







一、 数组

数组,占用连续的内存空间。就相当于一列火车,按着车厢号进行有序的排列,你可以直接的寻找到自己所在的车厢。
数组也类似的,可以通过角标实现随机访问。
for(int i = 0;i<=5:i++)
cout<<a[i]<<endl;但是数组也有缺点:
1.因为数组是在内存中连续的一段存储空间,所以数组一旦被创建,空间就固定了,长度是不能扩增的。 如果需要扩充,必须创建新数组。申请多了又浪费。
在局部变量的数组又不能创建的太大,因为在Windows下,栈的大小为2M,也就是1024*1024*2 = 2097152个字节。而一个int类型的变量则占2个或4个字节。所有我们在程序中声明局部变量时(在栈区,就是在main函数中),最好不好超过int[200000]的内存变量。
2.如果需要在中间插入,需要每个数都往后移。很浪费时间。
前情提要:
我们知道(不知道的点我,我是个链接)
1.地址要用指针接收
2.如果有一int型数组,int a[5]; 那么a是一个指针,存的是这个数组的首地址。(可以用以下代码验证:)
int a[2] = {0,1]; int *p = &a[0]; cout<<"&a[0] = "<<&a[0]<<endl; cout<<"p = "<<p<<endl; cout<<"a = "<<a<<endl;3.两个数组不能直接互相赋值
因为数组是指针常量, int a[] 是 int * const a, int b[] 是 int * const b,一个指针常量不可以被另一个指针常量修改(地址常量不可以被修改)。

这个时候我们就可以用到到链表。但在学习链表之前,先了解一下“->”这个符号。
二、“->”:结构体指针
1.结构体的访问
之前学过,访问结构体时,用 “结构体名” + “ . ”的方式,例如:

