






目录
一.朴素贝叶斯
1.朴素贝叶斯的概念
朴素贝叶斯(Naive Bayes)是一种基于贝叶斯定理和特征条件独立假设的分类方法。朴素贝叶斯分类器基于一个强假设:给定类别下,特征之间相互独立。这个假设在现实中往往不成立,但在很多情况下,朴素贝叶斯分类器依然能够取得很好的分类效果。
朴素贝叶斯是贝叶斯决策理论的一部分,所以讲述朴素贝叶斯之前有必要快速了解一下贝叶斯决策理论。假设现在我们有一个数据集,它由两类数据组成,数据分布如下图所示:
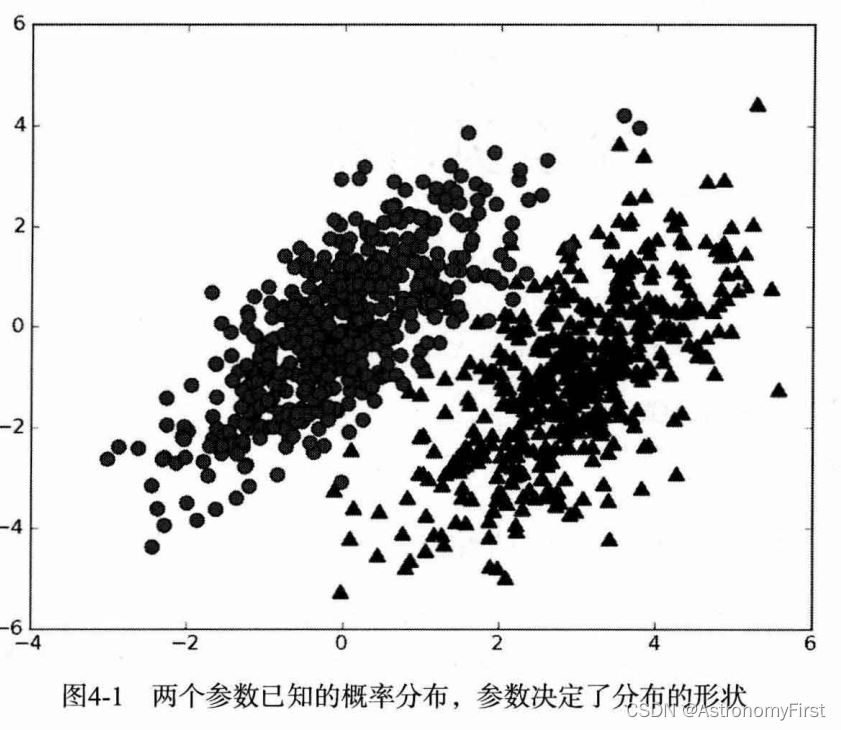
我们现在用p1(x,y)表示数据点(x,y)属于类别1(图中用圆点表示的类别)的概率,用p2(x,y)表示数据点(x,y)属于类别2(图中用三角形表示的类别)的概率,那么对于一个新数据点(x,y),可以用下面的规则来判断它的类别:
如果 p1(x,y) > p2(x,y),那么类别为1;如果 p2(x,y) > p1(x,y),那么类别为2。
也就是说,我们会选择高概率对应的类别。这就是贝叶斯决策理论的核心思想,即选择具有 最高概率的决策。
2.条件概率
在了解贝叶斯定理之前,先对条件概率有一个初步的认识
已知两个独立事件A和B,事件B发生的前提下,事件A发生的概率可以表示为P(A|B),即:
那么同理,我们也可以得到在事件A发生的前提下,事件B发生的概率公式为:
那么将P(AB)利用条件概率公式进行变换后,就可以得到著名的贝叶斯定理公式为:
3.朴素贝叶斯分类器
先验概率P(X):通常是指根据以往的经验和分析得到的概率,表示事件X所发生的概率
后验概率P(Y|X):表示在事件X发生的情况下,事件Y发生的概率,可通过条件概率公式求出
后验概率P(X|Y):表示在事件Y发生的情况下,事件X发生的概率
朴素:朴素贝叶斯算法是假设各个特征之间相互独立,那么贝叶斯公式中的分子可写成如下形式:
4.优缺点
利用朴素贝叶斯分类器实现分类有什么优缺点:
优点:(1)模型简单,易于实现 (2)分类速度快 (3)在文本分类等领域表现出色
(4)对缺失数据不太敏感 (5)对多类别分类问题效果好
缺点:(1)特征独立性假设:朴素贝叶斯分类器假设所有特征之间是相互独立的,这在现实中往往不成立。当特征之间存在较强的相关性时,朴素贝叶斯分类器的性能会受到影响
(2)对输入数据的表达形式敏感 (3)对参数估计敏感 (4)对不平衡数据集敏感
(5)对于非数值型数据需要预处理
二.例子
1.小明做作业
下面通过一个例子更好的理解朴素贝叶斯算法
(1)假设有一个人名叫小明,有一天老师留了一道作业题,但是作业的题目非常难,小明便打算给30个同学发求助消息。这30个回复中,既有作业答案,也有对小明的深情告白。其中小明能分辨的,其中有16份作业答案,还有13份情书,唯独有一个同学的回复小明看不懂。于是小明想通过消息中的关键词来给这一份未知的回复进行分类,看看到底是作业还是情书(所要解决的问题)。

