







我本科不是计算机,也不是人工智能专业的相关的,我是学化学生物的。
人工智能研究生以来,我每次回看CNN的时候,我就想找一些项目练练手,我发现有一些人写了CNN进行Cifar10分类的项目,但是一般都很粗糙。我想这个应该算一个非常大众的开源项目了,咋就没有一点详细、大道至简、通俗易懂的项目展示呢???
直接上手代码吧!跟着代码做,如果实在不懂可以搜我的bilibili进行视频观看,里面有讲解(写这篇文章的时候,我才刚录好),我先给大家代码带来的效果:
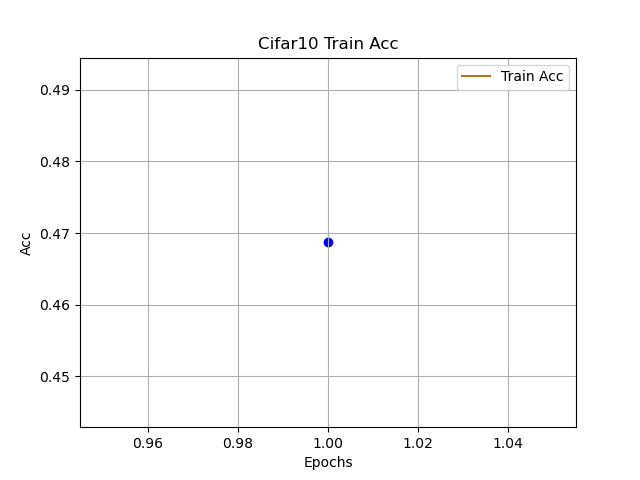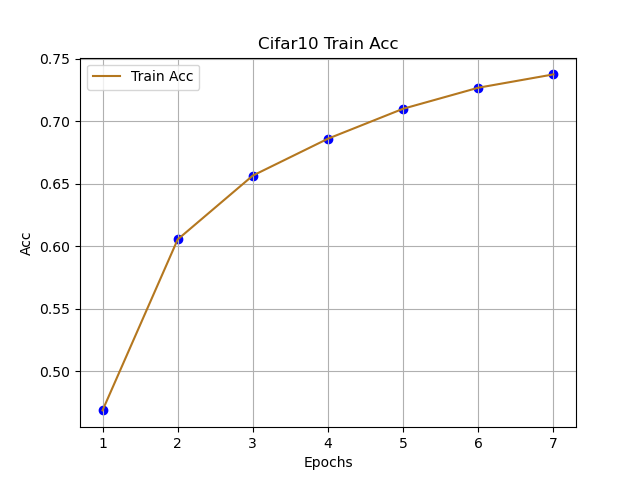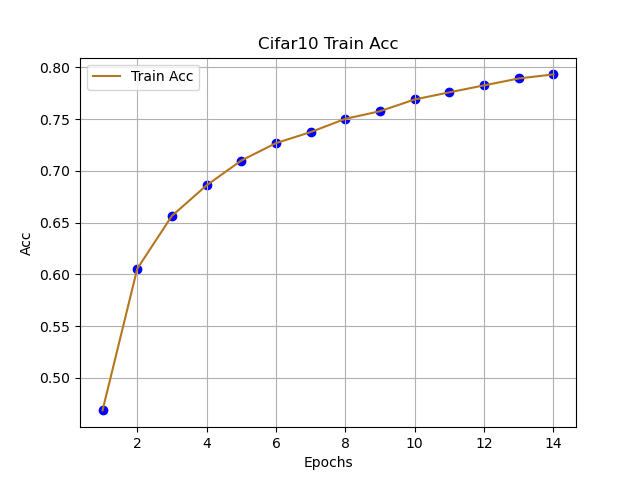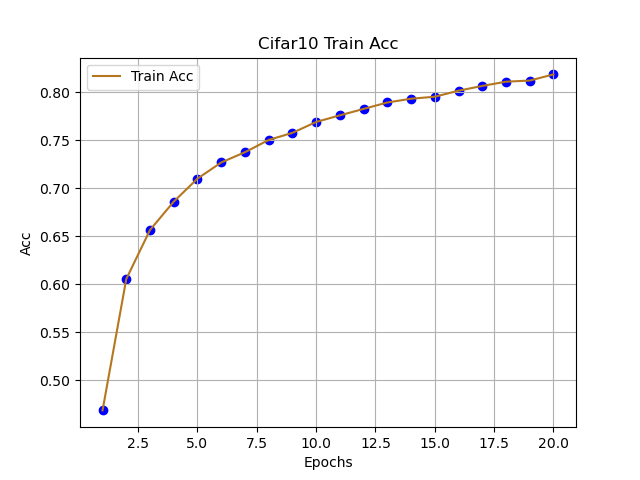
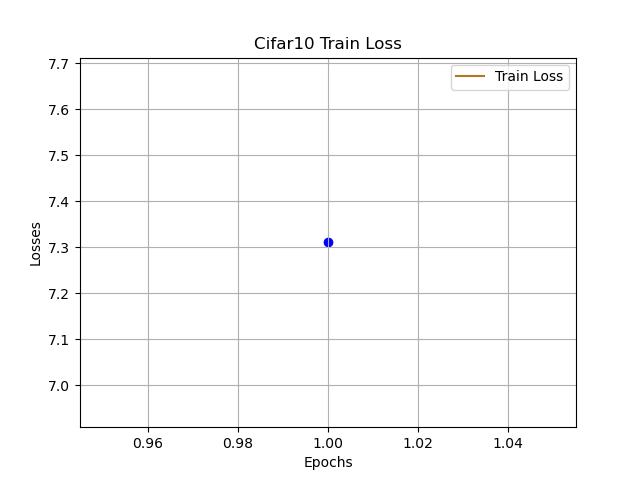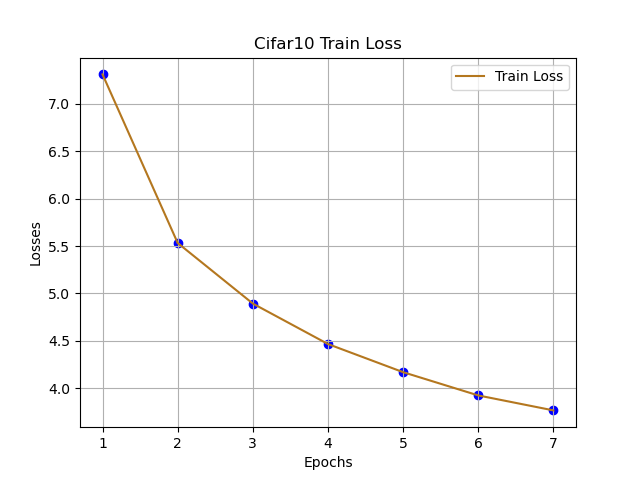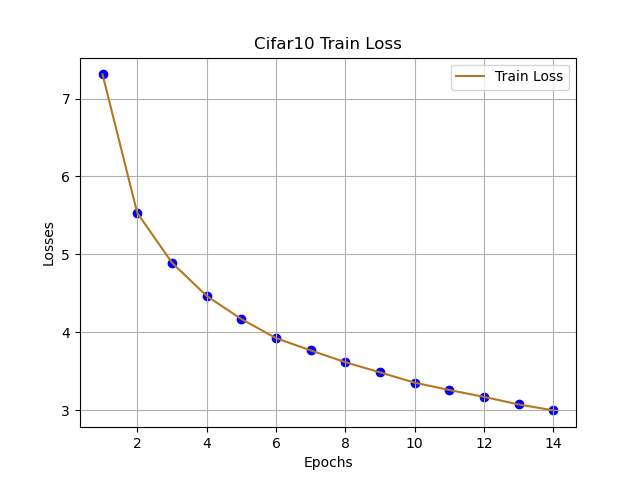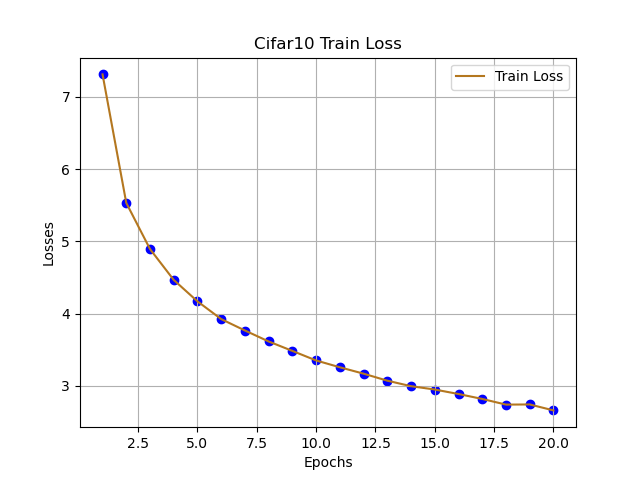
跟着代码走,这篇文章主要理解CNN网络在分类的基本流程,由于本人只是想讲清楚:CNN如何快速用于Cifar10分类,可能存在不足的地方,可在评论区提出想法,互相学习。
import torch
import torchvision
import matplotlib.pyplot as plt
import os
from torch.utils.data import DataLoader
