







Lec 23: RCU
- Ref: https://github.com/huihongxiao/MIT6.S081/tree/master/lec23-rcu-robert
- Preparation: RCU Usage In the Linux Kernel: One Decade Later (2013)
读写锁
接口
r_lock(&l)r_unlock(&l)w_lock(&l)w_unlock(&l)
多个数据读取者可以获取读锁并发读, 但只能有一个数据写入者获取写锁.
简要实现
// A simplified version of Linux's read/write lock.
// n=0 -> not locked
// n=-1 -> locked by one writer
// n>0 -> locked by n readers
struct rwlock {
int n;
};
r_lock(l):
while 1:
x = l->n
if x < 0
continue
if CAS(&l->n, x, x + 1)
return
// CAS(p, a, b) is atomic compare-and-swap instruction
// if *p == a, set *p = b, return true
// else return false
w_lock(l):
while 1:
if CAS(&l->n, 0, -1)
return
rwlock结构体: 其中有一个计数器nn为 0 表示锁未被以任何形式持有n为 -1 表示被数据写入者持有写锁n大于 0, 表示有 n 个数据读取者持有读锁.
r_lock(): 在循环中等待写入者释放锁(n<0). 获取锁(n>=0)后对锁原子操作(CAS)加 1.
CAS: Compare-and-swap.- 多个
r_lock()同时调用时只有其中 1 个 CAS 能够执行成功返回 1, 其余失败的将继续循环尝试执行 CAS. - 该实现读取者优先, 读取者过多时写入者可能一直等待.
性能问题
- 多个数据读取者同时调用
r_lock()时, 都会读取技术l->n将其加载到 CPU 的 cache 并调用 CAS 指令修改计数值. 在多核 CPU 情况下, 只有一个 CAS 指令成功, 其它失败, 同时需要告知其它 CPU 的 cache 失效(让其它 CPU 核不缓存该数据, 称之为无效化, invalidation). 假设有 n 个读取者, 则每个r_lock()平均循环 n 2 \frac{n}{2} 2n 次, 且每次循环涉及 O ( n ) O(n) O(n) 的 CPU 消息, 则获取锁的成本为 O ( n 2 ) O(n^2) O(n2). - 读写锁将一个只读操作变成了需要修改锁的计数器
l->n的写操作.
RCU
RCU: Read Copy Update. 通过 RCU 通过数据写入者进行一些额外的规则和操作, 使得数据读取者可以不使用任何锁进行读取.
基本实现
以单向链表为场景:
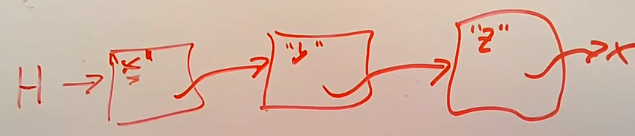
一个结点元素内容为字符串的单向链表. 涉及的写入操作有三种:
- 修改结点内容(字符串)
- 插入结点
- 删除结点
RCU 不能直接修改结点的内容, 而是创建并初始化一个新的结点, 用新结点替换旧结点. 这样数据读取者永远不会看到一个正在修改的链表元素.

旧结点 E2 和结点 E3 的指向关系不会删除, 因为更新指向新结点指针时, 可能有读取者读取到了 E2.
将 E1 的 next 指针从旧的结点 E2 切换到新的结点 E2 的过程, 被称为提交写入(committing write). 单个提交写入操作是原子的. 以提交写入操作的完成为分界, 读取者要么要么读取的是旧元素, 要么读取的新元素.
RCU 主要用于具备单个写入提交操作的数据结构上. 如双向链表则对 RCU 不太友好, 而树(无父指针)对于 RCU 是友好的.

内存屏障
编译器和 CPU 都会重排指令, 需要使用内存屏障(barrier)以防止指令重排.

读取者和写入者都需要使用内存屏障:
- 数据写入者: 在提交写入(committing write)操作之前加入内存屏障, 以确保完成提交写入时, 元素已完全初始化.

