






3..1北京和天津地区常驻人口和户籍人口可视化.... 14
3.5北京各地区行政面积和GDP可视化(Tableau).... 20
第1章绪论
1.1研究背景
定期开展人口普查的目的就是查清我国人口在数量、结构、分布和居住环境等方面的情况变化,为科学制定国民经济和社会发展规划,统筹安排人民的物质和文化生活,实现可持续发展战略,构建社会主义和谐社会,提供科学准确的统计信息支持。 近些年来,经济全球化深入发展,世界经济大变革大调整步伐加快,全球人口状况也发生了较大变化。 各国为了应对挑战,更好地制定相关政策,都对人口进行普查。 2005年以来,世界上已经有70多个国家和地区进行了人口普查,另有150多个国家和地区将开展人口普查。 我国从2000年第五次人口普查以来,经济持续快速发展,社会结构不断调整,人口状况也有很大的改变。而北京作为我国的首都,全国的政治中心,文化中心,它的人口变化以及经济变化更应该值得关注。
1.2 研究目的与意义
通过研究北京各地区的户籍人口和常住人口以及GDP发展情况和男女比例来了解北京各地区的人口变化和经济状况,并且通过这些数据来预测之后两个地区的发展方向和人口变化趋势。
1.3研究内容
- 研究北京各地区常住人口和户籍人口的变化情况。
- 研究北京各地区男女比例的变化情况
- 研究北京各地区的GDP形势。
- 研究北京各地区行政面积和GDP的关系
第2章 数据采集与存储
2.1数据采集
数据采集意味着从在线资源中获取数据和信息。它通常可以与Web抓取,Web爬取和数据提取互换。采集是一个农业术语:从田地中采集成熟的农作物,具有采集和搬迁行为。数据采集是从目标网站提取有价值的数据,并将其以结构化格式放入数据库的过程。
要进行数据采集,需要有一个自动搜寻器来解析目标网站,捕获有价值的信息,提取数据并最终导出为结构化格式以进行进一步分析。因此,数据采集不涉及算法,机器学习或统计。相反,它依靠诸如Python,R,Java之类的计算机程序来起作用。
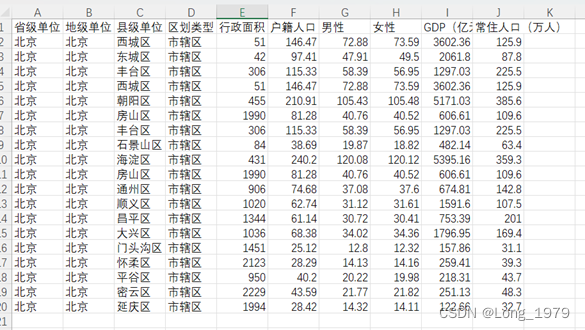
