







概率论知识补充
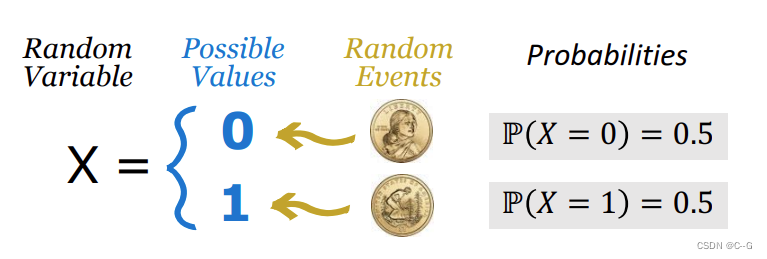
Random Variable
抛硬币是随机事件,正面朝上与反面朝上概率都是0.5,通常使用X表示随机变量,x表示观测值
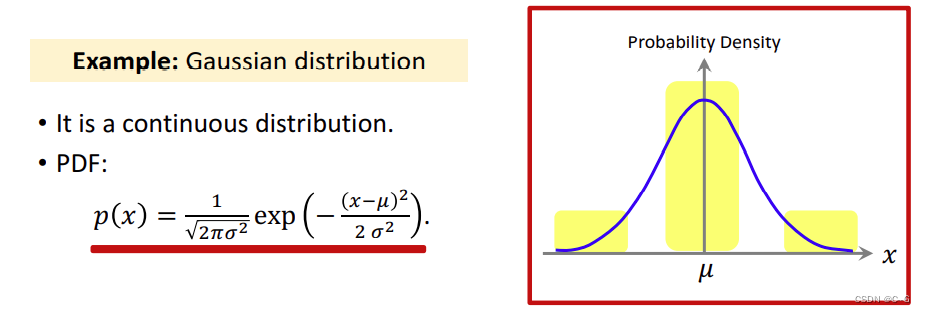
Probability Density Function (PDF)
概率密度函数意味着某个随机变量在某个确定的取值点附件的可能性
高斯分布
离散概率分布

概率密度函数如果为连续型,则函数积分和为1,离散型所有取值和为1

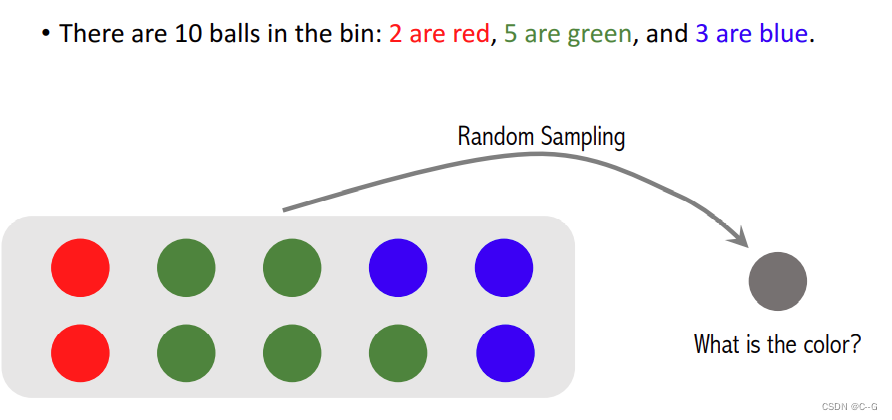
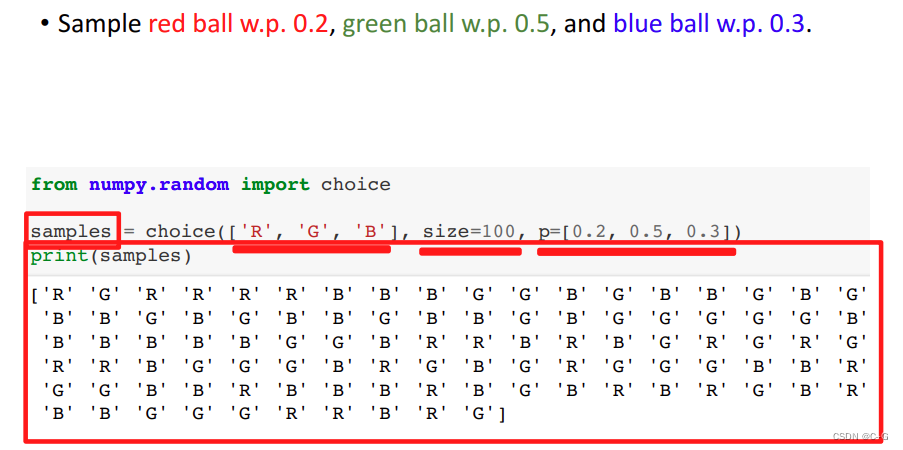
Random Sampling
随机抽样
强化学习基础
强化学习概念名词
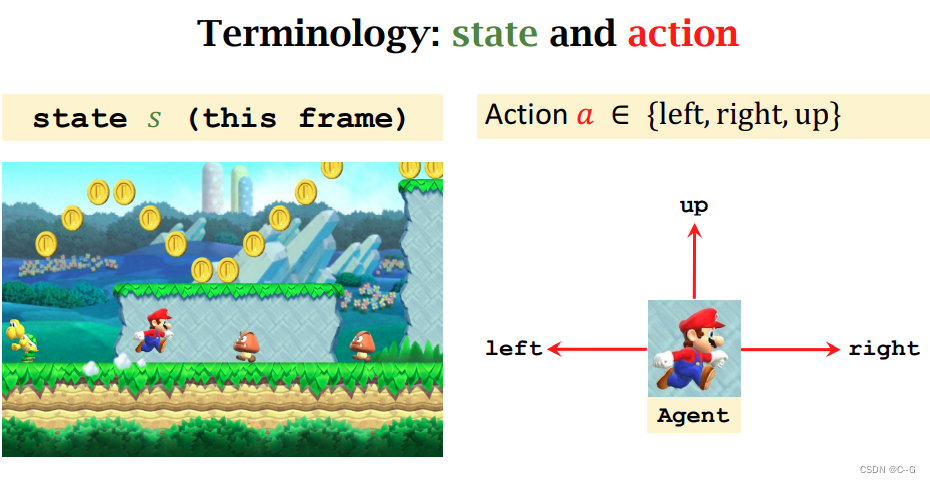
state:状态
action:动作
agent:智能体

policy:策略(概率密度函数)

