






论文:https://arxiv.org/abs/2203.15326
代码:https://github.com/vincent-zhq/ca-mser
Title: SPEECH EMOTION RECOGNITION WITH CO-ATTENTION BASED MULTI-LEVEL ACOUSTIC INFORMATION
题目:基于共注意的多层次声学信息语音情感识别
语音情感识别(SER)旨在帮助机器仅从音频信息中理解人的主观情感。然而,提取和利用全面深入的音频信息仍然是一项具有挑战性的任务。在本文中,提出了一个端到端语音情感识别系统,利用多级声学信息和新设计的共注意模块。首先利用CNN、BiLSTM和wav2vec2分别提取多层声学信息,包括MFCC、谱图和嵌入的高级声学信息。然后将这些提取的特征作为多模态输入,并通过所提出的共同注意机制进行融合。实验在IEMOCAP数据集上进行,我们的模型通过两种不同的与说话人无关的交叉验证策略实现了具有竞争力的性能。
情感的自动识别在人机交互和监控等方面有广泛的应用。一些研究者提出将声音信息与文本信息相结合,学习高水平的语境信息来帮助做出最终的情绪预测。然而,对于大多数情感识别应用程序来说,相应的转录并不总是可用的。此外,现有的自动语音识别系统生成的文本也会引入单词识别错误,干扰情绪识别任务。由于单一的音频数据更容易获得,因此仅从音频信号中进行情感感知要比使用额外的文本和视觉信号进行多模态情感识别容易得多。将多种声音信息整合起来,将语音情感识别问题转化为多层次融合问题,是一种利用完整音频信息的有效方法。
在本文中,我们介绍了三种不同的编码器用于多级声学信息:用于谱图的CNN,用于MFCC的BiLSTM和用于原始音频信号的基于变压器的声波提取网络wav2vec2。利用所设计的共注意模块,利用MFCC和谱图特征提取的有效信息对每帧进行加权后优化得到最终的wav2vec2嵌入(W2E)。我们将这三个提取的特征串联起来,用最终融合的信息进行最终的情感预测。提出的模型在广泛使用的IEMOCAP数据集上超越了目前的竞争模型,它采用了“保留一个说话者”和“保留一个会话”的交叉验证策略。

在将原始音频话语分割成多个片段后,将一个片段的三个层次的声学信息(MFCC、谱图和W2E)引入到各自的特征编码器网络中,并与所提出的共注意方法进行融合,最终实现情感识别。
本文将多层次声学信息定义为基于人类知识的低层MFCC、基于深度学习的高层谱图和W2E的结合,从而涵盖语音信号在频率和时域的特征。MFCC序列采用双向LSTM处理,dropout为0.5且平坦。先对预训练的AlexNet的谱图图像进行重塑。对AlexNet提取的特征进行类似于MFCC特征的操作。原始音频片段直接发送到相应的wav2vec2处理器和wav2vec2模型,以获得目标的原始wav2vec2输出
考虑到三种声音信息源在最终情绪预测中的作用相似,我们利用它们之间的相关性来指导特征的适应。通常,最后一帧或wav2vec2输出的平均值被用来表示wav2vec2特征。很明显,在序列维数中我们丢失了一些有效的信息。
数据集:IEMOCAP是一个广泛使用的情感识别数据集,从十个不同的演员记录的音频、视频、转录和动作捕捉信息。根据其他人的研究[12,7,5],我们将“高兴”和“兴奋”合并到“高兴”的范畴中,并考虑了来自4种情绪的5531个声音话语,即愤怒、悲伤、高兴和中性。为了更准确地评估模型的性能,我们使用5次保留一个会话和10次保留一个说话人的交叉验证策略来测试我们的模型,以生成与说话人无关的结果。同时,我们使用常用的加权精度(W A)和非加权精度(UA)作为评价指标。
使用的原始音频信号采样在16khz。我们将每段音频分成3秒的几个片段。当一个段小于3秒时,将对这个段应用0填充操作以保持相同的长度。一个音频话语的最终预测结果将由该话语的所有分割片段决定。
为了充分利用不同层次的语音信息,我们在这个SER任务中使用了三种声学信息:MFCC、谱图和W2E。MFCC是一种考虑到人类听觉特征的40维htk风格的Mel频率特征。它是用librosa库[20]从原始音频片段中提取出来的。谱图和W2E是音频信号的深层特征。对于光谱图,应用了一系列40毫秒的汉明窗,跳长为10毫秒,这里我们将每个加窗块视为一个帧。每一帧被转换成一个频率域,其长度为800的离散傅里叶变换(DFT)。前200个DFT点被用作输入谱图特征。我们最终得到了每个音频片段大小为300*200的谱图图像。和多模态情感识别方法[21]一样,W2E是通过预训练的基于变压器的wav2vec2网络获得的。它是语言的深层特征在时域的反映。

