







 本文介绍了朴素字符串匹配方法,然后详细阐述了KMP算法的原理,包括如何找到最长公共前后缀以及构建next数组以避免不必要的字符比较,从而提高搜索效率。
本文介绍了朴素字符串匹配方法,然后详细阐述了KMP算法的原理,包括如何找到最长公共前后缀以及构建next数组以避免不必要的字符比较,从而提高搜索效率。
一、朴素匹配法
S= "abgabcd"
T = "abcd"
假设有两个字符串,要判断字符串T是否在字符串S中出现过,你会怎么做?一般来说我们都是这样,一个一个对比:
#include<iostream>
using namespace std;
int main(){
string S = "abefabcd";
string T = "abcd";
int count = 0;
int cnt=0;
cout<<"changduwei:"<<S.length()<<endl;
for(int i=0,j=0;i<S.length();i++){
cnt++;
if(S[i]==T[j]) {
count ++;
j++;
cout<<"count = "<<count<<endl;
if(count == T.length()) { cout<<"找到一次咯"<<endl; break;}
}else{
count = 0;
cout<<"count = "<<count<<endl;
j =0 ;
}
}
cout<<"一共找"<<cnt<<"次,才找到"<<endl;
} 
1.2KMP算法的思想
但是这样会很耗费时间,其实发现子串”abcd"与"abefabcd"的第1,2两位匹配这说明,并且子串中a之后再没有其他a了,这说明主串第2位不可能再和子串的第1位相匹配了,

可以跳过子串第1位和主串第二位比(跳过1->2,2->3,直接从1->3)。所以就有了KMP算法。
2.KMP算法步骤
1.找到第一个不匹配的位置 t

发现在第6个位置S中是"B",T中是"A"
2. 在小于t的位置找最长公共前后缀
这句话有三个点,我们剖析一下
2.1 小于t的位置
也就是在前面匹配的串中(暂时把它称为匹配子串),(在这道例题中也就是在1~5的位置:ABABA)找某个东西
2.2 前后缀
一个箭头从匹配子串的最前面开始,另一个箭头从匹配字串的最后一个往前延申,他们是互相奔赴的,找到前后相同的部分

在这道例题中,上图中红色的A和黑色的A就是一个匹配子串
2.3 最长
但是你发现这个箭头如果继续延伸,还是相同的
ABA 和 ABA

如果再延长就是:ABAB 和 BABA 不相同
继续延长箭头:ABABA 和 ABABA 可是这样有意义吗?这不就是同一个串?
所以上图就是最长公共前后缀了
3.前缀移动到后缀的地方
你前面找到最长的相同的部分不就是为了能够最快的跳过没有必要去比的地方吗,所以前缀移动到后缀的位置

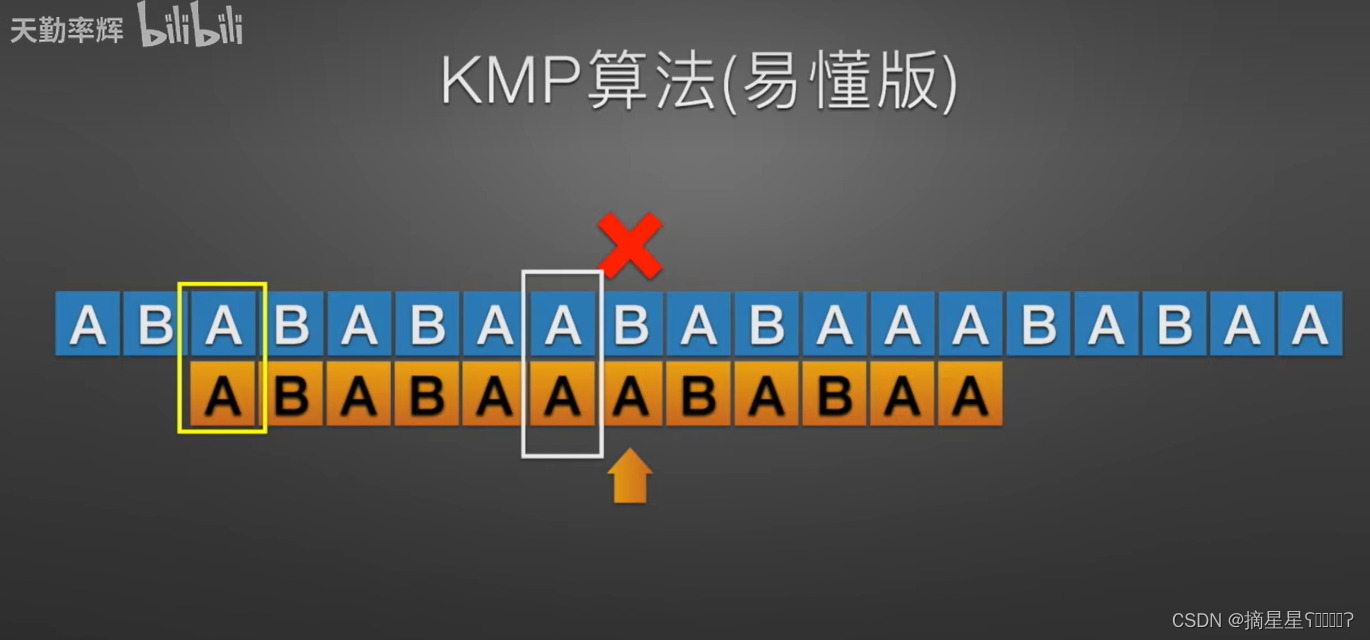
一直重复这个操作,没看懂的去看(跳到8:01讲的就是这里)http://【【天勤考研】KMP算法易懂版】https://www.bilibili.com/video/BV1jb411V78H?vd_source=7f1e3551ae4b557a2f2008705a646502
现在来看一道完整的例题和步骤巩固一下
怎么样是不是好方便,这么长的字符串也就比3次就完成了

