






多任务学习模式下的语音情绪识别的研究(2021)
摘要
语音情感识别(SER)将语音分为快乐、愤怒、悲伤和中性等情感类别。近年来,深度学习已被应用于SER任务。
本文提出了一种多任务学习(MTL)框架,利用基于wav2vec-2.0的端到端深度神经模型,同时执行语音到文本识别和情感分类。
在IEMOCAP基准上的实验表明,该方法在SER任务上达到了最先进的性能。
此外,消融研究证明了所提出的MTL框架的有效性。
研究的内容
快乐、愤怒、悲伤和中性等情绪在人类交流过程中发挥着重要作用。情绪被描述为一种“隐式通道”。如果对话参与者能够识别彼此的情绪状态,他们可以更有效地沟通。虽然人类感知他人情绪可能并不困难,但对计算机来说,这仍然是一项具有挑战性的任务。几十年来,人们在人机交互领域对情感识别进行了大量的研究。
在本文中,我们重点研究了语音情感识别(SER)任务,该任务以音频语音为输入,并输出情感类,例如:快乐、愤怒、悲伤、中性。
SER系统通常由几个主要的级联组件组成:特征提取、特征选择和分类[4]。
许多系统利用频谱特征,以及韵律特征、音质特征和基于teager能量算子的特征的显式表示[5]。这些方法需要强大的领域知识和对语音的深刻理解。
近年来,端到端系统的性能往往优于那些基于精心设计的传统系统。特别是,端到端深度神经模型通过卷积层等可训练的块来学习隐式提取特征。
由于更大的模型容量(显著更多的参数)和高效学习算法的发展,深度神经模型已成为SER任务的主导和首选系统[6]。
提出的方法&模型架构
模型架构
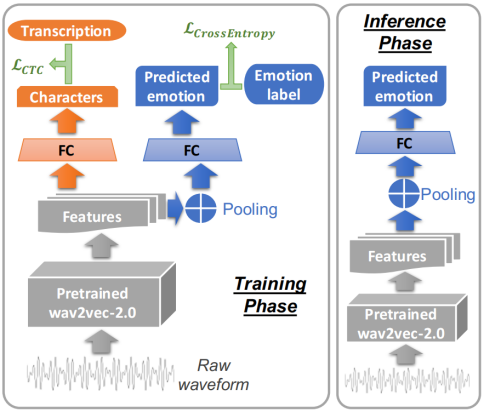
图1:拟议的训练模型采用单个输入(原始波形),并产生两个输出(预测的角色和预测的情绪)。有两种损失:LCE和LCTC,用于测量预测和黄金标签之间的损失。推理阶段丢弃图中的橙色路径。
我们提出了一种端到端模型,将语音作为原始波形输入,并输出预测的情绪。
图1显示了训练和推理过程。图中有三种颜色。灰色表示共享主干预训练wav2vec-2.0模型(底部)。橙色(训练图中的左上部分)和蓝色(训练中的右上部分,推理中的上部分)用于分离这两个任务。蓝色任务是SER:SER输入语音并输出情感标签。橙色任务是ASR:ASR输入语音并输出文本。
蓝色任务是本文感兴趣的主要任务。橙色任务在训练中起辅助作用,但在推理时不使用。第4.5节中的消融研究将表明,橙色和蓝色任务的组合提高了蓝色任务的性能,即使橙色部分没有用于推理。
我们将预训练的wav2vec-2.0模型表示为f θ(·)。它是底部的灰色盒子。输入波形为x∈ RL,其长度为L(共L个样本),我们得到wav2vec-2.0的最后一个隐藏层的输出作为特征z(标记为特征的灰色分量),即z∈ RL×d=f θ(x),其中d是隐藏维度,通常为768,θ表示f中的参数。橙色和蓝色部分均以z作为输入。
对于橙色(ASR)路径,我们使用由V=32个字符组成的词汇表,其中有26个英文字母加上几个标点符号。如图1所示,在获得特征z后,我们应用一个完全连接的层(左侧的橙色FC块),表示为gφ ,其中gφ 将z∈ RL×d映射到logits y∈ RL×V。在橙色路径的末尾,我们根据logit获得了对字符的预测:y=gφ(f θ(x))。
图1中的蓝色路径从池化层开始,池化层在样本长度L上进行求和。这将转换一个向量的序列(长度L),表示为z∈ RL×d,转化为单个向量zˆ∈ Rd。假设我们有C个情感类别。我们应用另一个全连接层hφ(蓝色FC块),将zˆ映射到logits c∈ RC。在蓝色路径的末尾,我们根据Logit获得了情感类的预测:![]() 。注意,φ表示与两个完全连接的层g和h相关的参数。
。注意,φ表示与两个完全连接的层g和h相关的参数。
训练和推理
对训练阶段进行监督。也就是说,训练过程可以获得橙色和蓝色路径的金色标签。
对于训练集中的每个语音,橙色路径可以访问金色文本(transcription),t,蓝色路径可以访问地面真实情感标签,l。
在两条路径的末尾,我们在y和c上应用softmax算子,将其转换为概率向量(概率向量v∈ Pd s.t. ![]() 1和vi ≥ 0)。
1和vi ≥ 0)。
对于字符编码(橙色任务),我们计算了连接主义时间分类(CTC)的[22]损失与给定的金转录(transcription)的编码。CTC将输入信号映射到输出目标,当它们没有相同的长度并且没有提供对齐信息时侯。这里,语音信号长度L 通常明显长于文本转录本长度,因为多个帧对应于单个音素。CTC可以用作损失函数,我们可以有效地反向传播梯度。详情见[22]。
因此,我们的CTC损失为:LCTC=CTC(yˆ,t),其中yˆ=softmax(y)∈ PL×V(1)
同时,我们计算了预测概率分布和真实情感标签之间的交叉熵。交叉熵损失广泛用于分类任务。
交叉熵损失:LCE=CrossEntropy(cˆ,l),其中cˆ=softmax(c)∈ PC(2)
我们引入了一个超参数α,将两个损失合并为一个损失。α控制CTC损失的相对重要性。通过网格搜索可以找到α的最佳选择。最后,我们优化了以下目标w.r.tθ和φ:![]()
在推理时,我们用argmax算子替换softmax,并选择最可能的情感类标签作为输出。为了获得对转录的预测,我们需要进一步添加一个CTC解码器,将y转换为最可能的文本tˆ。
注意,gold转录,t,仅用于在训练期间微调网络。在推理时不需要t。换句话说,我们的模型预测P[情绪|波形](P[emotion | waveform]),而不是P[情绪|(波形,转录)](P[emotion | (waveform, transcription)])。
