







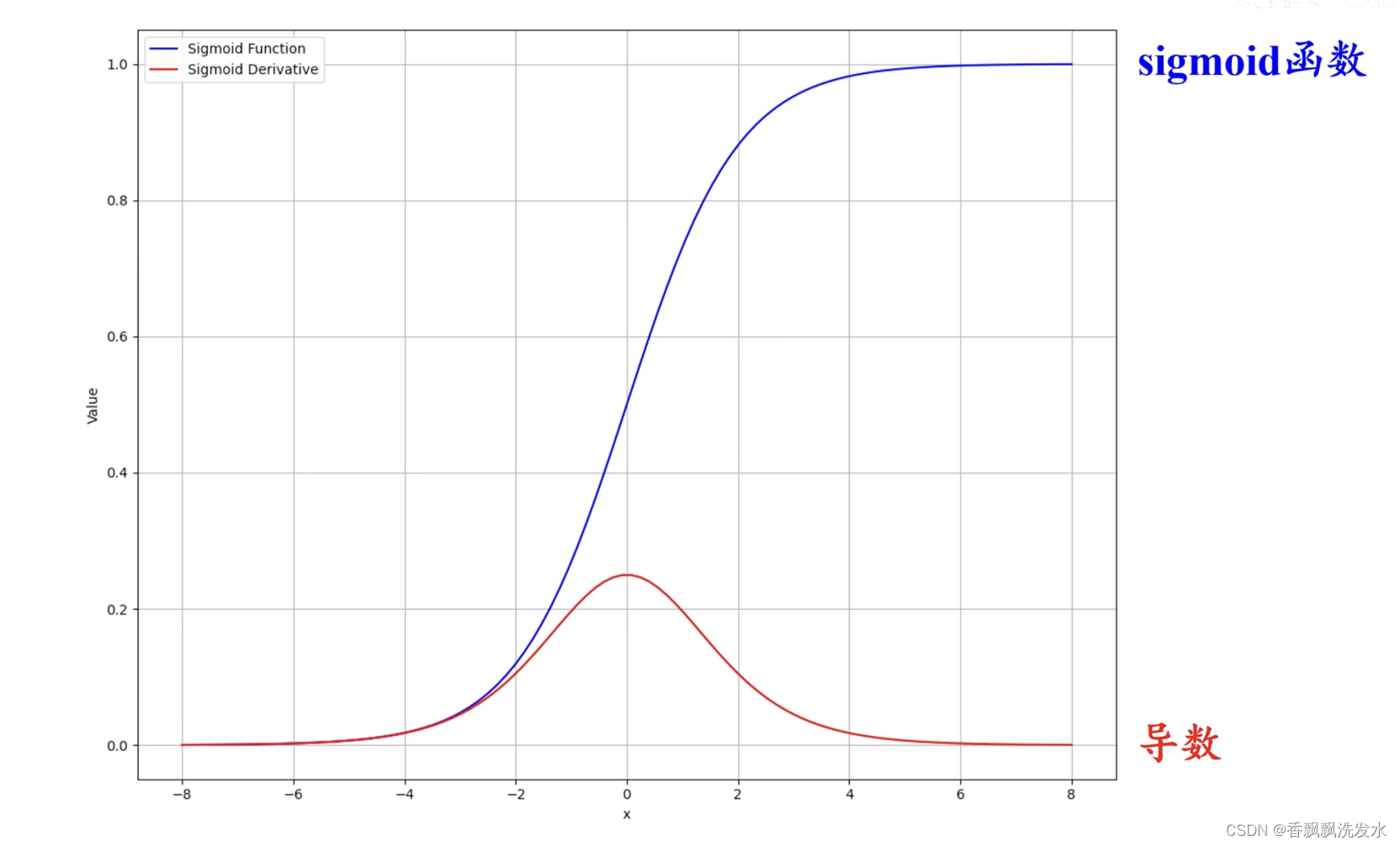
一、Sigmoid函数 /逻辑斯谛回归函数
理想下的激活函数满足条件:
1.单侧饱和,可以避免噪声,截断为0
2.输出值分布在0的两侧
优点
Sigmoid 函数取值范围为(0,1),这可以对输出进行归一化,使其可解释为概率值,非常适合二分类问题中的输出层
缺点
1. 输入的绝对值越来越大,梯度逐渐接近于0,会发生梯度饱和,链式求导过程中出现梯度消失现象,导致模型无法收敛
2.为神经元输入,
为损失函数,u为学习率
各权重w损失函数值相同,不同在于,它的值取决于Sigmoid,因此取值恒大于0
因此的正 负一致,即w更新方向一致
3.sigmoid函数存在复杂的幂运算,存在运算效率问题

w的更新方向相同,则迭代需要走Z型,导致模型收敛速度减慢
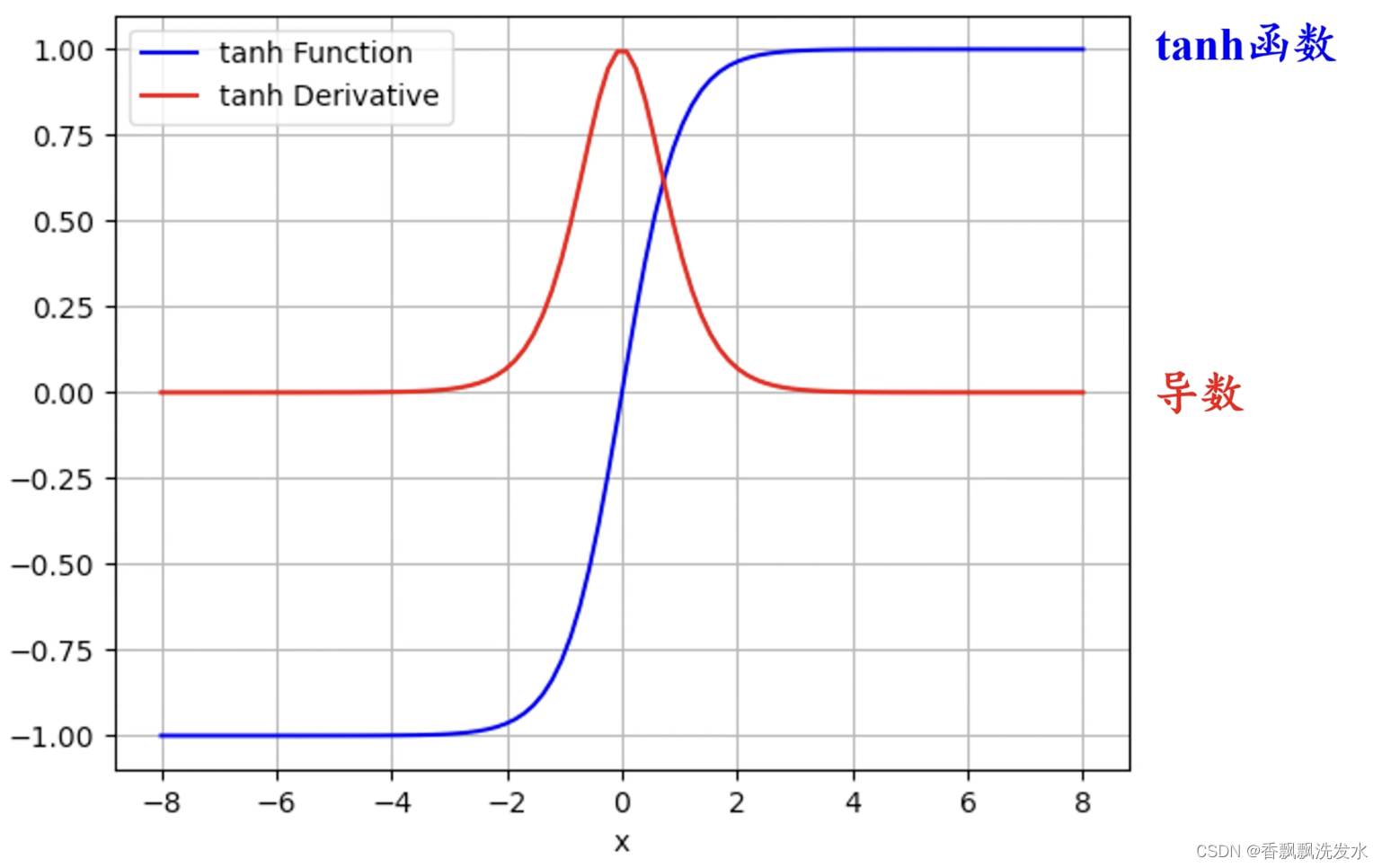
二、tanh函数/双曲正切函数
