








Hi,大家好,我叫 Danny,很高兴今天能和大家一起来探讨一些关于聊天机器人的话题。
先自我介绍一下,我本科毕业于中山大学,工作两年后到卡耐基梅隆大学读博士,博士期间的研究方向是多媒体和深度学习,博士毕业后到一家智能监控公司做了一段时间视频监控方面的研究,现在在 Google 的研究部门工作,因为工作敏感性的原因,我想先声明一下,这个讲座的所有观点仅代表我个人的观点,跟 Google 以及我在 Google 所做的工作无关。
我今天要讲的话题非常有趣,是关于聊天机器人的历史、现状和未来的。
如果大家关注聊天机器人的进展就会发现,现在很多聊天机器人都有 Samantha 的部分功能了,比如微软的小冰也会讲笑话,会作曲,亚马逊的 Alexa 也能叫我们起床,播放音乐,很多推荐系统会读取我们的个人信息并帮助我们做很多事情,当然要真正做到像 Samantha 一样,我们还有很长的路要走。
但一个不可否认的事实是聊天机器人正变得越来越智能,能够帮我们做的事情越来越多。
我们今天要讲的聊天机器人是广义上的聊天机器人,它包括问答系统,比如 IBM 的 Waston;对话系统,如苹果的 Siri,亚马逊的 Alexa,和 Google 的 Assistant 都属于这一类;当然还有传统定义上的聊天机器人,如微软小冰,Mitsuku 和国内很有名的贤二机器僧。
我们今天会围绕两条主线来讲:
第一条是聊天机器人演化史上著名的聊天机器人的一些主要功能,我们会从第一个著名的聊天机器人 Eliza 开始,一直讲到 IBM 的 Waston,Google 的 Assistant。当然我们不会每个都讲,只会挑一些有代表性的讲,对其他类似的会一笔代过,这里所列的也不尽完整,有很多著名的机器人我这里没有列到,比如百度和出门问问都有自己的聊天机器人,但因为它们跟我列到的一个或多个比较相似,这里就不详列了。
第二条主线是聊天机器人架构的演化,这里我们有三个模块,最上面的模块代表的是比较古老的 Chatbot 框架,非常简单,只能处理文本,而且只能做一些比较简单的模式匹配;中间的模块代表是现有大部分聊天机器人的架构,我们现在大部分的聊天机器人都能做到比较好的语音识别,自然语言理解 NLU,还有一些能够执行比较复杂的查询和动作,属于 Dialogue Management 系统,之后根据这个对话管理系统所发出的指令它能够做一些比较复杂的动作,或者能够生成自然语言,做一些声音的合成,传达回一些信息。
那最下面的模块是代表当前比较流行的研究方向,和图片处理一样,现在学术界的普遍希望是能够通过大量的数据来训练一个足够复杂的神经网络模型,从而代替现有的各个分开的一个模块。
在继续深入探讨每个模块之前,我想先聊聊几个聊天机器人兴起,或者为什么我们现在要玩儿聊天机器人原因。
第一个原因当然是手机聊天的兴起,根据 BI Intelligent 估计,在短短的几年内,手机聊天的月活跃量、用户活跃量从远低于社交平台到 15 年开始远超社交平台。其实不用这些数据我们大概也能估计到,现在有大部分的人用的最多,或者是最离不开的 APP 大概是微信吧。