各个动作的概率,使用随机的策略,更切合现实,不易看出规律

reward:奖励
要根据实际情况设置奖励,如:吃到金币奖励+1,游戏通过奖励+10000,玛丽淘汰奖励-10000,什么也没发生奖励是0,强化学习的目的是提高获得的奖励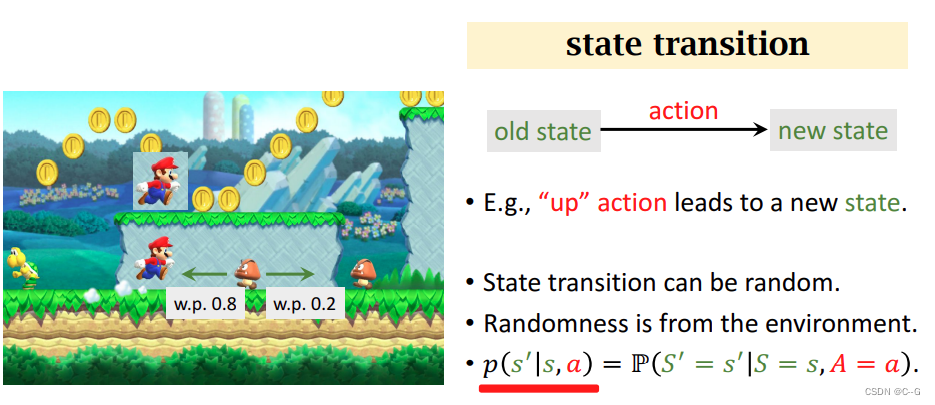
state transition:状态转移
状态转移是随机的,状态转移概率密度函数只有环境知道,玩家不知道
简介
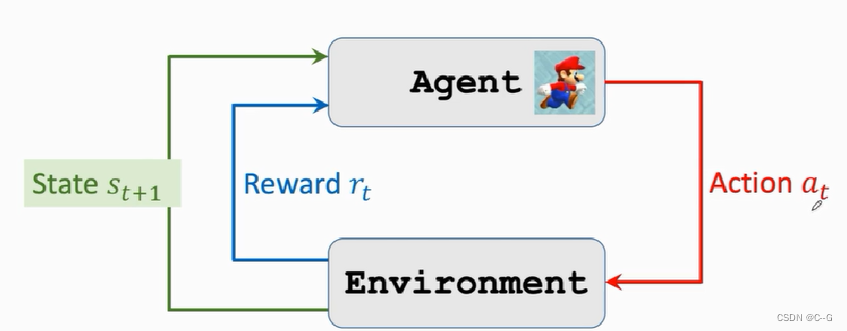
agent采取action,environment的state改变同时返回reward给agent,agent根据reward进行学习
- 强化学习中随机性的来源
action的随机性

state的随机性

- AI如何玩游戏
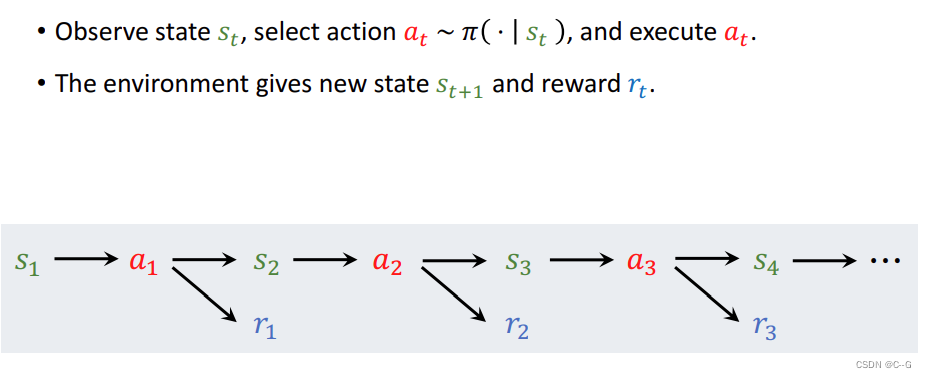

观察state s1,Agent利用policy函数执行action a1,environment生成新的state s2并返回的reward r1给agent ,agent再次利用policy函数执行action a2。。。。。。循环该操作 - Rewards and Returns

- 回报
return:回报,也就是未来的累积奖励
Ut由Rt到游戏结束Rn累加所得。当前reword应该比后期reword权重大,比如:今天的80元比明天100元来得实际

y:折扣汇报,介于0-1
- 汇报的随机性


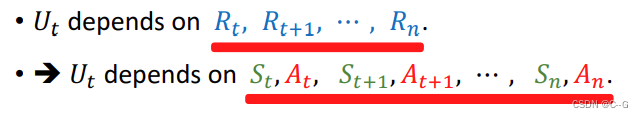
t时刻return取决于t到n时刻的reward,reward取决与state和action,所以return也取决与state和action
- Value Function
action-value function——动作价值函数


对于Ut而言,St和At是可以观察的,St+1——Sn,和At+1——An是随机变量

St+1概率与St,At有关,At+1概率与St+1有关
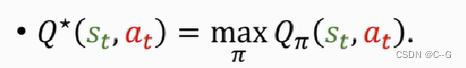
state-value function——状态价值函数
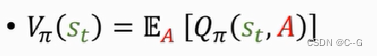

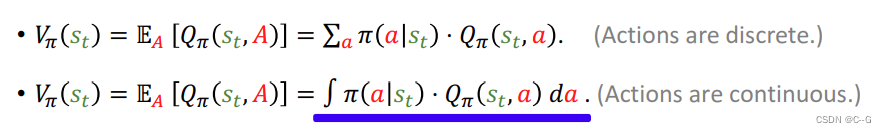

- Ai control the agent

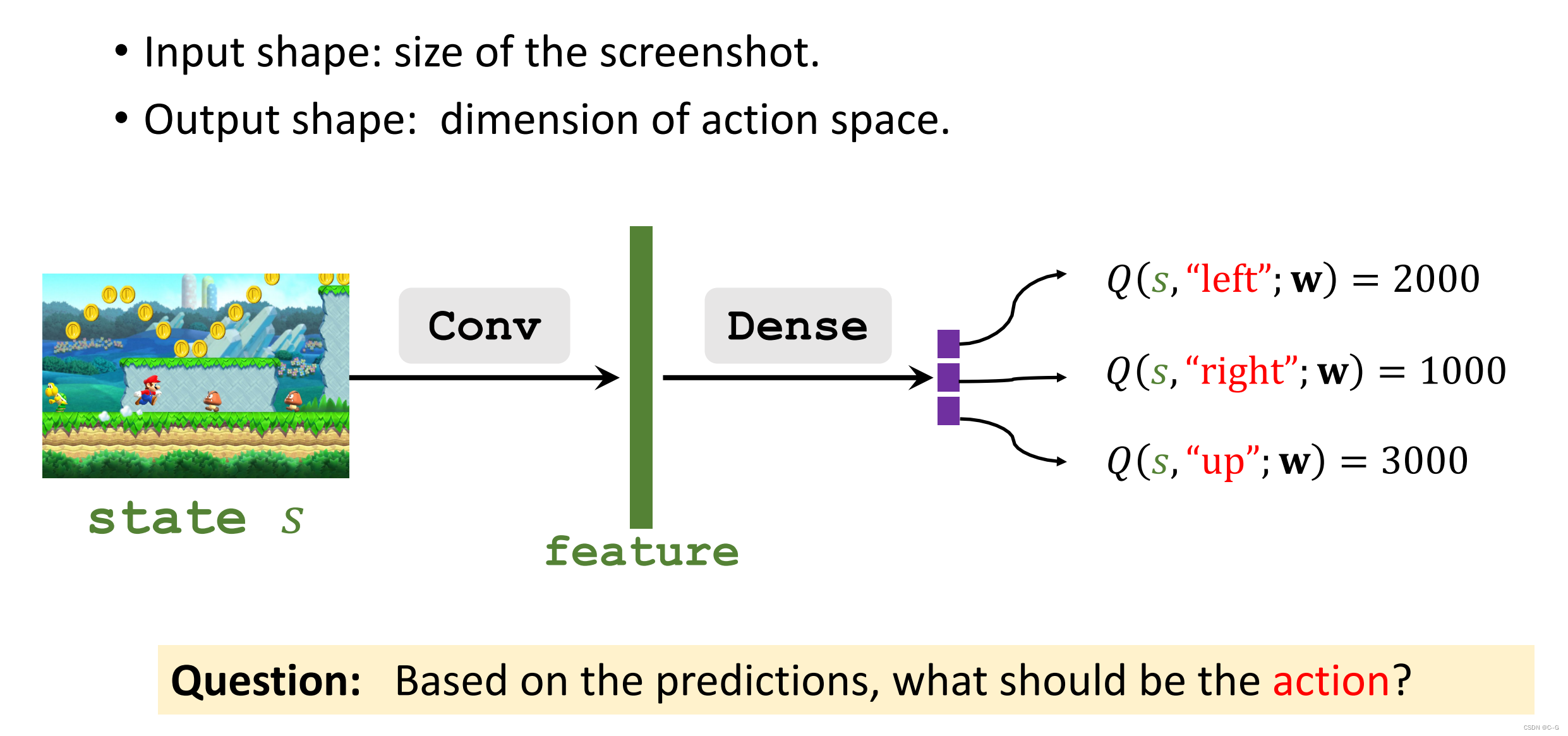
Π(a|s)策略学习函数,在state情况下最优action,Q(s,a)计算各个动作的得分,选择最优*
评估强化学习
OpenAI Gym