# 计算设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Cifar10模型类
class Cifar10Net(torch.nn.Module):
def __init__(self,in_dim,out_dim,hidden_dim=64,lr=0.0003,model_file=None):
super(Cifar10Net, self).__init__()
self.conv_net = torch.nn.Sequential(
# 输出结果为(batch_size,hidden_dim,16,16)
torch.nn.Conv2d(in_channels=in_dim,out_channels=hidden_dim,kernel_size=(3,3),padding=1,stride=(1,1)),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=(2,2),stride=(2,2)),
torch.nn.BatchNorm2d(num_features=hidden_dim),
# 输出结果为(batch_size,hidden_dim,8,8)
torch.nn.Conv2d(in_channels=hidden_dim, out_channels=hidden_dim, kernel_size=(3, 3), padding=1, stride=(1, 1)),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2)),
torch.nn.BatchNorm2d(num_features=hidden_dim),
# 输出结果为(batch_size,hidden_dim,4,4)
torch.nn.Conv2d(in_channels=hidden_dim, out_channels=hidden_dim, kernel_size=(3, 3), padding=1,stride=(1, 1)),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2)),
torch.nn.BatchNorm2d(num_features=hidden_dim),
)
self.linear_net = torch.nn.Sequential(
torch.nn.Flatten(),
# 输入维度:hidden_dim*4*4
torch.nn.Linear(in_features=hidden_dim*4*4,out_features=1024),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(in_features=1024, out_features=256),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(in_features=256, out_features=out_dim),
)
# 读取已存在模型
if model_file != None and os.path.exists(model_file):
self.load_state_dict(torch.load(model_file))
print("成功读取模型...")