要对北京地区的人口变化以及GDP的变化情况进行分析,就需要先得到数据,我这里选择从找到的网页上去下载所需要的数据,将其以表格的格式保存到本地,这里下载的数据是关于某年北京地区地区人口数据表,表中包含了省级单位,地级单位,县级单位,区划类型,行政面积(K㎡),户籍人口(万人),男性,女性,GDP(亿元),常住人口(万人)共十七个字段。通过这些数据对北京各地区的人口变化以及男女比例和GDP变化有所了解。
采集到的数据如下图所示:
2.2数据预处理
2.2.3读取数据
因为采集数据后使用的是csv格式保存的,所以这里使用pandas中的read_csv()函数来读取数据,这里的参数enconding是编码格式的设置,因为有中文的数据所以这里使用的编码格式是UTF-8。
2.2.4缺失值处理
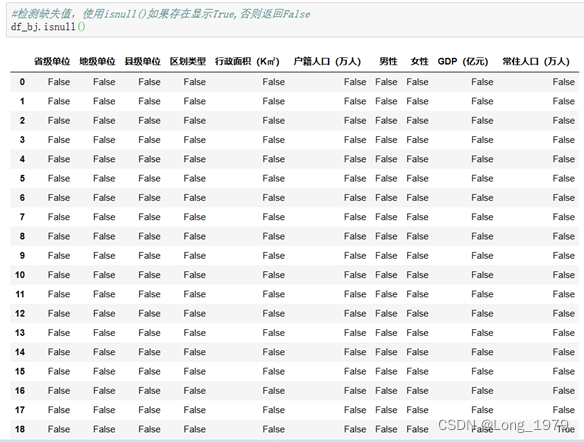
这里我使用pandas中的isnull()函数进行判断,如果是缺失值显示True否则显示False,判断之后对数据中的True进行填充处理。
北京地区缺失值的判断
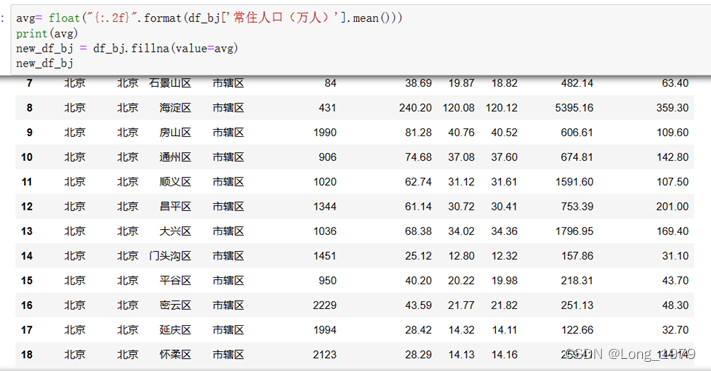
北京地区缺失值的处理
对于我们的数据而言,因为其数据量相对而言较小,且有一定的存在意义,所以这里使用该列数据(df_bj[“常住人口(万人)”])的均值(mean())对缺失数据进行填充处理,这里使用到的填充数据的函数fillna(),
2.2.5重复值处理
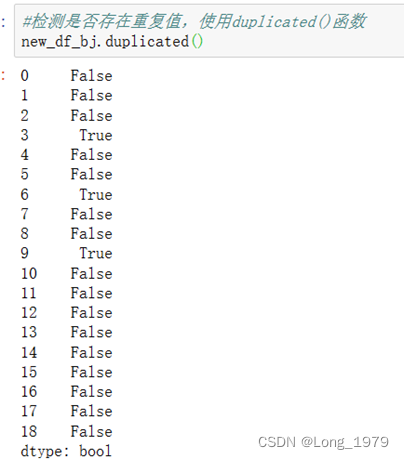
北京地区重复值判断
要想知道有无重复值首先进行判断,因为使用的是pandas库,其自带的判断重复值的函数为DataFrame.duplicated(),其返回的结果表现为布尔型,其中显示True的表示为重复数据,否之不是。当然有判断重复值的函数当然也有处理重复值的函数drop_duplicates(),该函数是直接删除重复数据
Pandas中使用duplicated()方法来检测数据中的重复值。检测完数据后会返回一个由布尔值组成的Series类对象,该对象中若包含True,说明该值对应的一行数据为重复项。
北京地区地区重复值处理
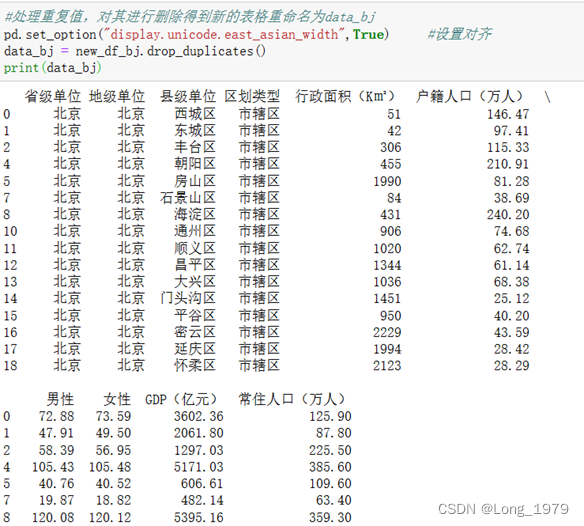