对于leave-one-session-out验证策略,我们提出的方法在UA和W A方面的最佳性能分别为69.80%和71.05%。对于“留一个说话人”验证策略,该方法的UA值最高,为72.70%。同时,在这个不平衡的IEMOCAP数据集上,它在W A中的性能也具有竞争力,与UA的结果非常相似,为71.64%。

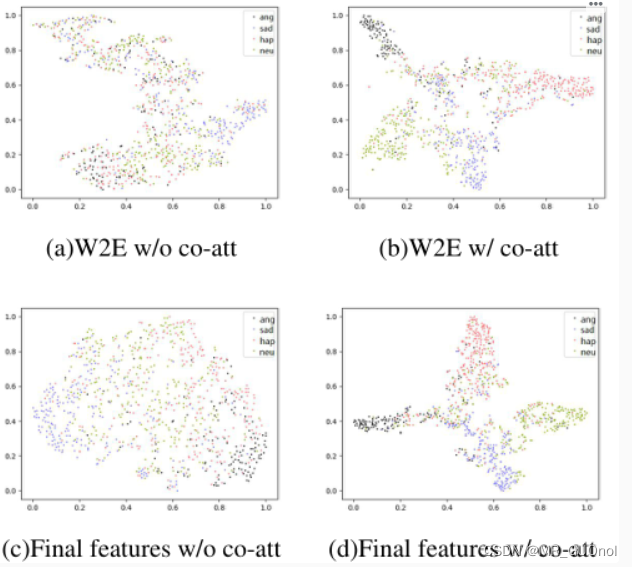
该方法利用了时域和频域的多层次声学信息。表2为不同声信息组合下模型性能的烧蚀研究。前三行是只有一个声学信息层次的情感识别结果:MFCC、谱图和W2E。在最终的情感识别中,W2E比其他方法具有更好的性能。接下来的三行总结了不同特性与W2E结合的结果。后四行展示了不同组合特征与加权W2E信息共同关注后的结果。多种声学信息的结合和提出的共同注意模块对整个模型的性能有很大的提高。消融研究也显示了所提出的共同注意机制的有效性。从表2的最后两行可以看出,联合注意机制进一步优化了融合数据,其性能优于直接拼接操作,分别提高了4.42%和4.89%的W A和UA。如图2所示,经过共同注意的加权W2E和最终合并特征的t-SNE可视化结果,与未进行共同注意的未加权W2E和最终合并特征的结果相比,分类边界更加清晰。从图3中我们还可以观察到,由最终归一化混淆矩阵得到的具有共注意的模型最终分类结果要比没有共注意的模型好得多。
本文提出了一种利用多层次声学信息的基于协同注意的SER系统。通过设计不同的编码器,该模型可以从原始音频信号中获得特定特征的信息,并为SER问题提供互补的声学信息。此外,该方法还引入了一种基于共注意的融合方法来获得加权的wav2vec2嵌入并结合最终的特征。在IEMOCAP数据集上的实验表明,我们提出的方法在不同的与说话人无关的交叉验证方法下获得了具有竞争力的性能。在未来,我们希望结合来自不同语言或数据集的知识来提高最终的性能。














 1313
1313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