2.结构体指针
可以用于间接引用指向的结构体的变量。
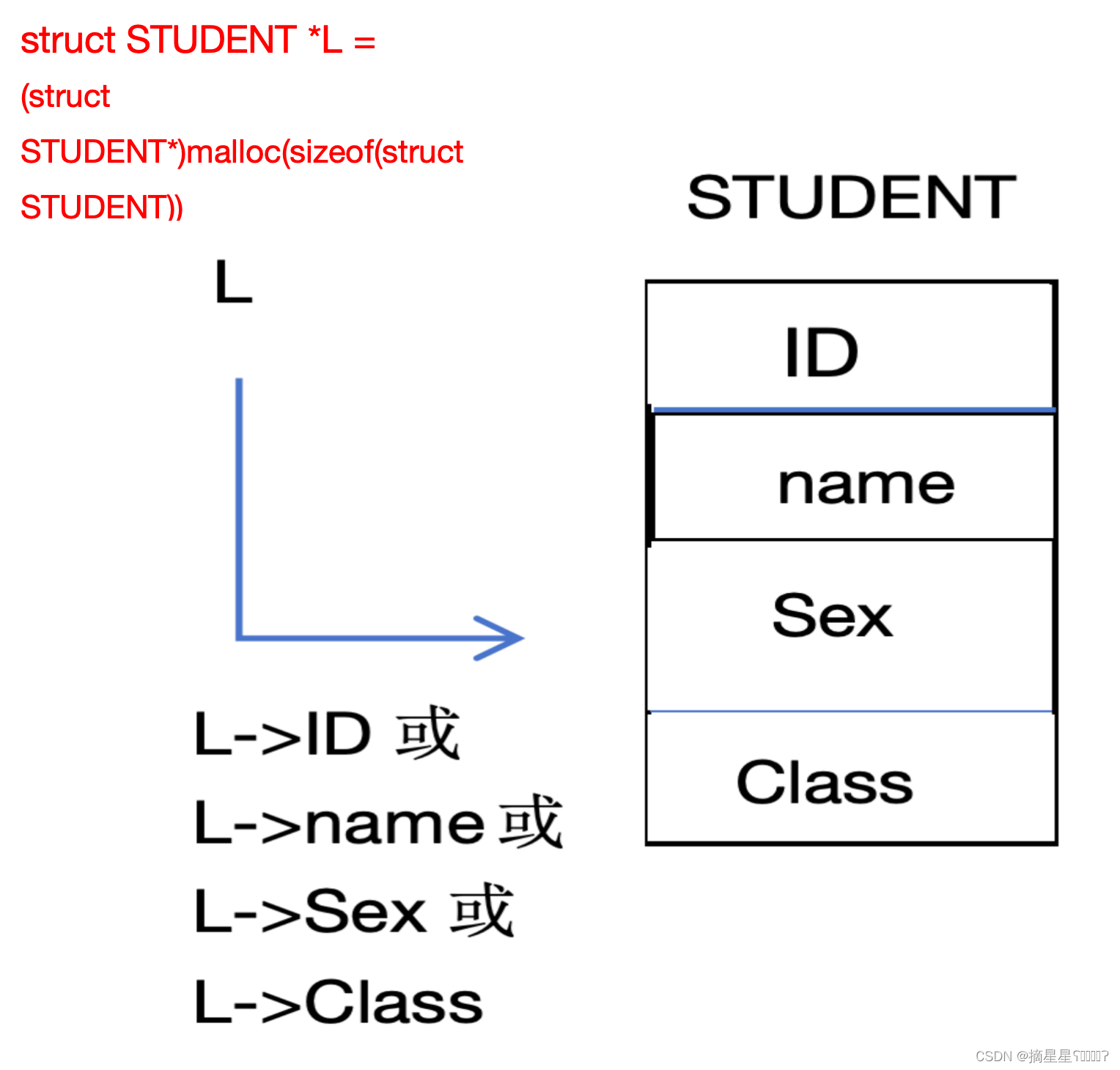
若L是结构体指针,则可以进行L->ID等操作(前提是L是struct STUDRNT型的指针)
与int a[ ],int *p = a相类似的,L接收到的也是链表的首地址。
L->ID == (*L).ID
L->name == (*L).name
3.动态内存申请知识补充
动态内存申请:内存申请在堆区,手动申请,手动释放。
之前我们学过类型强制转换,例如:要把一个float型转换为int型,写作:(int)5.2, 这样5.2就被转换成了5。其实动态内存申请也是类似的:int *p = (int*)malloc(sizeof(int)*n), n为int型数组的长度,因为p是指针,所以返回的是你申请到的这一片内存的首地址。类似于数组中&a[0]或a。
所以在链表中,struct LinkNode* L = (struct LinkNode*)malloc(sizeof(struct LinkNode)),L返回的是链表的首地址(随机生成的)。
也就是说,上面这句代码和下面这段代码是一个意思。
struct STUDENT st,*head;
head = &st;
感觉很神奇哈哈哈🥹,原谅我以前什么都不懂😌
三、 链表
到底是谁在把链表比作火车,它们中间根本没有什么勾结😡!而且链表的排列又不是有序的😡!我还以为中间有什么东西把它们串成一根线,😡!