对于重复值,pandas中一般使用drop_duplicates()方法删除重复值。
2.2.6 异常值处理
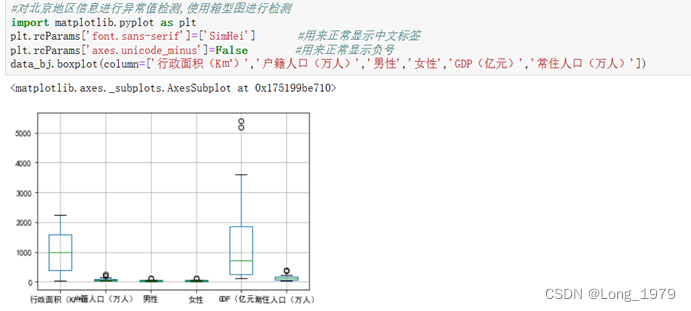
北京地区异常值判断
对于数据异常值的判断这里使用的是箱型图的方法,如果超出了上限或者下限就表示为异常值,这里由图可以看出在GDP一列出现了两个超出上限的点,所以这里对于北京数据存在两个异常值,接下来 对异常值进行处理。
北京地区异常值处理
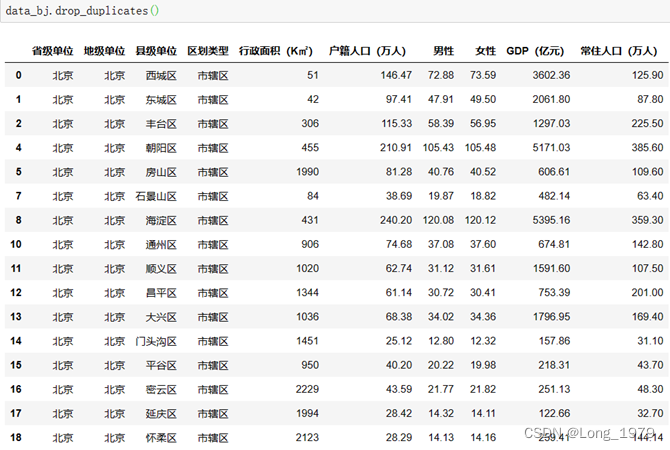
上面进行判断之后存在两个异常值,所以这里使用异常值的处理方法,对其进行删除操作,使用drop_duplicates()进行删除,最后得到没有异常值的数据,然后在此数据上进行下面的可视化分析。
处理后的数据如如图所示:
2.2.7无用列处理
因为数据集中的省级单位和地级单位都是同样的数据为了减小数据量,降低工作难度,这里选择将其中一列删除操作,还有区划类型一列都是直辖市,并且本次的数据分析对该列也不进行相应的分析,所以进行删除操作。

2.3数据存储
使用pandas中的to_csv()函数将处理好的数据以csv的格式保存到相应路径下,参数encoding=”gbk”是对导出数据编码格式的处理,参数index=0是将数据中的行索引为0的作为最终表的表头,保存后的数据表名为”北京最终.csv”,后面的数据分析都是在此表的基础上进行。

2.4本章小结
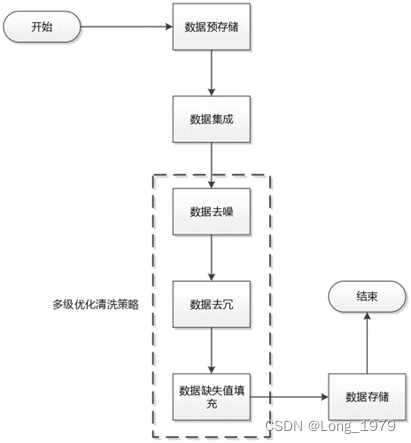
因为是网上下载的数据,不能保证该数据没有脏数据,从而无法直接用于可视化分析,所以需要先对原始数据进行一定的数据清洗操作。首先在原始的数据表中,可能存在一些空值、异常值、错误值和无效列等数据,而这些便是所谓的脏数据,要对这些脏数据进行了剔除和替换,最终筛选出了我们需要的、正确的数据,其中主要使用了县级单位,行政面积(K㎡),户籍人口(万人),男性,女性,GDP(亿元),常住人口(万人)等字段的数据进行分析和探索。