






数据集地址:数据集地址
我的NoteBook地址:NoteBook地址
这个此在线零售数据集包含2009年12月1日至2011年12月9日期间的在线零售的所有交易。该公司主要销售独特的各种场合礼品。这家公司的许多客户都是批发商。本文将通过pyspark对数据进行导入与预处理,进行可视化分析并使用RFM、生存分析与BG-NBD模型进行对购买客户的各项分析。
1、数据集导入与清洗预处理
这一部分我们将数据集使用PySpark导入、转换为我们要的数据类型,并过滤掉非正常商品、负单子、处理缺失值。代码贴在这里单纯是为了更加熟悉pyspark的各个算子。
from pyspark import SparkContext
from pyspark.sql import functions as F, SparkSession, Column,types
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings("ignore")
spark = SparkSession.builder.appName("CRMAnalysis").getOrCreate()
data = spark.read.csv("/kaggle/input/online-retail-ii-uci/online_retail_II.csv",header=True,sep=",")
## 数据类型 Convert Data
data = data.withColumn("Quantity",data["Quantity"].cast("int"))
data = data.withColumn("Customer ID",data["Customer ID"].cast("int"))
data = data.withColumn("InvoiceDate",F.to_date(data["InvoiceDate"],"yyyy-MM-dd HH:mm:ss"))
data = data.withColumn("Price",data["Price"].cast("decimal"))
## 数据类型 Convert Data
data = data.withColumn("Quantity",data["Quantity"].cast("int"))
data = data.withColumn("Customer ID",data["Customer ID"].cast("int"))
data = data.withColumn("InvoiceDate",F.to_date(data["InvoiceDate"],"yyyy-MM-dd HH:mm:ss"))
