







vector说明
template < class T, class Alloc = allocator<T> > class vector; // generic template
vector是表示可以改变大小的数组的序列容器。
就像数组一样,vector对它们的元素使用连续的存储位置,这意味着它们的元素也可以使用指向其元素的常规指针上的偏移量来访问,并且效率与数组相同。 但是与数组不同,它们的大小可以动态更改,其存储由容器自动处理。
vector在内部使用动态分配的数组存储其元素。 插入新元素时,可能需要重新分配该数组以增大大小,这意味着分配新数组并将所有元素移至该数组。 就处理时间而言,这是一项相对昂贵的任务,因此,每次将元素添加到容器时,vector都不会重新分配。
取而代之的是,相反,向量容器可以分配一些额外的存储器以适应可能的增长,因此容器可以具有比严格需要的存储器更大的实际容量来包含其元素(即,其大小)。 库可以实现不同的增长策略,以在内存使用和重新分配之间取得平衡,但是在任何情况下,重新分配应该只以大小的对数增长间隔发生,以便在向量末尾插入单个元素时可以提供分摊的恒定时间复杂度。
因此,与arrays相比,vector消耗更多内存以换取管理存储和以有效方式动态增长的能力。
与其他动态序列容器(deques, lists and forward_lists)相比, vector能非常有效地访问其元素(就像数组一样),并且相对有效地从其末端添加或删除元素。对于涉及在末端以外的位置插入或删除元素的操作,它们的性能比其他操作差,并且迭代器和引用的一致性比列表和转发列表差。
vector结构简述
vector是 典型的 实现。 vector本身只是一个数据结构,它具有一个指针,该指针指向存储在“对象”中的实际数据。
vector 遵循以下原则:
template <typename Val> class vector
{
public:
void push_back (const Val& val);
private:
Val* mData;
}
上面显然是伪代码,但是您知道了。 当一个 vector 在堆栈(或堆)上分配:
vector<int> v;
v.push_back (42);
内存可能最终看起来像这样:
+=======+
| v |
+=======+ +=======+
| mData | ---> | 42 |
+=======+ +=======+
当你 push_back 到一个完整的vector,数据将被重新分配:
+=======+
| v |
+=======+ +=======+
| mData | ---> | 42 |
+=======+ +-------+
| 43 |
+-------+
| 44 |
+-------+
| 45 |
+=======+
并且指向新数据的vector的指针现在将指向此处。
vector布局介绍
注意: std::allocator 实际上很可能是一个空的Class, std::vector可能不包含此类的实例。 对于任意分配器,可能不是这样。
std :: vector布局
在大多数实现中,它由三个指针组成,其中
begin指向堆上vector的数据存储器的开头(如果没有,则始终在堆上)nullptr)end指向vector数据的最后一个元素之后的一个存储位置->size() == end-begincapacity指向vector存储器中最后一个元素之后的存储器位置上的点->capacity() == capacity-begin
栈上的Vector
我们声明一个类型的变量 std::vector<T,A> , T 是任何类型, A 是分配器类型 T (i.e. std::allocator<T>)。
std::vector<T, A> vect1;
堆上什么都没有发生,但是变量占用了堆栈上所有成员所需的内存。 在那里,它将一直呆在那里,直到 vect1 超出范围,因为 vect1 就像任何其他类型的对象一样 double, int管他呢。 它会坐在其堆栈位置,等待销毁,无论它在堆上处理了多少内存。
vect1 指针不要指向任何地方,因为vector是空的。
堆上的vector
现在我们需要一个指向vector的指针,并使用一些动态堆分配来创建vector。
std::vector<T, A> * vp = new std::vector<T, A>;
我们的vp变量位于堆栈上,vector位于堆上。 同样,vector本身不会在堆上移动,因为其大小是恒定的。 仅指针( begin, end, capacity)如果发生重新分配,将跟随内存中的数据位置移动。
vector 添加元素
T a;
vect1.push_back(a);
单个push_back之后的std :: vector
变量 vect1 仍然在原处,但堆上的内存已分配为包含一个元素 T.