这里使用了jupyer notebook调用pandas库进行数据预处理操作,对数据表中的缺失值,重复值,异常值进行排查处理,筛选空值使用的是pandas中的isnull()函数,为了保证数据的完整性,因此对这列数据中的空值数据使用该列的平均值进行填充处理,使用fillna()函数进行填充。使用duplicated()函数发现数据中存在重复值,因为重复值会使数据的分析有一定的影响,为了更准确的分析对这部分数据使用了pandas提供的drop_duplicates()进行删除。在检测异常值时使用箱型图进行,未出现异常值,最后观察数据发现省级单位和地级单位重复以及区划类型在分析中没有利用价值,为了减小分析的工作量,将这些列进行剔除掉,抽取所需要分析的列,将其重新制成表用作后面的分析探索。
第3章可视化分析
3..1北京和天津地区常驻人口和户籍人口可视化
3.1.1数据获取
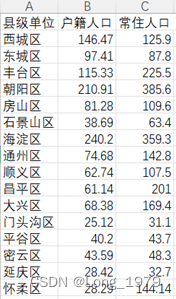
为了了解北京各地区常住人口和户籍人口之间的人口差异,对北京各地区常住人口和户籍人口进行分析,所以对数据处理后的数据表再次进行处理得到只含有县级单位,户籍人口和常住人口三列的新数据表,对该数据表进行数据可视化分析。
处理后的新数据表如下图所示:
表格 1用于分析北京各地区户籍人口和常住人口的数据表
3.1.1可视化分析(Excel)
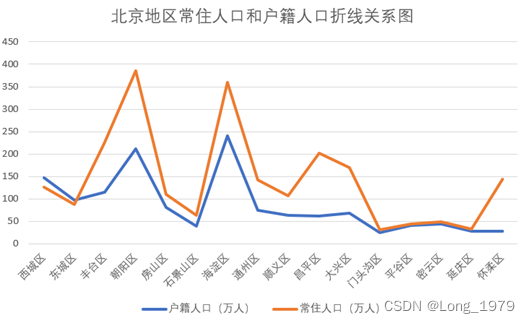
图表 1北京各地区常住人口和户籍人口的差异图
数据分析:通过上图可以看出对于北京各个地区来说,常住人口普遍高于户籍人口,尤其是朝阳区,海淀区,昌平区,大兴区,怀柔区(这里剔除怀柔区,因为该区的常住人口是后面因为此处缺失填充的结果),产生这种现象的原因可能是因为北京作为我国的首都,全国政治中心,文化中心,所以这里对于许多人来说都是一个人生发展的好地方,导致常住人口明显高于户籍人口。
3.2 北京地区各区男女比例可视化
3.2.1数据获取
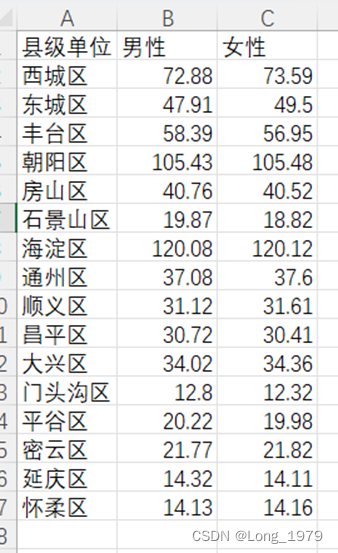
为了了解北京各地区的男女比例情况,所以对“北京最终.csv”数据表再次进行处理,提取出只含有县级单位,男性和女性三列数据,以此数据作为新表,对该表进行数据可视化的分析,从中得到分析结果。
处理后的新表如下图所示:
