






Introducion
随着AI算法的不断进步与不断普及,目标检测算法广泛的运用于我们生活中的各个领域,例如智慧城市、无人驾驶、智慧家居等场景。对于普通的开发者而言,目标检测算法的数据集准备+训练+部署依然存在着不小的难度,而Aidlux的出现很好的解决了这一个问题。Aidlux可以将我们的安卓设备进一步改造成边缘计算设备,非常的易于部署。项目完整代码可于github上下载:loushengtao/Yolo5Lite-onnx-Aidlux: 基于Yolo5Lite+onnx+Aidlux,全流程实现桌面级监测系统 (github.com)
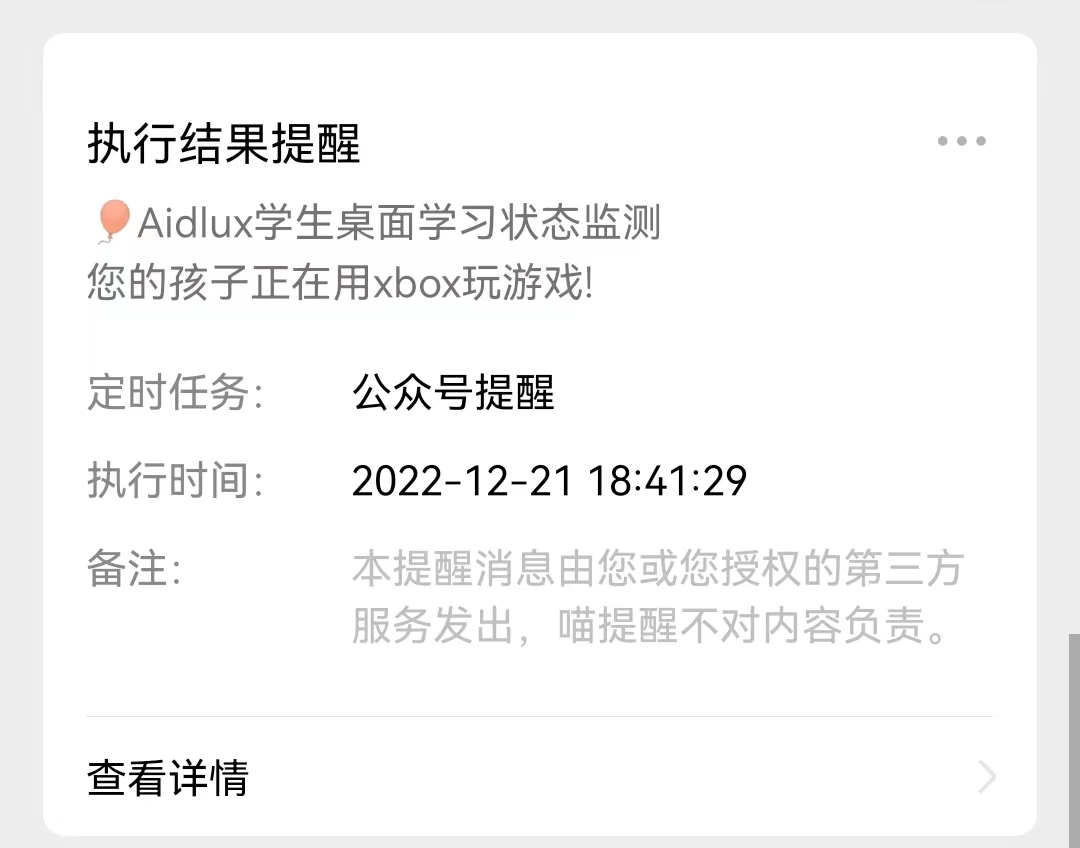
本项目为基于Aidlux+Yolo5-Lite+onnx,全流程实现桌面级监测系统。具体功能是可以检测网课学生在桌面上的一些活动,例如是不是在用笔写字,是不是在使用鼠标,是不是在用手柄打游戏。当检测出学生在使用手柄打游戏时,家长绑定的喵提醒公众号上将会收到提醒:
在本帖子中,我将全流程介绍一个目标检测算法的数据集采集+模型训练+模型部署的三个步骤,本项目需要的硬件需求为:
- 1.装有pytorch框架的电脑
- 2.一台安卓设备
- 3.usb摄像头(采集训练集数据用)

项目具体操作流程
1.数据集准备
想要Train一个目标检测模型,训练集是第一步,所以我们先使用摄像头对训练集的图片进行采集。在本项目中我设置了三种检测物体(读者也可以根据需求自行改变):
- pen——(笔)
- mouse——(鼠标)
- controller——(手柄)
我们使用usb摄像头来采集数据,首先我们先测试摄像头是否正常工作:
import os
import cv2
cap = cv2.VideoCapture(0) # 选择摄像头的编号
cv2.namedWindow('USBCamera', cv2.WINDOW_NORMAL) # 添加这句是可以用鼠标拖动弹出的窗体
while(cap.isOpened()):
# 读取摄像头的画面
ret, frame = cap.read()
# 真实图
cv2.imshow('USBCamera', frame)
# 按下'q'就退出
k=cv2.waitKey(1) & 0xFF
if k == ord('s'):
a=1
elif k == ord('q'):
break
# 释放画面
cap.release()
cv2.destroyAllWindows()
如果摄像头画面正常弹出,则说明usb摄像头工作正常,那么我们就可以进入到数据采集环节。在打开摄像头后,按’s’保存图像,按’q’退出图像采集程序。
import os
import cv2
cap = cv2.VideoCapture(0) # 选择摄像头的编号
cv2.namedWindow('USBCamera', cv2.WINDOW_NORMAL) # 添加这句是可以用鼠标拖动弹出的窗体
root='dataset/images/'
index=len(os.listdir(root)) # 从最后一张图片开始计数,不覆盖前面采集的数据集
while(cap.isOpened()):
# 读取摄像头的画面
ret, frame = cap.read()
# 真实图
cv2.imshow('USBCamera', frame)
# 按下'q'就退出
k=cv2.waitKey(1) & 0xFF
if k == ord('s'):
cv2.imwrite(root+str(index)+'.jpg',frame)
index+=1
elif k == ord('q'):
break
# 释放画面
cap.release()
cv2.destroyAllWindows()
为了实现三个物体的监测,本项目大概采集了 两百多张照片 (读者可以根据检测物体个数、模型鲁棒性等因素自行决定数据集照片张数),这里展示数据集中采集到的一张照片

2.数据集标注
在采集完图像数据之后,我们就进入到了数据的标注环节。本项目采用的标注工具为labelme,他的下载和使用非常简单,只需一下两步:
- pip install labelme
- labelme
唤起labelme图像界面之后,单击左上角的file,我们需要对其进行一些设置:

在配置好我们的输入images文件夹和输出labels文件夹的路径之后,我们就可以进入到标注环节,create rectangle创建矩形框来框住我们图像中的物体。标注的话是个 体力活,体力活,体力活 。
在标注完成后,我们图片的json文件是长这样的

