









《A review of convolutional neural network architectures and their optimizations》论文指出随着网络架构的深入,梯度消失、爆炸或退化问题变得越来越严重。跨层连接的思想是解决现有问题的有效方案,允许网络在非相邻层之间传递信息。因此,在文中主要介绍了以下跨层连接思想的网络:Highway Networks、ResNet、Pyramidal Net、ResNext、DenseNet、CondenseNet、CSPNet、D3Net。

目录
1.Highway Networks
2015年由Rupesh Kumar Srivastava等人受到LSTM门机制的启发提出的网络结构(Highway Networks)很好的解决了训练深层神经网络的难题,Highway Networks是一种新的神经网络结构,旨在解决深度神经网络难以训练的问题。Highway Networks通过gate机制,允许信息高速无阻碍的通过深层神经网络的各层,这样有效的减缓了梯度的问题,使深层神经网络不在仅仅具有浅层神经网络的效果。Highway Networks可以直接使用随机梯度下降法进行训练,并且可以使用多种激活函数,从而打开了研究极其深层和高效架构的可能性。
论文:《Highway Networks》
https://arxiv.org/pdf/1505.00387.pdf
贡献:引入跨层连接,在层中分配两个门控单元;
缺陷:更多的计算资源和更长的训练时间;
2.ResNet
深度残差网络(Deep residual network, ResNet)的提出是CNN图像史上的一件里程碑事件,ResNet在2015年发表当年取得了图像分类,检测等等5项大赛第一,并又一次刷新了CNN模型在ImageNet上的历史记录。直到今天,各种最先进的模型中依然处处可见残差连接的身影,其paper引用量是CV领域第一名。
He等人利用高速公路网络中的绕行路径提出了ResNet,并引入残差学习的概念来解决退化(精度快速饱和、错误率随深度加深而增加)问题。ResNet继承了高速公路网络的跨层连接思想。不同之处在于其门控机制在任何时候都是畅通的而不是可学习的,这有助于大大降低网络复杂度。通过捷径连接,ResNet将输入跨层传递并添加到卷积结果中,从而对底层网络进行充分训练,显著提高准确率。
2.1 残差结构
所谓残差连接指的就是将浅层的输出和深层的输出求和作为下一阶段的输入,这样做的结果就是本来这一层权重需要学习是一个对 x 到 H(x) 的映射。那使用残差链接以后,权重需要学习的映射变成了 从x -> H(x) - x ,也就是F(x)。这样在反向传播的过程中,小损失的梯度更容易抵达浅层的神经元。
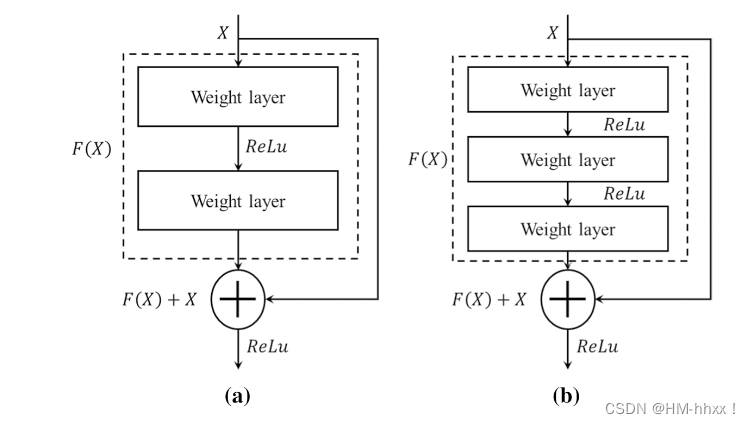
(残差模块架构:a.跨两层链接;b.跨三层连接)
图中右侧的曲线叫做残差链接(residual connection),通过跳接在激活函数前,将上一层(或几层)之前的输出与本层计算的输出相加,将求和的结果输入到激活函数中做为本层的输出。