三、next数组
next 是什么意思,是下一步的意思,所以next数组就是结合KMP算法来告诉你:如果当前位置不匹配,下一步要去找子串中的谁和当前不匹配的位置比较,而不是一步步慢慢往前一个个比? 我们来一步步推一下,找找规律
为了方便表达,我们下面把所有不匹配的位称为当前位
例一:如果第一位就不匹配
最长公共前后缀长度=0
那就是1号位和主串下一位去比较,其实就是整个T往后移

例二:如果第一位匹配,但第二位匹配
最长公共前后缀长度为 = 0
1号位和当前位比较

例三:三号位不匹配
最长公共前后缀长度 = 2,前缀移到后缀的地方
3号位和当前位比较
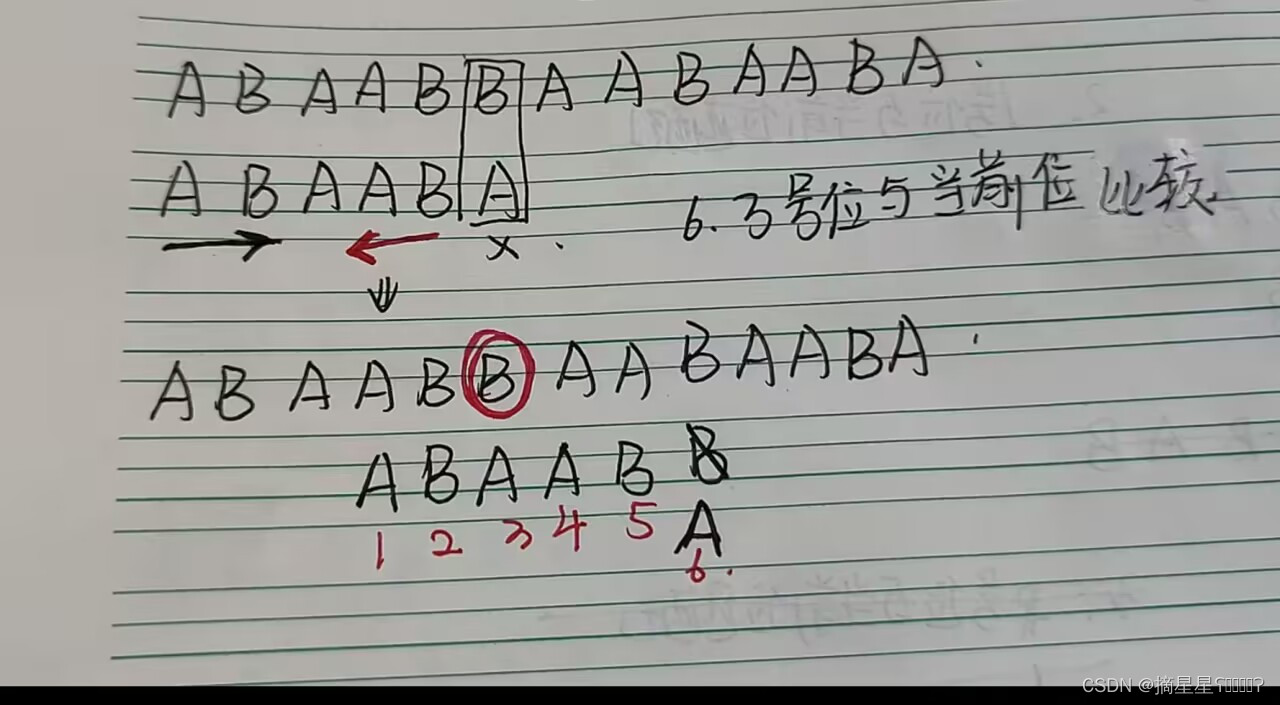
例四:四号位不匹配
最长公共前后缀长度 = 2,前缀移动到后缀的地方
3号位与当前位比较

例四:五号位不匹配
最长公共前后缀长度 = 1,前缀移动到后缀的地方
2号位与当前位比较

我们发现,每次都是 (最长公共前后缀长度 +1)号位与当前位比较,那不就跟主串没关系了(因为你看的是字串的最长公共前后缀),所以我们每次只需要计算匹配串(也就是子串)的T[i]之前的T[0]~T[i-1]的最长公共前后缀,就可以判断出如果T[i]这个位置不匹配下一步需要几号位和当前位进行比较。
设最长公共前后缀长度为i,那么next数组里存的就是i+1.
下面来看道例题的next数组

