







 本文探讨了在数据分析场景中,Python相比于Excel的优势。Python简化了数据读取、筛选、排序、去重、统计和可视化等任务,提高了效率。对于大型数据集,Python表现更优,而Excel在小规模数据和快速原型设计时仍有其便利性。掌握Python能实现自动化和高效的数据处理。
本文探讨了在数据分析场景中,Python相比于Excel的优势。Python简化了数据读取、筛选、排序、去重、统计和可视化等任务,提高了效率。对于大型数据集,Python表现更优,而Excel在小规模数据和快速原型设计时仍有其便利性。掌握Python能实现自动化和高效的数据处理。
现在很多行业,都离不开Excel:
做财务的,要用Excel做报表;
做物流的,会用Excel来跟踪订单情况;
做HR的,会用Excel算工资;
做运营的,会用Excel记录数据做分析。
不知道你有没有这样的经历,每次你用Excel做数据分析时,往往都要生成好多张工作簿,做中间计算的时候,鼠标要一路移到最后一页,才出现最终结果。所以想学的同学,有必要听一下这位老师的课、领取python福利奥,想学的同学可以到梦雅老师的围鑫(同音):前排的是:762,中间一排是:459,后排的一组是:510 ,把以上三组字母按照顺序组合起来即可,她会安排学习的。
如果其中某个数据出了些问题,你可能要从头开始,排查错误,很容易看花眼,错上加错。

为了避免这种情况,很多人开始学Excel的高级技能 - VBA。
但其实,VBA并不容易学,而且在数据量大的情况下,VBA运行很耗时。
那么我们应该怎么解决呢?用Python呀!
**相比VBA,Python非常容易入门,而且用途广泛。**别人用Excel花2天做的事情,Python1ge 小时就能搞定。
下面就用几个常见的操作带你感受一下:
数据读取、生成、存储
Excel读取本地数据需要打开目标文件夹选中该文件并打开
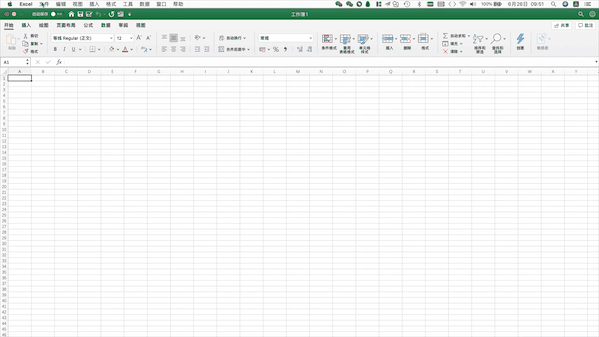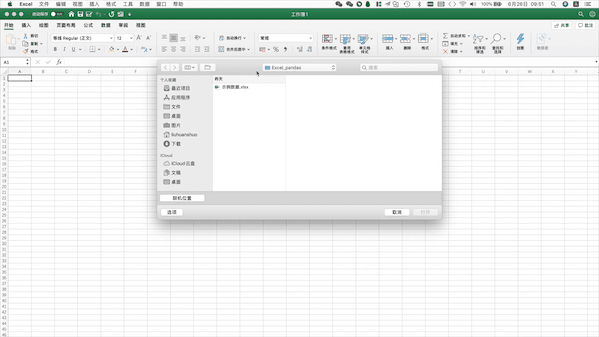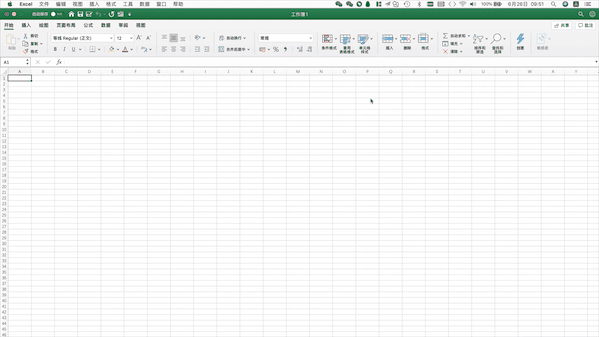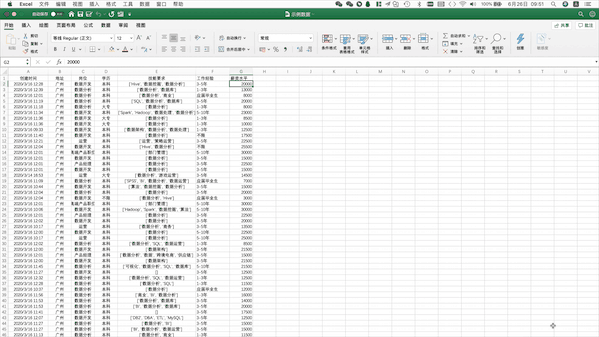