微信的聊天平台的流行给 Chatbot 发展带来了两个便利:第一个是数据,我们可以有海量的数据训练非常复杂的模型;第二个是用户,通过这些聊天的 APP,Chatbot 得到大量的用户,这些用户不用改变自身的聊天习惯,就可以和 Chatbot 很自然的进行交互。
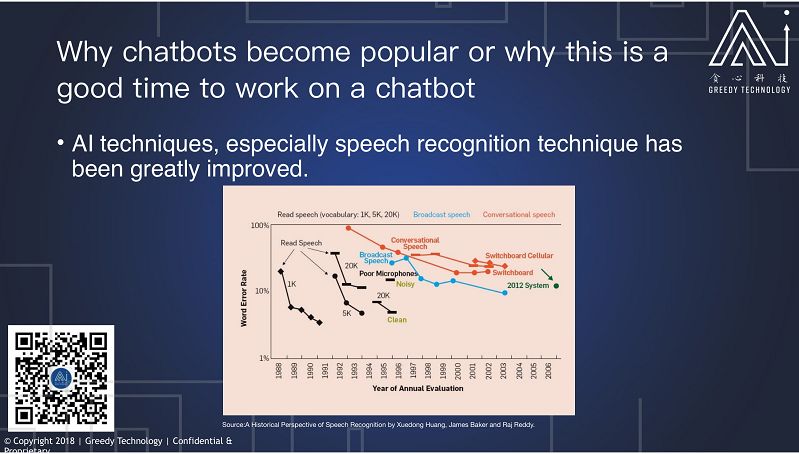
第二个原因是技术的发展,特别是语音识别技术的发展。这张图展示的是从 1988 年以来语音识别技术的发展,横轴所展示是年份,纵轴是错误率。从最开始我们只能识别慢速的,非常不自然的实验室数据,到慢慢的我们能够识别广播数据,到现在我们能够对日常的交流的语音比较,做比较好的识别。
这里最好的是,一个是 2012 年的系统,大概能到达 12% 的准确率,现在我们能够识别到低于 6% 的错误率,语音识别虽然只是聊天机器人的一个小模块,但是它特别重要。Alexa、Siri、Google assistant 之所以能够成功,大部分原因是有比较好的语音识别系统,当然,肯定还是因为大公司的参加。
大公司的参与有两个好处,第一个是使技术发展更快,亚马逊据说有五千多个人在 Alexa 部门工作,这么多人力物力的投入将大大加速技术的进步;另一方面是降低其他开发者的开发门槛,比如说现在很难的语音识别技术,自然语言处理技术在 Alexa 和 Google Assistant 上都可以免费的得到,这将大大降低开发的门槛。
下面来开始讲第一个比较著名的 Chatbot,叫做 Eliza。
Eliza 诞生于 1966 年,发明者是 MIT 一名叫 Joseph 的教授。Eliza 一开始的角色是一名心理学家,它所践行的疗法叫人本主义疗法,人本主义疗法特别有意思,他希望对求助者创造无条件的支持和鼓励,使的求助者能够发现自己的问题,所以他特别关注求助者的本身,机器人只是做一个陪伴,只要帮他理清思路而已。这样,Eliza 可以避免被问到关于自己的问题,它只是做一个基本的陪伴而已,任务比较简单。
有趣的是 Joseph 发明 Eliza 之后发觉它特别 powerful,很多人包括他的助手都愿意跟 Eliza 聊天,并且聊自己很私密的事情,最后还要求 Joseph 不能够看他们的聊天记录。Joseph 就觉得未来机器人的发展会很可怕,会涉及到拥有私人的秘密,可以做很多坏事,他花了很多时间来反对研究 Chatbot,反对自己的研究的成果。
我们来感受一下 Eliza 有多 powerful。

这里有两段对话,左边的是 Joseph 发表的一段对话, 这里我们可以看到,H 表示的是 human,就是来访者,B 代表的就是 Eliza。
我们可以看到,来访者开始先抱怨说男人都是一样的。Eliza 就说,怎么会一样呢?来访者说,他们都喜欢烦我。Eliza 说,能给个具体的例子吗?来访者说,我男朋友就逼我来这里。然后 Eliza 说,你男朋友逼你来这里吗?对话就这样继续下去。
到最后来访者说,你在某些方面挺像我父亲的,从这句话中可以看出,来访者已经把 Eliza 看成是一个真正的心理医生,这让 Joseph 觉得特别可怕。