总结

Deep Q-Network(DQN)

Q 就像是挂,给我们游戏提供最优策略,然后现实是不存在的*

我们可以使用神经网络去近似Q*
Temporal Difference (TD) Learning
论文
Sutton and others: A convergent O(n) algorithm for off-policy temporal-difference learning with linear function approximation. In NIPS, 2008.
Sutton and others: Fast gradient-descent methods for temporal-difference learning with linear function approximation. In ICML, 2009
例子

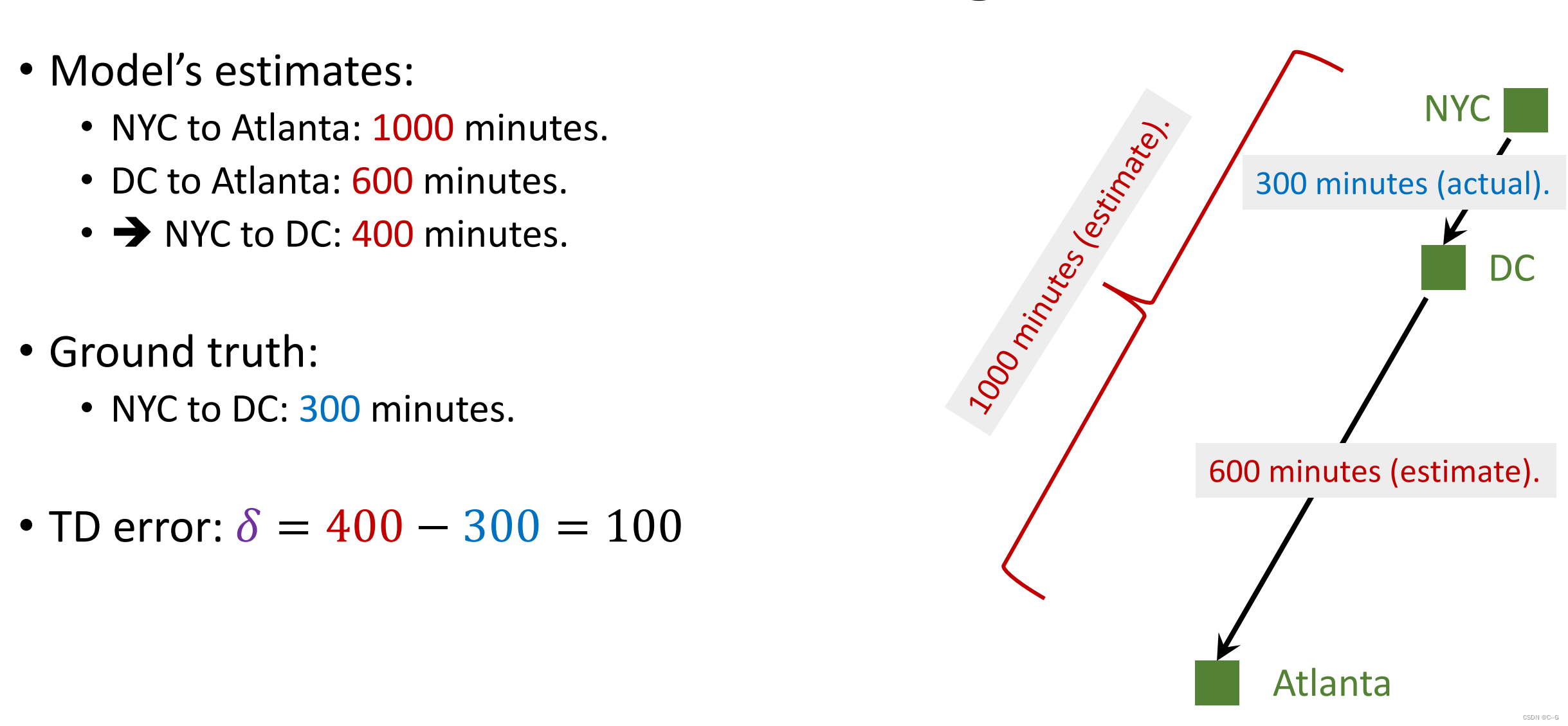
从NYC到Atlanta,模型预测要1000分钟,实际需要860分钟,那么以方差为损失,就可以进行梯度优化,听起来就像是普通的回归
那么我就开到中途就停车了,我不去Atlanta了,我还能获得更好的w来优化模型么?答案是可以的