Pandas支持读取本地Excel、txt文件,也支持从网页直接读取表格数据,只用一行代码即可,
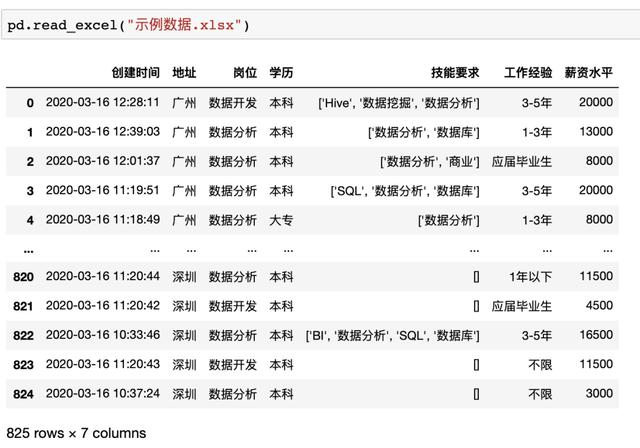
例如读取上述本地Excel数据可以使用pd.read_excel(“示例数据.xlsx”)
以生成10*2的0—1均匀分布随机数矩阵为例,在Excel中需要使用rand()函数生成随机数,并手动拉取指定范围
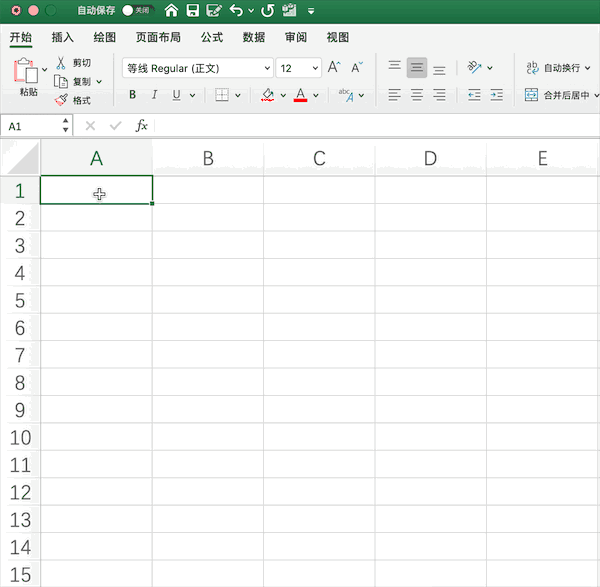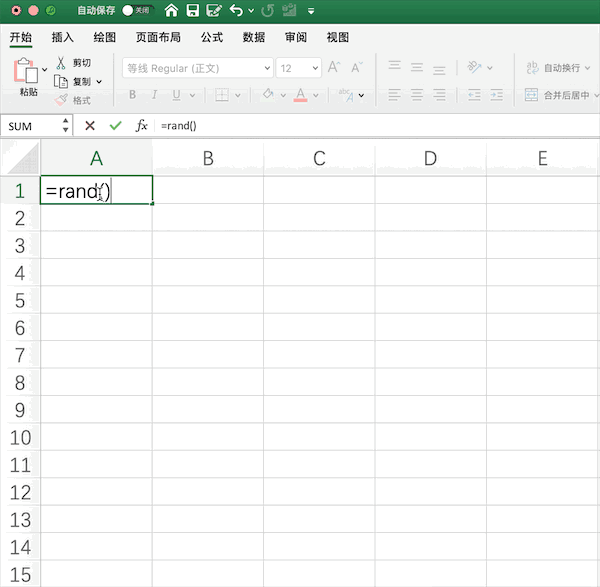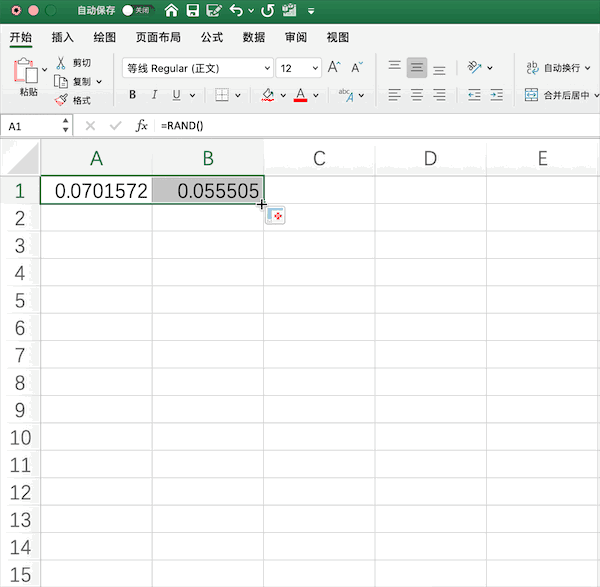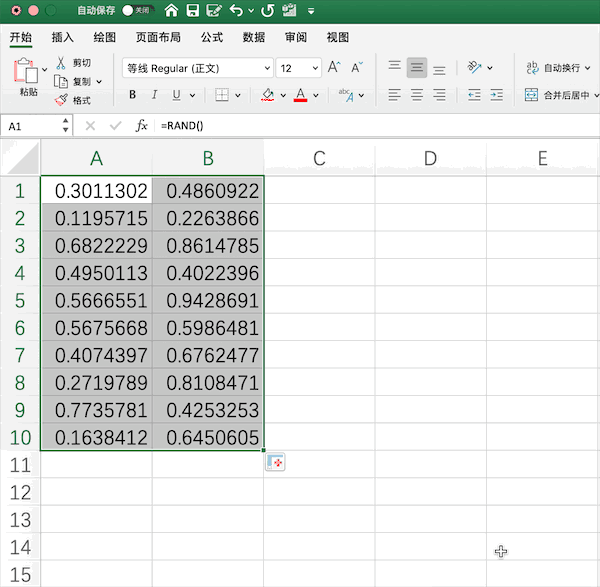
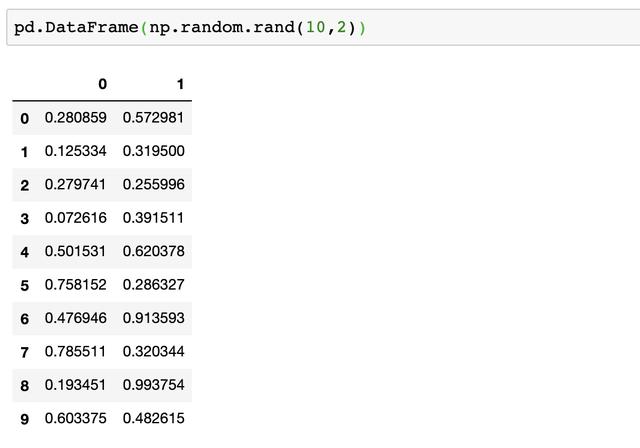