data = data.withColumn("Price",data["Price"].cast("decimal"))
## 缺失值 Deal Missing Values
data_null_agg = data.agg(*[F.count(F.when(F.isnull(c),c)).alias(c) for c in data.columns])
data_null_agg.show()
data = data.fillna({"Customer ID":99999})
## <0的条目数 C打头的Invoice删去 Quantity与Price为负数的删去 Filter out Invoices that begin with "C"(cancel) and Quantity/Price < 0
data_filtered = data.where(F.udf(lambda x:x[0].upper()!="C",types.BooleanType())(F.col("Invoice")))
data_filtered = data_filtered.filter("Quantity>0 and Price>0")
## 增加Total Price
data_filtered = data_filtered.withColumn("Total Price",F.col("Quantity")*F.col("Price"))
## 时间变量 Convert Date columns
data_filtered = data_filtered.withColumn("Year",F.year(data_filtered["InvoiceDate"]))
data_filtered = data_filtered.withColumn("Month",F.month(data_filtered["InvoiceDate"]))
data_filtered = data_filtered.withColumn("DayOfWeek",F.dayofweek(data_filtered["InvoiceDate"])-1)
data_filtered = data_filtered.withColumn("DayOfWeek",F.udf(lambda x:x if x!=0 else 7,types.IntegerType())(data_filtered["DayOfWeek"]))