self.loss_fn = torch.nn.CrossEntropyLoss().to(device)
self.optimizer = torch.optim.Adam(self.parameters(),lr=lr)
def forward(self,x):
conv_out = self.conv_net(x)
out = self.linear_net(conv_out)
return out
# 画训练图
def plot_logs(y,pic_label,ylabel,title,epoch):
x = range(1,1+len(y))
plt.plot(x,y,label=pic_label)
plt.scatter(x,y,color="r")
plt.legend()
plt.grid()
plt.xlabel("Epochs")
plt.ylabel(ylabel)
plt.title(title)
plt.savefig(f"logs/{epoch}_cifar10_{title}.png")
plt.cla()
# 训练主函数
def main():
# 训练集 数据预处理对象
transformer_train = torchvision.transforms.Compose([
# 图片数据裁剪为(32,32)
torchvision.transforms.RandomCrop(size=(32,32),padding=4),
# 图片按50%概率随机水平翻转
torchvision.transforms.RandomHorizontalFlip(p=0.5),
torchvision.transforms.ToTensor(),
])
# 测试集 数据与处理对象
transformer_test = torchvision.transforms.Compose([
# 图片数据裁剪为(32,32)
torchvision.transforms.RandomCrop(size=(32,32),padding=4),
# 图片按50%概率随机水平翻转
torchvision.transforms.RandomHorizontalFlip(p=0.5),
torchvision.transforms.ToTensor(),
])
# 训练集 读取
train_data = torchvision.datasets.CIFAR10(root="datasets",train=True,download=True,transform=transformer_train)
test_data = torchvision.datasets.CIFAR10(root="datasets",train=False,download=True,transform=transformer_test)
# 训练集和测试集 个数
train_data_size = len(train_data)
test_data_size = len(test_data)
# 数据 迭代器
batch_size = 64
train_data_batch = DataLoader(dataset=train_data,batch_size=batch_size,shuffle=True,drop_last=True)
test_data_batch = DataLoader(dataset=test_data,batch_size=batch_size,shuffle=True,drop_last=True)
# 每个数据集有多少个批数据
train_batch_nums = len(train_data_batch)
test_batch_nums = len(test_data_batch)
# 模型文件夹
model_dir = "models/"
log_dir = "logs/"
cur_model_file = model_dir + "cur_cifar10.pth"
if not os.path.exists(model_dir):
os.mkdir(model_dir)
os.mkdir(log_dir)
# 模型参数
in_channels = 3
out_dim = 10
hidden_dim = 64
lr=0.0003
cifar_net = Cifar10Net(in_channels,out_dim,hidden_dim,lr,cur_model_file).to(device)
# 查看模型结构
print(cifar_net)
# 训练参数
epochs = 20
losses = []
accs = []
for epoch in range(1,1+epochs):
# 模型训练模型
cifar_net.train()
# 每局训练损失和准确率
epoch_loss = 0.0
epoch_acc = 0.0
for index , (imgs,targets) in enumerate(train_data_batch,start=1):
# 数据放入计算设备
imgs, targets = imgs.to(device) , targets.to(device)
# 前向传播
outs = cifar_net(imgs)
# 计算损失
loss = cifar_net.loss_fn(outs,targets)
epoch_loss += loss.item()
# 计算准确率
acc = (outs.argmax(axis=1) == targets).sum().item()
epoch_acc += acc
# 反向传播
cifar_net.optimizer.zero_grad()
loss.backward()
cifar_net.optimizer.step()
print(f"Epoch:[{epoch}|{epochs}], Batch:[{index}|{train_batch_nums}], Loss:{round(loss.item(),4)}, Acc:{round(acc/batch_size,4)*100}%.")
# 每一局损失和准确率
losses.append(epoch_loss / test_batch_nums)
accs.append(epoch_acc / train_data_size)
plot_logs(losses,"Train Loss","Losses","Cifar10 Train Loss",epoch)
plot_logs(accs,"Train Acc","Acc","Cifar10 Train Acc",epoch)
# 模型保存
torch.save(cifar_net.state_dict(),cur_model_file)
# 模型测试
cifar_net.eval()
accuracy = 0
with torch.no_grad():
for imgs , targets in test_data_batch:
# 前向传播
outs = cifar_net(imgs)
accuracy += (outs.argmax(axis=1) == targets).sum().item()
# 所有图片的测试 准确率
accuracy /= test_data_size
print("#"*50)
print(f"Epoch:[{epoch}|{epochs}], Accuracy:{round(accuracy,4)*100}%.")
print("#"*50)
if accuracy >= 0.95:
print("任务成功...")
break
if __name__ == "__main__":
main()
给个赞~谢谢各位学霸了~















 1182
1182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









