







1.规范化
-
针对数据库
规范化把关系满足的规范要求分为几级,满足要求最低的是第一范式(1NF),范数的等级越高,满足的约束集条件越严格。 -
针对数据
数据的规范化包括归一化标准化正则化,是一个统称(也有人把标准化作为统称)。
2.标准化(Standardization)
数据的标准化是将数据按比例缩放,使之落入一个小的特定区间。
主要方法:z-score标准化方法

特点:
对不同特征维度的伸缩变换的目的是使其不同度量之间的特征具有可比性,同时不改变原始数据的分布。
优点:
1.不改变原始数据的分布,保持各个特征维度对目标函数的影响权重
2.对目标函数的影响体现在几何分布上
3.在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景

3.归一化(Normalization)
- 把数据变为(0,1)之间的小数,主要是为了方便数据处理。
- 把有量纲表达式变换为无量纲表达式,成为纯量。经过归一化处理的数据,处于同一数量级,可以消除指标之间的量纲和量纲单位的影响,提高不同数据指标之间的可比性。
主要算法:一般方法是最小最大规范的方法:min-max normalization

此方法是线性归一化
优点:
1.提高迭代求解的收敛速度
2.提高迭代求解的精度
缺点:
1.最大值与最小值非常容易受异常点影响
2.鲁棒性较差,只适合传统精确小数据场景

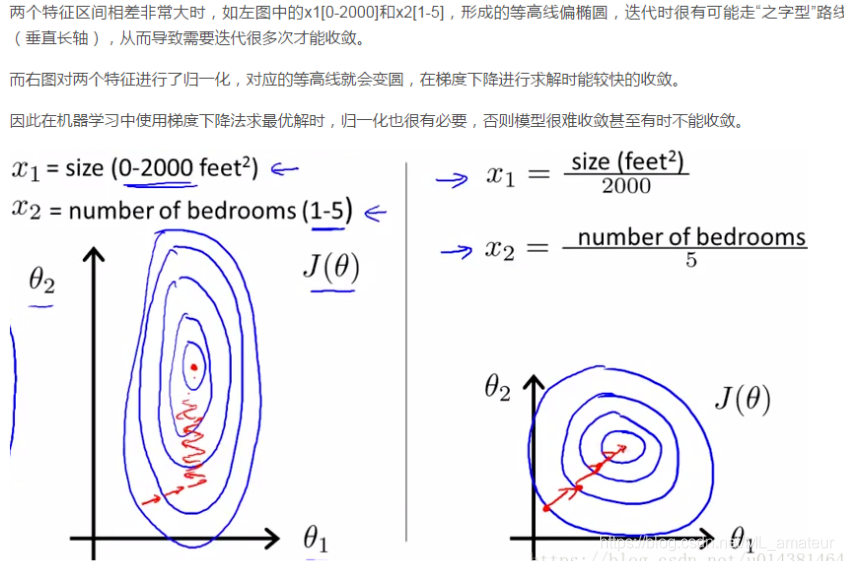
4.正则化(Regularization)
用一组与原不适定问题相“邻近”的适定问题的解,去逼近原问题的解,这种方法称为正则化方法。
在求解最优化问题中,调节拟合程度的参数一般称为正则项,越大表明欠拟合,越小表明过拟合。
为了解决过拟合问题,通常有两种方法,第一是减小样本的特征(即维度),第二是正则化(又称为惩罚penalty)
正则化的一般形式是在整个平均损失函数的最后增加一个正则项(L2范数正则化,也有其他形式的正则化,作用不同)
正则项越大表明惩罚力度越大,等于0表示不做惩罚。
正则项越小,惩罚力度越小,极端为正则项为0,则会造成过拟合问题;正则化越大,惩罚力度越大,则容易出现欠拟合问题。
总结
1.归一化是为了消除不同数据之间的量纲,方便数据比较和共同处理。比如在神经网络 中,归一化可以加快训练网络的收敛性。
2.标准化是为了方便数据的下一步处理,而进行的数据缩放等变换,并不是为了方便与其他数据一同处理或比较,比如数据经过零-均值标准化后,更利于使用标准正态分布的性质,进行处理。
3.正则化而是利用先验知识,在处理过程中引入正则化因子(regulator),增加引导约束的作用,比如在逻辑回归中使用正则化,可有效降低过拟合的现象。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