可以看到这里表示bbox是图像中的真实值,而我们送入yolov5-lite里面训练的bbox是需要归一化之后的数据,所以我们对数据经行归一化,生产符合yolov5-Lite训练格式的文件。同时我们也根据ratio分割训练集和测试集。
import os
import json
import random
import base64
dic_labels={'pen':0,'mouse':1,'controller':2,
'path_json':'dataset/labels','ratio':0.9} # ratio为0.9则百分之九十为训练数据,百分之10为测试数据
def generate_labels(dic_lab):
path_input_json=dic_lab['path_json']
ratio=dic_lab['ratio']
for index,labelme_annotation_path in enumerate(os.listdir(path_input_json)):
image_id=os.path.basename(labelme_annotation_path).rstrip('.json') #读取文件名
train_or_valid='train' if random.random()<ratio else 'valid'
# 读取labelme格式的json文件
labelme_annotation_file=open(path_input_json+'/'+labelme_annotation_path,'r')
labelme_annotation=json.load(labelme_annotation_file)
#print(labelme_annotation)
# 写入yolo格式的json
yolo_annotation_path=os.path.join('dataset\\'+train_or_valid,'labels',image_id+'.txt')
yolo_annotation_file=open(yolo_annotation_path,'w')
sw=1.0/labelme_annotation['imageWidth']
sh=1.0/labelme_annotation['imageHeight']
for obj in labelme_annotation['shapes']:
if obj['shape_type']!='rectangle':
print('Invalid type in annotation')
continue
points=obj['points']
width=(points[1][0]-points[0][0])*sw
height=(points[1][1]-points[0][1])*sh
x=((points[1][0]+points[0][0])/2)*sw
y=((points[1][1]+points[0][1])/2)*sh
obj_class=dic_lab[obj['label']]
yolo_annotation_file.write(f'{obj_class} {x} {y} {width} {height}\n')
yolo_annotation_file.close()
#yolo格式图像保存
yolo_image=base64.decodebytes(labelme_annotation['imageData'].encode())
yolo_image_path=os.path.join('dataset\\'+train_or_valid,'images',image_id+'.jpg')
yolo_image_file=open(yolo_image_path,'wb')
yolo_image_file.write(yolo_image)
yolo_image_file.close()
print('create lab %d:%s'%(index,image_id))
generate_labels(dic_labels)
3.数据集训练
yolo5-Lite的github项目地址为:https://github.com/ppogg/YOLOv5-Lite。在准备好yolo格式的数据集之后,我们就可以进入到训练环境。训练环节有三个需要注意的点:
- 1.pretrained model
- 2.mydata.yaml
- 3.config
3.1 pretrainde model
pretrained model预训练模型是我们模型的初始参数,如果不使用pretrained model,网络的收敛速度会慢很多,训练效果也会差很多。本项目使用的pretrianed model为v5lite-e.pt.