- 数据读取者: 在读取了结点的指针后, 读取指针指向的内容之前加入内存屏障.(此处可能是避免指针的值被先前缓存等情况, 课程中也未讲清楚).

旧元素释放
对于旧元素在被替换后释放的时机.
GC
对于带有 GC(垃圾回收)的编程语言可以无需考虑该问题, 由 GC 进行元素释放.
延迟冻结(Delaying Freeze)
对于无 GC 的情况(如 Linux 系统), 读写规则如下:
- 数据读取者: 不允许在线程切换的上下文切换时持有 RCU 保护的数据, 即数据读取者不能在 RCU 的临界区内出让 CPU.
- 数据写入者: 在每个 CPU 核至少执行过一次上下文切换后再释放元素(每个核都进行过上下文切换则没有核还持有该元素).

数据写入者的代码:
E1->next = e;
synchronize_rcu();
free(old);
- 首先完成对数据的修改
- 调用
synchronize_rcu()已迫使每个 CPU 核发送一次上下文切换, 这也确保没有 CPU 核再持有指向旧元素的指针 - 释放旧元素
- 该情况写入者需要等待
synchronize_rcu()进行上下文切换. - 使用
call_rcu()可以立刻返回. 该函数参数为待释放的对象和执行释放的回调函数. RCU 系统会将这两个参数存入一个列表, 并立刻返回. 在后台 RCU 系统会检查每个 CPU 核的上下文切换计数, 当每个核都发生过上下文切换后, 调用回调函数进行对象的释放. 缺点是大量调用该函数, 参数列表会很长占用大量内存导致内存耗尽.
代码示例
数据读取
// list reader:
rcu_read_lock()
e = head
while(p){
e = rcu_dereference(e)
look at e->x ...
e = e->next
}
rcu_read_unlock()
- 数据读取位于
rcu_read_lock()和rcu_read_unlock()之间. 这两个函数值设置一个标志位来阻止定时器中断导致的线程上下文切换(中断还会发生, 但不切换上下文).
这里的标志位是每个 CPU 独有的数据, 而不是所有 CPU 共享, 因此不会引起 CPU 间的缓存一致消息. rcu_dereference()函数会插入内存屏障. 首先会从内存中拷贝e, 触发一个内存屏障, 之后返回指向e的指针. 之后就可读取e指针指向的数据内容, 并走向下一个链表元素.- 数据读取代码值, 不能将链表元素返回(包括指针以及字符串内容), 以避免访问过程中触发上下文切换, 只能返回元素的拷贝.
- 数据读取几乎无额外开销, 仅标志位设置和内存屏障有少量开销, 读取速度很快.
数据写入
// replace the first list element:
acquire(lock)
old = head
e = alloc()
e->x = ...
e->next = head->next
rcu_assign_pointer(&head,e)
release(lock)
synchronize_rcu()
free(old)
- 此处使用自旋锁(
spinlock)避免数据写入者之间的竞争. - 通过
old保存待释放的结点 - 使用
alloc()分配并初始化一个新的结点元素 rcu_assign_pointer()函数会设置一个内存屏障, 以确保之前的所有写操作都执行完成, 再将head指向新分配的链表元素e- 释放自旋锁后, 调用
synchronize_rcu()确保任何一个可能持有了旧的链表元素的 CPU 都执行一次上下文切换 - 最后释放旧链表元素
- 数据写入性能很差. 因为有了非常耗时的
synchronize_rcu()函数调用.
总结
- 适用于读操作远多于写操作的情况
- 直接应用 RCU 的数据结构在更新时需要能支持单个提交写入操作(如单向链表, 树).
- RCU 不能原地更新数据, 而是使用一个新元素进行替代.
- RCU 不能保证数据读取者一定读取的是新的数据, 即数据读取者可能读取到更新前的旧数据.

















 312
312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