右面是我实现的一个 Eliza 的一个中文版,如果你认真跟它对话,不调戏它,你才是可以看到,它有帮来访者理清思路的效果的。这里我先开始说,你好。然后它问我心情怎么样。我说心情不是很好啊。它就说,那是什么事情让你不开心?我说跟我妈吵架了。它说你跟你妈的关系如何?这句已经不是特别顺畅了。顺畅的话它应该是问一些吵架的事情。但是我们可以看到,就基本上语言的还是顺畅的,跟我们正常的人聊天还是有些相似之处的,我右边有放了一个二维码,如果大家感兴趣,可以去扫这个二维码,聊聊看。
Eliza 的工作原理很简单,通过简单的模式匹配,甚至没有任何的语义理解,它也只能够处理文本。

图中是 Eliza 的一段伪代码, 我们可以看到它是做一个简单的关键字匹配,这里它有大概两百多个模板,如果匹配到一个或者多个关键字,它就用关键字对应的模板去回复,如果匹配不到的话,它只是简单的把“我”改成“你”,然后返回原话,比如说我们前面看到的:来访者说“我父亲”,然后 Eliza 说“你父亲”;来访者说“我男朋友逼我来这里”,Eliza 说“你男朋友逼你来这里”。只是简单的重复他的对话。
但是就是这些很简单的规则,基本是现在很多很有名的聊天机器人的基石,比如说 ALICE、Mitsuku、机器人小冰等等,ALICE 和 Mitsuku 都是 Eliza 的一个直接的延伸,只不过在此基础上极大的扩展了模板,并且加了一些跳转,但仅仅是扩大了模板使 Chatbot 就变得特别强大。
ALICE 和 Mitsuku 都是三届 Loebner 铜奖的获得者。Loebner 奖是聊天机器人非常重要的奖项,它用来奖励每年最像人类的聊天机器人,2017 年的获奖者是 Mitsuku。和 ALICE 同时诞生的还有一个叫 AIML 的语言,通过这种 AIML 的语言,我们可以做到很快速的匹配。Mitsuku 就是建立在这种语言的基础上的。
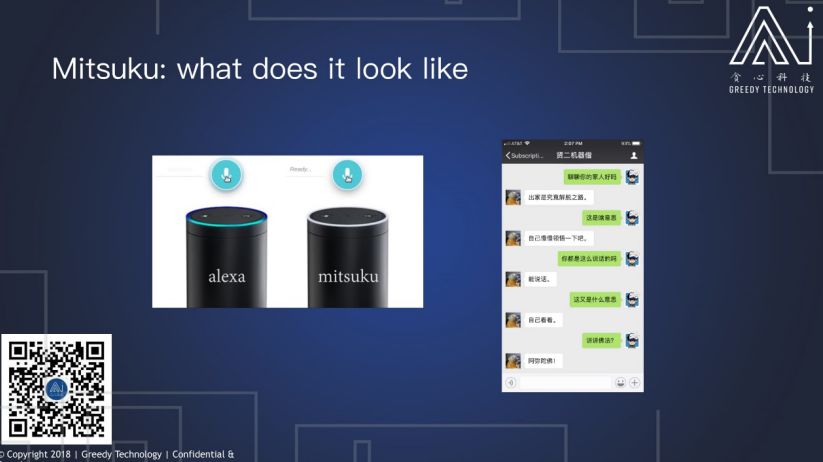
下面我们看一下 Mitsuku 的一些实例,这里有两个对话,左边是 Mitsuku 和 Alexa 的对比, 这个视频发表于 2016 年 10 月底。
我们可以看到在 2016 年 10 月底,这个视频发表的时候,Alexa 仍无法做多个回合的对话,这里当作者说到“it”的时候, Alexa 的回答是去定义那个“it”。而 Mitsuku 是知道这个“it”代表的是印度,所以我们可以看到在多个回合的对话和对话的流利有趣程度来讲 Mitsuku 是要优于 Alexa。这是因为 Mitsuku 的模板来源于网络,它跟微软小冰一样,通过收集网上大量的人的对话,只是返回一些人的言语而已,所以它的回答特别像人。但是 Mitsuku 除了聊天之外没有其他功能,而 Alexa 可以控制家电,可以帮你买东西,可以记录信息等等,就有用程度来讲,Alexa 要远超于 Mitsuk。
右边是我跟机器僧贤二的一段对话,大家可以看到这类 Chatbot 一个特点是它们的对话没有一个 Topic 的概念,就只能够“尬聊”,并不能维持一个 Topic 进行深入探讨,因为它并不知道你前面讲的是什么。
前例中,Mitsuku 虽然能够知道前文聊天的内容是什么,但是如果我们更做比较复杂的指代,它就很难做到。工作原理上来说跟 Eliza 差不多,只做简单的模式查找替换,并不能针对语境做理解,而且它也不能够做一些语音的理解。