3.2 mydata.yaml
mydata.yaml是数据集中的一些信息。其中包含了train和val的path以及训练集中存在的所有class
3.3config
每一个模型都是需要配置config的,在此记录一些基本操作和yolo5Lite配置过程中遇到的问题。
首先是基本配置:
parser.add_argument('--weights', type=str, default='../v5lite-e.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='models/v5Lite-e.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='../mydata.yaml', help='data.yaml path')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu') # 0代表cuda:0,以此类推
parser.add_argument('--workers', type=int, default=1, help='maximum number of dataloader workers') # 不采用分布式训练,workers调成1
再是包的配置,这里提一个windows系统下极难安装的pycocotools包,根据一下步骤安装即可:、
- 先从网上下载pycocotools的安装包 https://pypi.tuna.tsinghua.edu.cn/simple/pycocotools/ ,建议下载2.0.4版本。
- 进入到解释器的文件夹目录,我这里是miniconda3/envs/pt_env,然后解压下载的安装包,进入到安装包文件夹,并在在此处打开终端,输入如下命令:
python setup.py build_ext --inplace python setup.py build_ext install - 终端出现成功安装提示。
在配置完参数之后,直接运行trian.py即可。训练完成之后会在runs里生成exp_n文件夹来保存训练模型参数和训练过程的一些数据。
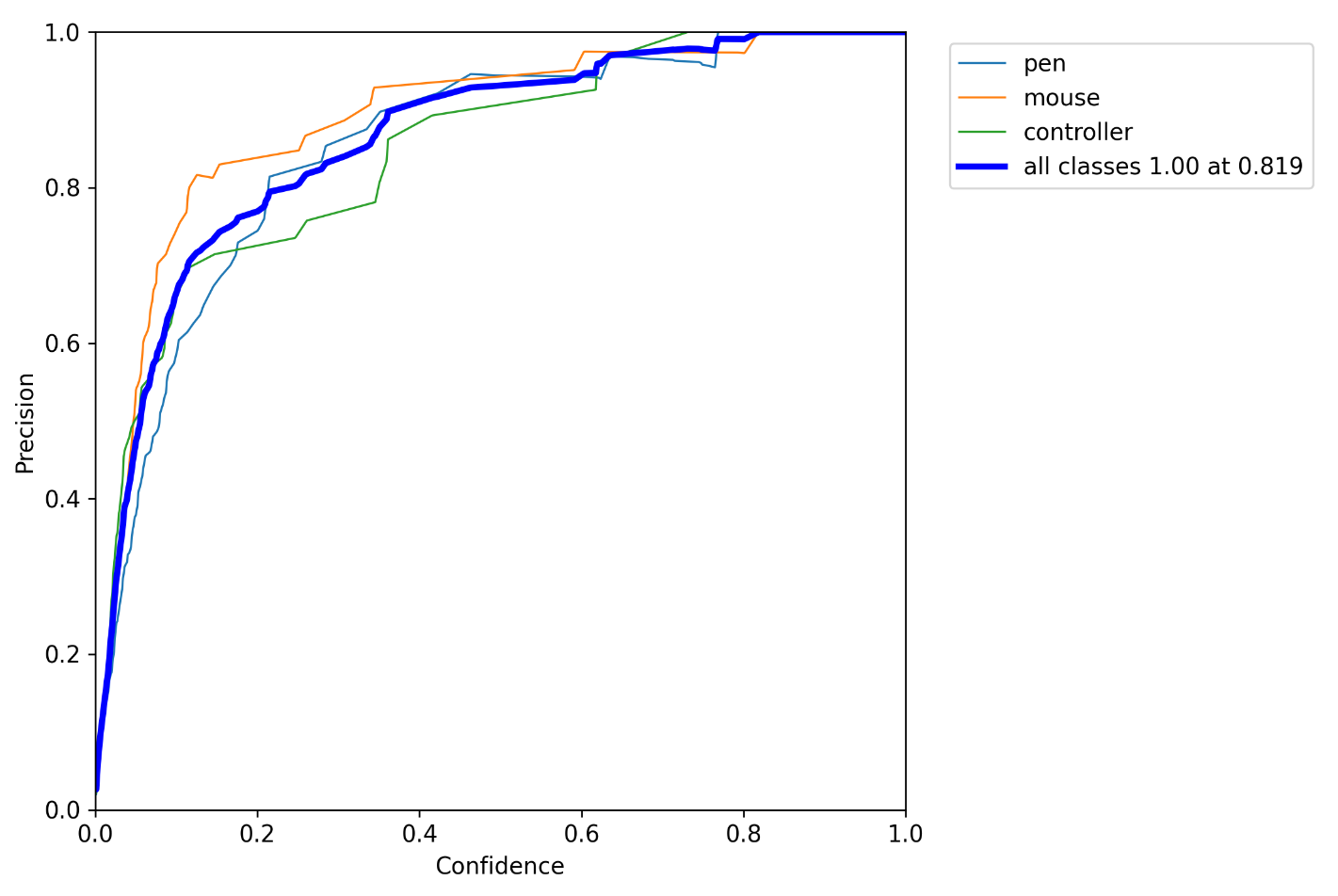
4.电脑端模型推理
在模型训练完毕之后,我们需要在电脑端先对pt模型文件进行测试。在模型推理过程中,可能会出现如下报错:
‘Upsample’ object has no attribute ‘recompute_scale_factor’
我们只需进入对应文件
“C:\Users\Levite_Lou\miniconda3\envs\pt_env\lib\site-packages\torch\nn\modules\upsampling.py”
将153,154行替换为如下内容即可
return F.interpolate(input, self.size, self.scale_factor, self.mode, self.align_corners)
电脑端模型推理代码如下:
import sys
sys.path.append('YOLOv5_Lite_master') # 用sys吧兄弟目录path加入搜索path
import argparse
import numpy as np
import time
from pathlib import Path
from PIL import Image
import cv2
import torch
import torch.backends.cudnn as cudnn
from numpy import random
import torchvision.transforms as transforms
from models.experimental import attempt_load
from utils.datasets import LoadStreams, LoadImages
from utils.general import check_img_size, check_requirements, check_imshow, non_max_suppression, apply_classifier, \
scale_coords, xyxy2xywh, strip_optimizer, set_logging, increment_path
from utils.plots import plot_one_box
from utils.torch_utils import select_device, load_classifier, time_synchronized
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='best.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='0', help='source') # file/folder, 0 for webcam
