







contents
卷积神经网络(part 4) ResNet
写在开头
虽然根据泛逼近定理,只要有足够的训练样本,单层前馈网络也能足以表示任何函数,但是该层可能非常庞大,网络和数据容易出现过拟合。因此,研究界普遍认为网络架构需要更多层。
自从AlexNet以来,CNN网络越来越深,但是网络的深度并不能够通过层与层简单堆叠来实现,由于梯度消失问题的存在,深层网络变得难于训练。

刚开始的应对措施是增加额外的辅助损失来应对,但是效果并不好。在此环境下,ResNet架构应运而生。ResNet使得训练数百上千层网络的情况成为可能,并且保持其优越性能。
基于残差网络的手写体数字识别实验
模型构建
ResNet核心——恒等快捷链接
ResNet之所以能够脱颖而出,到今天都能充满活力的核心,就在于其引入了一个巧妙的结构:恒等快捷链接(identity shortcut connection)。这个快捷链接跳过一个或多个层:

与其希望每个堆叠层直接拟合一个需要的潜在映射,我们明确地让这些堆叠层拟合残差映射。
形式上,将所需的潜在映射表示为
H
(
x
)
H ( x )
H(x),我们让堆叠的非线性层拟合
F
(
x
)
F ( x )
F(x)的另一个映射
H
(
x
)
−
x
H ( x ) − x
H(x)−x 。原映射重构为
F
(
x
)
+
x
F ( x ) + x
F(x)+x F(x)。
我们假设去优化残差映射比优化原始映射容易。考虑极端的情况,如果恒等映射是最佳的,那么将残差优化到0比通过一个堆叠的非线性层去拟合一个恒等映射要容易。
公式
F
(
x
)
+
x
F ( x ) + x
F(x)+x能够被带有“捷径连接”的前馈神经网络实现。捷径连接是跳过一层或多层的连接。
在我们的案例中,捷径连接仅仅表现为恒等映射,并且其输出被添加到堆叠层的输出中。
恒等捷径连接既不会增加额外的参数也不会增加计算复杂性。
代码定义如下:
class Identity(torch.nn.Module):
def __init__(self, with_residual=True):
super(Identity, self).__init__()
self.with_residual = with_residual
def forward(self, x):
return (self._shortcut(x) + self._sub_forward(x)) if self.with_residual else self._sub_forward(x)
借由Identity基类,能够构成各个带残差的块,且子类可以定义单独的_sub_forward函数进行不带残差的网络传播。
ResNet18网络
ResNet18网络结构如下:

由此图能够方便地进行模型构建:
class Identity(torch.nn.Module):
def __init__(self, with_residual=True):
super(Identity, self).__init__()
self.with_residual = with_residual
def forward(self, x):
return (self._shortcut(x) + self._sub_forward(x)) if self.with_residual else self._sub_forward(x)
class ResBlock_Partial(Identity):
def __init__(self, in_channels, out_channels, stride=1):
super(ResBlock_Partial, self).__init__()
self.conv1 = torch.nn.Conv2d(in_channels, out_channels, 3, padding=1, stride=stride, bias=False)
self.conv2 = torch.nn.Conv2d(out_channels, out_channels, 3, padding=1, bias=False)
self.shortcut = None if in_channels == out_channels else torch.nn.Conv2d(in_channels, out_channels, 1, stride=stride, bias=False) # 残差函数使用,如果通道 不对等,则用1x1卷积进行对应
self.bn1 = torch.nn.BatchNorm2d(out_channels)
self.bn2 = torch.nn.BatchNorm2d(out_channels)
self.bn3 = torch.nn.BatchNorm2d(out_channels)
self.act1 = torch.nn.ReLU()
def _shortcut(self, x):
return x if self.shortcut is None else self.bn3(self.shortcut(x))
def _sub_forward(self, x):
return self.bn2(self.conv2(self.act1(self.bn1(self.conv1(x)))))
class ResBlock(torch.nn.Module):
def __init__(self, in_channels, out_channels, stride=1, with_residual=True):
super(ResBlock, self).__init__()
self.res = ResBlock_Partial(in_channels, out_channels, stride, with_residual)
self.act = torch.nn.ReLU()
def forward(self, x):
return self.act(self.res(x))
通过实例化测试,我们发现能够正常使用(测试部分我们将with_residual移至forward部分方便对比):

