






补充知识
代码
/*
* 一元线性回归
* 用于拟合 y = 0.5x + 0.1
*/
public class SingleRegression {
//随机数种子,用于结果复现
private static final int seed = 12345;
//对于每个miniBatch的迭代次数
private static final int iterations = 10;
//epoch数量(全部数据的训练次数)
private static final int nEpochs = 20;
//一共生成多少样本点
private static final int nSamples = 1000;
//Batch size: i.e., each epoch has nSamples/batchSize parameter updates
private static final int batchSize = 100;
//网络模型学习率
private static final double learningRate = 0.01;
//随机数据生成的范围
private static int MIN_RANGE = 0;
private static int MAX_RANGE = 3;
private static final Random rng = new Random(seed);
public static void main(String[] args) {
//Create the network
int numInput = 1;
int numOutputs = 1;
/*
神经网络的配置
我们需要配置神经网络的超参数->为什么叫超参数呢?
超参数 -> 用于辅助模型学习参数的参数 -> hyper-parameter -> 超参数
学习的参数是什么? y = ax + b
其中的x,y是已知的,这是用于神经网络的训练样本。
参数 a,b是未知的,所以a,b是我们神经网络需要学习的参数
同时我们需要配置超参数来辅助神经网络学习到a 和 b这两个参数
*/
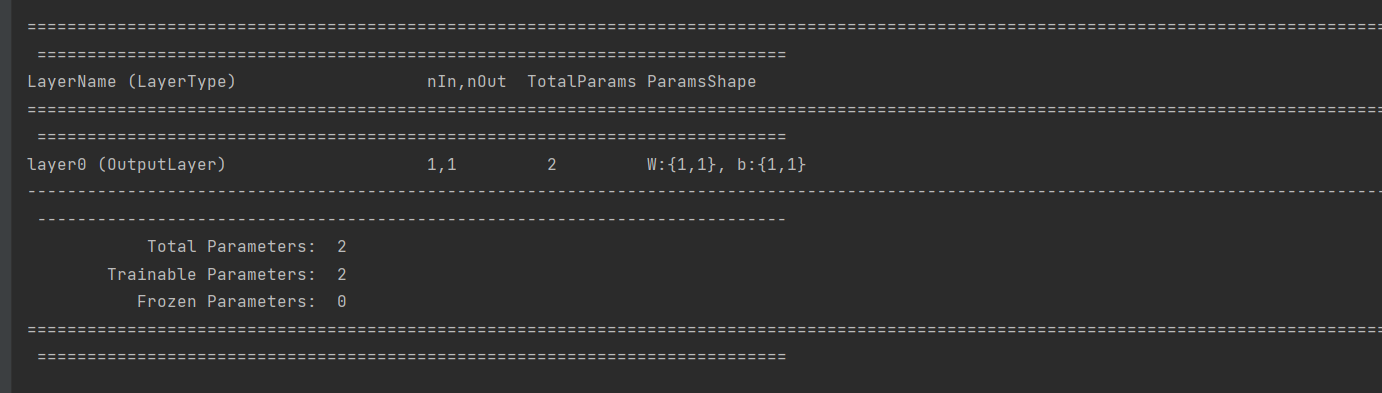
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
/*
* 随机种子 -> 随机数生成通常需要一个起点,我们所生成的随机数都是伪随机数。
* 因为神经网络训练时,模型的初试权重和偏置是随机生成的
* 我们需要随机数种子保证每次初始化的权重大体一致
* 这样可以保证模型结果的可复现性
* 只有模型结果可复现->进行神经网络的调参->我们的调参对于模型效果提升是有意义的
*/
.seed(seed)
/*
* 找方向
*/
.optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT)
/*
* 对神经网络的权重进行随机初始化
* 随机的权重要比全0的权重对神经网络训练更有意义
*/
.weightInit(WeightInit.XAVIER)
/*
* 优化算法
* tf,keras -> optimizer
* 迈步子
*
* 学习率迈步子的大小
* 去吴恩达->网易云课堂->微专业
*/
.updater(new Sgd(learningRate))
.list()
.layer(0, new OutputLayer.Builder(LossFunctions.LossFunction.MSE)
/*
* y = x
* None
*/
.activation(Activation.IDENTITY)
/*
* 上一层输出
*/
.nIn(numInput)
/*
* 当前层神经单元的个数
*/
.nOut(numOutputs).build())
/*
* 预训练
*/
.pretrain(false)
/*
* 反向传播
*/
.backprop(true).build();
// 使用 MultiLayerNetwork 对我们的 conf 进行一个包装