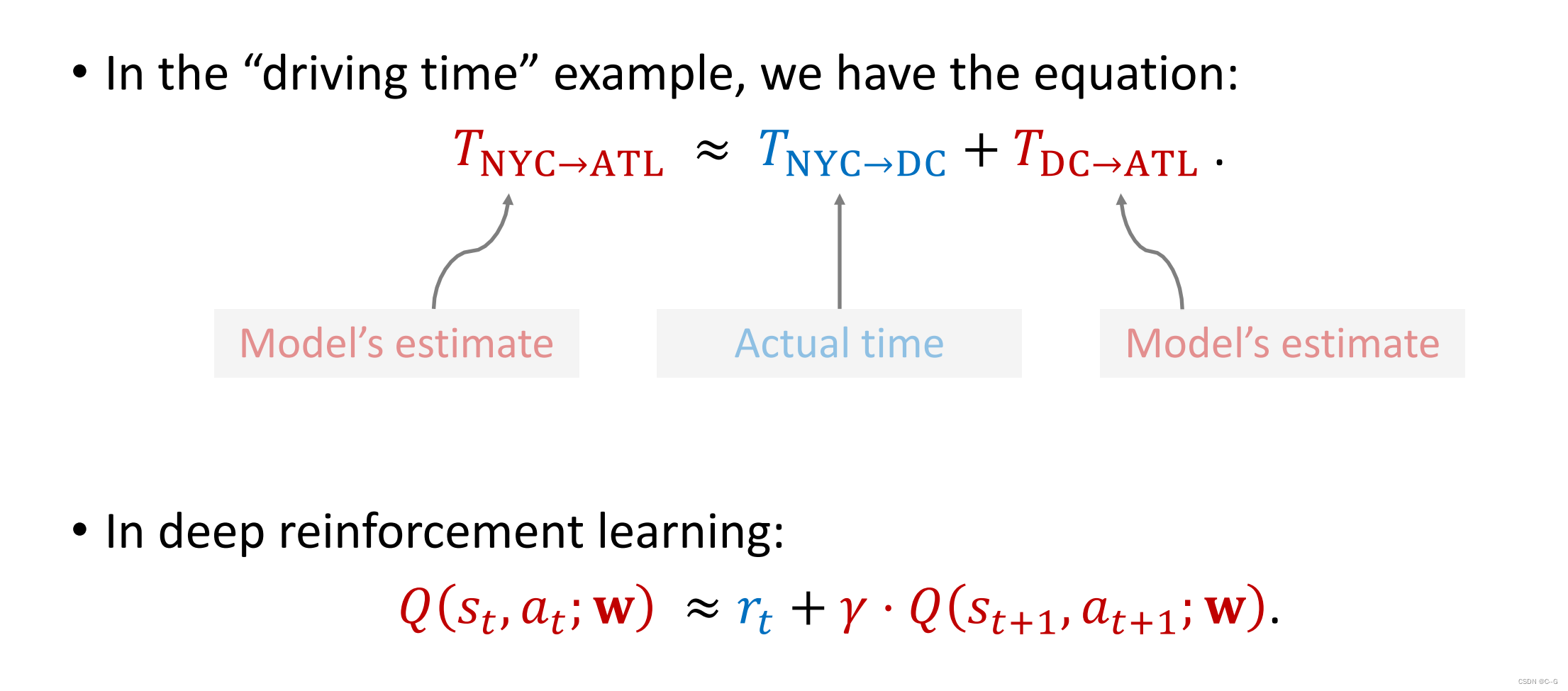
虽然我到DC就停了,这里我们可以测量从NYC到DC需要300分钟,模型再预测需要900分钟从DC到Atlanta,那么就可以用1000和(300+600)来计算损失,优化模型
- TD Learning
DQN应用TD Learning
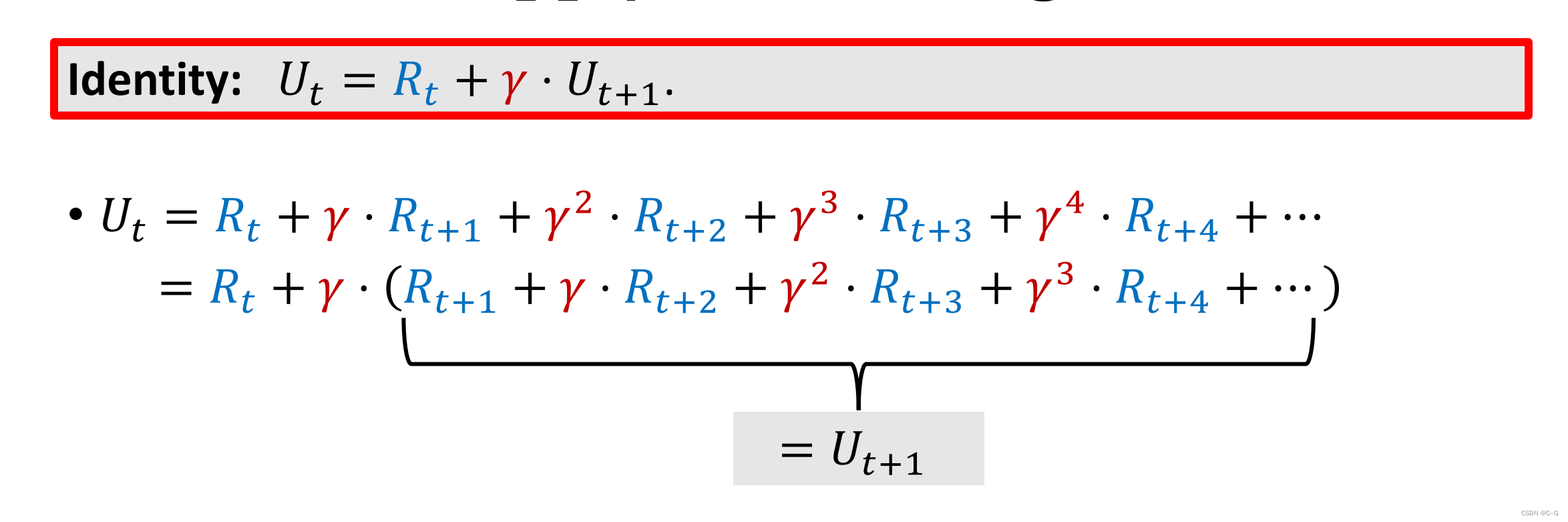

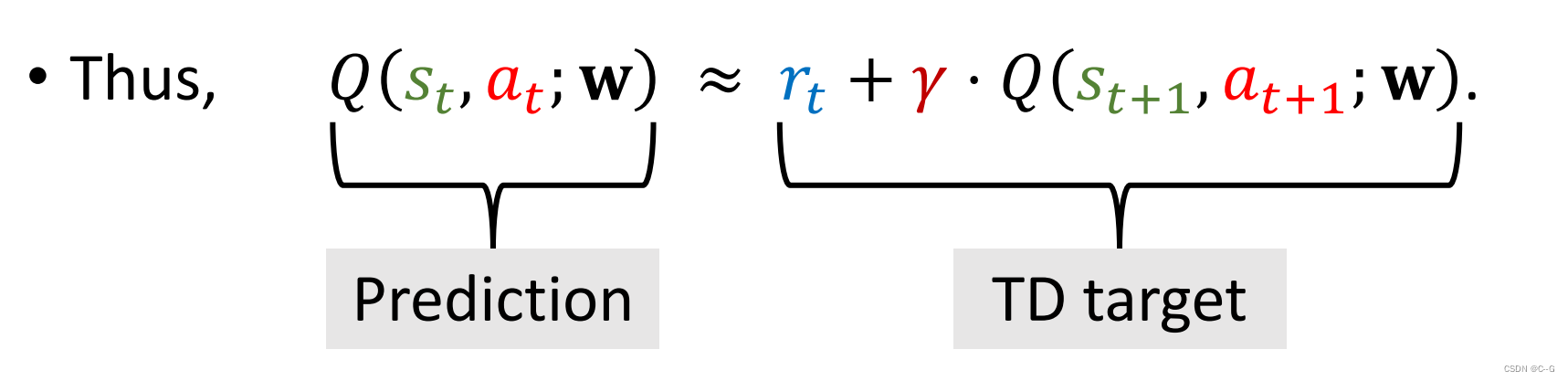
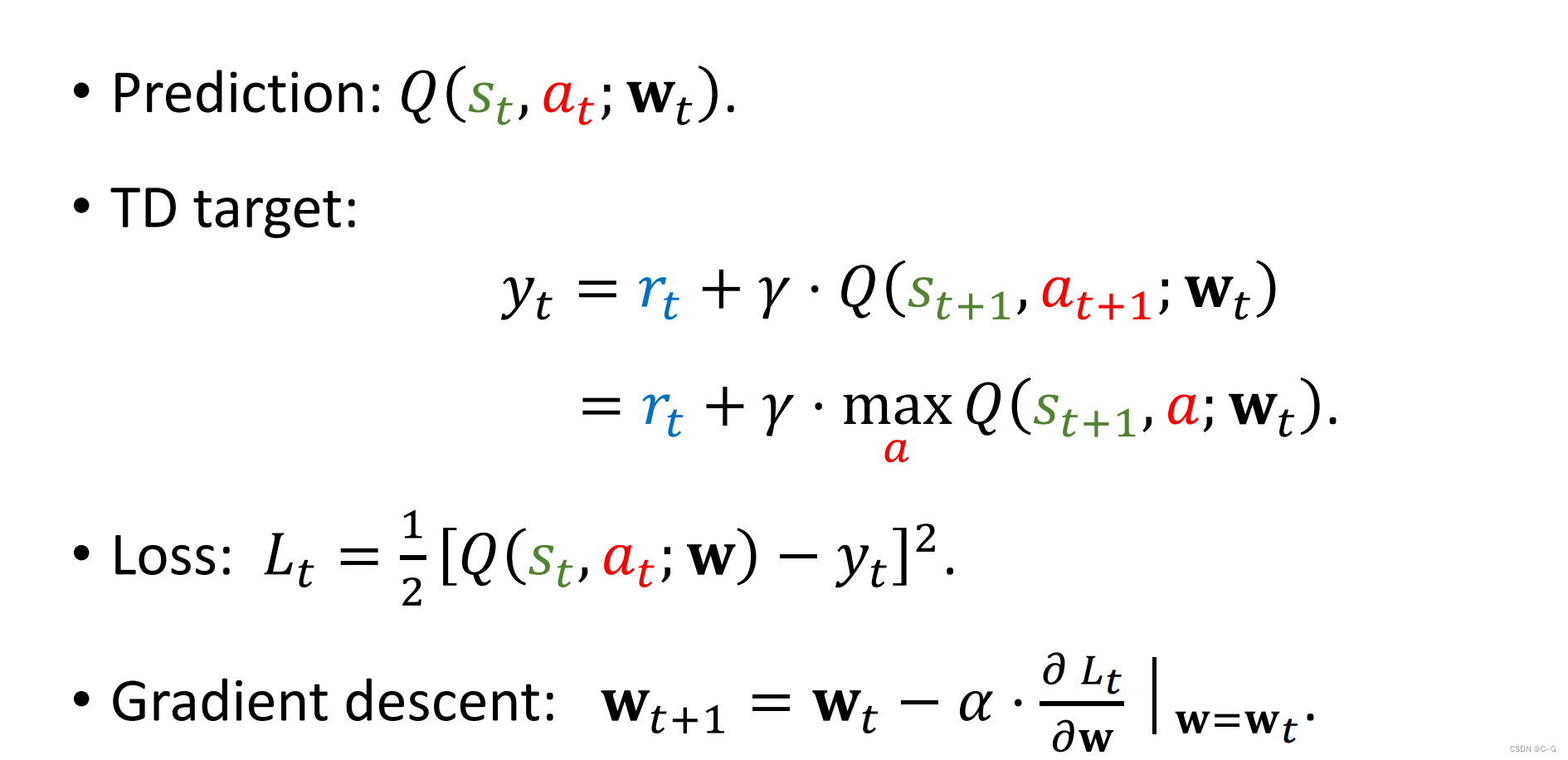
总结