学习下面内容之前,你可以暂时想像成旋转木马(也是一个好不到哪的比喻),它们之间不是按着什么顺序排列的。
链表由一个个结点组成,在物理存储单元中是不连续的,由指针把它们连接在一起。(怎么理解这里说的连接呢,其实我认为这个连接的过程其实是寻找的过程,因为首先你会拿到表头的地址,表头里存着下一个结点的地址,你找到下一个结点之后里面又存着下下一个结点的……)
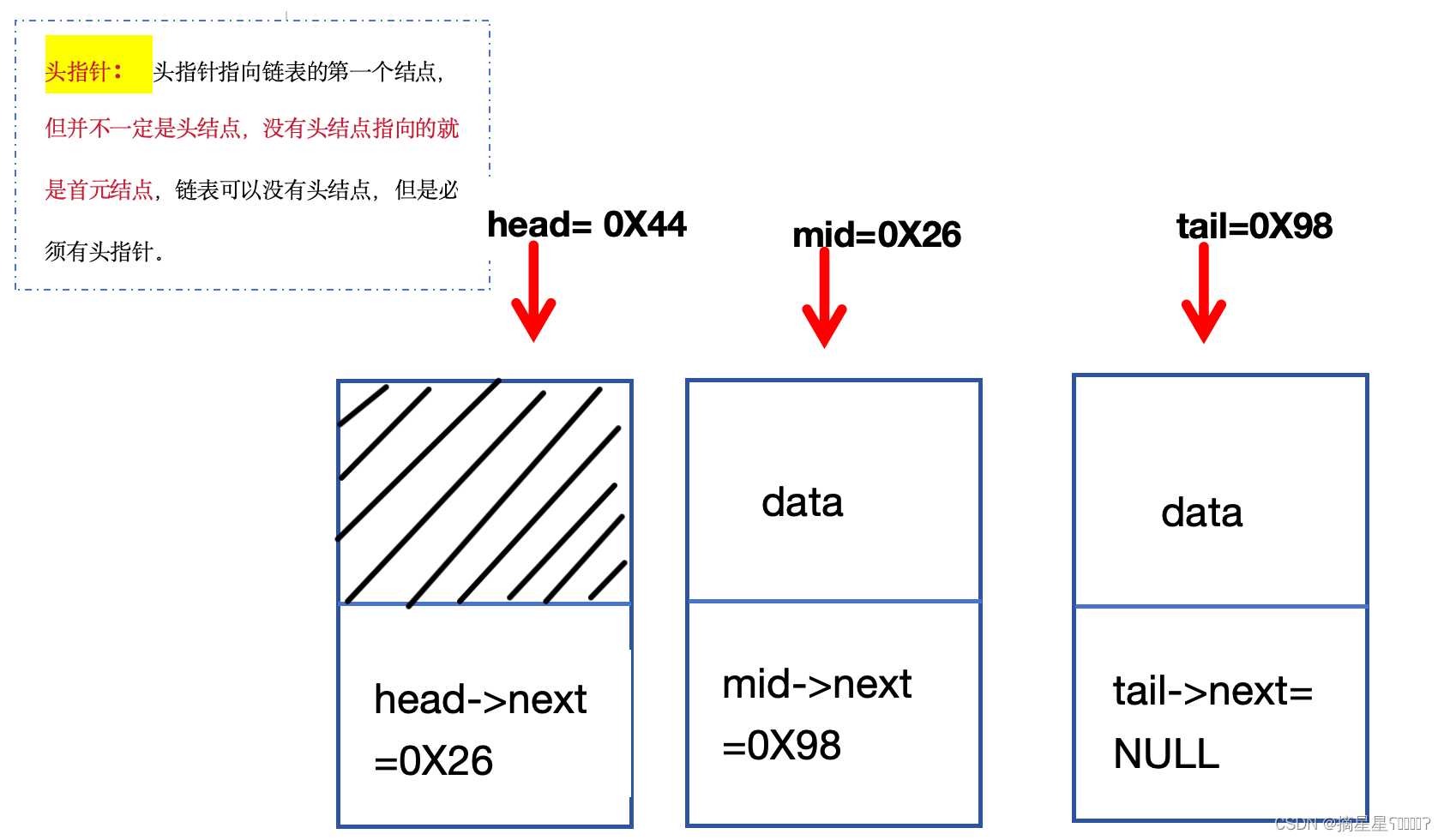
在上图中,head,mid,tail是结构体指针,是它们结点的首地址,相当于&a[0]或者是a,既然是结构体指针,就可以像结构体一样st.name,也就是(*mid).data;
而每个结点的next,也是指针但不是结构体指针,但它们保存的地址是结构体指针的地址。
最直观的说就是,head可以head->next,mid可以mid->next,但是next 不能next->data或者next->next,但是head->next可以head->next->next,因为head->next就是mid.
头指针:指向第一个结点,可以是指向头结点或者首元结点的指针。
头结点:是链表有效结点前面附加的结点,一般不记录信息,
1. 头结点
那为什么要有头结点呢?
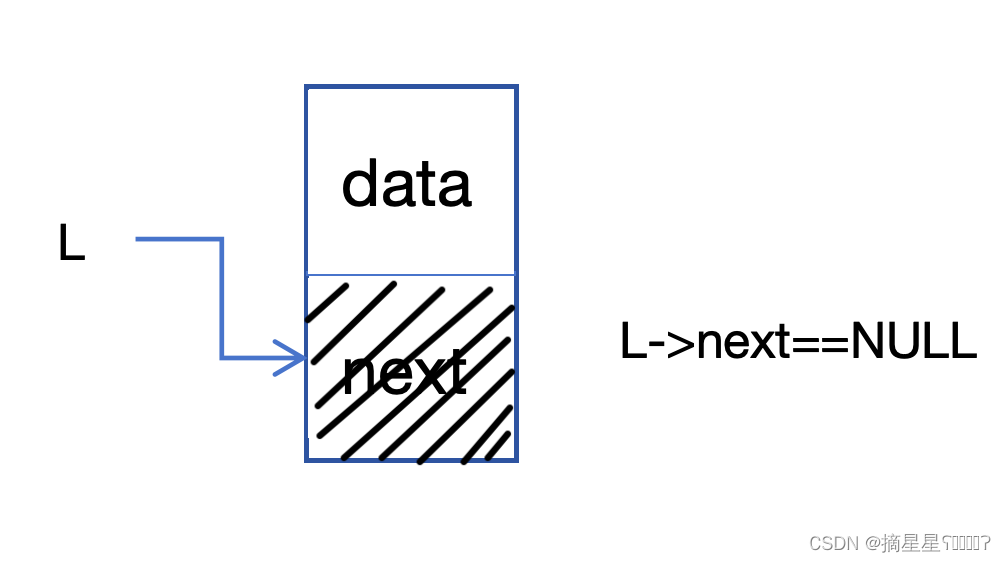
头结点是为了防止链表为空设计的,
当无头结点时: L == NULL(NULL用于指示指针未指向有效位置。理想情况下,如果在声明时不知道指针的值,则应将指针初始化为NULL。另外,当由它指向的内存在程序中间被释放时,我们应该使指针为NULL。 )
当有头结点时:L->next == NULL