// 对神经网络进行了构建
MultiLayerNetwork net = new MultiLayerNetwork(conf);
// 必须调用 init() 方法
// 是对于模型参数的初始化
net.init();
System.out.println(net.summary());
/*
* 有监听器,用于监听我们神经网络训练时候的状态
* 主要是用于监听我们神经网络训练时候的损失函数的得分
* 目前参数为1,则说明网络每训练一次,就会打印一次损失函数的得分
*/
// net.setListeners(new ScoreIterationListener(1));
DataSetIterator iterator = getTrainingData(batchSize, rng);
// 训练整个数据集nEpochs次
for( int i=0; i<nEpochs; i++ ){
iterator.reset();
/*
* 用于训练模型
*/
net.fit(iterator);
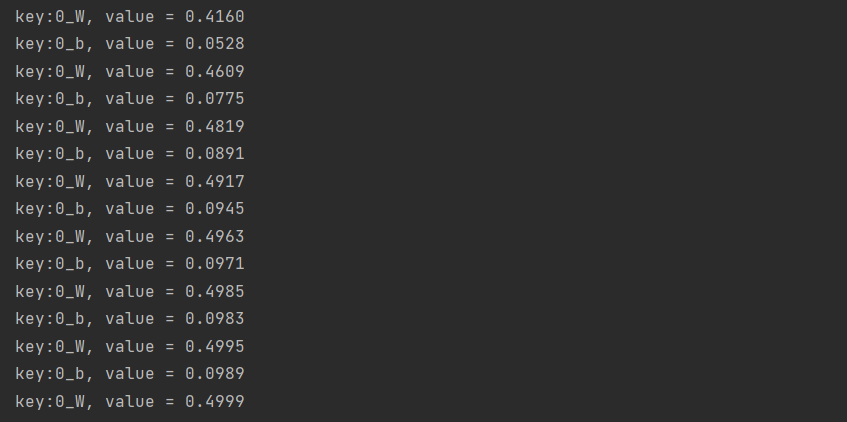
Map<String, INDArray> params = net.paramTable();
/*
* java 8 的用法
* java8实战 -> 图灵社区
* java 14年出来的
*/
params.forEach((key, value) -> System.out.println("key:" + key +", value = " + value));
}
// 测试两个数字,判断
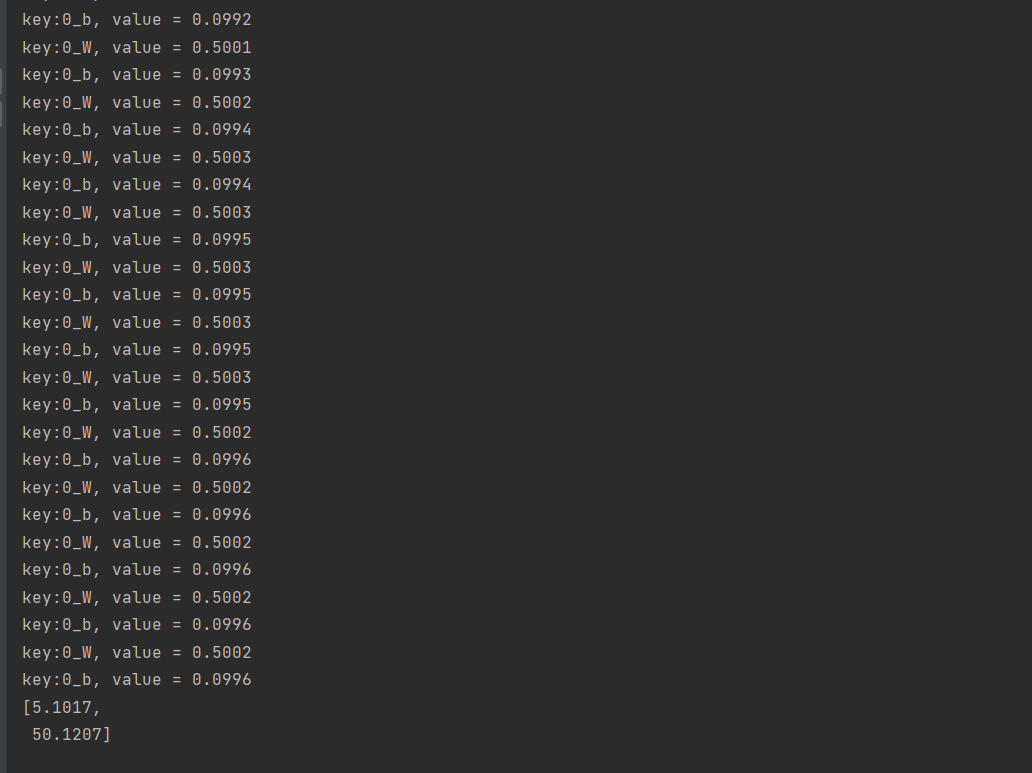
final INDArray input = Nd4j.create(new double[] { 10, 100 }, new int[] { 2, 1 });
INDArray out = net.output(input, false);
System.out.println(out);
}
private static DataSetIterator getTrainingData(int batchSize, Random rand) {
/*
* 如何构造我们的训练数据
* 现有的模型主要是有监督学习
* 我们的训练集必须有 特征+标签
* 特征-> x
* 标签->y
*/
double [] output = new double[nSamples];
double [] input = new double[nSamples];
//随机生成0到3之间的x
//并且构造 y = 0.5x + 0.1
//a -> 0.5 b ->0.1
for (int i= 0; i< nSamples; i++) {
input[i] = MIN_RANGE + (MAX_RANGE - MIN_RANGE) * rand.nextDouble();
output[i] = 0.5 * input[i] + 0.1;
}
/*
* 我们nSamples条数据
* 每条数据只有1个x
*/
INDArray inputNDArray = Nd4j.create(input, new int[]{nSamples,1});
INDArray outPut = Nd4j.create(output, new int[]{nSamples, 1});
/*
* 构造喂给神经网络的数据集
* DataSet是将 特征+标签 包装成为一个类
*
*/
DataSet dataSet = new DataSet(inputNDArray, outPut);
List<DataSet> listDs = dataSet.asList();
return new ListDataSetIterator(listDs,batchSize);
}
}

















 331
331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