四、代码
那么最后我们来看看KMP算法的代码实现
void get_next(String T,int *next){
int i,j;
i = 1;
j = 0;
while(i<T.length()){
if(j==0 || T[i] == T[j]){
next[++i] = ++j;
}
else{
j = next[j];
}
}
}嗯?怎么和想象中不一样,它这是什么意思?
我们来看一道例题
假设我们现在已经知道next数组1~5号中(想知道为啥以前都说数组从0开始现在都从1开始的先别急,继续看后面)存放的啥,想知道第next[6]是多少,要怎么做呢?
跟next[6]关系最大的就是next[5]了,我们看看next[5] = 2对我们有什么帮助,next[5]=2意思就是
在B之前有最长公共前后缀长度为1,所以能最快判断这个长度是否能再延伸的方法就是
看T[2](也就是T[ next[5] ])是否和T[5]相同,如果相同那么next[6] = next[5]+1,对应代码中的
next [ ++i ] = ++j



那么现在你自己动动灵活的小脑瓜想想如果是不相等的情况要怎么做
再来看一道例题
假设已经求出来1~5号位置对应的next值,要求next[6]的值,还是跟之前一样,看next[5],next[5]=4说明最长公共前后缀=3,我们试试看next[6]能不等于next[5]+1,就是看T[5]?=T[4]
我们发现T[5]≠T[4],说明next[6]不能直接通过next[5]最长公共前后缀向后扩展一位的方式等于5,既然不能等于5,那一点点缩小,能不能等于4呢?也就是最长公共前后缀能不能等于3呢?那就看T[1]T[2]T[3]是否一 一对应T[3]T[4]T[5]
我们把他们next数组的含义写出来找规律
(5结尾,无非就是345,45,5,就有了以下三种情况)
现在已经证明了T[1]T[2] == T[3]T[4],就差T[3]和T[5]相等了,
发现T[5]≠T[3],继续重复之前的步骤,既然next[6]也不能=4,那再继续缩小能不能=3呢,就是判断T[1]T[2]?=T[4]T[5],
现在只需要判断T[2]?=T[5],如果还不相等就只能判断T[1]?=T[5]
所以next[6] = 0+1 = 1;
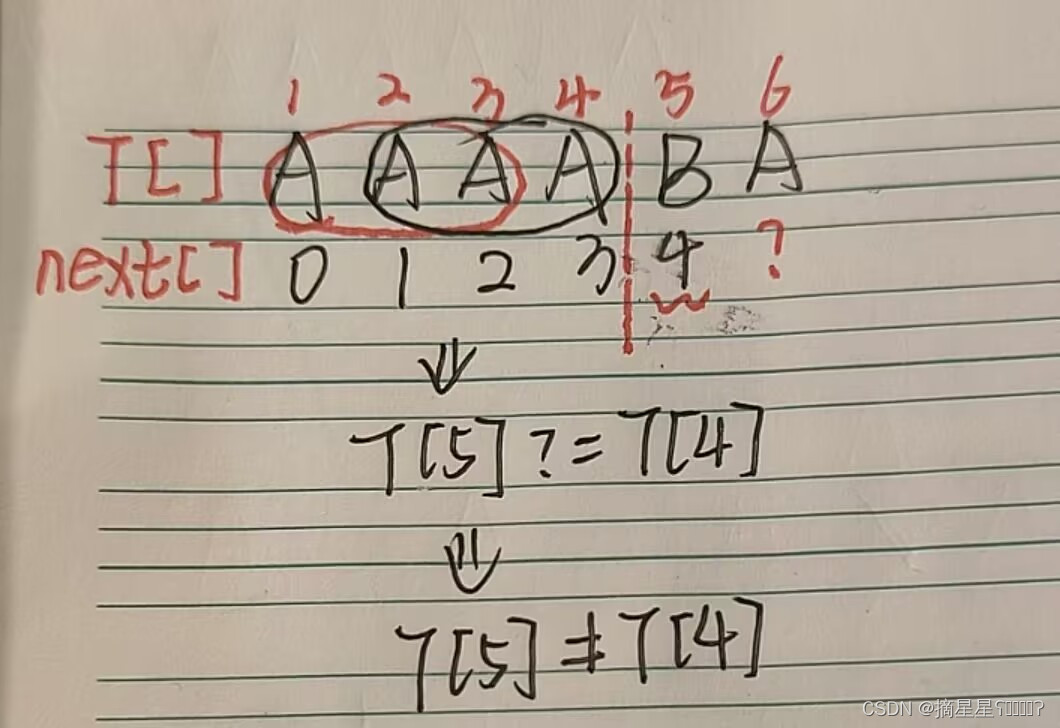




发现了一个规律,T[5]≠T[4] ,就判断T[5]?=T[next[4]],不相等继续T[5]?=T[next[next[4]]],还不相等继续T[5]?=T[next[next[next[4]]]],这不就是我们前面说过的next数组的含义:
如果当前位置不匹配,下一步要去找子串中的谁和当前不匹配的位置比较
对应代码
J = next[j]















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