此外,该方法不需要显式的语言模型。这是我们的模型与其他多模式模型(例如[34])之间的关键区别,这些模型在推理时使用gold转录或其他来源。因此,我们的方法在推理过程中是单峰的。
文章贡献
本文的主要贡献是:
•我们构建了一个端到端模型,该模型在标准IEMOCAP[7]数据集上实现了最先进的SER结果。
•我们利用预训练的wav2vec-2.0进行语音特征提取,并通过两个任务(即:SER(情感分类)和ASR(语音识别))对SER数据进行微调。
•消融研究验证了MTL方法的有效性,并讨论了ASR如何影响SER。
•语音转录可以作为副产品获得。
补充内容
Speech Emotion Recognition
语音情感识别从说话人的语音信号中检测说话人的情感状态。它通常被视为一项分类任务。
关于SER有大量文献。这项工作大多使用了预处理、特征提取和分类等步骤[5、8]。
在早期工作[4]中,通常提取基音、能量、共振峰、mel频带能量和mel频率倒谱系数(MFCC)等特征作为基本特征,以及语音级别的特征,如语速。下一步是将这些特征作为输入输入到机器学习分类器中,例如支持向量机、LDA、QDA和HMM。支持向量机和隐马尔可夫模型在分类精度方面表现相对较好。
由于深度学习的进步,基于神经的模型主导了SER研究的最新趋势。
在[12]中,作者对CNN和LSTM架构进行了评估,发现3个卷积层加上一个双LSTM层的级联可以产生最佳结果。
在[13]中,采用了更大的主干卷积网络ResNet-101,以提供更强的特征提取。
最近,注意力机制开始在自然语言处理领域发挥重要作用,并扩展到语音和视觉领域。
在[14]中,作者提出了一个由注意力滑动递归神经网络(ASRNN)组成的模型。
在[15]中,作者结合编码语言和声学特征,建立了一个多头自注意力模型,以研究这两种特征对SER任务的影响。
在[16]中,作者利用基于深度注意力的语言模型,将停顿作为检测情绪的关键特征。
在[17]中,从几个方面评估和比较了两个模型,CNN加注意和biLSTM加注意。
[6]对近年来SER的深度神经模型进行了全面综述。
Multi-task Learning
多任务学习使用共享主干模型同时优化不同任务中的多个目标。优势来自于辅助信息和不同任务的交叉正则化(隐含地,任务A可以是任务B目标的正则化器)。同时,联合优化带来了挑战[18]。
MTL广泛应用于各个领域的不同深度神经模型中。例如,在计算机视觉领域,最近的一项工作[19]提出了一种同时在12个不同数据集上运行的MTL模型,并在其中11个数据集上获得了最先进的结果。在语音识别中,[20,21]将连接时序分类(CTC)[22]映射层放置在基于注意力的解码器旁边,在共享注意力编码器的顶部,以执行端到端语音识别(ASR任务)。文本到语音(TTS)模型FastSpeech-2[23]明确并联合学习mel谱图和韵律:基音、持续时间和能量。众所周知的深度语言模型BERT[24]在预训练阶段采用了两个任务:掩码标记预测和下一句预测。对于SER任务,[25]同时根据性别和情绪对输入话语进行分类;这种方法被证明优于仅预测情绪的模型。
此外,MTL通常与转移学习[26]和连续学习[27]等其他技术密切相关。例如,深度语言模型ERNIE-2.0[28]将连续学习与MTL框架相结合,并在粘合任务上实现最先进的结果。
Wav2Vec-2.0: Pretraining with Fine-Tuning for Speech
预训练和微调的组合已证明是一种非常有效的学习方案。预训练阶段通常以无监督的方式训练诸如BERT之类的模型。在此阶段,需要一个大型数据集,例如Wikipedia和BookCorpus,以让模型学习文本的有意义表示。一旦完成预训练,可以使用相对较少的带标签的监督训练数据(例如[29,30])为特定的下游任务微调模型。由于在训练前阶段获得的知识,这种组合可能优于仅针对任务特定数据训练的模型。另一个优点是,该模型往往不会过度拟合特定于任务的数据,因为预训练阶段的行为类似于带来大量先验信息的正则化器。由于这些优点,这种结合预训练和微调的方法正在从自然语言处理领域[24,28]转移到语音领域[31]。
最近的一种预训练模型wav2vec-2.0[32]通过对大量音频数据进行预训练来学习语音表示,使用类似于BERT采用的无监督方法。它试图恢复编码音频特征的随机屏蔽部分。经过预训练后,wav2vec2.0在Librispeech[33]上进行了微调,在文字错误率(WER)方面具有令人印象深刻的性能。
在本文中,我们也从预训练的wav2vec-2.0模型开始,但使用两个不同的任务特定头对其进行微调,以用于不同的下游任务,即语音情感识别(SER)。
实验
数据集
根据大量关于SER的文献,如表2中的参考文献,我们使用IEMOCAP[7]。该数据集包含10位演讲者大约12小时的演讲。每一个话语都带有一种情感。表2中的文献选取了5531个话语,这些话语分为五类:快乐、愤怒、中性、悲伤和高兴。通过将“高兴”和“快乐”合并为一个类别,该集合被映射为四个类别。我们按照[35]进行了10次交叉验证。对于每一次迭代,我们都保留一个演讲者作为测试集,并使用其余九个演讲者进行训练。最终加权准确度(WA)计算为
其中![]() 是测试集上第k次迭代的正确情绪预测数量。许多文献还报告了未加权精度(UA),即不同类别的平均精度。然而,对于表3中的基线,我们列出了UA和WA之间的较高者。
是测试集上第k次迭代的正确情绪预测数量。许多文献还报告了未加权精度(UA),即不同类别的平均精度。然而,对于表3中的基线,我们列出了UA和WA之间的较高者。
实验内容