如果再添加一个元素会怎样?
vect1.push_back(a);
第二次pushback后std :: vector
- 在堆上为数据元素分配的空间将不够用(因为到目前为止,它仅是一个内存位置)。
- 一个新的内存块将分配给两个元素
- 第一个元素将被复制/移动到新的存储中。
- 旧的内存将被释放。
我们看到:新的内存位置是不同的。
为了获得更多的见解,让我们看一下销毁最后一个元素时的情况。
vect1.pop_back();
分配的内存不会改变,但是最后一个元素将调用其析构函数,并且结束指针向下移动一个位置。
2次pushback和1次popback后的std :: vector
如你看到的: capacity() == capacity-begin == 2 尽管 size() == end-begin == 1
测试增长
这里借用侯捷同志的一张图
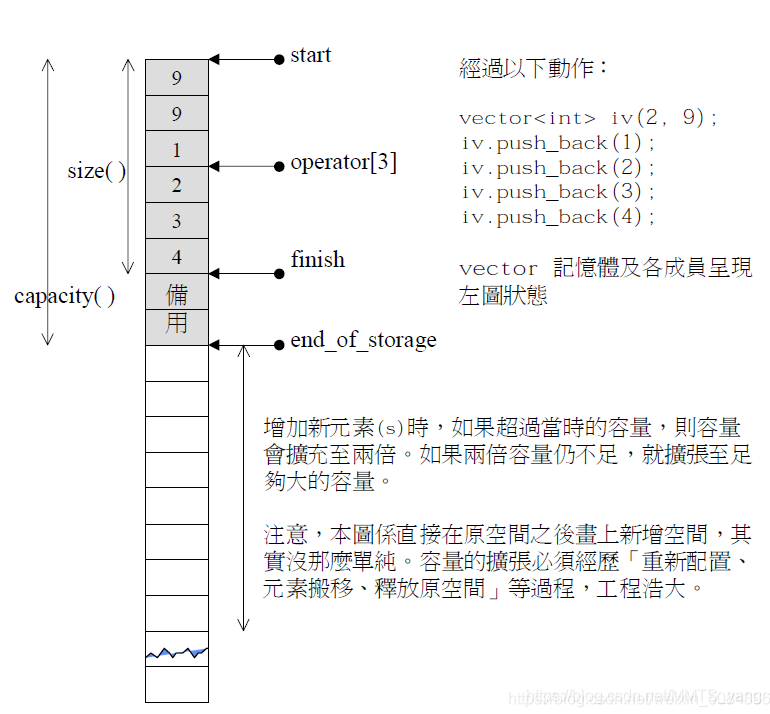
std::vector<int> my_vec;
auto it=my_vec.begin();
for (int i=0;i<10000;++i) {
auto cap=my_vec.capacity();
my_vec.push_back(i);
if(it!=my_vec.begin()) {
std::cout<<"it!=my_vec.begin() :";
it=my_vec.begin();
}
if(cap!=my_vec.capacity())std::cout<<my_vec.capacity()<<'\n';
}
it!=my_vec.begin() :1
it!=my_vec.begin() :2
it!=my_vec.begin() :4
it!=my_vec.begin() :8
it!=my_vec.begin() :16
it!=my_vec.begin() :32
it!=my_vec.begin() :64
it!=my_vec.begin() :128
it!=my_vec.begin() :256
it!=my_vec.begin() :512
it!=my_vec.begin() :1024
it!=my_vec.begin() :2048
it!=my_vec.begin() :4096
it!=my_vec.begin() :8192
it!=my_vec.begin() :16384
常见错误
vector<int>v(4);
std::cout << v[0] << std::endl;
std::cout << v[1] << std::endl;
std::cout << v[2] << std::endl;
std::cout << v[3] << std::endl;
///>-1 越界访问
/** --1.1 std::vector::operator[] 并不执行边界检查,
* 属于典型的未定义行为(Undefined Behavior),
* 这种情况下异常机制(try/thorw/catch)并不起作用。
*/
std::cout << v[4] << std::endl;//越界
/** --1.2 std::vector::at,
* 它会执行边界检查,如果越界,会抛出 std::out_of_range 异常。
*/
try {
std::cout << v.at(4) << std::endl;
} catch (out_of_range e) {
std::cout << e.what() << std::endl;
}
///> -2 重新分配内存
try {
std::vector<int> v1;
v.resize(v1.max_size() + 5);
} catch (length_error e) {
std::cout << e.what() << std::endl;
}
注: 在实际的操作中可以在安全性(使用at()监测异常)和执行速度(使用数组表示)之间进行选择 --引自《C++ primer plus 6》。
















 8573
8573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