## 为准备prepare DataFrames for EDA
data_monthly = data_filtered.groupby(["Year","Month"]).agg(F.sum(F.col("Total Price")).alias("Total Price")
,F.sum(F.col("Quantity")).alias("Quantity")
,F.countDistinct(F.col("Invoice")).alias("Nr_Of_Transaction")).toPandas()
data_day_of_Week = data_filtered.groupby(["DayOfWeek"]).agg(F.sum(F.col("Total Price")).alias("Total Price")
,F.sum(F.col("Quantity")).alias("Quantity")
,F.countDistinct(F.col("Invoice")).alias("Nr_Of_Transaction")).toPandas()
data_all_stock = data_filtered.groupby(["StockCode","Description","Year","Month"]).agg(F.sum(F.col("Total Price")).alias("Total Price")
,F.sum(F.col("Quantity")).alias("Quantity")
,F.countDistinct(F.col("Invoice")).alias("Nr_Of_Transaction")).toPandas()
data_all_customer = data_filtered.groupby(["Country","Customer ID","Year","Month"]).agg(F.sum(F.col("Total Price")).alias("Total Price")
,F.sum(F.col("Quantity")).alias("Quantity")
,F.countDistinct(F.col("Invoice")).alias("Nr_Of_Transaction")).toPandas()
2 探索性分析
首先让我们对总体的销售数据做一个分析
import seaborn as sns
import matplotlib as mpl
import matplotlib.pyplot as plt
import plotly.graph_objects as go
data_monthly = data_filtered.groupby(["Year","Month"]).agg(F.sum(F.col("Total Price")).alias("Total Price")