parser.add_argument('--imgsz', type=int, default=320, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.45, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.5, help='IOU threshold for NMS')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
opt = parser.parse_args(args=[])
model = attempt_load(opt.weights, map_location=opt.device) # load FP32 model
stride = int(model.stride.max()) # model stride
imgsz = check_img_size(opt.imgsz, s=stride) # check img_size
img=Image.open('dataset/images/0.jpg')
c=cv2.cvtColor(np.array(img),cv2.COLOR_RGB2BGR)
trans=transforms.PILToTensor()
res=transforms.Resize([320,320])
img=trans(img)
w,h=img.shape[2:][0],img.shape[1:2][0]
print('img shape is',img.shape[1:])
input_tensor=res(img/255).unsqueeze(0)
#print(input_tensor.shape)
pred=model(input_tensor,augment=opt.augment)[0]
#print(pred.shape)
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)
det=[j for _,j in enumerate(pred)][0]
cla=['pen','mouse','controller']
det[:,0],det[:,2]=det[:,0]*w/opt.imgsz,det[:,2]*w/opt.imgsz
det[:,1],det[:,3]=det[:,1]*h/opt.imgsz,det[:,3]*h/opt.imgsz
for i,det in enumerate(det):
xyxy=[int(i) for i in det[:4]]
print(xyxy)
plot_one_box(xyxy,c,label=cla[int(det[5])], line_thickness=3)
cv2.imshow('testimg', c)
cv2.waitKey(0)
因为我们最后是要部署到手机摄像头上,所以我们现在电脑上启用摄像头看看检测效果:
import sys
sys.path.append('YOLOv5_Lite_master') # 用sys吧兄弟目录path加入搜索path
import argparse
import numpy as np
import time
from pathlib import Path
from PIL import Image
import cv2
import torch
import torch.backends.cudnn as cudnn
from numpy import random
import torchvision.transforms as transforms
from models.experimental import attempt_load
from utils.datasets import LoadStreams, LoadImages
from utils.general import check_img_size, check_requirements, check_imshow, non_max_suppression, apply_classifier, \
scale_coords, xyxy2xywh, strip_optimizer, set_logging, increment_path
from utils.plots import plot_one_box
from utils.torch_utils import select_device, load_classifier, time_synchronized