在Pandas中可以结合NumPy生成由指定随机数(均匀分布、正态分布等)生成的矩阵,例如同样生成10*2的0—1均匀分布随机数矩阵为,使用一行代码即可:pd.DataFrame(np.random.rand(10,2))
在Excel中需要点击保存并设置格式/文件名
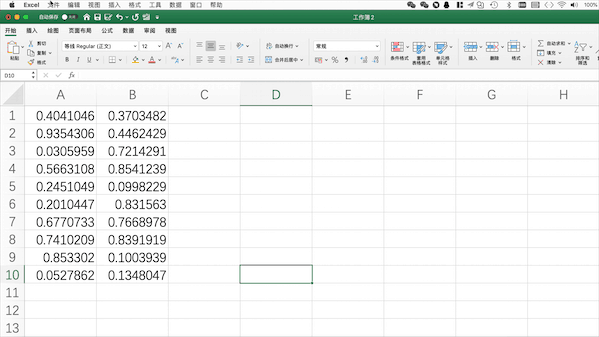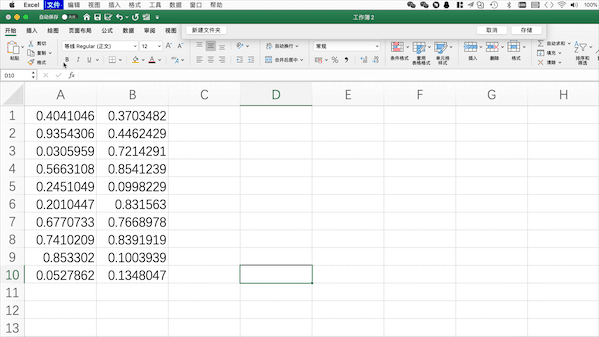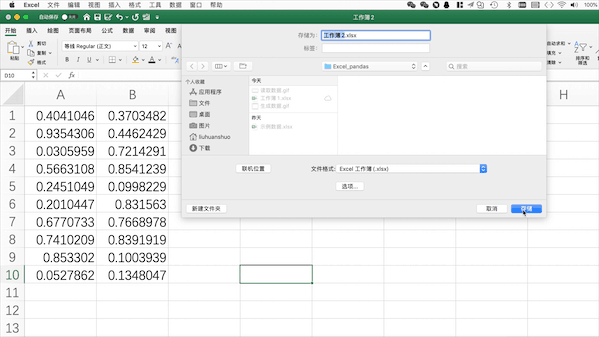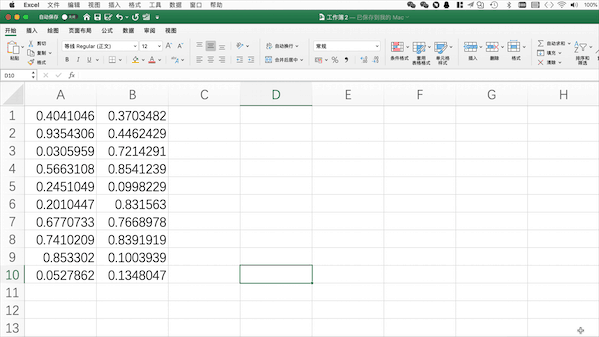
在Pandas中可以使用
pd.to_excel(“filename.xlsx”)来将当前工作表格保存至当前目录下,当然也可以使用to_csv保存为csv等其他格式,也可以使用绝对路径来指定保存位置

筛选、排序、去重数据
使用我们之前的示例数据,在Excel中筛选出薪资大于5000的数据步骤如下