,F.sum(F.col("Quantity")).alias("Quantity")
,F.countDistinct(F.col("Invoice")).alias("Nr_Of_Transaction")).toPandas()
data_monthly = data_monthly.sort_values(["Year","Month"]).reset_index(drop=True)
plt.figure(figsize=(20,10))
plt.plot(data_monthly["Total Price"])
plt.xticks(data_monthly.index,[str(data_monthly.loc[i,"Year"])+"\n"+str(data_monthly.loc[i,"Month"]) for i in data_monthly.index])
plt.title("Trend of All Sales")
plt.show()
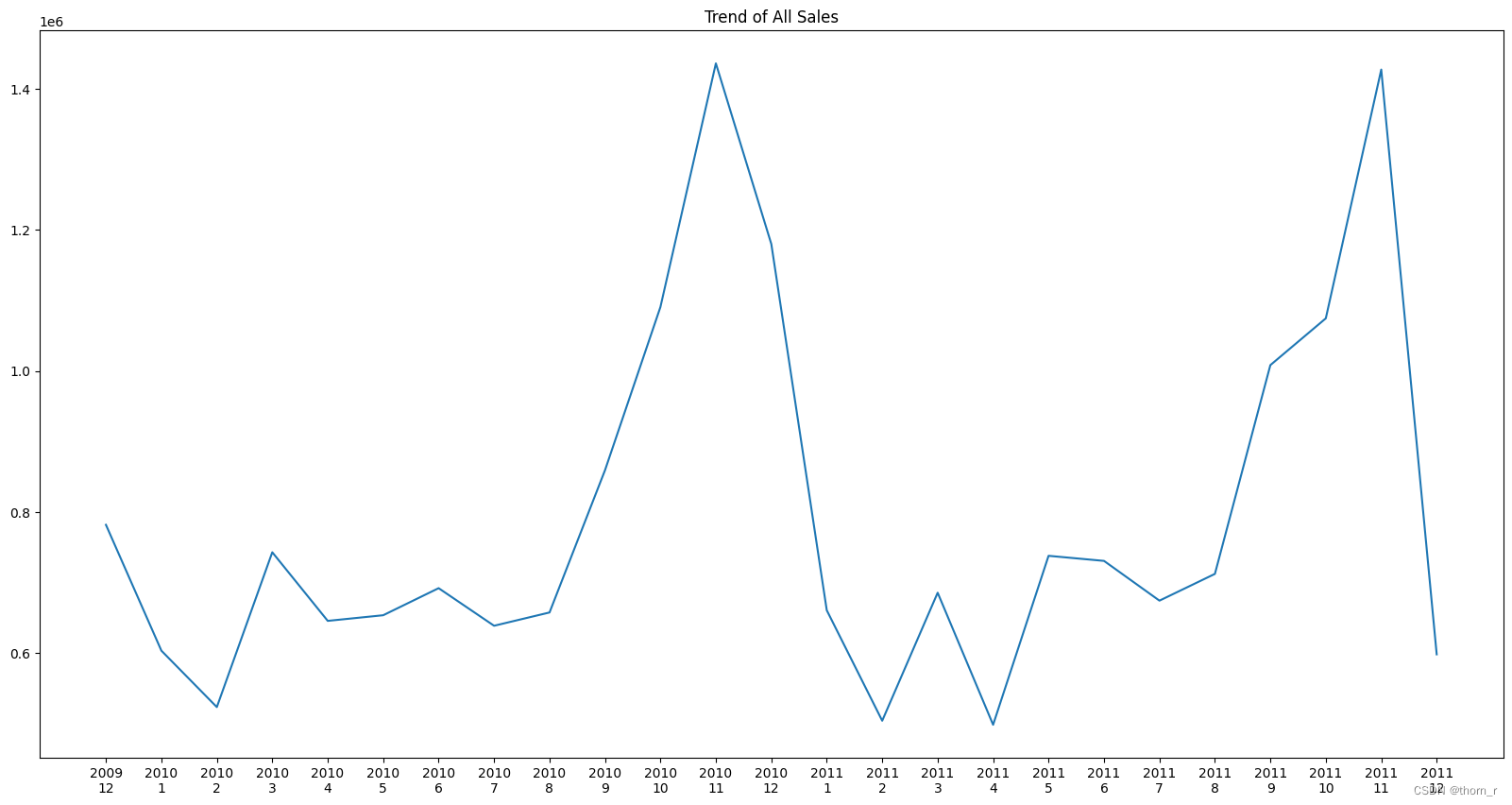
从整体趋势来看,销售在每年的11月都会有一个明显的顶峰,到了12月又急速落回。
data_day_of_Week = data_day_of_Week.sort_values(["DayOfWeek"]).reset_index(drop=True)
go.Figure(go.Bar(x=data_day_of_Week["DayOfWeek"],y=data_day_of_Week["Total Price"]),layout={"title":"DayOfWeek Total Sales"})
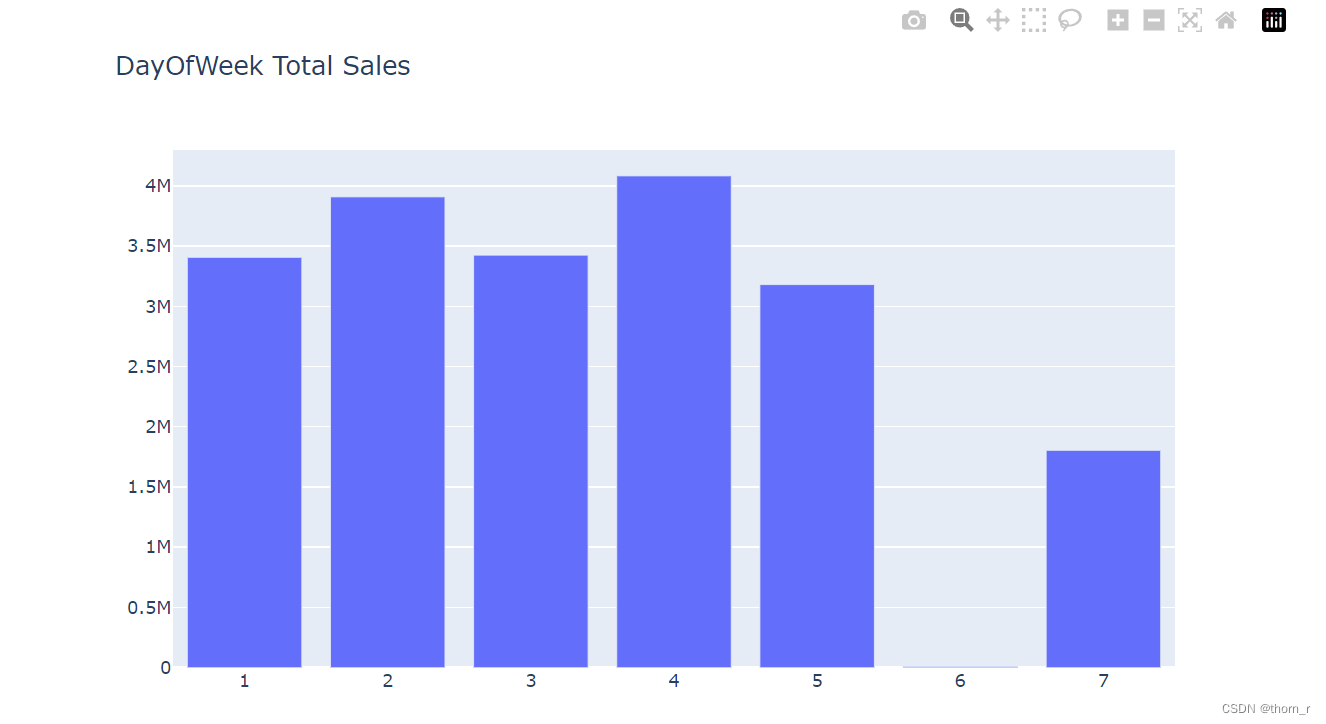
周六没有任何的销售,周日的销售明显低于其他工作日的销售。
接下来将数据粒度放在每个客户上,看看客户的销售状况。
from collections import Counter
data_all_customer=data_all_customer[data_all_customer["Customer ID"]!=99999].reset_index(drop=True)
all_countrys = data_all_customer.groupby("Country")["Customer ID"].nunique().sort_values(ascending=False)