优点
tanh值域为(-1,1)能够有效解决sigmoid函数恒大于0,收敛慢的问题
缺点
1.依旧存在梯度饱和问题,会出现梯度消失
2.tanh函数存在复杂的幂运算,存在运算效率问题
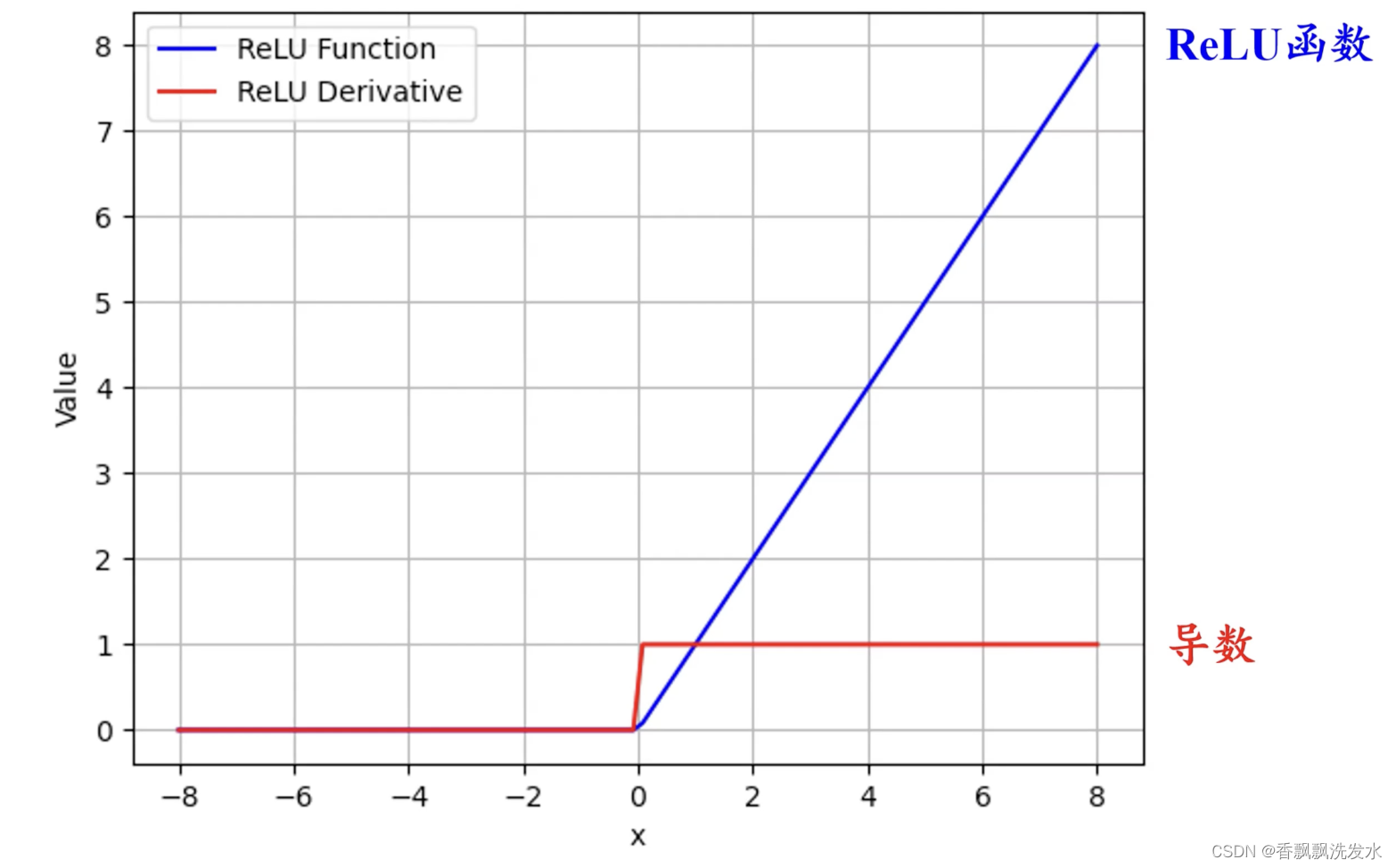
三、ReLU函数/线性整流函数
优点
1.深度学习常用的激活函数,输入为正值时,梯恒为1,激活函数等于输入值,解决了梯度消失的问题
2.ReLU函数只存在线性关系,计算复杂度小,运算效率高
缺点
1.当ReLU输入为负值时,输出为0,反向传播更新参数时, 对应梯度为0,W则得不到更新,此外若学习率u过大,更新的W会成为负值,通过ReLU函数输出为0,导致神经元永久输出为0神经元会出现永久失活。常被称为Dead ReLU问题
2.ReLU输出值为为负,存在梯度更新时,收敛速度慢的问题
四、Leaky ReLU函数

优点
1.可以有效解决Dead ReLU问题