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='best.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='0', help='source') # file/folder, 0 for webcam
parser.add_argument('--imgsz', type=int, default=320, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.45, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.5, help='IOU threshold for NMS')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
opt = parser.parse_args(args=[])
model = attempt_load(opt.weights, map_location=opt.device) # load FP32 model
stride = int(model.stride.max()) # model stride
imgsz = check_img_size(opt.imgsz, s=stride) # check img_size
def infer(cv_im):
img = Image.fromarray(cv2.cvtColor(cv_im,cv2.COLOR_BGR2RGB))
trans=transforms.PILToTensor()
res=transforms.Resize([320,320])
img=trans(img)
w,h=img.shape[2:][0],img.shape[1:2][0]
#print('img shape is',img.shape[1:])
input_tensor=res(img/255).unsqueeze(0)
#print(input_tensor.shape)
pred=model(input_tensor,augment=opt.augment)[0]
#print(pred.shape)
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)
det=[j for _,j in enumerate(pred)][0]
cla=['pen','mouse','controller']
det[:,0],det[:,2]=det[:,0]*w/opt.imgsz,det[:,2]*w/opt.imgsz
det[:,1],det[:,3]=det[:,1]*h/opt.imgsz,det[:,3]*h/opt.imgsz
for i,det in enumerate(det):
xyxy=[int(i) for i in det[:4]]
#print(xyxy)
plot_one_box(xyxy,cv_im,label=cla[int(det[5])], line_thickness=3)
return cv_im
cap = cv2.VideoCapture(0) # 选择摄像头的编号
cv2.namedWindow('USBCamera', cv2.WINDOW_NORMAL) # 添加这句是可以用鼠标拖动弹出的窗体
while(cap.isOpened()):
# 读取摄像头的画面
ret, frame = cap.read()
t=infer(frame)
# 真实图
cv2.imshow('USBCamera', t)
# 按下'q'就退出
k=cv2.waitKey(1) & 0xFF
if k == ord('q'):
break
# 释放画面
cap.release()
cv2.destroyAllWindows()
5.导出onnx文件
ONNX(Open Neural Network Exchange) 是一种表示神经网络模型的 IR(Intermediate Representation),它定义了一套可扩展的计算图以及一系列标准的数据类型和算子。当前大多数训练、部署框架以及硬件厂商的推理加速引擎都支持 ONNX 格式。
本项目也使用了onnx文件在Aidlux进行推理,我们先将best.pt文件导出为best.onnx:
import torch
import onnx
device = select_device('cpu')
model = attempt_load('best.pt', map_location=device)
labels=model.names
print('\nStarting ONNX export with onnx %s...' % onnx.__version__)
f = opt.weights.replace('.pt', '.onnx') # filename