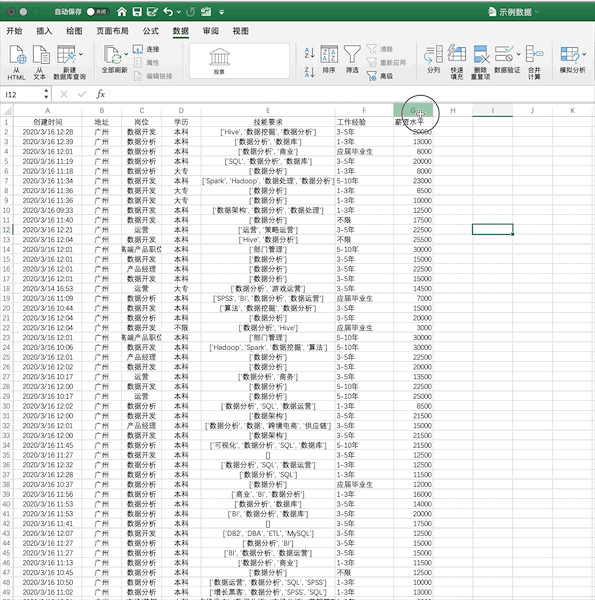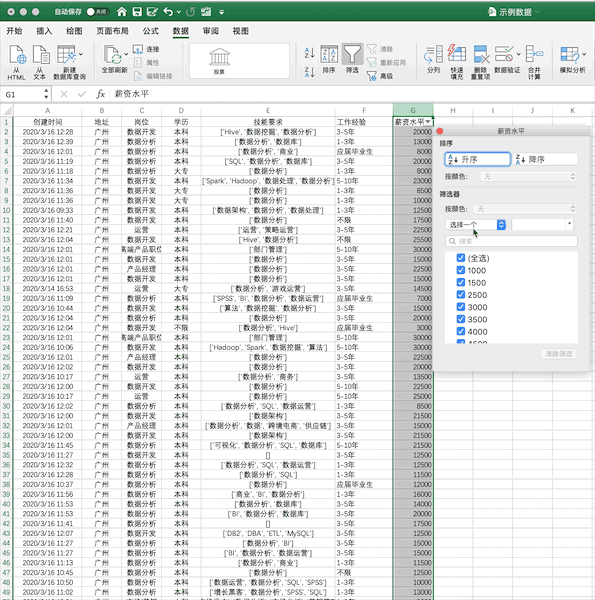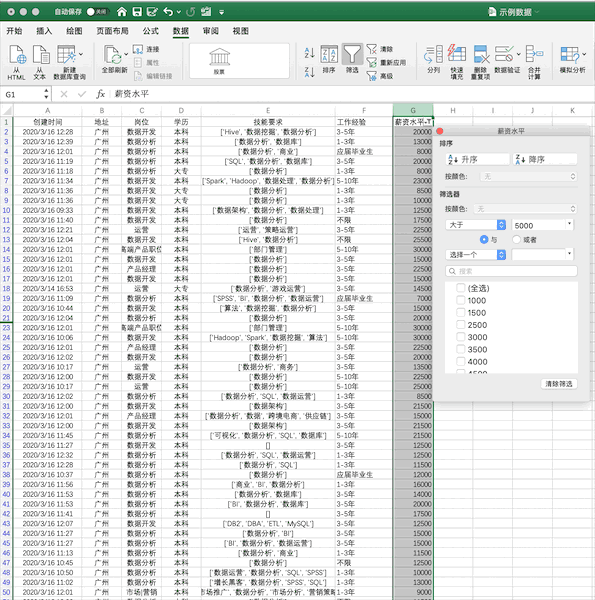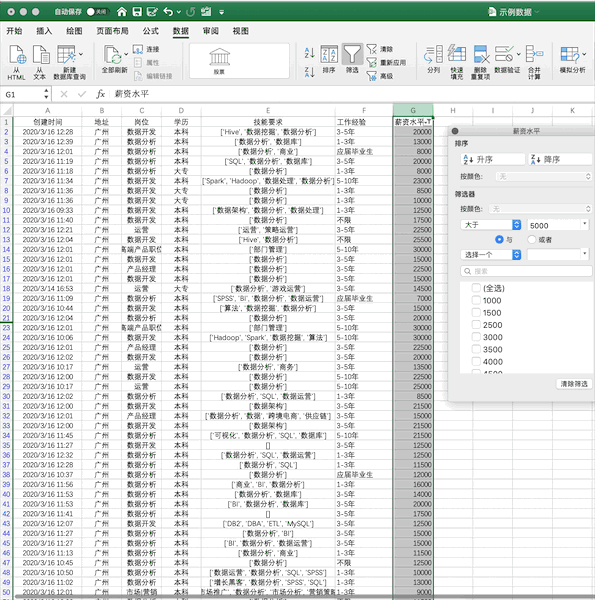
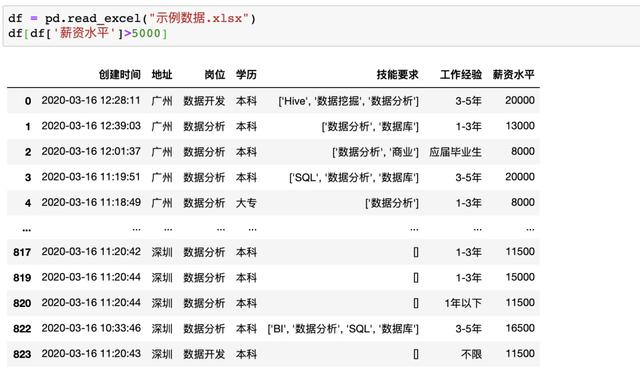
在Pandas中,可直接对数据框进行条件筛选,例如同样进行单个条件(薪资大于5000)的筛选可以使用df[df[‘薪资水平’]>5000],如果使用多个条件的筛选只需要使用&(并)与|(或)操作符实现。所以想学的同学,有必要听一下这位老师的课、领取python福利奥,想学的同学可以到梦雅老师的围鑫(同音):前排的是:762,中间一排是:459,后排的一组是:510 ,把以上三组字母按照顺序组合起来即可,她会安排学习的。
在Excel中可以点击排序按钮进行排序,例如将示例数据按照薪资从高到低进行排序可以按照下面的步骤进行
