知到的状态。因此我们可以知道策略是强化学习系统的核心,因为我们完全可以通过策略来确定每个状态下的行为。我们将策略的特点总结为以下三点:
- 策略定义智能体的行为
- 它是从状态到行为的映射
- 策略本身可以是具体的映射也可以是随机的分布
奖励(Reward)
奖励信号定义了强化学习问题的目标,在每个时间步骤内,环境向强化学习发出的标量值即为奖励,它能定义智能体表现好坏,类似人类感受到快乐或是痛苦。因此我们可以体会到奖励信号是影响策略的主要因素。我们将奖励的特点总结为以下三点:
- 奖励是一个标量的反馈信号
- 它能表征在某一步智能体的表现如何
- 智能体的任务就是使得一个时段内积累的总奖励值最大
价值(Value)
接下来说说价值,或者说价值函数,这是强化学习中非常重要的概念,与奖励的即时性不同,价值函数是对长期收益的衡量。我们常常会说“既要脚踏实地,也要仰望星空”,对价值函数的评估就是“仰望星空”,从一个长期的角度来评判当前行为的收益,而不仅仅盯着眼前的奖励。结合强化学习的目的,我们能很明确地体会到价值函数的重要性,事实上在很长的一段时间内,强化学习的研究就是集中在对价值的估计。我们将价值函数的特点总结为以下三点:
- 价值函数是对未来奖励的预测
- 它可以评估状态的好坏
- 价值函数的计算需要对状态之间的转移进行分析
环境(模型)
也叫外界环境,它是对环境的模拟,举个例子来理解,当给出了状态与行为后,有了模型我们就可以预测接下来的状态和对应的奖励。但我们要注意的一点是并非所有的强化学习系统都需要有一个模型,因此会有基于模型(Model-based)、不基于模型(Model-free)两种不同的方法,不基于模型的方法主要是通过对策略和价值函数分析进行学习。我们将模型的特点总结为以下两点:
- 模型可以预测环境下一步的表现
- 表现具体可由预测的状态和奖励来反映
https://blog.csdn.net/weixin_45560318/article/details/112981006
MDP过程 Markov decision processes
马尔可夫决策过程(MDPs)以安德烈马尔可夫的名字命名 ,针对一些决策的输出结果部分随机而又部分可控的情况,给决策者提供一个决策制定的数学建模框架。MDPs对通过动态规划和强化学习来求解的广泛的优化问题是非常有用的。
马尔可夫决策过程是一个元组(S、a、{Psa}、γ、R),其中:
- S是一组状态。(例如,在自主直升机飞行中,S可能是直升机所有可能的位置和方向的集合。)
- A是一组动作。(例如,可以推直升机控制杆的所有可能的方向集合。)
- Psa是状态转移的概率。对于每个状态的∈S和动作∈a,Psa是状态空间上的分布。简单地说,Psa给出了如果我们在状态s中采取行动a,我们将过渡到什么状态的分布。
- γ∈[0,1)被称为折扣因子。
- R:S×A7→R是奖励函数。(奖励有时也只写成状态S的函数,在这种情况下,我们将有R:S7→R)。
MDP的动态过程如下:我们在某些状态s0开始,然后选择在MDP中选择一些动作a0∈a。由于我们的选择,MDP的状态随机过渡到某个后继状态s1,根据s1∼Ps0a0绘制。然后,我们可以选择另一个动作a1。由于这个动作,状态再次转换,现在转换到一些s2∼Ps1a1。然后我们选择一个2,以此类推。。
我们可以这样表示这个过程:
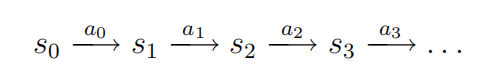
在访问状态序列s0,s1,…对于动作a0,a1,…,,我们的总收益为
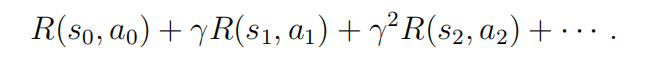
或者,当我们把奖励仅仅作为状态的函数来书写时,这就变成了
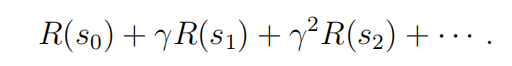
在我们的大部分开发中,我们将使用更简单的状态奖励R(s),尽管推广到状态动作奖励R(s,a)没有提供特殊的困难。
我们在强化学习中的目标是随着时间的推移而选择行动,以最大化总收益的期望值:
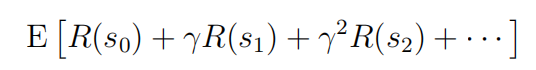
策略是任意函数π:S→A反映了从状态到所映射的动作。我们说,如果我们处于状态s时,我们采取=π(s),我们正在执行一些策略π。我们还定义了策略π的值函数
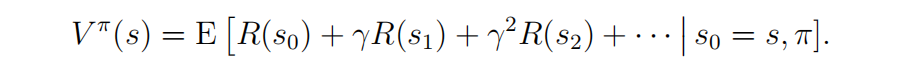
















 1477
1477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