为一个很小的正数,通常设置为0.01,当输入值小于等于0时,激活函数输出为一个很小的负值, 反向传播过程中,输入小于0的部分也可以得到梯度
缺点
1.性能依赖于取得的参数
取值方法:
- 随机Leaky ReLU
分布满足均值为0,标准差为1的正态分布,同时引入随机噪声,可以帮助参数跳出局部最优点和鞍点
- Parametric ReLU
将作为学习参数
2.用于深度神经网络时,在反向传播过程中,由于连乘效应可能发生梯度消失
五、ELU激活函数

优点
1.满足单侧饱和带来的优势,提高网络的训练速度和稳定性
2.减少梯度爆炸问题,ELU在负输入值时输出的下限。当 x 的值变得非常小(即远小于0)时,,因此
,使得ELU的输出趋近于
。这意味着无论输入值下降到多么低,ELU的输出都会趋于一个常数值
,而不是继续减小,限制了梯度增幅
缺点
1.性能会依赖于参数,通常参数
=1
2.ReLU及其变种相比,ELU在负输入部分涉及指数运算,这使得它的计算成本相对更高,特别是在前向传播和反向传播过程中。
3.用于深度神经网络时,在反向传播过程中,由于连乘效应可能发生梯度消失
六、Swish激活函数
为sigmoid函数,
为可调节参数
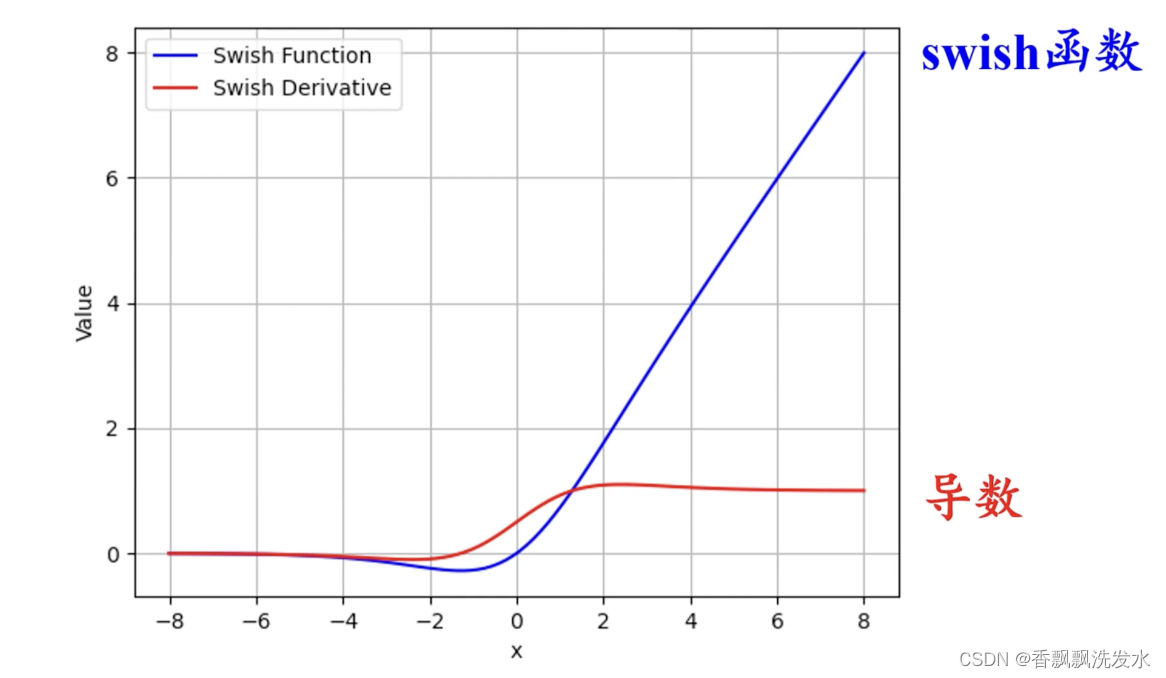
sigmoid函数起到类似门控单元的作用,Swish激活函数将输入信号现通过门控单元,得到的输出再与输入信号相乘得到最终输出。
门控单元信号大于0时,swish函数激活;门控单元信号小于0时,swish函数失活
优点
1.非单调性的性质,可以提高训练速度,同时能够提高神经网络的准确率
2.负输入值不是完全为0,减少梯度消失的问题
缺点
1.相比于ReLU及其他简单变体相比,运算量更大
2.参数影响训练效果,同时可能也会发生过拟合















 853
853











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