all_countrys["Others"] = sum(all_countrys[all_countrys.index[3:]])
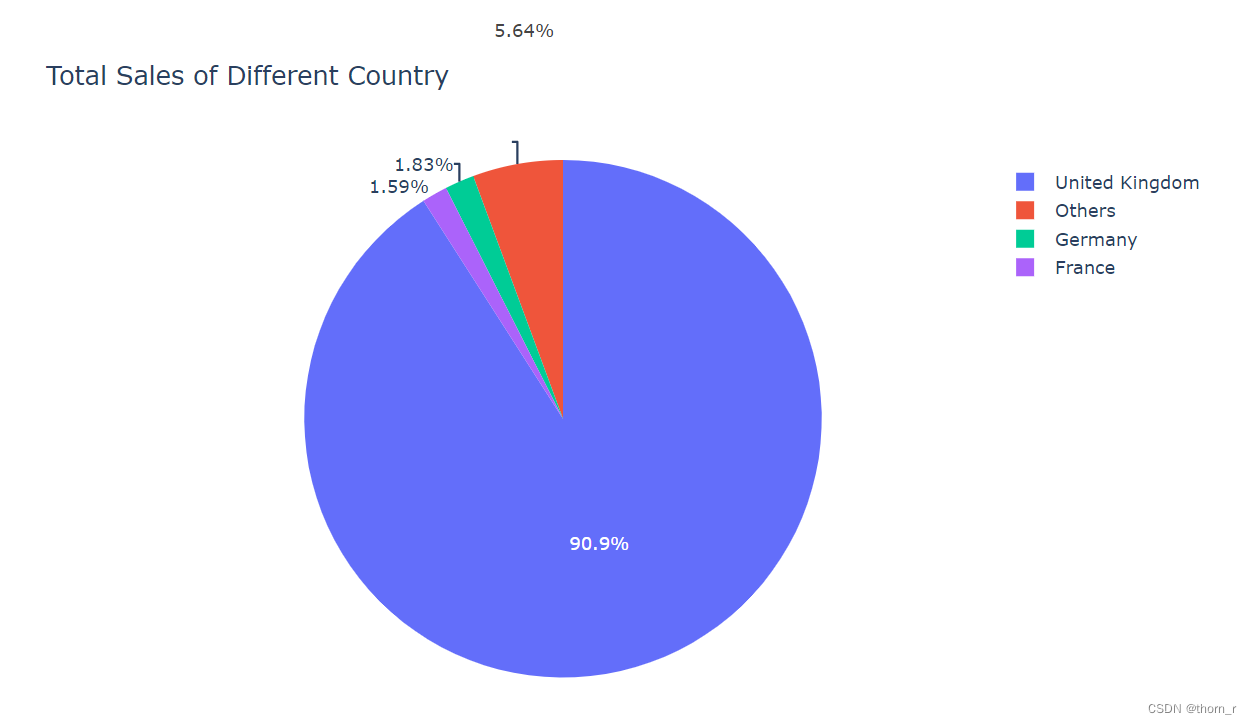
go.Figure(go.Pie(labels=all_countrys.index[0:3].tolist()+["Others"],values=all_countrys[all_countrys.index[0:3].tolist()+["Others"]]),
layout={"title":"Total Sales of Different Country"})
all_customer_frequencys = dict(Counter(data_all_customer.groupby(["Customer ID"])["Nr_Of_Transaction"].sum().sort_values()))
go.Figure(go.Bar(x=list(all_customer_frequencys.keys()),y=list(all_customer_frequencys.values())),layout={"title":"Number of Transactions of each Customer"})
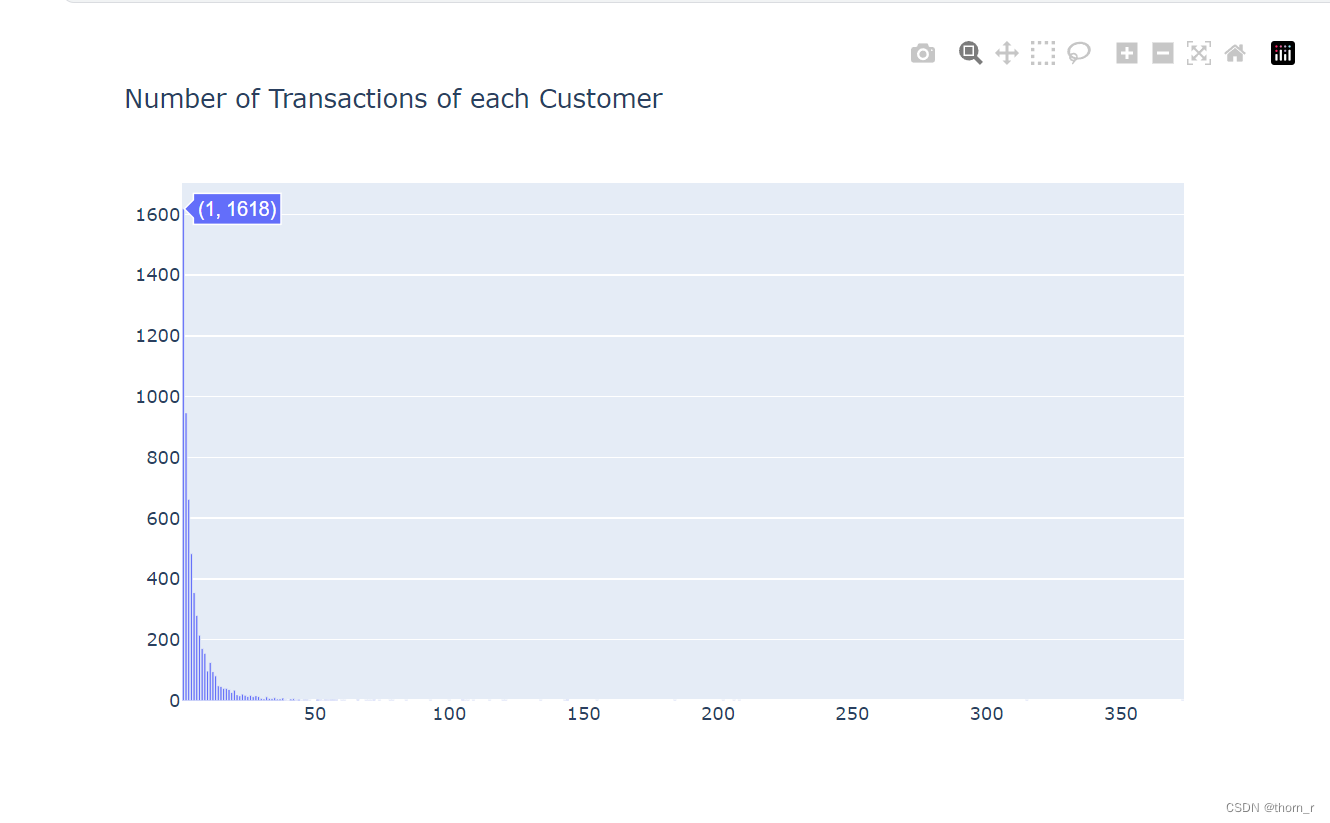
可以看到,有超过90%的客户都来自于英国。使用plotly作图,通过拖拽缩放可以看出,又数量相当的客户(1618个)都是“只买一次”的。大多数的客户只会进行有限次数的消费。
## top 10 customers
Top10_Sales_Customer = data_all_customer.groupby(["Customer ID"])["Total Price"].sum().sort_values(ascending=False)[0:10]
go.Figure(go.Bar(x=Top10_Sales_Customer.index.astype("str"),y=Top10_Sales_Customer.values),layout={"title":"Top 10 Customers"})
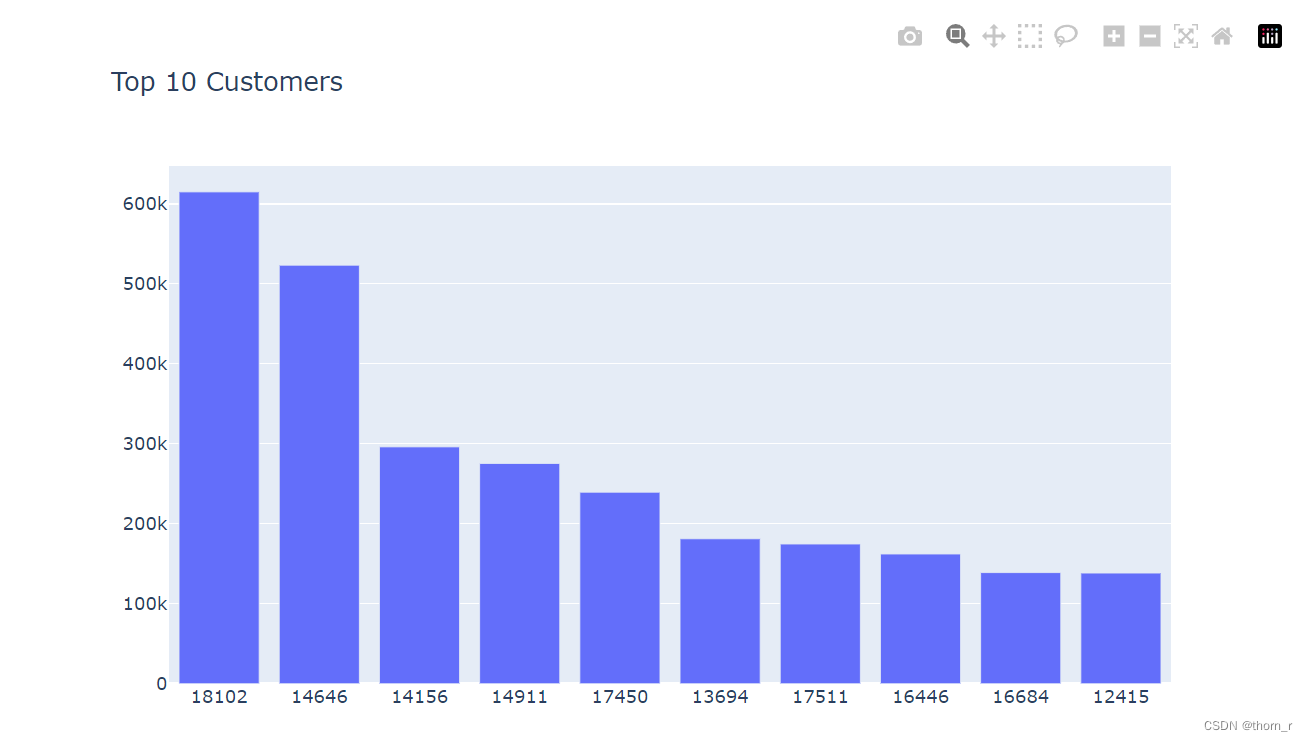
Top10_Sales_History=data_all_customer[[data_all_customer.loc[i,"Customer ID"] in Top10_Sales_Customer.index for i in range(data_all_customer.shape[0])]].reset_index(drop=True)
