







LinearRegression线性回归基于sparkml采用Java语言开发
什么是线性回归?
以下来自知乎马同学(10 封私信 / 80 条消息) 马同学 - 知乎 (zhihu.com)的高赞回答(10 封私信 / 80 条消息) 如何解释「线性回归」的含义? - 知乎 (zhihu.com)
回归大致可以理解为根据数据集D,拟合出近似的曲线,所以回归也常称为拟合(fit),像下列右图一样拟合出来是直线(y=w*x+b)的就称为线性回归

“回归”这个词源于高尔顿,他采集了一千多组父子身高,发现高个子父亲的儿子身高会矮一些,而矮个子父亲的儿子身高会高一些(否则高个子家族会越来越高,而矮个子家族会越来越矮),也就是说人类的身高都会回到平均值附近,他将这种现象称为均值回归。
拟合过程也就是找到w和b

w和b需要满足下面的经验误差最小:
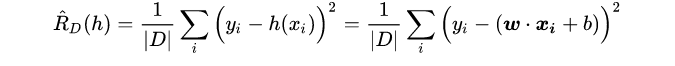
首先,将手上的数据集D:

代入线性回归的经验误差函数后可得:

可见经验误差是关于w和b的凹函数,凹函数在一阶偏导等于0时取得极值
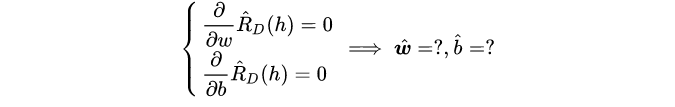
Java代码实现
spark工程的pom依赖(CDH5.7)
<!--spark ml--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_2.11</artifactId> <version>2.1.0.cloudera1</version> </dependency>
测试类
@Test public void TestLinearRegressionAnalysis() { List<Row> list = new ArrayList<>(); list.add(RowFactory.create("1.0", "1.9", "1.0")); list.add(RowFactory.create("2.0", "3.1", "0.0")); list.add(RowFactory.create("3.0","4.0", "1.0")); list.add(RowFactory.create("3.5", "4.45", "0.0")); list.add(RowFactory.create("4.0", "5.02", "1.0")); list.add(RowFactory.create("9.0", "9.97", "0.0")); list.add(RowFactory.create("-2.0", "-0.98", "1.0")); Dataset<Row> rowDataset = DatasetCreateUtils.quickCreateStrDs(list, Lists.newArrayList("labelD", "priceD", "ID")); Dataset<Row> data = rowDataset //label 用来计算 系数 和 截距 .withColumn("label", rowDataset.col("labelD").cast(DataTypes.DoubleType)) .withColumn("price", rowDataset.col("priceD").cast(DataTypes.DoubleType)) ; String[] transClos = (String[]) Arrays.asList("price").toArray(); VectorAssembler vectorAssembler = new VectorAssembler().setInputCols(transClos).setOutputCol("features"); Dataset<Row> dataset = vectorAssembler.transform(data); LinearRegressionAnalysis.linearRegression(dataset); }
线性回归方法
import org.apache.spark.ml.regression.LinearRegression; import org.apache.spark.ml.regression.LinearRegressionModel; import org.apache.spark.ml.regression.LinearRegressionTrainingSummary; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; /** * 线性回归 * 根据label 计算出系数和截距 * features * 系数 + 截距 = prediction */ public class LinearRegressionAnalysis { public static Dataset<Row> linearRegression (Dataset<Row> training) { LinearRegression lr = new LinearRegression() .setMaxIter(10)//设置最大迭代次数,默认是100。 .setRegParam(0.3)//设置正则化参数,默认0.0。 .setElasticNetParam(0.8);//设置弹性网混合参数,默认0.0。 0->L2(ridge regression岭回归);1->L1(Lasso套索);(0,1)->L1和L2的组合;与 huber 损失拟合仅支持 None 和 L2 正则化,因此如果此参数为非零值,则会引发异常 //训练模型 LinearRegressionModel lrModel = lr.fit(training); //打印线性回归的系数和截距 System.out.println("系数Coefficients: "+lrModel.coefficients() + ""); System.out.println(" 截距Intercept: " + lrModel.intercept()+ ""); //总结训练集上的模型并打印出一些指标。 LinearRegressionTrainingSummary trainingSummary = lrModel.summary(); //trainingSummary.predictions().show(); Dataset<Row> dataset = trainingSummary.predictions().select("label", "price", "features","prediction"); dataset.show(false); return dataset; } }
计算结果
系数Coefficients: [0.9072296333951201]
截距Intercept: -0.6303608190042851±------±--------±---------------±----------------------+
|label|price|features|prediction |
±------±------±----------±----------------------------+
|1.0 |1.9 |[1.9] |1.093375484446443 |
|2.0 |3.1 |[3.1] |2.1820510445205876 |
|3.0 |4.0 |[4.0] |2.9985577145761955 |
|3.5 |4.45 |[4.45] |3.4068110496039994 |
|4.0 |5.02 |[5.02] |3.923931940639217 |
|9.0 |9.97 |[9.97] |8.414718625945063 |
|-2.0 |-0.98|[-0.98] |-1.5194458597315026|
2] |3.923931940639217 |
|9.0 |9.97 |[9.97] |8.414718625945063 |
|-2.0 |-0.98|[-0.98] |-1.5194458597315026|
±----±----±-------------±--------------------------------+















 2786
2786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