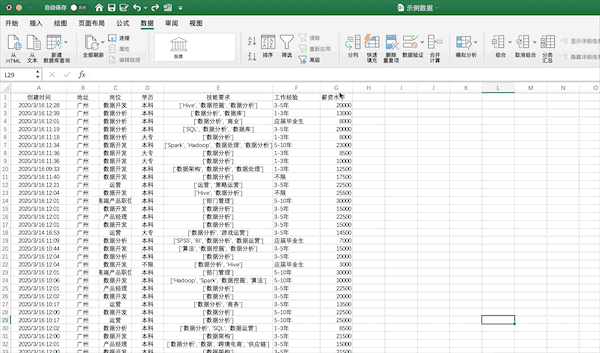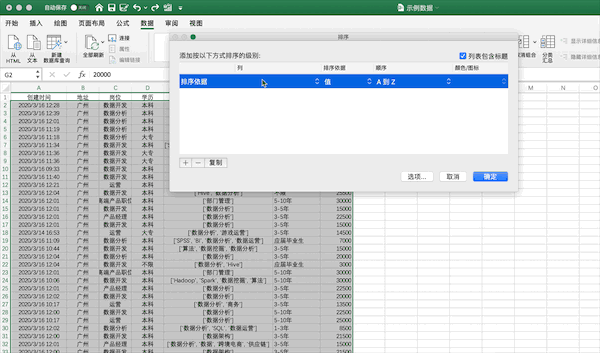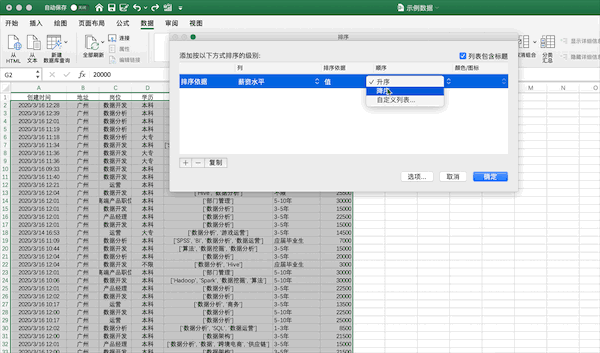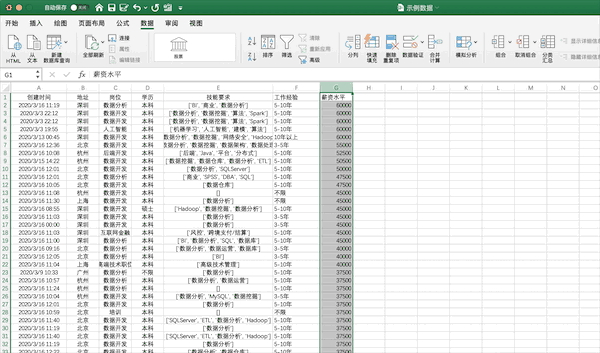
在pandas中可以使用sort_values进行排序,使用ascending来控制升降序,例如将示例数据按照薪资从高到低进行排序可以使用df.sort_values(“薪资水平”,ascending=False,inplace=True)

在Excel中可以通过点击数据—>删除重复值按钮并选择需要去重的列即可,例如对示例数据按照创建时间列进行去重,可以发现去掉了196 个重复值,保留了 629 个唯一值。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 843
843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