Policy Network
Policy-Based Reinforcement Learning


- Policy gradient
Sutton and others: Policy gradient methods for reinforcement learning with function approximation. In NIPS,
2000

假设QΠ独立于θ(显然这个假设不严谨,这里为了后面方便计算)

由于
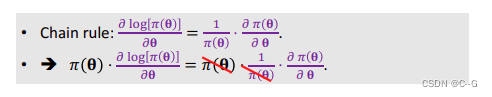


- Calculate Policy Gradient

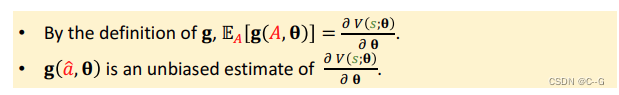
- Update policy network using policy gradient



总结

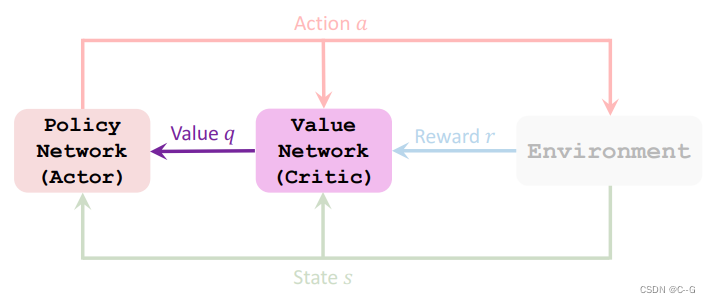
Actor-Critic Methods
Actor:演员,表演,也可以理解为运动员
Critic:评论家,打分,也可以理解为裁判
State-Value Function Approximation


-
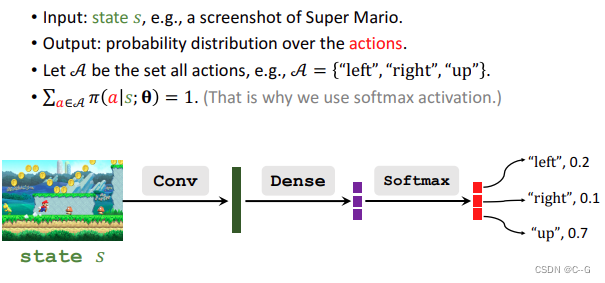
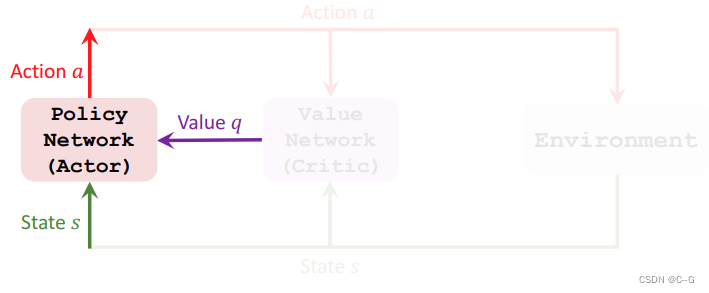
Policy Network (Actor)
-
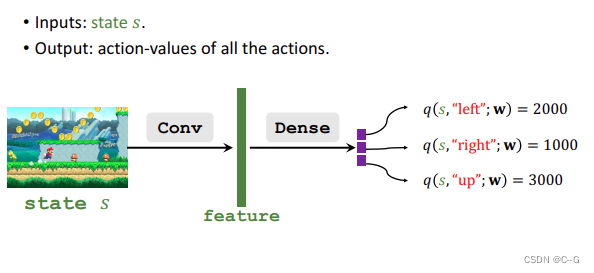
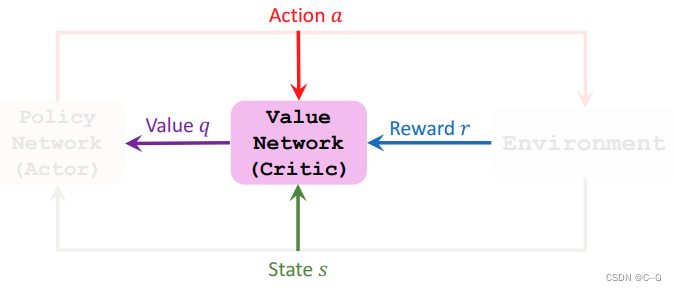
Value Network (Critic)
-
Train the networks


- Update value network q using TD
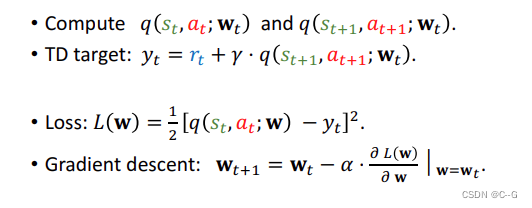
- Update policy network Π using policy gradient