由此得到ResNet18模型:
class ResNet18(torch.nn.Module):
def __init__(self, in_channels=3, num_classes=10, with_residual=True):
self.sec1 = torch.nn.Sequential(
torch.nn.Conv2d(in_channels, 64, 7, stride=2, padding=3),
torch.nn.BatchNorm2d(64),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
self.sec2_sec5 = torch.nn.Sequential(
*([ResBlock(64, 64, 1, with_residual)]*2), # sec2
*([ResBlock(64, 128, 2, with_residual)]*2), # sec3
*([ResBlock(128, 256, 2, with_residual)]*2), # sec4
*([ResBlock(256, 512, 2, with_residual)]*2) # sec5
)
self.pool = torch.nn.AdaptiveAvgPool2d(1)
self.flatten = torch.nn.Flatten()
self.linear = torch.nn.Linear(512, num_classes)
def forward(self, x):
return self.linear(self.flatten(self.pool(self.sec2_sec5(self.sec1(x)))))
实例化
实例化非常简单,结果如下:
model_without_residual = ResNet18(1,with_residual=False)
model_with_residual = ResNet18(1)
没有残差连接的ResNet18
前面已经构建完成,这边只需要测试。效果如下图:
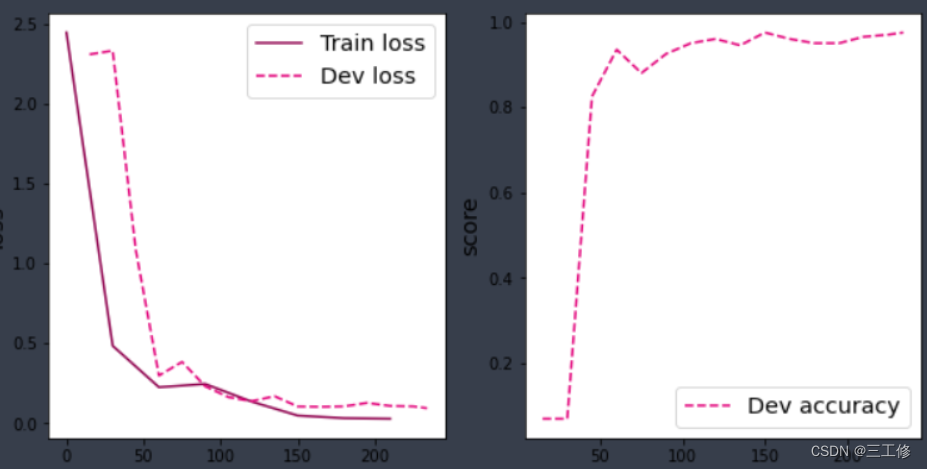
带残差连接的ResNet18
前面已经构建完成,这边只需要测试。效果如下图:
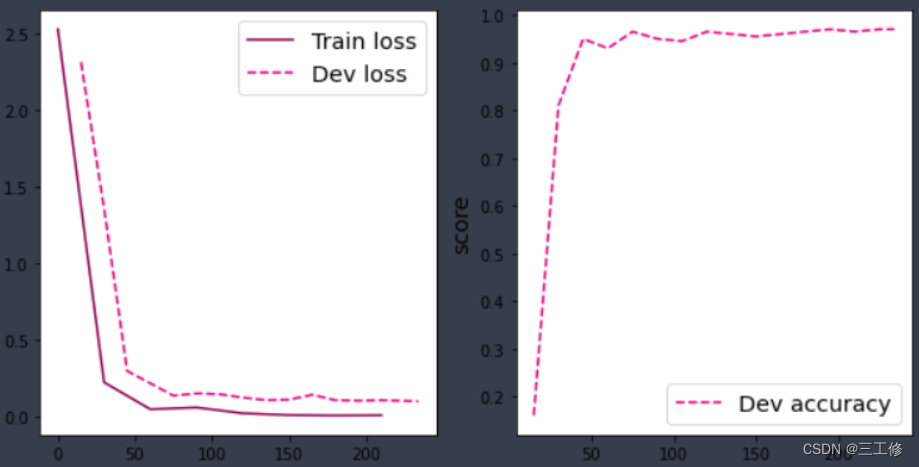
比较
显然可见,带残差的ResNet效果比不带残差的要好很多。
同时,由于高层API的代码构建更为精简、执行效率更高,因此在以后的实验中,了解原理的前提下,能用高层API则用高层API。
写在最后
本次实验,我们了解了深度学习中一个举足轻重的结构:残差结构,并且使用其非常优秀的特性构建了ResNet18这一网络并进行测试,得到了非常好的效果。在以后自主构建模型的时候,我们如果需要用深层的网络,则最好增加残差层,这样网络既美观又高效。















 404
404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