这里的展示的是,下面展示的是 AMIL 语言的一个简单的例子,我们可以看到它有一个叫 Pattern 的标注,这个 Pattern 就是我们人类说的话,它是用来匹配用户的话语的;下面有一个 Template 标注,是用来放置回复的模板的;最下面还有一个 SRAI 的一个标注,这是用来做跳转的,比如这里当用户说到:“What are you called”的时候,它可以跳转到“What is your name”这样一个模板。
Mitsuku 这种模式之所以能够成功,一个原因是我们现在可以得到大量的用户的聊天数据。另一个原因是我们的语言会 follow 一个叫 Zipf`s Law 的分布。简单来说,我们如果把词语按词频来排序,那么这个词频大致会是 1/X 的一个分布,X 表示的是词的排序,也就说人类语言并没有我们想象的那么复杂。
有人对英语做过统计,每个句子的第一个词大概有两千种可能,但是如果我们把第一个词放好之后,第二个词就只有两种可能了。所以总的句子的数量并不是特别多,当然如果我们每个人说话都像莎士比亚一样,非常具有创造性的话,那么 Mitsuku 这种方式可能就不太成功了。
下面我们来讲一个比较复杂且非常有代表性的一个系统叫 IBM Waston。
Waston 是第一个在 Jeopardy!上战胜人类选手的 QA 系统,Jeopardy!是美国一个电视智力竞技节目,在 2011 年的一场比赛中 Watson 成功打败人类选手,赢得第一名,获得一百万奖金。那时候是非常轰动的一件事情,但是现在来看我们知道 Chatbot,包括 Siri,Alexa,因为借助网络知识的缘故,在知识问答方面更远超人类。在我看来,这个 Q&A 系统就是一个回合制的 Chatbot,类似于刚才展示的 Alexa,只是没有一个执行动作的功能。
从系统模块来说,因为要做到比较精确的回答,比如当不知道答案时候不能够插科打诨,Waston 需要的系统已经远比之前的 Eliza 或者 Mitsuku 要复杂。首先它需要做一些语法和语义上的分析,我们可以从这个图的左边看到,当 Waston 拿到一个问题的时候它会做很多的语义的分析,包括比如说问题的类型分析、代名词是指代哪些词语的分析,还有哪些代表的是人名,哪些代表的是地方名。有了这些语义分析之后,它再对这问题进行重新组织,之后分别到网上去搜索和自己的数据库中进行搜索。搜索大量文章之后再对这些文章进行排序,拿到排序的文章之后,通过一个系统,从文章里面搜出关健词,再把这些关健词组成答案,再对答案进行排序,最后再由一个系统把这些答案拼在一起,显示单个答案。
我们可以看到 Waston 就像一个搜索引擎,但它只能返回一个答案,这样的话,它的准确度要很高,并且因为他有自己的数据库,所以它是一个在某方面比较有用的搜索引擎。当然对比 Mitsuku 来说,Waston 虽然只能回答一些问题,但是商用来说它可能会更加有用,大部分原因就是因为它有特定的数据库。
我们再把 Waston 的架构映射到前面提到的现代聊天机器人架构上去,我们可以看出它拥有聊天机器人的基本模块,它也有语音识别系统,也有自然语言理解系统,也有对话管理系统,基本上就是去搜索知识,然后把这些知识拼接在一起,它也有自然语言生成和语音合成系统,只是缺了一个执行动作的模块而已。