Actor-Critic Method

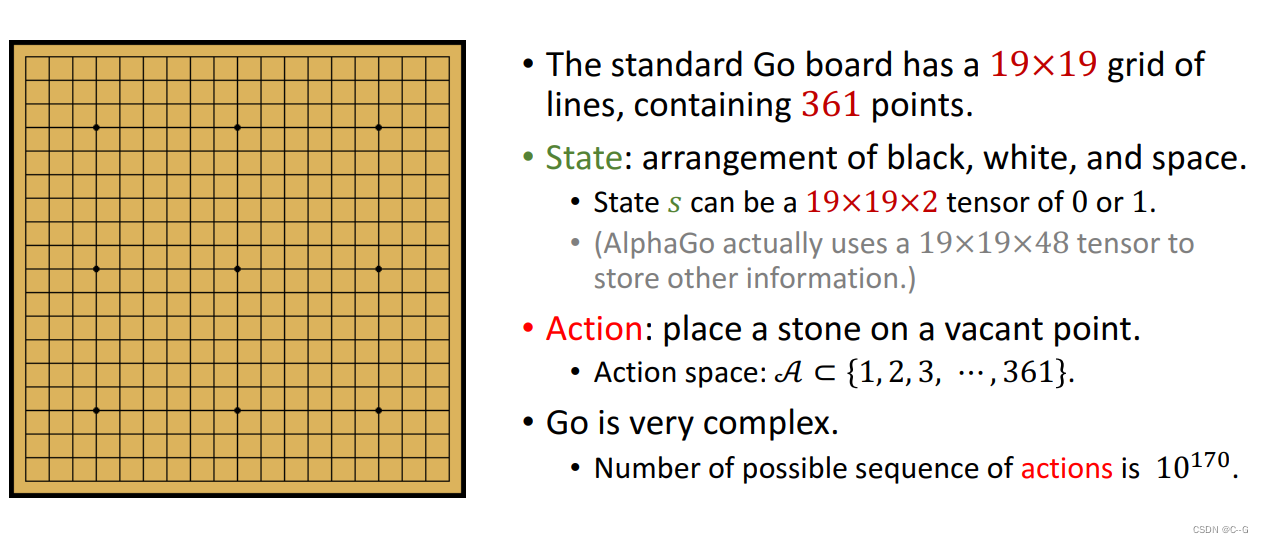
AlphaGo案例分析
Silver and others: Mastering the game of Go with deep neural networks and tree search. Nature, 2016.
Silver and others: Mastering the game of Go without human knowledge. Nature, 2017
Training and Execution

从人类下棋记录进行模仿学习,然后让两个决策网络相互下棋,训练好决策网络后再用该网络去训练价值网络

使用决策网络和价值网络执行蒙特卡洛树搜索
Policy Network
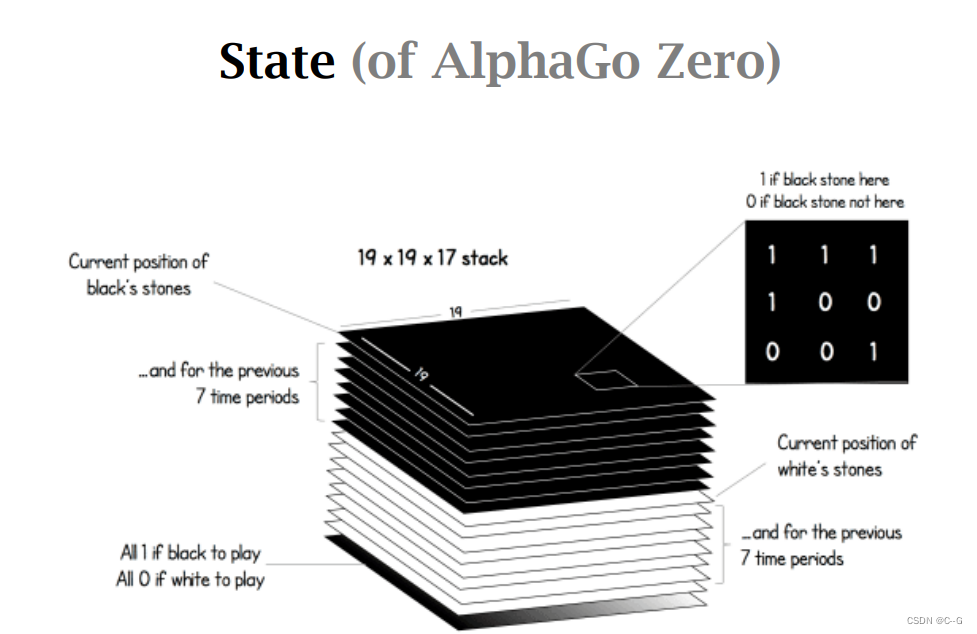
最新的AlphaGo Zero使用191917的特征记录状态,其中1层记录黑棋当前状态,并记录前7次状态,白棋同理
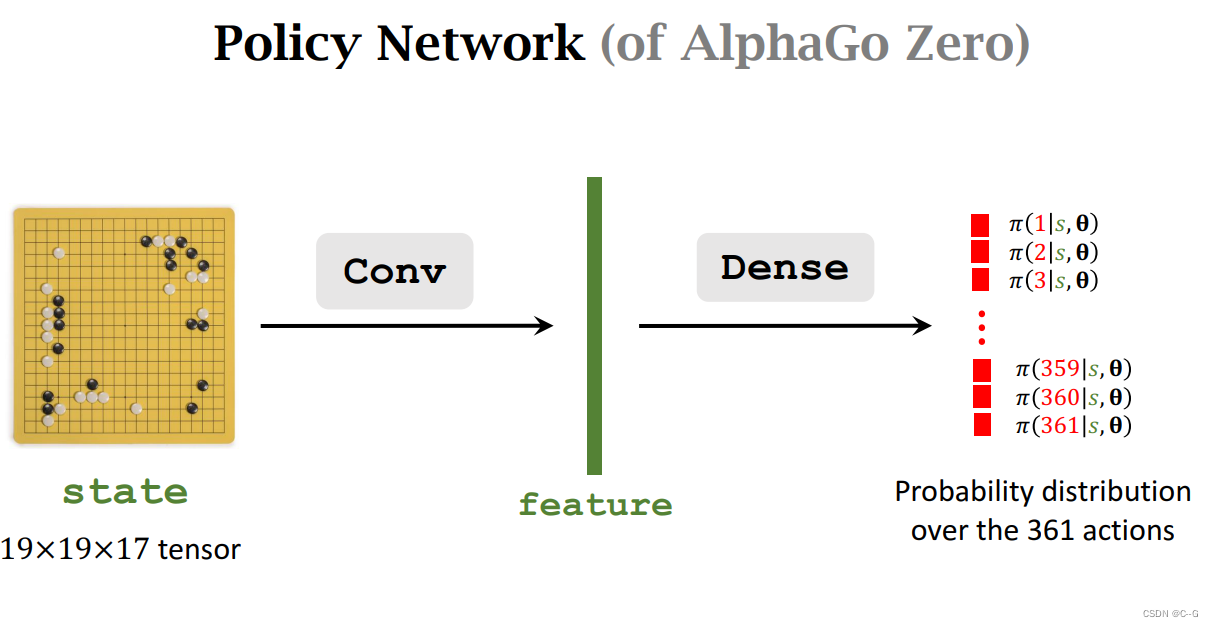