layout = go.Layout(title="Top 3 Customers History",legend={"title":"Customer ID"},xaxis={"tickvals":list(range(25)),"ticktext":[str(data_monthly.loc[i,"Year"])+" "+str(data_monthly.loc[i,"Month"]) for i in data_monthly.index]}
,width=1000)
ax = go.Figure(layout=layout)
for i in Top10_Sales_Customer.index[0:3]:
tmp = Top10_Sales_History[Top10_Sales_History["Customer ID"]==i].sort_values(["Year","Month"]).reset_index(drop=True)
tmp.index = [str(tmp.loc[i,"Year"])+"\n"+str(tmp.loc[i,"Month"]) for i in tmp.index]
ax.add_scatter(x=list(range(tmp.shape[0])),y=tmp["Total Price"],name=i)
ax.show()
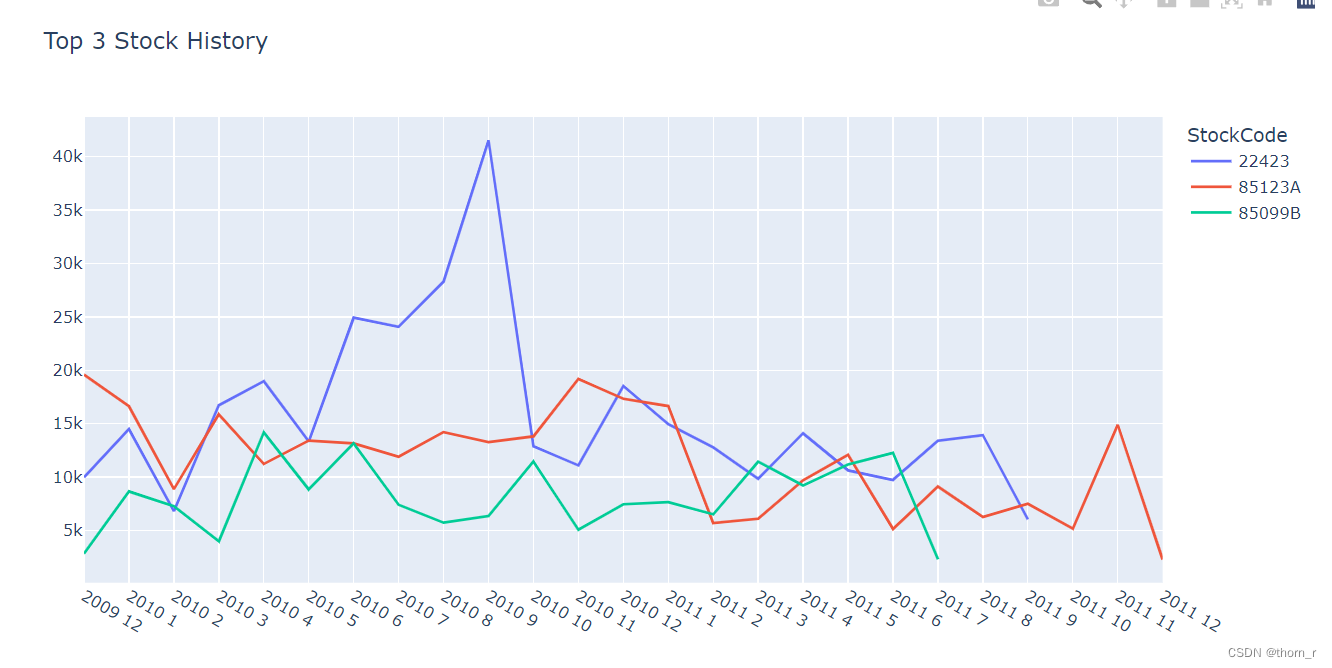
从Top10和Top3的用户销售来看,头部用户的销售有着“间隔短、销售大”的特点。当然,这里的头部用户也有可能是数据集中的“批发商”。
接下来,我们从商品粒度来看一下名列前茅的商品:
Top10_Sales_Stock = data_all_stock.groupby(["StockCode","Description"])["Total Price"].sum().sort_values(ascending=False).reset_index().iloc[0:10,:]
go.Figure(go.Bar(x=Top10_Sales_Stock["Description"],y=Top10_Sales_Stock["Total Price"]),
layout={"xaxis":{"tickfont":{"size":10}},"width":1000,"height":800,"title":"Top 10 Stock Sales"})
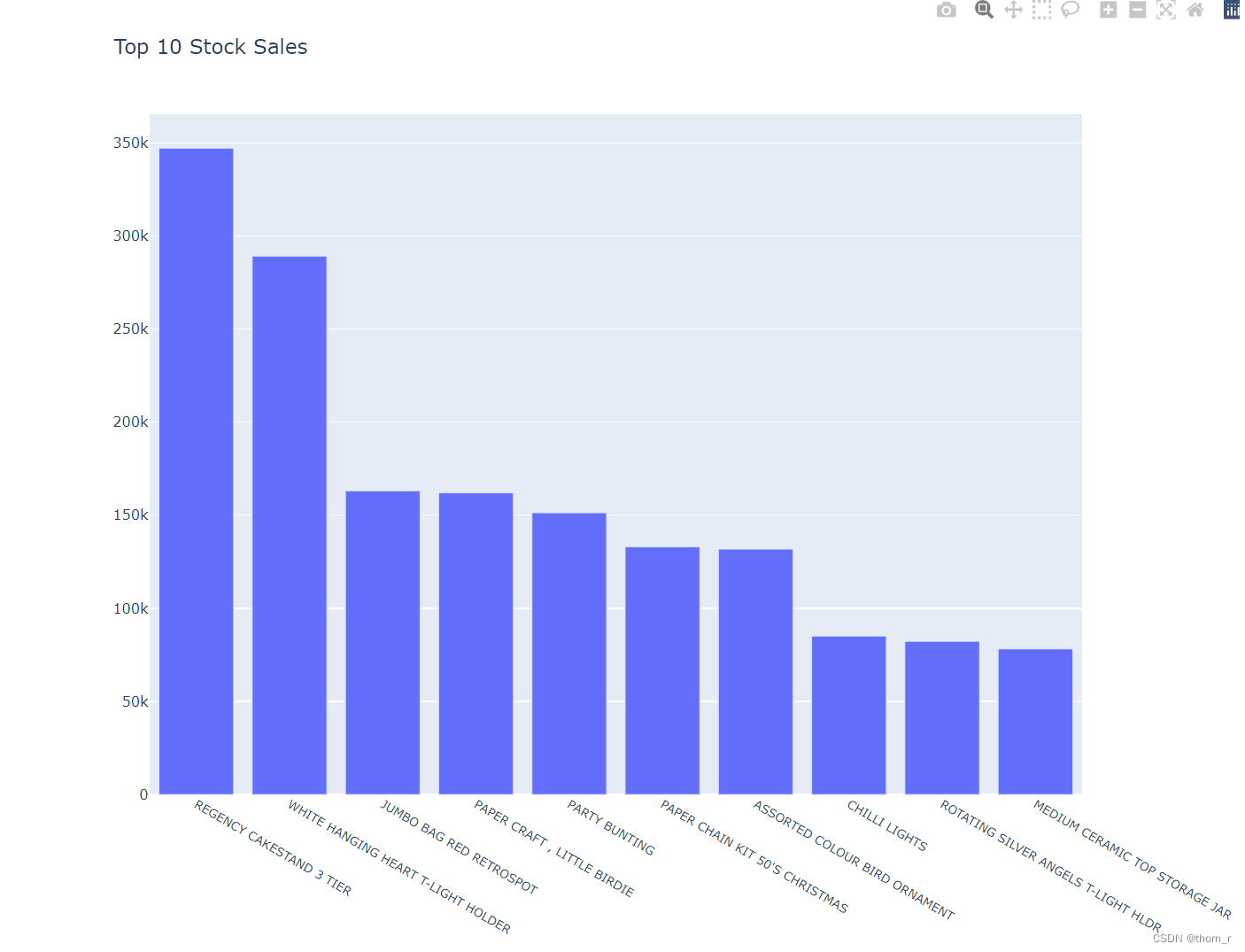