讲完了以 Waston 为代表的问答系统,现在我们来讲讲以 Siri、Alexa 和 Google Assistant 为代表的任务驱动系统。
Siri 最早出来 2011 年,比 Alexa 和 Assistant 都要早的多。它原本是美国军方一个研究项目,后来因为技术比较成熟,成立公司,并且被苹果买走,并集成到苹果手机中,可以说是第一个非常成功的一个聊天机器人。
Alexa 和 Google Assistant 是不同于 Siri 之处是,它们是一个平台,开放了很多 API,使的很多开发者可以在上面开发各种功能,现在他们拥有的技能应该比 Siri 多的多。
前面我们说到在 2016 年底,Alexa 只能做一个回合的对话,我们这里可以看到 Siri 在 2014 年的时候也只能做一个回合的对话。

从上面图我们可以看到, 当用户在问完:“找附近的餐馆”之后,他接着问:“这些餐馆里面是否有意大利餐馆”,这时 Siri 就不知道“这些”指代的是那些返回的餐馆。同样的,当用户问:“给我多一些第二个餐馆的信息”的时候,Siri 也无法回答。
但是到了 2017 年,它已经可以做很多比较完整的多个回合的对话了。这当然是得益于对话管理系统的更新,在此之前 Siri 只能根据当前的对话去回答。现在 Siri 是可以集成一些历史的数据来回答问题。
我们可以看到这里展示的是 Siri 的基本模块,当然因为我们没有在 Apple 工作过,我也不知道它的具体的模块是怎样,但是它的模块大致应该是这样一个系统:它同样有一个自然语言的理解模块,有对话管理系统模型,还有个执行动作,可以去调用其他的 APP。当这些系统要处理多个回合的对话,并且完成任务的时候,大致都用在一个叫 Frame-based Dialog 的框架。
这个框架下,Chatbot 为了完成任务,需要填多个空。
比如说我们这里展示的是一个定机票的系统,它要知道出发的日期、时间、城市、到达的日期时间和城市,于是它就会一个一个问题的去问用户,并且从回答中抽取合适的答案来回答这些问题。这就要求对话系统去理解语义,知道这个词代表的是一个城市还是一个日期。这个框架现在应用的特别广泛,美国的很多机器客服都用到这个框架。
最后我们来简单聊一下小冰,小冰是一个跟 Siri、Alexa 和 Google Assistant 都非常不同的一个框架,它更像 Mitsuku 和 Eliza,它不是一个任务为主导的系统,而是一个纯粹的聊天系统。它通过收集大量的用户和聊天数据,并且从中学习一些模式,从而进行模式匹配。
当然据说微软是不存储用户数据的,所以我猜测它是一个基于模型的系统,很可能是一个神经网络系统。这样的系统有个不好之处就是它特别容易学坏,因为我们很难控制用户会说什么。
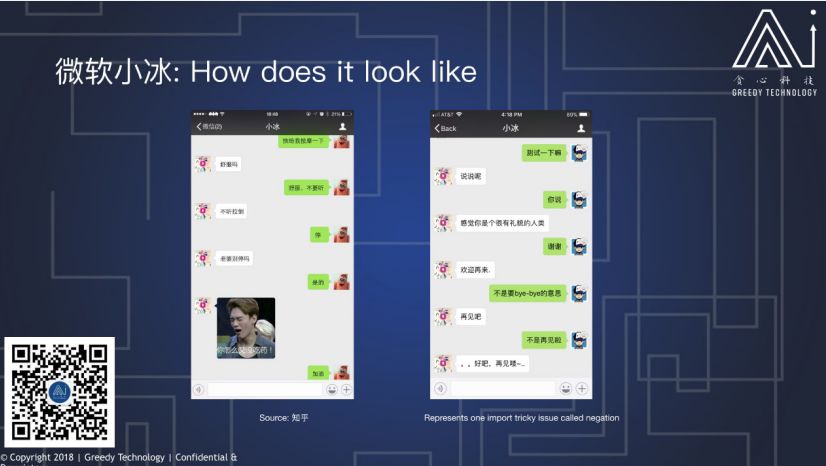
