







0x1 前言
挖掘CNVD漏洞有时候其实比一般的edusrc还好挖,但是一般要挖证书的话,还是需要花时间的,其中信息收集,公司资产确定等操作需要花费一定时间的。下面就记录下我之前跟一个师傅学习的一个垂直越权成功的CNVD漏洞通杀(仅作为思路分享)。
0x2 信息收集——github
简介
在漏洞挖掘的过程前期我们进行信息收集,github和码云搜索相关的信息,代码库,运气好的话可以在库中发现一些重要配置如数据库用户密码等。
这里先给师傅们分享一下手工github搜索语法:
in:name baidu #标题搜索含有关键字baidu
in:descripton baidu #仓库描述搜索含有关键字
in:readme baidu #Readme文件搜素含有关键字
stars:>3000 baidu #stars数量大于3000的搜索关键字
stars:1000..3000 baidu #stars数量大于1000小于3000的搜索关键字
forks:>1000 baidu #forks数量大于1000的搜索关键字
forks:1000..3000 baidu #forks数量大于1000小于3000的搜索关键字
size:>=5000 baidu #指定仓库大于5000k(5M)的搜索关键字
pushed:>2019-02-12 baidu #发布时间大于2019-02-12的搜索关键字
created:>2019-02-12 baidu #创建时间大于2019-02-12的搜索关键字
user:name #用户名搜素
license:apache-2.0 baidu #明确仓库的 LICENSE 搜索关键字
language:java baidu #在java语言的代码中搜索关键字
user:baidu in:name baidu #组合搜索,用户名baidu的标题含有baidu的
等等..
然后再给师傅们分享下github官方文档:GitHub检索文档
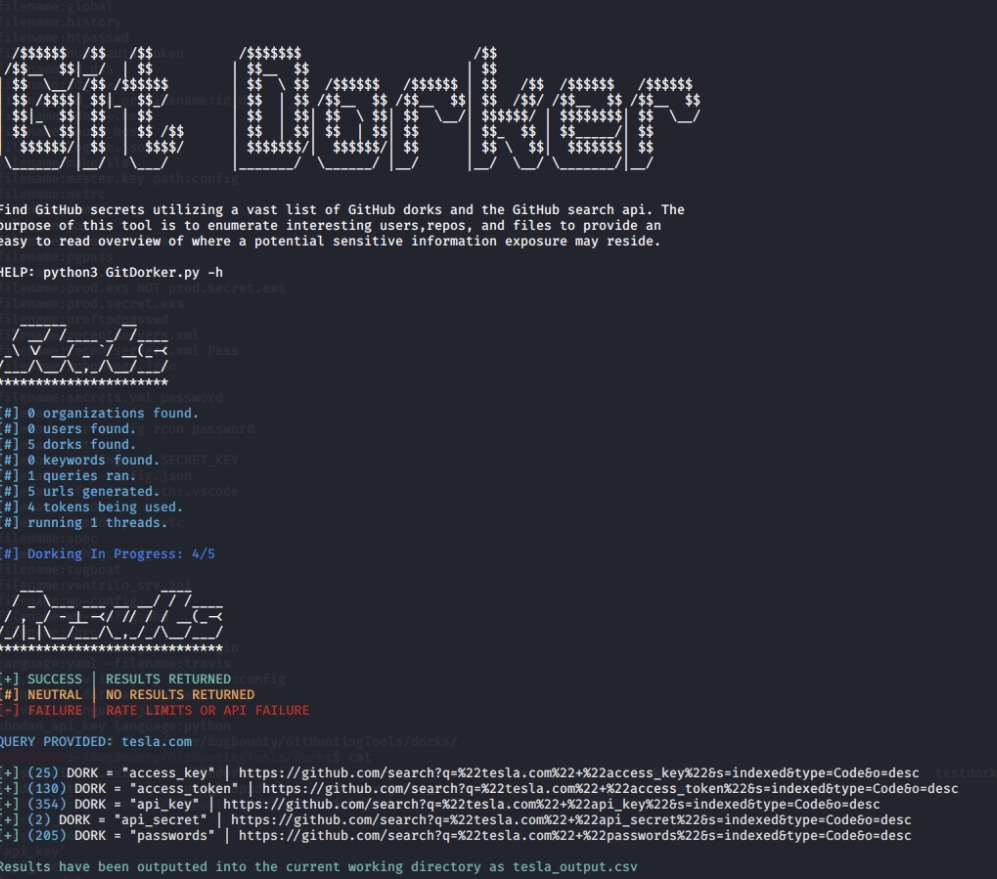
自动化工具——GitDorker
GitDorker工具下载GitDorker是一款github自动信息收集工具,它利用 GitHub 搜索 API 和作者从各种来源编译的大量 GitHub dorks 列表,以提供给定搜索查询的 github 上存储的敏感信息的概述。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6115
6115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