Top10_Sales_History_Stock=data_all_stock[[data_all_stock.loc[i,"StockCode"]+data_all_stock.loc[i,"Description"] in
[i+j for i,j in zip(Top10_Sales_Stock["StockCode"].tolist(),Top10_Sales_Stock["Description"].tolist())]
for i in range(data_all_stock.shape[0])]].reset_index(drop=True)
layout = go.Layout(title="Top 3 Stock History",legend={"title":"StockCode"},xaxis={"tickvals":list(range(25)),"ticktext":[str(data_monthly.loc[i,"Year"])+" "+str(data_monthly.loc[i,"Month"]) for i in data_monthly.index]}
,width=1000)
ax = go.Figure(layout=layout)
for i in Top10_Sales_Stock.loc[0:2,"StockCode"]:
tmp = Top10_Sales_History_Stock[Top10_Sales_History_Stock["StockCode"]==i].sort_values(["Year","Month"]).reset_index(drop=True)
tmp.index = [str(tmp.loc[i,"Year"])+"\n"+str(tmp.loc[i,"Month"]) for i in tmp.index]
ax.add_scatter(x=list(range(tmp.shape[0])),y=tmp["Total Price"],name=i)
ax.show()
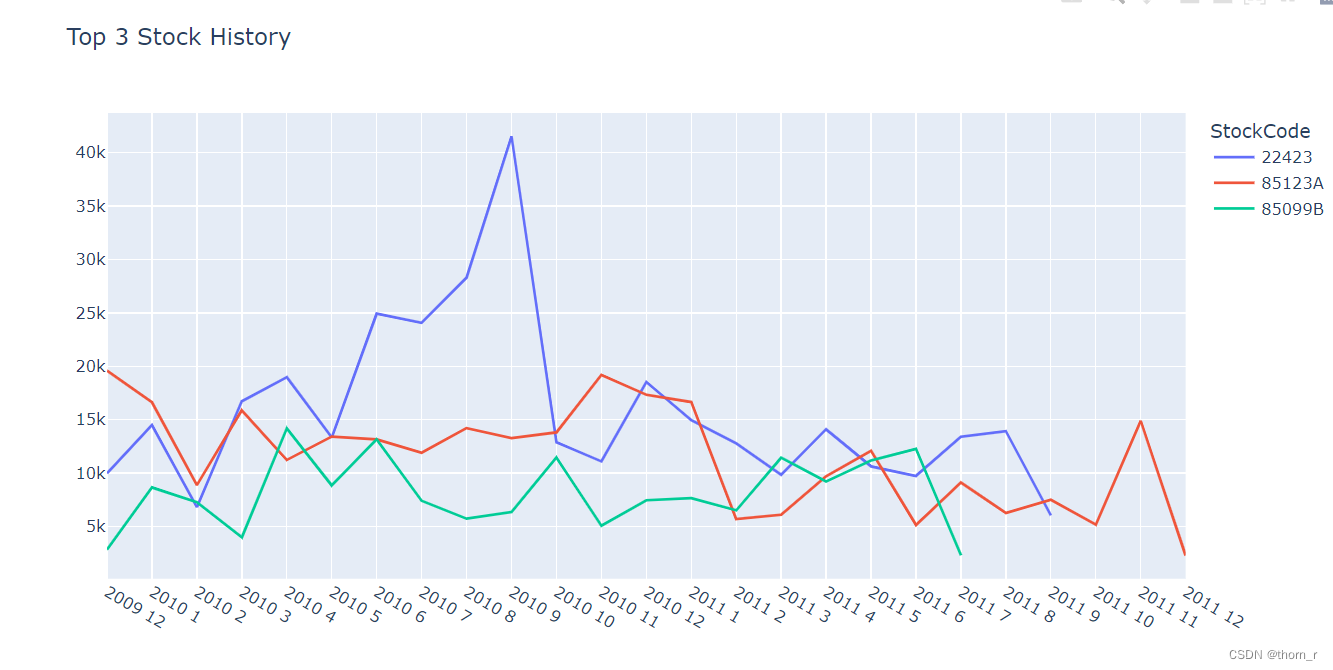
3 RMF
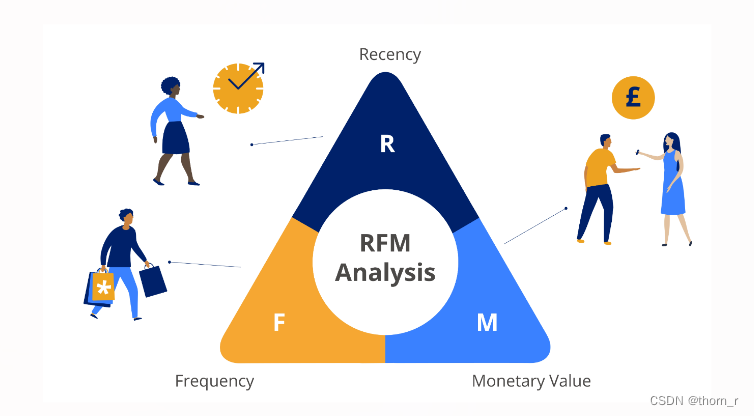
RFM模型通过R、F、M这3个指标将用户分群,用以衡量客户的价值于创收能力。
其中,R(Recency)代表用户最近一次的消费距离截止时间的间隔,通常间隔越短,代表用户越有消费意愿。
F(Frequency)代表用户在调查时间段内的消费次数,消费频次越高代表用户的忠诚度越高。
M(Monetary)代表用户在调查时间段内的消费金额。消费金额越大代表客户的消费能力也越大。