2.2 网络结构
ResNet网络是参考了VGG19网络,在其基础上进行了修改,并通过短路机制加入了上图所示的残差链接。除此之外,变化主要体现在ResNet直接使用stride=2的卷积做下采样(取代了VGG中的池化),并且用global average pool层替换了全连接层(这样可以接收不同尺寸的输入图像),另外模型层次明显变深。相似之处是两者都是通过堆叠3X3的卷积进行特征提取。
ResNet的一个重要设计原则是:当feature map大小降低一半时,feature map的数量增加一倍,这一定程度上减轻了因减少特征图尺寸而带来的信息损失(换句话说,将输入信息的特征从空间维度提取到通道维度上)。
从上图中可以看到,ResNet相比普通卷积网络每两层间增加了残差链接,其中虚线表示feature map数量发生了改变。
在ResNet原论文中,作者给出了五个不同层次的模型结构,分别是18层,34层,50层,101层,152层。上图所示的是34层的模型结构。下图给出所有模型的结构参数:
在50层,101层和152层使用的残差模块与18层、3层有所不同。主要原因是深层次的网络中参数量太大,为了减少参数,在3X3卷积前先通过1X1卷积对channel维度进行降维。
2.3 论文
论文:《Deep Residual Learning for Image Recognition》
https://arxiv.org/pdf/1512.03385.pdf
贡献:引入了残差模块;
缺陷:特征信息在前馈过程中被丢弃;
2.4 相关博文
1.深度学习之图像分类(六):ResNet - 魔法学院小学弟
2. ResNet网络结构详解与模型的搭建_resnet模型结构_太阳花的小绿豆的博客-CSDN博客
3.Pyramidal Net
Han等人在2017年开发了金字塔网络( Pyramidal Net ),与ResNet 中深度增加导致的空间宽度急剧减小相反,该网络逐渐增加了每个残差单元的宽度。改用加法金字塔来逐步增加维度,还用了零填充直连的恒等映射,以将受下采样影响而集中分布在单个残差单元上的压力分布在所有残差单元上。网络更宽,准确度很高,超过DenseNet,更泛化。
3.1 网络结构
1.各类残差结构示意图

(a.基本残差单元;b.瓶颈残差单元;c.宽残差单元;d.金字塔残差单元;e.金字塔残差瓶颈单元)
3.2 论文
论文:《Deep Pyramidal Residual Networks》
https://arxiv.org/pdf/1610.02915v4.pdf
贡献:网络逐步拓宽;
缺陷:昂贵的计算成本;
3.3 相关博文
相关文章连接:
1.CNN模型合集 | 18 PyramidNet - 知乎;
2.卷积神经网络学习路线(十三)| CVPR2017 Deep Pyramidal Residual Networks_just_sort的博客-CSDN博客
4.ResNeXt