表格 2用于分析北京各地区男女比例的数据表
3.2.2可视化分析(echarts)
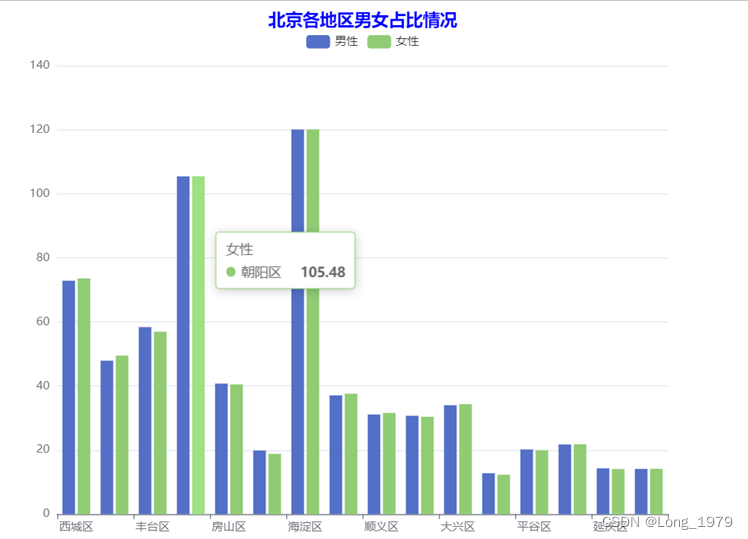
图表 2北京各地区男性和女性差异柱形图
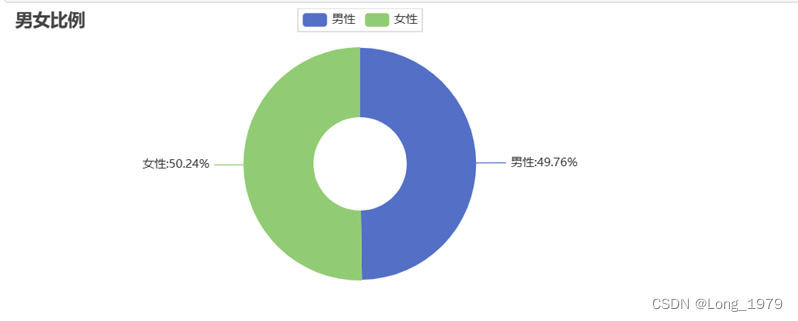
图表 3北京各地区男女占比情况玫瑰饼图
数据分析:通过上面的柱形图和玫瑰饼图可以看出北京各地区的男女比例情况没有明显差别,只是女性比男性的占比高出0.48%,从这可以看出,北京各地区的女性工作者有一定的增长趋势,这说明未来北京在些许工作岗位的设定上会提供更多与女性相关的行业岗位,打破男主外女主内的固定家庭格局,这对除北京地区外的其他地区也会有一定的参考意义。从一定方面来说,这样一定程度上也提高了女性的社会地位。
3.3北京GDP情况可视化
3.3.1数据获取
为了了解北京各地区的GDP情况,所以对“北京最终.csv”数据表再次进行处理,提取出只含有县级单位,GDP两列数据,以此数据作为新表,对该表进行数据可视化的分析,从中得到分析结果。
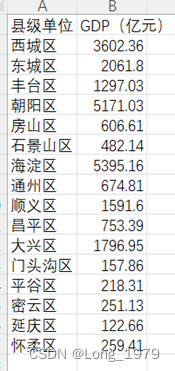
处理后的新表如下图所示:
表格 3用于分析北京各地区GDP集中情况数据表
3.3.2可视化分析(pyecharts)
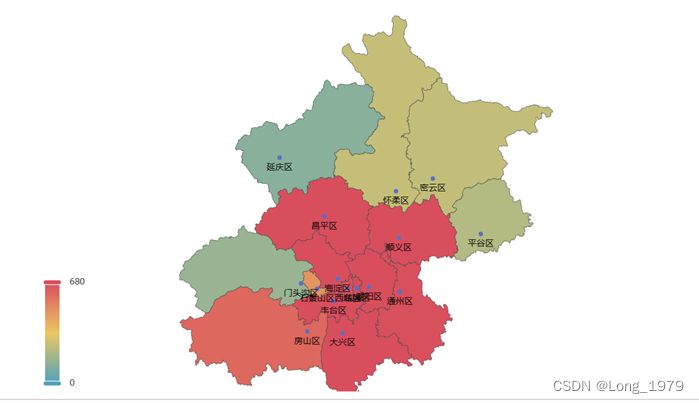
图表 4北京各地区GDP的集中情况
数据分析:通过上面的热力图可以看出北京地区的GDP主要集中在朝阳区,海淀区,通州区,大兴区等区域,首先因为朝阳区作为北京政府的所在地,而政府一般是建设在一个城市最繁华的地方,所以导致此处的GDP明显高于其他区域,而海淀区拥有众多的高等学府,并且我国注重人才的培养,所以高等学府也会带动周边产业的飞速发展,导致海淀区虽没有朝阳区的GDP高,但是也明显高于其他几个城区。所以北京的GDP形势主要跟本区域所拥有的政治社会资源有关,占有的资源越多,导致当地的GDP就越高。想要解决这个问题,可以对这些社会资源进行合理的分配,因地制宜更好的利用各地的优势发展北京的经济,是北京经济发展的重要举措。
3.5北京各地区行政面积和GDP可视化(Tableau)