2. 设计链表
struct LinkNode{
int data;
struct LinkNode* next;
//之前我们学的创建指针是: int *p; 代表是int 类型的
//在链表中,每个结点都是是你统一自定义的一个结构体,
//所以指针是:struct LinkNode*,代表是struct LinkNode类型的,意思就是存着struct LinkNode型的数据的地址
};为了用起来更方便,可以用typedef重命名.
pLN相当于struct LinkNode*,是指针
LN相当于struct LinkNode,是结构体
typedef struct LinkNode{
int data;
struct LinkNode* next;
}*pLNode,LNode;3.创建链表——尾插法
尾插法就是新结点插入到链表结尾
#include<stdlib.h>//包含malloc函数
struct LinkNode{
int data;
struct LinkNode *next;
}LinkNode,*pLinkNOde;
int main(){
pLinkNode head = (pLinkNode)malloc(sizeof(LinkNode));//创建头结点
//(相当于强制转换)
head -> next = NULL;
pLinkNode tail ;
tail = head ;//定义了一个末尾结点,但一开始什么都没有,所以末尾结点的地址就是head的地址
cout<<"请输入你要创建的链表长度"<<endl;
int n;
cin>>n;
cout<<"请输入你要输入的数据"<<endl;
for(int i =0;i < n;i ++){
int num;
cin>>num;
pLinkNode t = (pLinkNode)malloc(sizeof(LinkNode));
t -> data = num;
t -> next = NULL;
tail -> next = t;
tail = t;
}
}

其实关键就三句:
1) t->next=NULL;新建的结点next 指向空
2)tail->next=t;原来在链表结尾的结点里的next 不再为空,让他保存新结点的地址,这个时候你已经完全的把它们连接好了,tail已经不是末尾结点了,而是变成了倒数第二个结点,所以还要第三步:
3)t=tail;t变成新的末尾结点(不要想不明白,t,tail,head它们都只是指针,这个赋值就是互相给地址而已)
遍历链表
t = head;//t一直是一个媒介,谁的地址复制给了它都对这整个链表没有一点关系
//就像a与b交换值时,t=a;a=b;b=t;t只是一个中介,交换成功之后你再把谁的值给t都对ab没有任何影响
while(t->next!=NULL){//有头结点就这么判断
cout<<t->next->data;
t = t->next;}//t向下一个移动
4.创建链表——头插法
头插法就是把新结点插入到链表表头之后,核心代码如下
pLinkNode head = (pLinkNode)malloc(sizeof(LinkNode));
for(int i = 0;i<n;i++){
pLinkNode t = (pLinkNode)malloc(sizeof(LinkNode));//t是新结点的地址
int data;
cin>>data;
t->data = data;
t->next = head->next;//这一句和下面这句的顺序不能反,是先让t->next存原来head->next存的值,如果反了:head存的地址就已经先变成新结点的地址,那么新结点指向谁?你怎么表达?
head->next=t;//头结点的next存的是新结点的地址
}
遍历
遍历和上面是一样的也是找一个第三者t,让他=head的地址,然后不断地t=t->next,这里就不写了。














 496
496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