ResNext最大的贡献点就在于更新了 Residual Block,采用 split-transform-merge 策略,本质是分组卷积,但是不需要像 Inception 一样人工设计复杂的结构,也不像 Inception 一样结合不同尺寸感受野的信息,拓扑结构一致的 ResNeXt 对 GPU 等硬件也更友好 (所以这个结构跑得更快)。ResNeXt进一步拓宽了网络架构,在不增加网络复杂度的情况下提高了识别准确率,减少了超参数的数量。
值得指出的是,split-transform-merge 策略其实在 VGG 堆叠的思想和 Inception 的思想中都有体现,只不过 VGG split 的是变换函数本身,ResNeXt 和 Inception 都是 split 输入特征。
4.1 网络架构
1.ResNext块结构:

(左:ResNet的一个块;右:cardinality = 32的ResNext块)
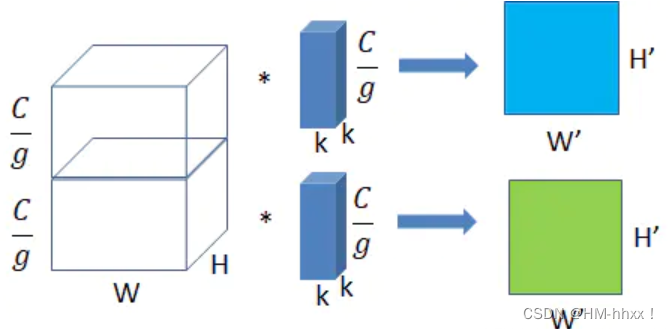
4.2 分组卷积
分组卷积 (Group Convolution):分组卷积的雏形其实可以追溯到 2012 年深度学习鼻祖文章 AlexNet。受限于当时硬件的限制,作者不得不将卷积操作拆分到两台GPU上运行,这两台GPU的参数是不共享的。如果采用g个group来做,计算量是普通卷积的1/g。
4.3 论文
论文:《Aggregated Residual Transformations for Deep Neural Networks》
https://arxiv.org/pdf/1611.05431v2.pdf
贡献:引入分组卷积;
缺陷:昂贵的计算成本;
4.4 相关博文
1.深度学习之图像分类(九)--ResNeXt 网络结构_resnext网络结构_木卯_THU的博客-CSDN博客
5.DenseNet
DenseNet是一种具有密集连接的CNNs架构,它借鉴了ResNet中跨层连接的典型思想。作为CVPR2017年的Best Paper, DenseNet脱离了通过加深网络层数(VGG,ResNet)和加宽网络结构(GoogLeNet)来提升网络性能的定式思维, 从特征的角度考虑, 通过特征重用和旁路(Bypass)设置,既大幅度减少了网络的参数量,又在一定程度上缓解了梯度弥散问题的产生。
5.1 网络架构
1.dense block结构:
下图所示是生长速率为k = 4的5层dense block。每一层都将前面的所有特征映射作为输入。

2. DenseNet网络结构 (DenseNet结构图)
一个包含3个dense block的DenseNet。两个相邻块之间的层称为过渡层,通过卷积和池化改变特征图的大小。
DenseNet中的每一层都以前馈的方式连接到每一层,从而更加彻底地加强了跨层深度卷积的效果。DenseNet中的Hi块是一个复合函数BN - ReLU - Conv,由BN、ReLU和3 × 3卷积( Conv ) 3个连续操作组成。DenseNet的基本模块称为Dense Blocks,每个模块都将之前所有Dense Blocks的特征图作为输入。与ResNet采用直接求和的方式不同,Dense Blocks以串联的方式合并了之前的多个输入。这种连接方式允许网络之间更有效的信息和梯度流动,显著减少了DenseNet参数的数量。