img = torch.zeros(1, 3, 320,320).to(device)
y = model(img)
torch.onnx.export(model, img, f, verbose=False, opset_version=12, input_names=['images'],
output_names=['classes', 'boxes'] if y is None else ['output'],
dynamic_axes={'images': {0: 'batch', 2: 'height', 3: 'width'}, # size(1,3,640,640)
'output': {0: 'batch', 2: 'y', 3: 'x'}})
# Checks
onnx_model = onnx.load(f) # load onnx model
onnx.checker.check_model(onnx_model) # check onnx model
# print(onnx.helper.printable_graph(onnx_model.graph)) # print a human readable model
print('ONNX export success, saved as %s' % f)
best.onnx文件导出成功,接下来我们就可以在Aidlux上进行推理测试了
6.Aidlux端模型推理
因为我们导出的是onnx类型文件,所以我们需要先在Aidlux上安装onnxruntime包,包的安装非常简单,只需打开Aidlux的app界面,其中有一个onnxruntime1.8.1版本,点击安装即可。

在安装好了onnxruntime之后,我们将会使用其框架读取我们在电脑端导出的best.onnx文件进行推理,在Aidlux端进行推理的代码如下:
import cv2
import numpy as np
import onnxruntime as ort
import math
import time
def plot_one_box(x, img, color=None, label=None, line_thickness=None):
tl = (
line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1
) # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(img,label,(c1[0], c1[1] - 2),0,tl / 3,[225, 255, 255],thickness=tf,lineType=cv2.LINE_AA,)
def post_process_opencv(outputs,model_h,model_w,img_h,img_w,thred_nms,thred_cond):
conf = outputs[:,4].tolist()
c_x = outputs[:,0]/model_w*img_w
c_y = outputs[:,1]/model_h*img_h
w = outputs[:,2]/model_w*img_w
h = outputs[:,3]/model_h*img_h
p_cls = outputs[:,5:]
if len(p_cls.shape)==1:
p_cls = np.expand_dims(p_cls,1)
cls_id = np.argmax(p_cls,axis=1)
p_x1 = np.expand_dims(c_x-w/2,-1)
p_y1 = np.expand_dims(c_y-h/2,-1)
p_x2 = np.expand_dims(c_x+w/2,-1)
p_y2 = np.expand_dims(c_y+h/2,-1)
areas = np.concatenate((p_x1,p_y1,p_x2,p_y2),axis=-1)
areas = areas.tolist()
ids = cv2.dnn.NMSBoxes(areas,conf,thred_cond,thred_nms)
return [np.array(areas)[ids],np.array(conf)[ids],cls_id[ids]]
#(640,480)
def infer(img0,img_h,img_w,dic,net1):
img = cv2.resize(img0, [320,320], interpolation=cv2.INTER_AREA)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = img.astype(np.float32) / 255.0
blob = np.expand_dims(np.transpose(img, (2, 0, 1)), axis=0)