旧AlphaGo使用全卷积模式,AlphaGo Zero使用卷积层、全连接层,最后输出361动作概率
- **Initialize Policy Network by Behavior Cloning**

一开始,决策网络的决策是随机的,通过记录模仿人类下棋后,就可以打败业余选手

behavior cloning不是强化学习,强化学习需要环境反馈奖励,Imitation learning监督专家的行动,behavior cloning是Imitation learning其中一个方法,是简单的分类或回归
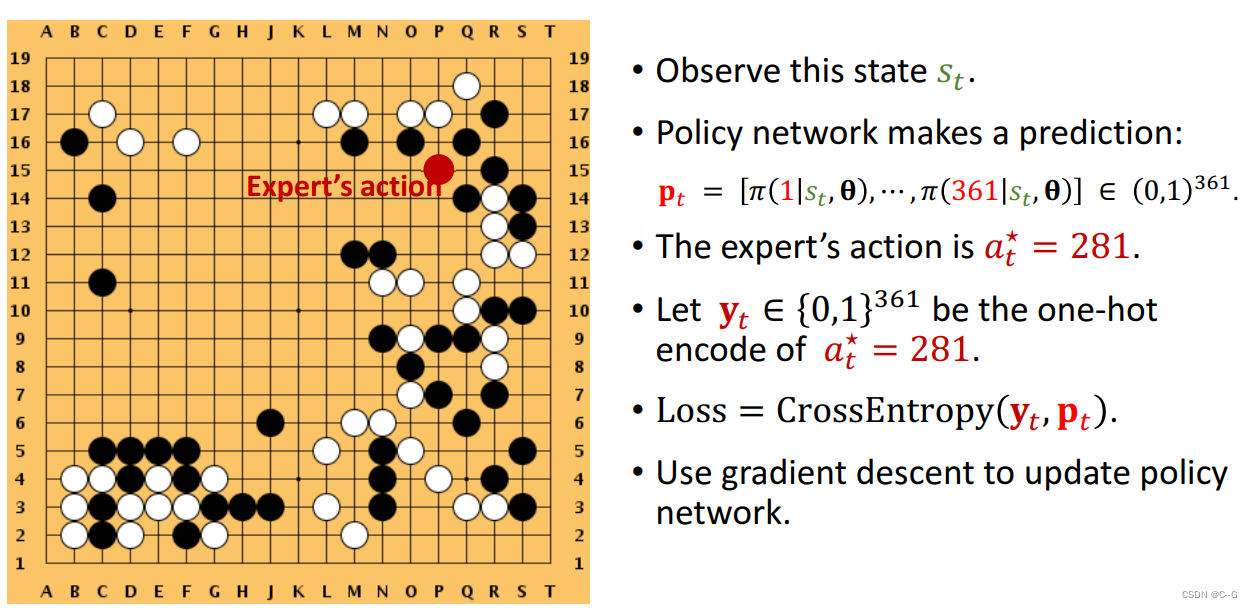
观察状态St,决策网络做出预测Pt,专家的动作是A*t,将其转化为one-hot编码后得到yt,计算yt与Pt的损失,从而更新决策网络

