







实验背景:
这是从2010/01/12-2011/12/09一家在英国的网络电商的真实数据,所以数据类型和值都具有很强的随机性,实践性较强。
该电商的主营业务是卖一些订制礼物。所以本次分析的目的是对该电商的客户进行分类,以让业务部门可以对不同的顾客有不一样的促销方式(marketing initiatives or offer),以增大销量。
实验内容:
数据预处理:
1.导入观察数据:
#import all necessary package
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
数据源:https://www.kaggle.com/carrie1/ecommerce-data
#load data
df=pd.read_csv(r'E:\test\ecommerce-data\data.csv',encoding='ISO-8859-1')
df.head()

观察数据一共有8列,根据已经显示的前5列,发现数据特点是同一个顾客ID可能在同一个INVOCE中购买了多项商品,并且逐行显示。
2.清理数据:
#观察数据
df.info()

重点关注InvoiceDate 是object格式,为了之后方便计算,我们最好将其变换为Datetime的格式。
#利用Datetime函数,加入指定格式,识别参数
df['InvoiceDate']=pd.to_datetime(df.InvoiceDate,format='%m/%d/%Y %H:%M')
3.检查空值
df.isnull().sum()
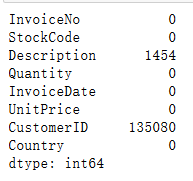
可以看到CID有相当多的空值,由于刚刚没有显示空值行的属性,现在单独将其列出进行分析:
Nan_rows=df[df.isnull().T.any()]
Nan_rows.tail(5)

因为我们无法通过别的列进行推断或者根据已有数据进行插值法补全CID,所以将其归类为脏数据删除
df=df.dropna(subset=['CustomerID'])
df.isnull().sum()
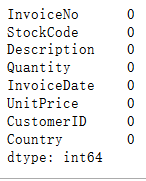
当我们删除CID之后,Description也为0。说明之前的那些CID为NaN的行里有一部分的Description也为NaN
4.重复值检查
df.duplicated().sum()
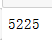
重复值只有5000多行,影响不大,我们选择删除
df.drop_duplicates(inplace=True)
在数据已经被清理干净之后,我们可以对其特征进行观察
数据分析与观察
1:找出Country一共有几种:
df.Country.unique()

顾客来自很多国家,那具体的下单数量和国家有很大的关联吗?我们可以将每个国家的下单数量进行排序并且可视化进行分析:
#先要将重复的CID去除,保证一个顾客只被计算了一次
order_unique_cus=df.drop_duplicates(['CustomerID'], keep='first', inplace=False)
order_sum=order_unique_cus.groupby(by='Country').UnitPrice.count()
order_sum=order_sum.sort_values(ascending=False).head(5)
plt.figure(figsize=(20,5))
sns.barplot(order_sum.index,order_sum.values,palette="Greens_r")
plt.ylabel('Counts' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1064
1064











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