5.2 网络优点
DenseNet的几个优点:
-
1、减轻了vanishing-gradient(梯度消失)
-
2、加强了feature的传递,更有效地利用了不同层的feature
-
3、网络更易于训练,并具有一定的正则效果.
-
4、因为整个网络并不深,所以一定程度上较少了参数数量
缺点:占内存,在计算的过程中需要保留浅层的feature map为了与后面的feature map就行拼接,虽然参数量少,但训练过程的中间产物(feature map)多。
5.3 论文
论文:《Densely Connected Convolutional Networks》
https://arxiv.org/pdf/1608.06993.pdf
贡献:全局跨层信息流;
缺陷:重复梯度信息计算;
6.CondenseNet
Gao等人对DenseNet进行了修改,提出了一种轻量级网络CondenseNet。该网络集成了学习到的组卷积、密集连接和剪枝等方法。作者增加了一个新的索引层,用于实现后续卷积层的分组卷积,并修改了网络卷积层的输入通道数,使其呈指数增长。此外,CondenseNet将DenseNet在密集块中采用的密集连接方式的应用扩展到网络的每一层。实验表明,CondenseNet优于当前最前沿的轻量级网络MobileNet和ShuffleNet。
6.1 网络架构
网络结构:
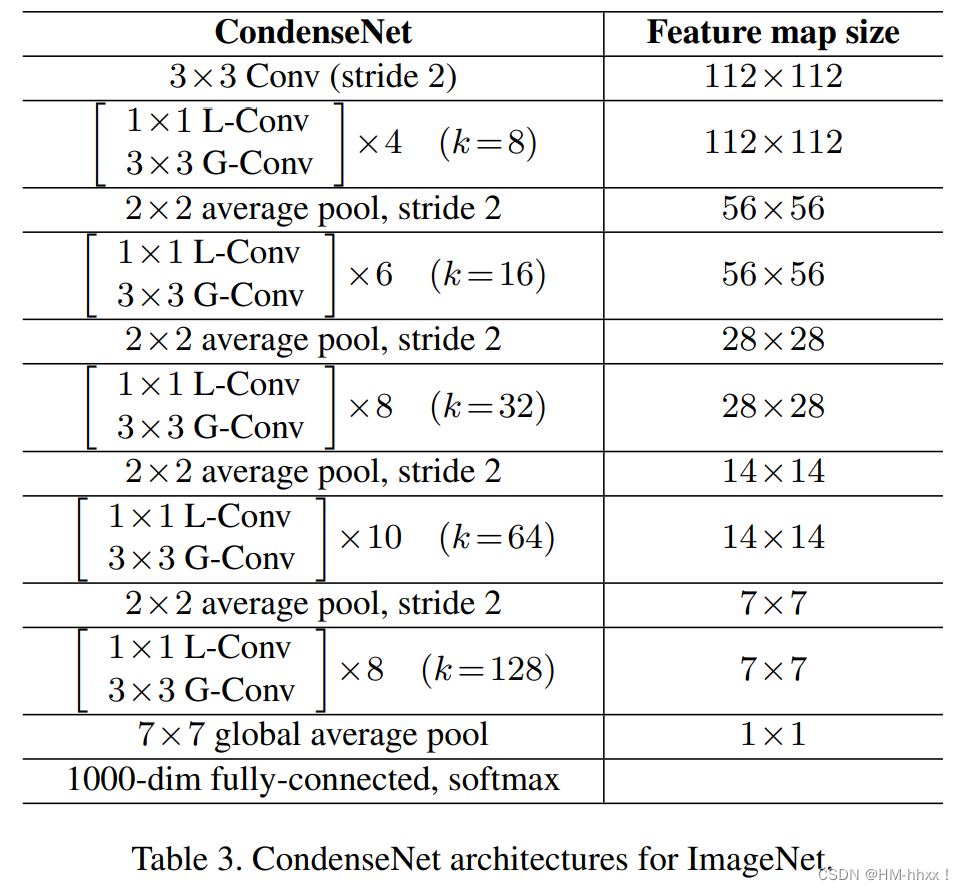
其中 L-Conv :学习到的组卷积; G-Conv :分组卷积;
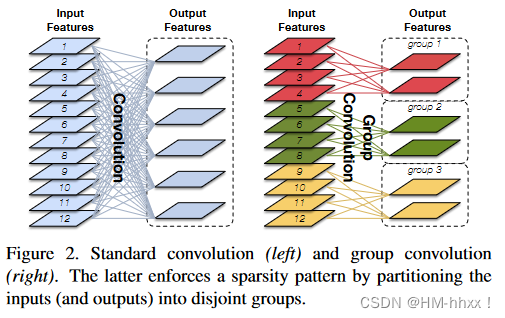
分组卷积(G-Conv):
下图中,左图为普通卷积操作,右图为分组卷积操作,通过分组卷积可减少计算开销,如果采用G个group来做,计算量是普通卷积的1/G。
可学习的分组卷积(L-Conv):
在densenet中,由于1×1卷积的使用,其通道数较多,所以作者采用了分组卷积的方式降低计算量。
L-Conv主要可分为三个阶段,浓缩(Condensing)阶段、优化(Optimizing)阶段和测试(Testing)阶段。其中浓缩阶段用于剪枝没用的特征,优化阶段用于优化剪枝之后的网络。
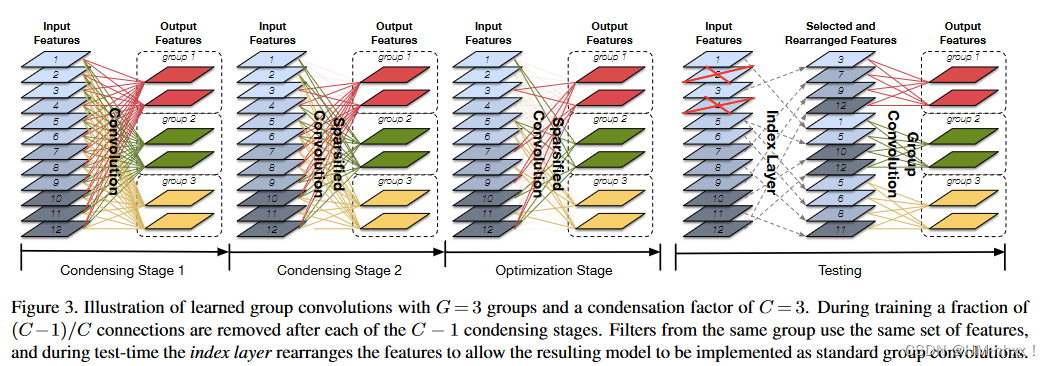
上图中,说明了G = 3和凝聚因子(condensation factor)C = 3的学习群卷积。在训练过程中,在每个C - 1凝聚阶段结束后移除一部分( C-1 ) / C连接,即只保留1/C的连接。来自同一组的过滤器使用相同的特征集,并且在测试期间索引层重新排列特征以允许结果模型作为标准组卷积实现。
1.Condensing Stage1是普通的卷积过程;在训练该网络时使用了分组lasso正则项,这样学到的特征会呈现结构化稀疏分布,好处是在后面剪枝部分不会过分的影响精度;