outs = net1.run(None, {net1.get_inputs()[0].name: blob})[0].squeeze(axis=0)
print(np.array(outs).shape)
outs=post_process_opencv(outs,320,320,480,640,0.4,0.5)
print(len(outs[0]))
print(outs[0][0])
xyxy=[int(i) for i in outs[0][0][0]]
print(xyxy)
print('%.2f'%outs[1][0][0])
print(outs[2][0][0])
for i in range(len(outs[0])):
xyxy=[int(i) for i in outs[0][i][0]]
label=dic_labels[outs[2][i][0]]+' %.2f'%outs[1][i][0]
plot_one_box(xyxy, img0, color=(255,0,0), label=label, line_thickness=2)
return img0
if __name__=='__main__':
model_pb_path = "best.onnx"
net = ort.InferenceSession(model_pb_path) # 创建InferenceSession
# 标签字典
dic_labels= {0:'pen',
1:'mouse',
2:'controller'}
img0 = cv2.imread('0.jpg')
#print(img0.shape)
img = cv2.resize(img0, [320,320], interpolation=cv2.INTER_AREA)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = img.astype(np.float32) / 255.0
blob = np.expand_dims(np.transpose(img, (2, 0, 1)), axis=0)
outs = net.run(None, {net.get_inputs()[0].name: blob})[0].squeeze(axis=0) # run session,进行推理
print(np.array(outs).shape)
outs=post_process_opencv(outs,320,320,480,640,0.4,0.5)
print(outs)
print(outs[0][0])
xyxy=[int(i) for i in outs[0][0][0]]
print(xyxy)
print('%.2f'%outs[1][0][0])
print(outs[2][0][0])
for i in range(len(outs[0])):
xyxy=[int(i) for i in outs[0][i][0]]
label=dic_labels[outs[2][i][0]]+' %.2f'%outs[1][i][0]
plot_one_box(xyxy, img0, color=(255,0,0), label=label, line_thickness=2)
cv2.imwrite('img.jpg',img0)
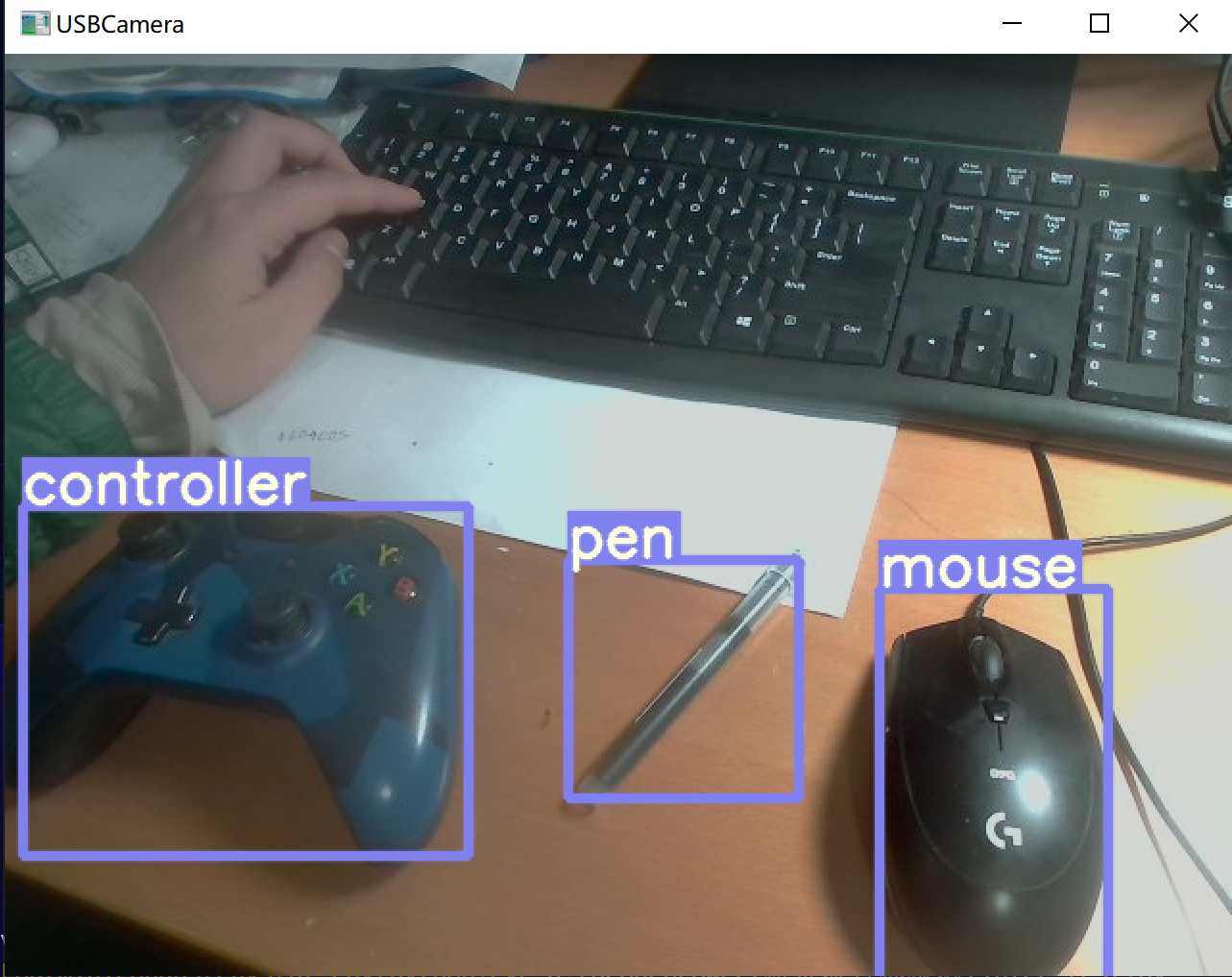
这边我使用的样本图片为训练集的第一张图片0.jpg,在Aidlux端利用onnxruntime推理效果如下:

7.喵提醒
当我们的桌面级监测系统检测到笔和鼠标时,说明孩子在正常的进行网课学习。当监测到手柄时,我们希望系统向家长的手机发送告警信息,此项功能我们使用喵提醒公众号来实现。
具体流程为: 关注喵提醒公众号—>点击右下角个人中心——>点击下方我的提醒——>新建提醒单——>复制喵码
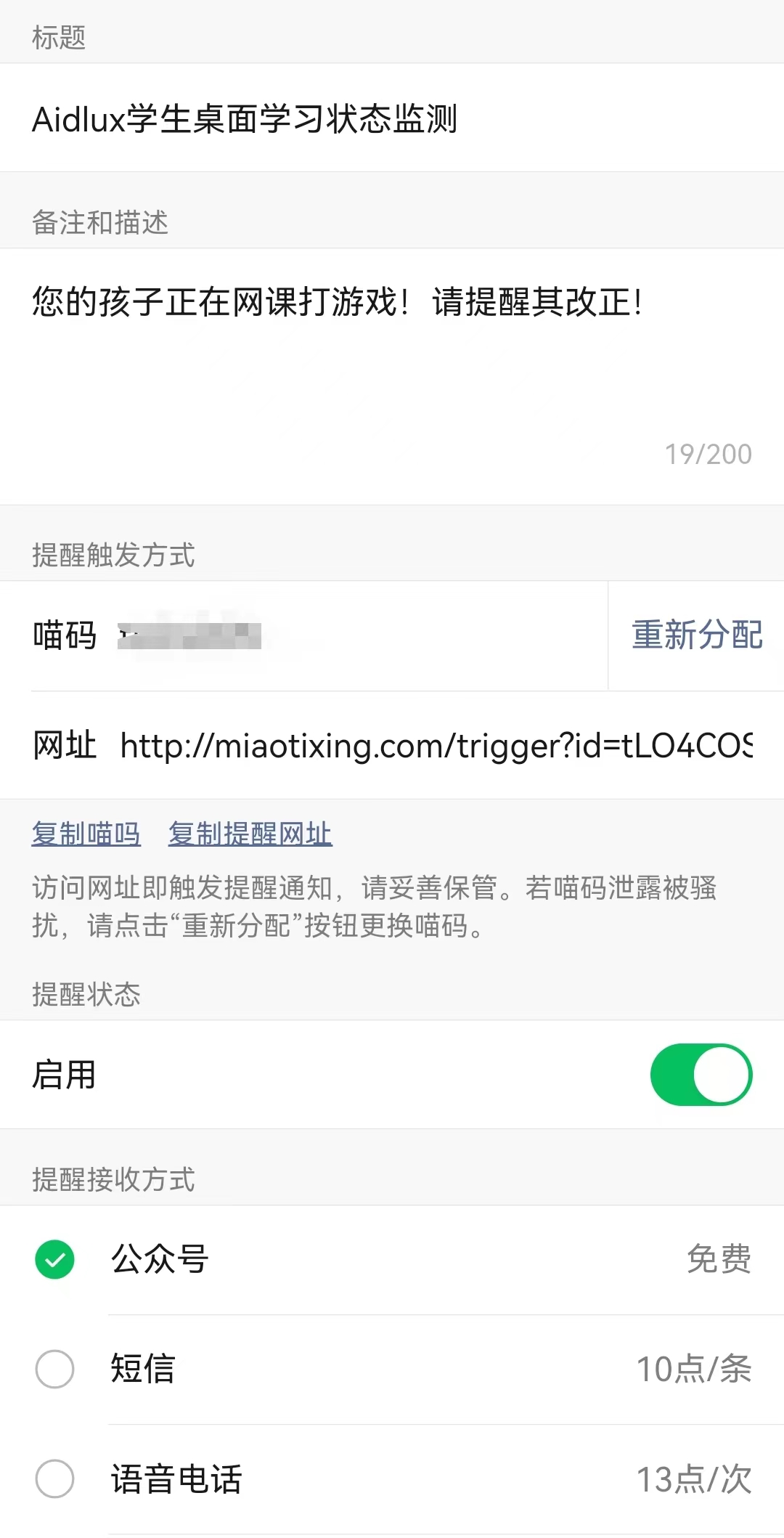
在成功创建提醒单之后,可以在Aidlux端先进行简单的测试:
import requests
import time
def sendmes(request_url,ids,text,headers):
ts=str(time.time())
type='json'
result=requests.post(request_url+"id="+ids+"&text="+text+"&ts="+ts+"&type="+type,headers=headers)
if __name__=='main':
id='miaoma' # 此处填入你的提醒单喵码
text="您的孩子正在用xbox玩游戏!"
ts=str(time.time()) # 时间戳
type='json'
request_url="http://miaotixing.com/trigger?"