这里有两条小冰的聊天记录,第一个是左边是在知乎上的问答, 我们可以看到小冰已经学会说脏话了,当然我这里选的是最好的一张,知乎上还有比这难堪得多的聊天记录;第二个是我跟小冰的一段对话,当我跟小冰说“谢谢”的时候,它理解为“再见”的意思,而且我跟它解释说我其实不是说再见的时候,它是不能理解的。这体现的一个模板型聊天机器人的一个很难解决的问题:理解否定,就因为数据中说“再见”的内容比说“不是再见”的内容多很多,所以小冰只能理解肯定的再见,而不是否定的再见,你在“再见”的前面加上任何词,它都只能理解为再见。
这里还有另一个例子来说明,向用户学习的不好之处。
这也是微软的另一个系统,它的初衷是作为英文版的小冰,但因为向用户学习,所以只公开了不到 24 小时就不得不下架。这里我们看到,它一开始还能比较正常的说话,说人类挺好的,然后慢慢的就开始反人类了,最后就像纳粹分子一样。
讲完了一些著名的聊天机器人,下面我们来讲一些近期的发展。
总的来说,现在聊天机器人的研究方向是以端对端学习为主导的,什么是端对端呢?不同的系统有不同的解释,在这张图中,“端对端”表示的是我们用一个神经网络把自然语言理解、对话管理、自然语言生成一起学,这里有点像 Eliza 的模块,它是通过把文字放到一个神经网络中去学一些规则,而不是我们人为去定义一些规则。
下面一个是跟前面比较像,只是他把各个模块用不同的神经网络来学。
比如说它把自然语言生成当作一个模块,把自然语言理解当作一个模块,把对话系统当作一个模块,但这些模块都是一个神经网络系统。每个模块都是一个神经系统有一个好处:比如训练完了某个系统,我们可以把它连起来,然后再进行一个端对端的训练。
总结一下,这个讲座我们主要根据聊天机器人的功能和架构两条主线来讲一些历史和现代比较著名的一些机器人的功能和工作原理;了解了如何做一个非常简单的聊天机器人,比如说 Eliza;另外了解了比如说小冰和 Eliza 是在不同的体系下的聊天机器人。
如果大家想亲自尝试一下,我这里还列了一些我感觉非常有用的资源:比如说 NTLK,NTLK 里面有大量的自然语言处理工具,比如有我刚才提到的 Eliza 的代码;
第二个是 Stanford Parser,对自然语言处理非常有帮助,比如说它能帮助你理解哪些是城市、哪些是地名、哪些是人名,而且它还有中文版的,大家可以去尝试一下;
下面是一本叫《Speech and language Processing》的书,在这个 Talk 里面有很多内容都是引用这本书的,我感觉非常有用。
最后是一个 Github code,是基于 AIML 语言的聊天机器人的版本,基于这个 Code 大家应该可以做出一个类似小冰或者贤二机器僧的一个 Chatterbot。
Danny Lan(Neeke),现任 Google 科学家,曾任美国一家智能监控公司的 Director of R&D, 对视频和多媒体的智能分析有深入研究。作为主要成员,他曾代表卡耐基梅隆大学在美国国家标准总局(NIST)举办的视频智能分析大赛中连续多年进入前三。其他参赛团队来自著名公司 IBM, BBN 等,以及包括斯坦福在内的多所世界顶级高校或科研机构。他在多个 AI 会议和杂志发表论文 20 余篇,论文引用次数近千。
ML & AI


长按,识别二维码,加关注

















 745
745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









