







DP算法
动态规划算法。
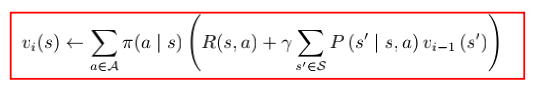
MC算法
蒙特卡罗算法就是说当得到一个 MRP过后,我们可以从某一个状态开始,产生一个轨迹,得到一个奖励,当积累到一定的轨迹数量过后,直接用 Gt(总收益之和) 除以轨迹数量,就会得到它的价值。
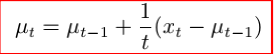
incremental MC方法:
![]()
TD算法
TD 是 model-free 的,不需要 MDP 的转移矩阵和奖励函数。对于某个给定的策略 π,在线 (online) 地算出它的价值函数 vπ,即一步一步地 (step-by-step)算。
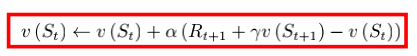
SARSA算法
Sarsa: On-policy TD Control
Sarsa 所作出的改变很简单,就是将原本我们 TD 更新 V 的过程,变成了更新 Q。
该算法由于每次更新值函数需要知道当前的状态 (state)、当前的动作 (action)、奖励 (reward)、下一步的状态 (state)、下一步的动作 (action),即 (St , At , Rt+1, St+1, At+1) 这几个值,由此得名 Sarsa 算法。
Sarsa 属于单步更新法,也就是说每执行一个动作,就会更新一次价值和策略。
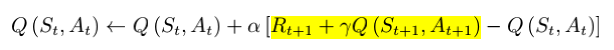
Q-learning算法
Q-learning: Off-policy TD Control
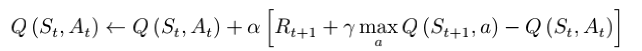
DQN算法——状态量巨大甚至是连续的任务
线性函数近似的缺点在于人为地寻找特征,DQN算法采用人工神经网络自动寻找特征。
DQN 是指基于深度学习的 Q-learning 算法,主要结合了值函数近似 (Value Function Approximation)与神经网络技术,并采用了目标网络和经验回放的方法进行网络的训练。
初始化两个网络;与环境交互获得经验数据(st, at ,rt, st+1);将经验数据存储于buff中;从buff中采样一批数据;用目标网络计算目标(希望目标与Q值越接近越好);更新一定次数之后,将Q估计设置为Q,这就是DQN。
Double DQN算法——解决argmax问题/Q值过高估计问题
DQN 由于总是选择当前值函数最大的动作值函数来更新当前的动作值函数,因此存在着过估计问题(估计的值函数大于真实的值函数)。为了解耦这两个过程,double DQN 使用了两个值网络,一个网络用来执行动作选择,然后用另一个值函数对一个的动作值更新当前网络。
PG算法——解决连续动作难计算的问题
策略梯度(Policy Gradient, PG)方法的核心思想在于是能获得更好的回报的动作的采样概率不断提高,使获得更少回报的动作的采样概率不断降低,从而达到一个最优的策略。
策略梯度算法广泛应用于具有连续动作空间的强化学习问题。基本思想是代表策略参数概率分布![]() 。在某个状态下根据参数向量
。在某个状态下根据参数向量![]() 随机选择行动
随机选择行动![]() 。策略梯度算法通常是通过对这种随机策略进行抽样,并根据累积收益的增加来调整策略参数。
。策略梯度算法通常是通过对这种随机策略进行抽样,并根据累积收益的增加来调整策略参数。
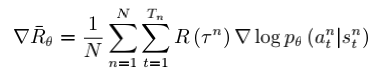
reinforce算法
REINFORCE: Monte Carlo Policy Gradient

我们就是从后往前推,一步一步地往前推,先算 GT,然后往前推,一直算到 G1,拿到每个步骤的奖励,然后计算每个步骤的未来总收益 Gt 是多少,然后拿每个 Gt 代入公式,去优化每一个动作的输出。
AC算法
演员-评论家算法 (Actor-Critic Algorithm) 是一种结合策略梯度和时序差分学习的强化学习方法。对于 actor-critic 方法,我们不是直接使用每一步得到的数据和反馈进行 policy π 的更新,而是使用这些数据进行 estimate value function,接下来我们再基于value function 来更新我们的 policy。
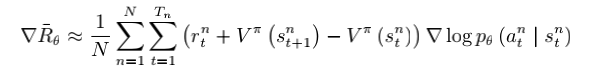
多摇臂问题
多摇臂问题。没有状态转移。reward是随机的。DQN的样本有效性不高,多摇臂算法的样本有效性高。用历史数据估计,然后基于Q值最大的原则选择action,但是这样会导致陷入局部最优解,所以使用贪婪算法。UCB算法,复习的时候不用推导。UCB的问题是没有利用先验信息,导致算法比较慢。
UCB算法

蒙特卡洛树搜索算法
蒙特卡洛树搜索是一种概率搜索算法。
Monte Carlo Tree Search, 是一类树搜索算法的统称。
- 蒙特卡洛树搜索是一种基于树数据结构、能在搜索空间巨大仍然比较有效的启发式搜索算法
- MCTS是一种逼近纳什均衡的搜索策略。
四大阶段:选择、扩展、模拟、回溯/反向传播。
UCT (UCB for Tree)算法,可以说是最经典的蒙特卡罗树搜索算法。
蒙特卡洛树搜索,结合model-based和马尔可夫,model-based就是通过经验去学习model,怎么学习?似然估计,出现次数/奖励。得到R,P,得到马尔可夫决策过程,就可以用策略迭代或者值函数迭代去求解。
贝叶斯算法
这一算法的基本思路是给定老虎机收益的先验分布,然后通过该分布来决定玩哪个老虎机,收集到信息之后再更新后验分布。为了保持先验分布和后验分布的形式一致,往往需要 共轭分布 (Conjugate Distribution)的帮助。比如说各个老虎机的回报服从伯努利分布,为了估计伯努利分布的参数,起初我们假设该参数均匀分布在[0,1]之间,然后其共轭分布便是beta分布,并且在更新的过程中,总是保持beta分布的形式,只是相应的参数有所变化。
贝叶斯方法,利用先验信息,计算比较快,统计学的思路。假设先验和后验共轭分布。先验信息初始化,采取行为(摇一下),得到Reward,更新先验信息,形成后验信息,先验信息和后验信息同一个分布,也就是共轭分布。
参考资料:















 932
932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