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47'}
sendmes(request_url,id,text,headers)
8.Aidlux端摄像头监测实现
在有了前面的准备之后,我们就可以很轻松的在Aidlux端利用Onnxruntime框架实现部署,Aidlux端的主启动文件代码如下:
import cv2
from cvs import *
import onnxruntime as ort
import time
from miaotixing import sendmes
def plot_one_box(x, img, color=None, label=None, line_thickness=None):
"""
description: Plots one bounding box on image img,
this function comes from YoLov5 project.
param:
x: a box likes [x1,y1,x2,y2]
img: a opencv image object
color: color to draw rectangle, such as (0,255,0)
label: str
line_thickness: int
return:
no return
"""
tl = (
line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1
) # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(
img,
label,
(c1[0], c1[1] - 2),
0,
tl / 3,
[225, 255, 255],
thickness=tf,
lineType=cv2.LINE_AA,
)
def post_process_opencv(outputs,model_h,model_w,img_h,img_w,thred_nms,thred_cond):
conf = outputs[:,4].tolist()
c_x = outputs[:,0]/model_w*img_w
c_y = outputs[:,1]/model_h*img_h
w = outputs[:,2]/model_w*img_w
h = outputs[:,3]/model_h*img_h
p_cls = outputs[:,5:]
if len(p_cls.shape)==1:
p_cls = np.expand_dims(p_cls,1)
cls_id = np.argmax(p_cls,axis=1)
p_x1 = np.expand_dims(c_x-w/2,-1)
p_y1 = np.expand_dims(c_y-h/2,-1)
p_x2 = np.expand_dims(c_x+w/2,-1)
p_y2 = np.expand_dims(c_y+h/2,-1)
areas = np.concatenate((p_x1,p_y1,p_x2,p_y2),axis=-1)
areas = areas.tolist()
ids = cv2.dnn.NMSBoxes(areas,conf,thred_cond,thred_nms)
if len(ids)==0:
return None
return [np.array(areas)[ids],np.array(conf)[ids],cls_id[ids]]
model_pb_path = "best.onnx"
net = ort.InferenceSession(model_pb_path)
idw='tLO4COS'
text="您的孩子正在用xbox玩游戏!"
request_url="http://miaotixing.com/trigger?"
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47'}
cap=cvs.VideoCapture(0)
# 标签字典
dic_labels= {0:'pen',
1:'mouse',
2:'controller'}
count=0 # 计数器,计数到3触发警告
flag=0 # 是否发送过错误提示
while True:
frame=cvs.read()
if frame is not None:
#frame=infer(frame,640,480,dic_labels,net)
img = cv2.resize(frame, [320,320], interpolation=cv2.INTER_AREA)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = img.astype(np.float32) / 255.0
blob = np.expand_dims(np.transpose(img, (2, 0, 1)), axis=0)
outs = net.run(None, {net.get_inputs()[0].name: blob})[0].squeeze(axis=0)
#print(np.array(outs).shape)
outs=post_process_opencv(outs,320,320,640,480,0.4,0.5)
if outs==None:
cvs.imshow(frame)
continue
for i in range(len(outs[0])):
xyxy=[int(i) for i in outs[0][i][0]]
label=dic_labels[outs[2][i][0]]+' %.2f'%outs[1][i][0]
if dic_labels[outs[2][i][0]]=='controller' and not flag:
count+=1
plot_one_box(xyxy, frame, color=(255,0,0), label=label, line_thickness=2)
if count>=3 and not flag:
flag=1
print('idw is:',idw)
sendmes(request_url,idw,text,headers)
cvs.imshow(frame)
cvs.VideoCapture(x)函数将会指定打开的摄像头,0为设备后摄,1为设备前摄,也可以使用usb摄像头配上usb转typec转接口接入手机,然后2为接入的usb摄像头。
9.视频演示
ontinue
for i in range(len(outs[0])):
xyxy=[int(i) for i in outs[0][i][0]]
label=dic_labels[outs[2][i][0]]+’ %.2f’%outs[1][i][0]
if dic_labels[outs[2][i][0]]==‘controller’ and not flag:
count+=1
plot_one_box(xyxy, frame, color=(255,0,0), label=label, line_thickness=2)
if count>=3 and not flag:
flag=1
print(‘idw is:’,idw)
sendmes(request_url,idw,text,headers)
cvs.imshow(frame)
`cvs.VideoCapture(x)`函数将会指定打开的摄像头,0为设备后摄,1为设备前摄,也可以使用usb摄像头配上usb转typec转接口接入手机,然后2为接入的usb摄像头。
### 9.视频演示
[基于Yolo5Lite+onnx+Aidlux,全流程实现桌面级监测系统_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1R3411Q712/?vd_source=eb7dd8a00a65d532039bffb3bc73c7f5)















 508
508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