2.Condensing Stage2为剪枝,是自动选择group的过程,浓缩率为C的CondenseNet会有C-1个浓缩阶段,在每次浓缩阶段训练完成之后会有的特征被剪枝掉。也就是经过C-1个浓缩阶段后,仅有的特征被保留下来,CondenseNet的剪枝并不是直接将这个特征删除,而是通过掩码的形式将被剪枝的特征置0,因此在训练的过程中CondenseNet的时间并没有减少,反而会需要更多的显存用来保存掩码;
3.Optimization Stage是在group确定的前提下进行的剪枝,也就是筛选出每个group中不是很重要的输入feature map,它会针对剪枝之后的网络单独做权值优化。剪枝完成后,每组内对应的残留的输入通道个数,与所有输入通道数的比例,即为浓缩因子C。如图中,输入通道为12个,设置C为3的话,每组应保留三分之一的通道,即12/3=4。并且修剪的过程也是由C来定义的。给定浓缩因子C,浓缩阶段包含C-1步,其中第一步是常规稀疏正则化训练,剩余的C-2步进行修剪。每个浓缩阶段,剪去1/C的通道数。在优化阶段,再剪掉1/C。所以,到了训练阶段,只剩下1/C通道了 ;
4.Testing部分主要是一个index layer操作和一个常规的group操作。经过训练过程的剪枝之后我们得到了一个系数结构,目前这种形式是不能用传统的分组卷积的形式计算的,如果使用训练过程中的掩码的形式则剪枝的意义就不复存在。为了解决这个问题,在测试的时候CondenseNet引入了索引层(Index Layer),索引层的作用是将输入Feature Map重新整理以方便分组卷积的高效运行。
6.2 结构改进

1.指数递增的增长率:
高层的卷积层可能更依赖于中高层的特征,而较少依赖于底层的特征。为了体现不同层的重要性,作者引入了指数递增的增长率k,同一个block内采用相同的k,随着block数增加,k值呈指数增长。从而强化近处层的连接,弱化较远层的连接。通过逐步增加增长率,后面某一层接收到底层的输出通道数少,而接收到近处层的输出通道数多。
2.全密集连接:
在Densenet中,密集连接只存在于dense block内部,而全密集连接指每一层都与前面其他层呈密集连接关系。由于dense block具有不同的特征尺寸,当我们将尺寸较高的特征图作为输入时,使用平均池化将其降采样到低尺寸层。
6.3 论文
论文:《CondenseNet: An Efficient DenseNet using Learned Group Convolutions》
https://arxiv.org/pdf/1711.09224.pdf
贡献:引入可学习的分组卷积、全稠密连接、采用指数增长率
缺陷:网络设计复杂,需要大规模数据集;
6.4 相关博文
2.轻量化神经网络CondenseNet--对DenseNet的进一步改进_胖虎记录学习的博客-CSDN博客
3.【开源+干货】DenseNet原作者最新力作:升级版浓缩网络,计算量少十倍!