Table 1:用于微调的超参数.

Table 2: 来自文献中的基线方法
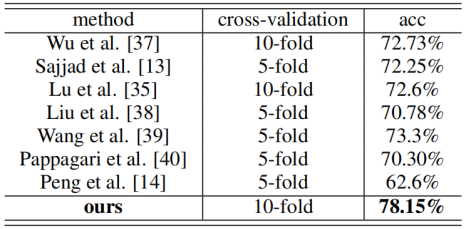
Table 3: 语音情绪识别(SER)结果
消融实验

Table 4: CTC损失的影响。α=0对应单任务(仅情绪分类),导致acc差。acc和wer都随着α的增大而提高
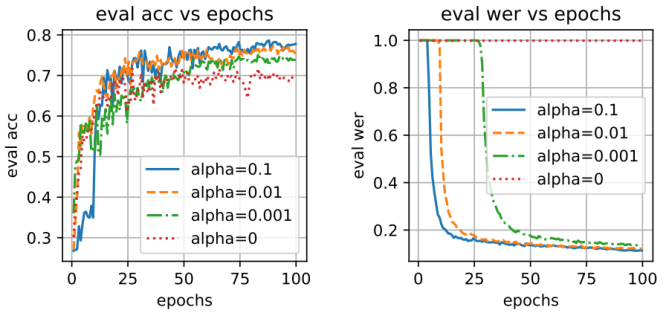
Figure 2: acc和wer对抗训练epochs,针对不同的α。注意,当α=0.1(最强CTC损失)时,acc的收敛速度比其他的慢(左图中的蓝色曲线)。然而,在wer收敛后(大约在第12阶段),acc快速上升,并最终优于其他阶段。
结果
本文提出了一种简单的端到端语音情感识别模型。该模型利用预训练语音模型wav2vec-2.0作为特征提取主干。我们在主干的顶部添加了一个CTC头部和一个分类头部,以同时获得对转录和情感类别的预测。
使用IEMOCAP基准数据集进行了综合实验。该模型极大地改善了最先进的结果(约提高5%)。消融研究证实了所提出的多任务学习(MTL)方法的有效性。它显示了在ASR和SER任务的组合上进行的训练,比在单个任务上的训练表现更好。

















 2479
2479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