- Train Policy Network Using Policy Gradient


- Policy Gradient



Value Network

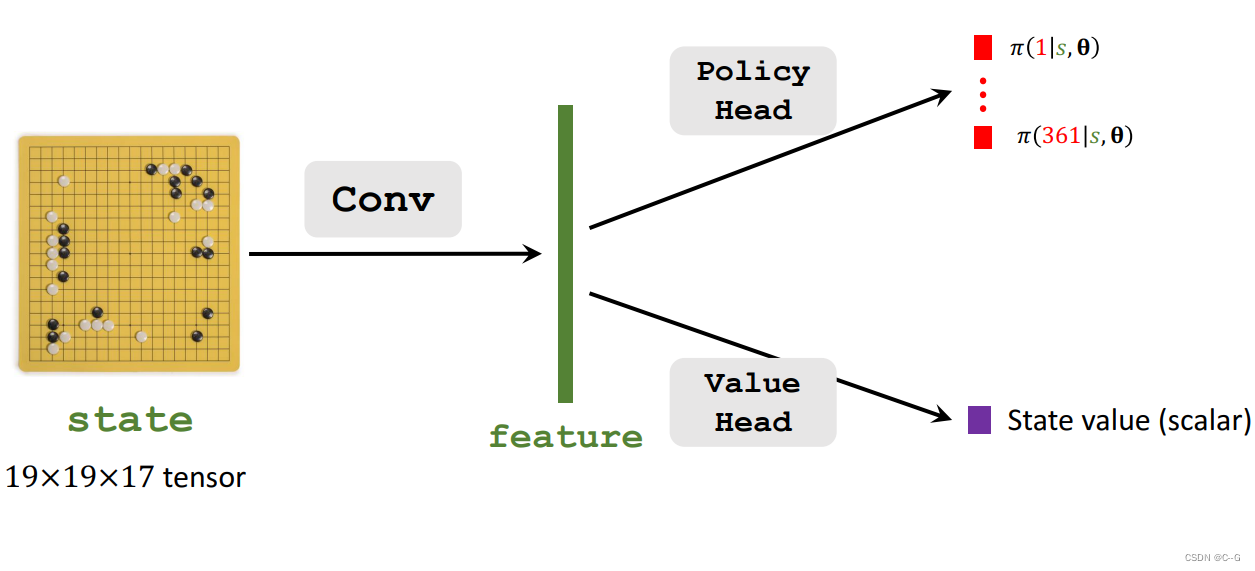

Monte Carlo Tree Search

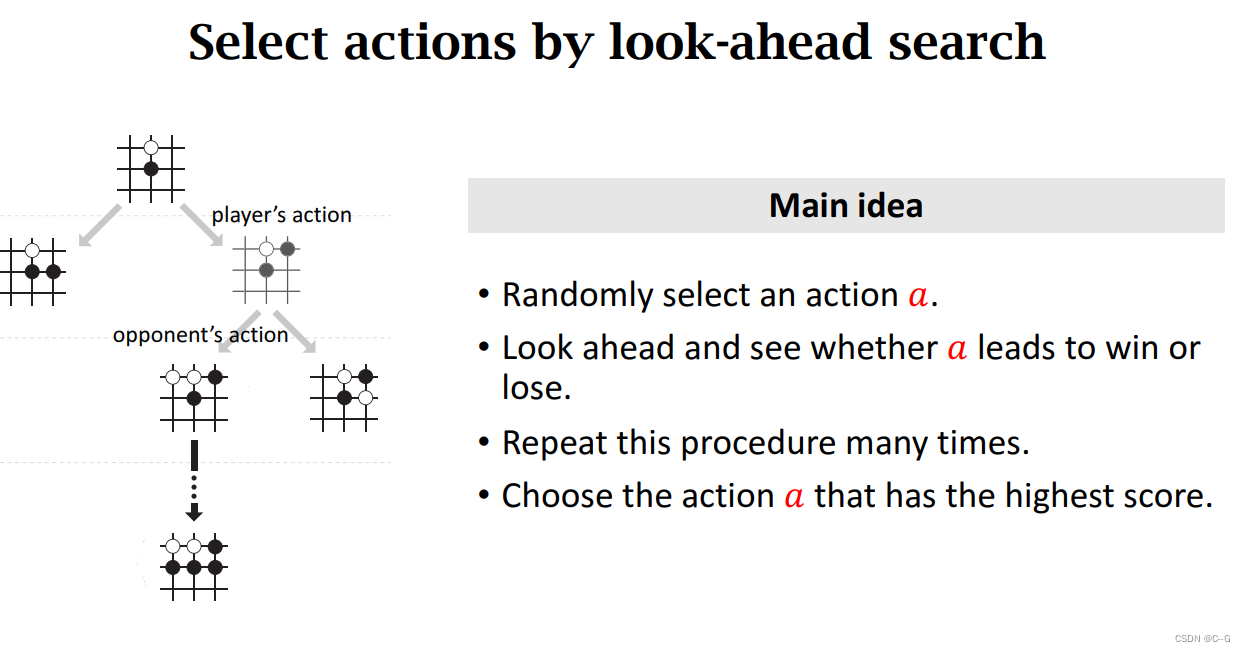








Monte Carlo Algorithms
Application 1 :Calculating Pi



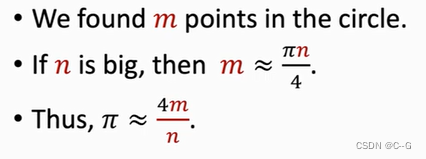

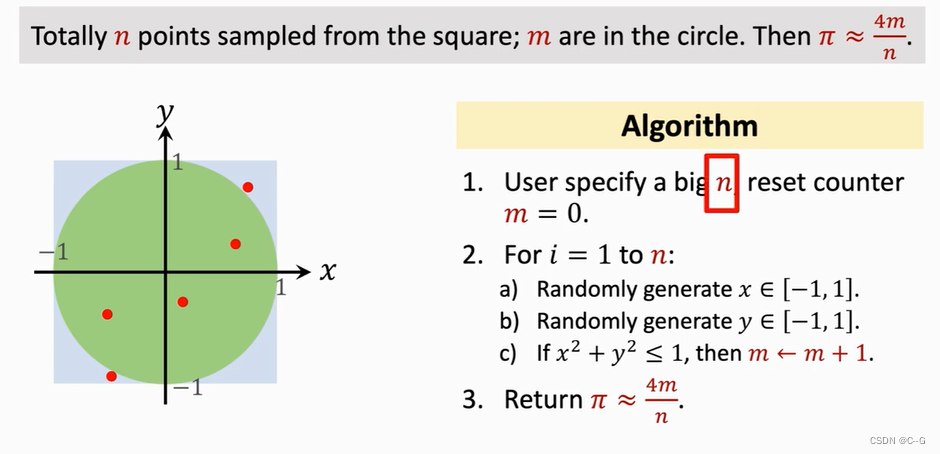
Application 2 :Buffon’s Needle Problem



Application 3 :Area of A Region
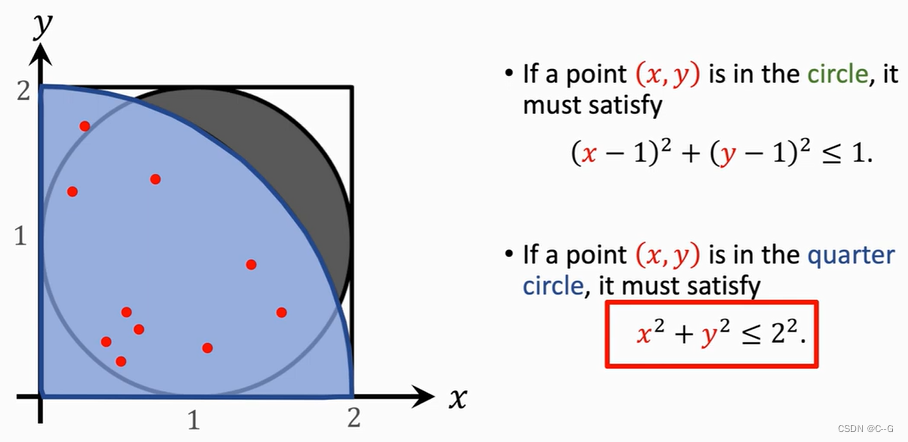
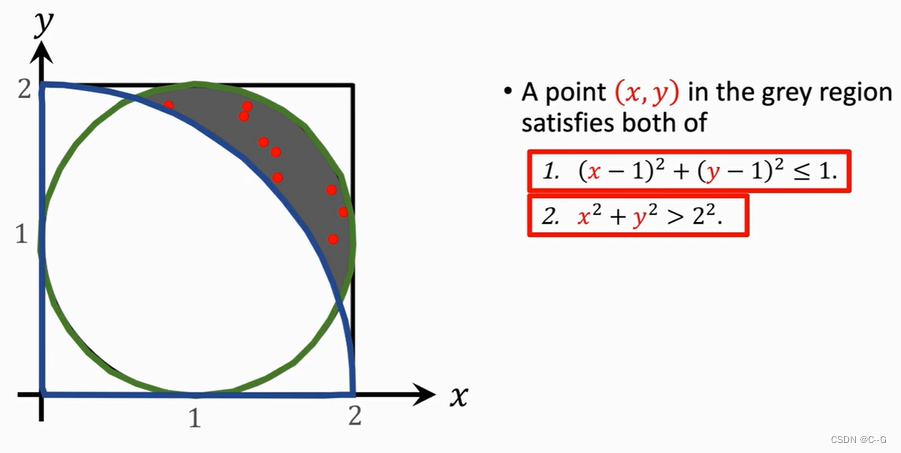
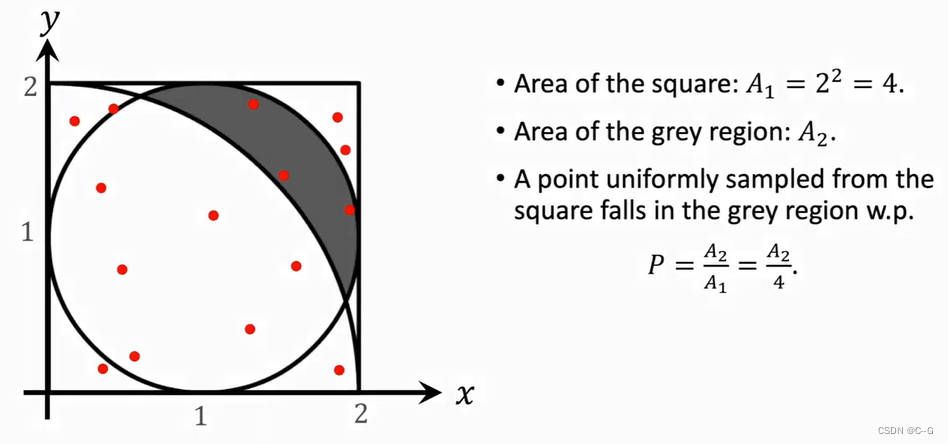


Application 4 :Integration
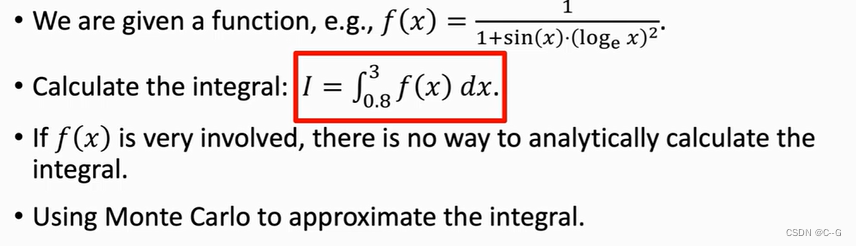





Application 5:Estimate of Expectation



Monte Carlo

















 1003
1003











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