7.CSPNet
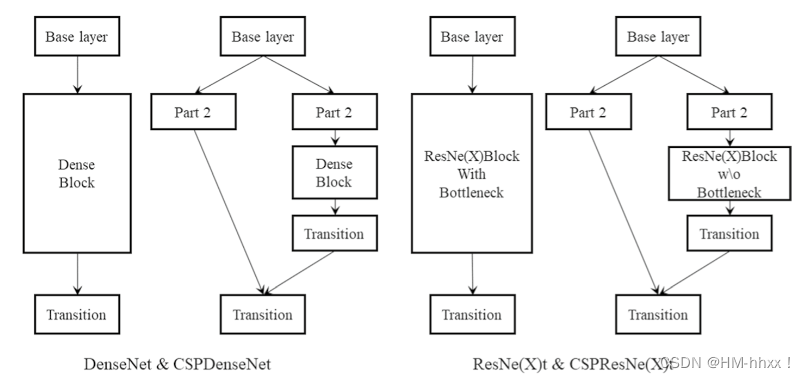
2019年,Wang等人认为DenseNet的网络有大量的梯度信息被重复用于更新不同Dense块的权重,这意味着Dense块重复学习相同的信息( Wang et al . 2020a)。考虑到这一点,他们提出了一种称为CSPNet的网络结构,通过添加部分过渡层来最大化梯度组合中的差异。
CSPNet通过引入一个交叉阶段局部连接模块,将特征图分为两个部分,并在两个部分之间进行信息交互,以增强特征的表达能力。
CSPNet的核心思想是通过在网络的不同阶段引入局部连接,将高分辨率的特征图和低分辨率的特征图进行融合。这种融合能够更好地捕捉不同尺度的信息,从而提高模型的性能。CSPNet还采用了一种路径重排的策略,通过重新排列特征图中的通道,进一步增强了模型的表达能力。
CSPNet 和不同 backbone 结合后的效果:
7.1 论文
论文:《CSPNet: A New Backbone that can Enhance Learning Capability of CNN》
贡献:增强CNN学习能力,嫩能够在轻量化同时保持准确性、降低计算瓶颈和 DenseNet 的梯度信息重复、降低内存成本
缺陷:可优化的多尺度特征提取;
7.2 相关博文
8.D3Net
2021年,Takahashi等人针对高分辨率稠密预测的任务,引入了一种密集连接的多扩展( D3Net )网络架构,将多层卷积与DenseNet架构相结合,在每一层获得指数增长的感知域。
在传统的卷积神经网络中,每个卷积层通常只与前一层的特征图相连接。而在密集连接的多膨胀卷积网络中,每个卷积层的输出都与前面所有层的输出相连接。这种密集连接的设计有助于信息的流动和传递,使网络可以更好地学习到图像中的细节和上下文信息。
另外,多膨胀卷积是一种在卷积操作中引入空洞率(dilation rate)的技术。通过增加卷积核的空洞率,可以扩大感受野(receptive field)的大小,从而捕捉更大范围的上下文信息。多膨胀卷积能够在不增加网络参数和计算量的情况下提高模型的感知能力。
密集连接的多膨胀卷积网络在密集预测任务中表现出色,如语义分割、实例分割和图像分割等。它能够有效地提取图像中的特征,并生成像素级别的预测结果。
总之,密集连接的多膨胀卷积网络是一种用于密集预测任务的强大模型,结合了密集连接和多膨胀卷积的优势,能够有效地处理图像数据并生成准确的预测结果。
8.1 论文
论文:《Densely connected multidilated convolutional networks for dense prediction tasks》
贡献:增强CNN学习能力,嫩能够在轻量化同时保持准确性、降低计算瓶颈和 DenseNet 的梯度信息重复、降低内存成本
缺陷:可优化的多尺度特征提取;

















 4765
4765











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