(2)首先我们假设小明收到的消息中有如下这四个关键词(即特征):喜欢、明天、红豆、辛苦,同时,我们可以知道,P(作业)=,P(情书)=
并且每个关键词在作业和情书的出现的次数如下:

(3)所以我们可以根据以上的数据计算出相应的条件概率如下:
P(喜欢|作业)= P(明天|作业)=
P(红豆|作业)=
P(辛苦|作业)=
P(喜欢|情书)= P(明天|情书)=
P(红豆|情书)=
P(辛苦|情书)=
(4)假设这份未知的回复中包含红豆和喜欢这两个关键词,所以通过计算:
假设回复是作业的正确概率为:P(作业)P(红豆|作业)P(喜欢|作业)=0.0147 (P1)
假设回复是情书的正确概率为:P(情书)P(红豆|情书)P(喜欢|情书)=0.0731 (P2)
即:P2>P1,小明得出结论,这份未知的回复确认为情书,问题得以解决,这就是朴素贝叶斯法,但有时算法的计算会出现问题。(往下看)
2.拉普拉斯平滑技巧
(1)假设有一段卑微的告别是这样写的:

(2)按照算法计算正确程度:
是作业的正确概率为:P(作业)P(辛苦|作业)P(喜欢|作业)^3=0.00176 (P1)
是情书的正确概率为:P(情书)P(辛苦|情书)P(喜欢|情书)^3=0.00000 (P2)
因为在情书中没有辛苦这个关键词出现过,导致P2的计算结果为0,算法会把信息判断为作业。因此,为了解决这一问题,我们可以使用拉普拉斯平滑技巧。
(3)人为在每一个关键词上增加一个出现的次数,如下:

(4)重新计算各个条件概率如下:
P(喜欢|作业)= P(明天|作业)=
P(红豆|作业)=
P(辛苦|作业)=
P(喜欢|情书)= P(明天|情书)=
P(红豆|情书)=
P(辛苦|情书)=
(5)再根据算法重新计算:
是作业的正确概率为:P(作业)P(辛苦|作业)P(喜欢|作业)^3=0.00189 (P1)
是情书的正确概率为:P(情书)P(辛苦|情书)P(喜欢|情书)^3=0.00311 (P2)
所以:P2>P1,这是一封情书,这就是拉普拉斯平滑技巧。
三.利用朴素贝叶斯进行西瓜分类
1.创建本次所要用到的西瓜数据集及其特征还有测试集
def createdataset():
#数据集
dataset = [
['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', '好瓜'],
['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', '好瓜'],
['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '好瓜'],
['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘', '好瓜'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑', '好瓜'],
['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', '坏瓜'],
['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘', '坏瓜'],
['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑', '坏瓜'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘', '坏瓜'],
['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑', '坏瓜'],
['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑', '坏瓜'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '坏瓜'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑', '坏瓜'],
['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑', '坏瓜']
]
#测试集
testset=[['青绿','蜷缩','沉闷','清晰','凹陷','硬滑'],['乌黑','硬挺','清脆','清晰','稍凹','硬滑']]
# 特征值列表
labels = ['色泽', '根蒂', '敲击', '纹理', '脐部', '触感']
return dataset,testset,labels2.计算先验概率P(好瓜)、P(坏瓜)输出结果并返回
1>代码:
def calpriority(dataset):
#计算好瓜和怀瓜的数量
total_count = len(dataset)
good_melon = 0
bad_melon = 0
for sample in dataset:
if sample[-1] == '好瓜':
good_melon += 1
else:
bad_melon += 1
p_good = good_melon/total_count
p_bad = bad_melon/total_count
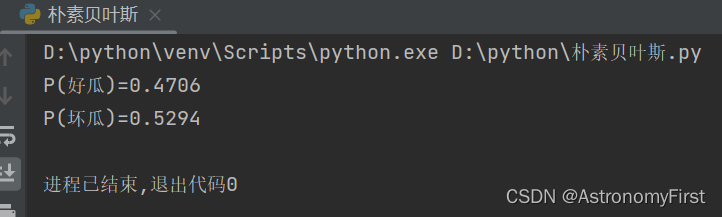
print(f"P(好瓜)={p_good:.4f}")
print(f"P(坏瓜)={p_bad:.4f}")
return p_good,p_bad2>计算的结果:
3.计算各个特征值的后验概率
1>代码:
def calposterior(dataset):
#将原数据集划分为好瓜和坏瓜数据集
good_dataset = [sample for sample in dataset if sample[-1] == '好瓜']
bad_dataset = [sample for sample in dataset if sample[-1] == '坏瓜']
#计算好瓜中的各个特征的后验概率(即条件概率)
good_length = len(good_dataset)
good_result = {}
#统计个数并计算结果
for sample in good_dataset:
for word in sample:
if word not in ['好瓜']:
if word not in good_result:
good_result[word] = 1
else:
good_result[word] += 1
for word,count in good_result.items():
good_result[word] = count/good_length
for word,count in good_result.items():
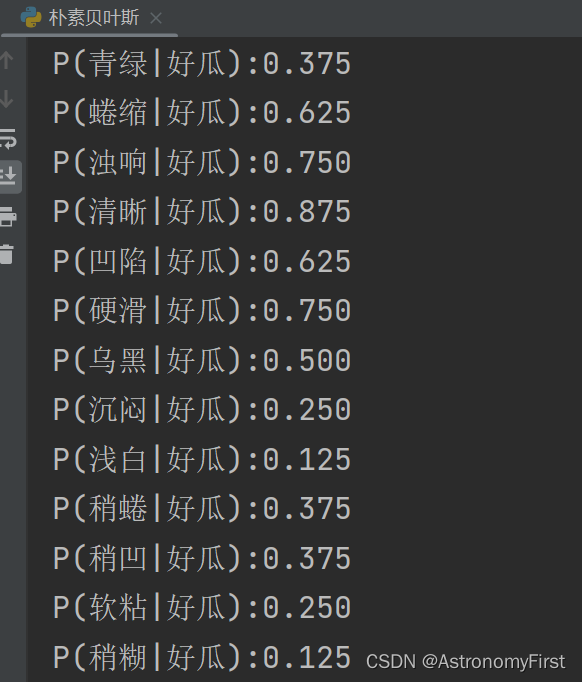
print(f"P({word}|好瓜):{count:.3f}")
#计算坏瓜中的各个特征的后验概率(即条件概率)
bad_length = len(bad_dataset)
bad_result = {}
#统计个数并计算结果
for sample in bad_dataset:
for word in sample:
if word not in ['坏瓜']:
if word not in bad_result:
bad_result[word] = 1
else:
bad_result[word] += 1
for word,count in bad_result.items():
bad_result[word] = count/bad_length
for word,count in bad_result.items():
print(f"P({word}|坏瓜):{count:.4f}")
return good_result,bad_result,good_dataset,bad_dataset2>好瓜数据集中的各个特征值的后验概率计算结果:
3>坏瓜数据集中的各个特征值的后验概率计算结果:
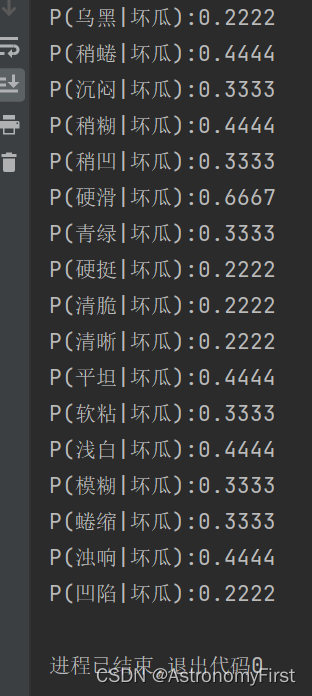
4.对测试集进行计算并分类
1>代码:
def calresult(testset, pgood, pbad, good_if, bad_if):
count1=0
for each in testset:
count1 += 1
calgood = pgood
calbad = pbad
for sample in each:
# 计算测试集为好瓜的概率
flag = 0
for word,count in good_if.items():
if sample == word:
flag = 1
calgood *= count
break
if flag == 0 :
calgood *= 0
# 计算测试集为好瓜的概率
flag1 = 0
for word,count in bad_if.items():
if sample == word:
flag1 = 1
calbad *= count
break
if flag1 == 0 :
calbad *= 0
print(f"计算得出该第{count1}个测试集为好瓜的概率为:{calgood:.4f}")
print(f"计算得出该第{count1}个测试集为坏瓜的概率为:{calbad:.4f}")
if calgood > calbad:
print(f"通过朴素贝叶斯计算得出,第{count1}个测试集的预测结果为:好瓜")
else:
print(f"通过朴素贝叶斯计算得出,第{count1}个测试集的预测结果为:坏瓜")2>计算结果截图:

3>结果分析:
由结果可知,第一个测试集所计算的分类的结果是没有错误的。因为第一个测试集中的每一个特征在好瓜和坏瓜中均有分布,因此不会计算得出0的结果;而第二个测试集因为'硬挺'和'清脆'这两个特征在好瓜数据集中均没有分布,因此P(硬挺|好瓜)=P(清脆|好瓜)=0,而导致计算得出第二个测试集为好瓜的概率为0,因此要用到拉普拉斯平滑技巧进行修正
5.拉普拉斯平滑技巧修正
1>修正好瓜中的条件概率代码:
def revision( dataset, good_dataset):
length = len(good_dataset)
length2 = length + 3
for word,count in dataset.items():
if word in ['蜷缩','稍蜷']:
dataset[word] = count * length / length2
if word in ['浊响','沉闷']:
dataset[word] = count * length / length2
dataset['硬挺'] = 1 / length2
dataset['清脆'] = 1 / length2
print("更正后好瓜数据集中的条件概率:")
for word, count in dataset.items():
print(f"P({word}|好瓜):{count:.4f}")
return dataset2>修正后的条件概率的结果如下:
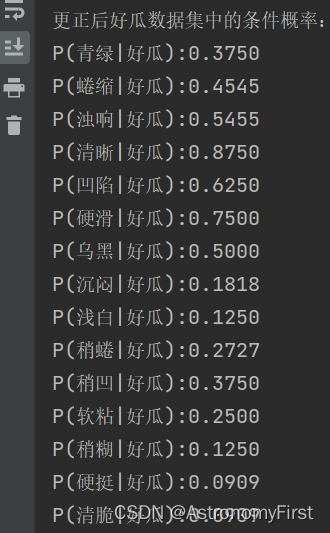
3>计算结果:
未修正:

修正后:

4>结果分析:
由结果分析可知,计算得出第二个测试集为好瓜的概率已经不为0,修正成功
四.总结
在本次机器学习的实验中,我采用了朴素贝叶斯算法进行分类任务。朴素贝叶斯基于特征之间的条件独立性假设,通过计算各特征属于不同类别的概率来进行预测。实验过程中,我准备了训练数据集和测试数据集,利用训练集学习模型参数,并使用测试集评估模型性能。
在整个实验流程中,我学会了如何对相应的先验概率以及后验概率的计算,并通过朴素贝叶斯算法通过计算出的结果来对测试集进行分类。同时,也学会了当计算出的结果为0的情况,如何利用拉普拉斯平滑技巧来进行数据的更正,并重新计算出正确的结果。
总之,本次实验加深了我对朴素贝叶斯算法的理解,并验证了其在分类任务中的有效性。在未来的学习和研究中,我将进一步探索其他机器学习算法,以应对更复杂和多样化的实际问题。















 1357
1357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