3.5.1数据获取
为了分析北京各地区的行政面积和GDP的关系,如果直接使用元数据的话,有可能会出现数据导入错误的情况,为了避免这种事情的发生,所以需要对数据进行删减和重新整合,得到新的数据表,里面只含有县级单位,行政面积,GDP三列数据,使用新的数据表进行下一步的可视化分析,新得到的数据表的内容如下表所示:
表格 4用于分析北京各地区行政面积和GDP关系的数据表
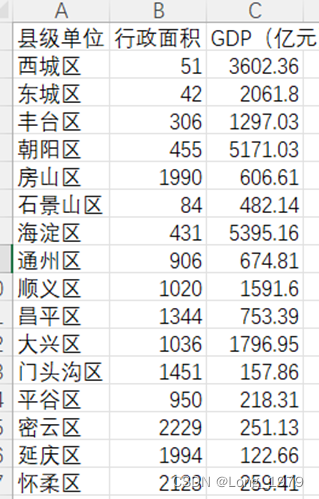
3.5.2可视化分析
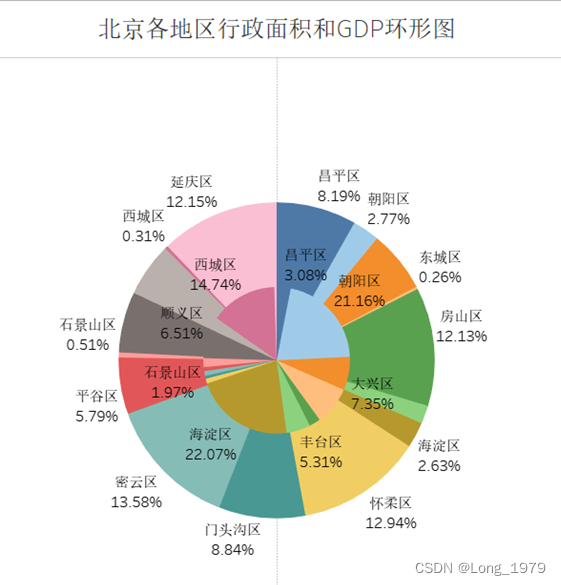
图表 5北京各地区行政面积和GDP环形图
数据分析:通过上面的北京各地区GDP和行政面积的比较发现,对于一些地区虽然行政面积较小,但是GDP的占比却明显高于其他行政面积大的区域,产生这样的情况是因为有的行政面积小的所拥有的政治文化资源丰厚,比如朝阳区是北京政府的所在区,海淀区有众多的985,211高等学府,西城区是战国燕都蓟城所在地,辽、金、元、明、清历代均为京都一部分。作为北京3000多年的建城地和800多年的建都地,是皇家文化和民俗文化的融合区,是皇城文化、仕子文化、民俗文化、宗教文化等各种文化高度融合的区域 。西城区风景名胜众多,所以这些地区的行政面积虽小,但是GDP却明显高与其他区。这种情况不利于北京地区的全面发展,为了解决这一问题,可以对周边行政面积大但是GDP却很低的区,进行一定的政策扶持,或者开发当地的旅游政治文化,使这些区域的经济情况,得到一个好的回升,不至于和主城区相差太多。
3.6问题与措施
3.6.1 问题总结
3.6.1.1格式问题
中英文转换
编码格式问题

使用tableau如何显示数值和将数值转换为百分比
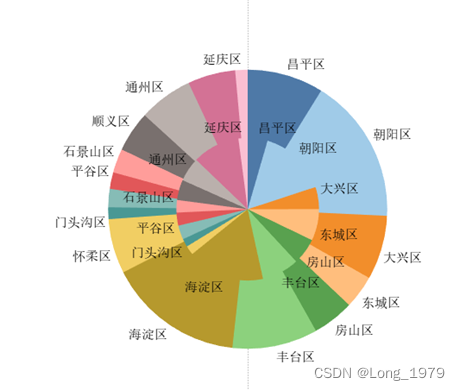
3.6.2 相关措施
中英文转换:在代码输入过程中,如果涉及到根据表格的列名来获取所对应的值,要注意其格式,一般情况下为了防止输入错误,可以采用复制粘贴的方法来得到所需要的列名。
编码格式的问题:在读入数据和导出数据时,往往会因为编码格式的问题导致读取失败或者是导出了数据,但是会出现乱码的情况,这时候一般都需要注意自己的文件编码格式,如果是中文的一般都是utf-8,数字的话一般是gbk
使用tableau如何显示数值和将数值转换为百分比:使用tableau时,在制作环形图时,为了更好的比较内环与外环之间的关系,以及因为是在饼图的基础上制作,所以要求显示的结果为百分比格式,显示百分比的前提是先将数据一标签的格式显示,再右击选择快速表计算,然后点击合计百分比,这样最终的显示结果就是以百分比的格式输出显示。
第4章总结与展望
4.1 总结
这次项目中,所分析的数据是从网上下载的某年北京各地区有有关常住人口,户籍人口,行政面积,GDP,男女占比情况数据表,通过对该数据表中的数据进行相应的分析处理操作,最后将处理后的数据进行可视化处理,根据可视化图表的显示情况,获取到一定的社会现状,从而提出相应的解决方案。
通过这次的实训,让我对可视化的处理流程有了一定的了解, 数据处理时使用了jupyter notebook数据处理工具,分别对表中的缺失值,重复值,缺失值以及无用列进行处理,可视化使用了四种可视化工具分别是excel,Tableau,echarts,pyecharts,可视化之后对图标进行一定的分析。分析过程中也遇到了不少的问题,通过解决这些问题,让自己对这四类的可视化工具有了很好的使用体验,对自己平时的工作学习有一定的帮助。
4.2 展望
经过上面的可视化分析,可以得出北京各地区的人口变化和GDP占比情况,发现主要集中在主城区,而这对北京的经济发展有一定的影响,为了减少这种影响可以不仅要发展主城区的经济,其他区域的经济也要跟着发展,虽说不能完全照搬主城区的发展方法,但是也可以参考一二,比如说对于行政面积大的地区,可以根据这些地区的地理优势和当地人口的喜好情况,开展相应的经济文化活动。对于行政面积小的并且GDP不高的可以采用与行政面积大的地区进行合作,通过合作,因地制宜,这样才能达到双赢的情况。当然这只是一部分,想要让北京的经济持续增长,其他的发展方向也需要进行考虑。















 402
402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