## 最大日期 MaxDate
data_filtered.agg(F.max(F.col("InvoiceDate"))).show()
这是数据的截止日期,我们可以通过这个日期作为基准来推测出每个用户的的最近一次消费间隔。
data_for_RFM = data_filtered.filter(~data["Customer ID"].isin([99999])).groupby(["Customer ID"]).agg(F.sum(F.col("Total Price")).alias("monetary")
,F.countDistinct(F.col("Invoice")).alias("frequncy")
,F.max(F.col("InvoiceDate")).alias("MaxInvoiceDate")
,F.min(F.col("InvoiceDate")).alias("MinInvoiceDate"))\
.toPandas()
data_for_RFM["recency"] = (pd.Timestamp("2011-12-10")-pd.to_datetime(data_for_RFM["MaxInvoiceDate"])).dt.days
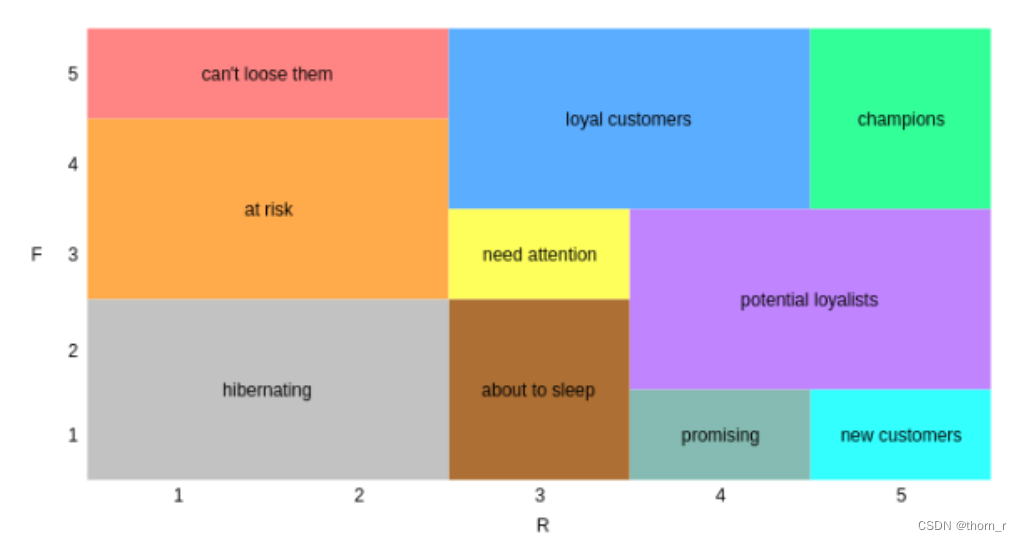
此处我们根据上图,我们可以通过Recency和Frequency来将用户划分为不同的10个维度。如果有兴趣的话,也可以使用一些无监督的机器学习方法来作为划分不同用户种类的方法。
## segmentation
data_for_RFM["Recency_score"] = pd.qcut(data_for_RFM["recency"].rank(method = "first"),5,labels=[5,4,3,2,1])
data_for_RFM["Frequncy_Score"] = pd.qcut(data_for_RFM["frequncy"].rank(method = "first"),5,labels=[1,2,3,4,5])
data_for_RFM["monetary_score"] = pd.qcut(data_for_RFM["monetary"].rank(method = "first"),5,labels=[1,2,3,4,5])
seg_map = {
r'[1-2][1-2]' : 'hibernating',
r'[1-2][3-4]' : 'at_Risk',
r'[1-2]5' : 'cant-loose',
r'3[1-2]' : 'about_to_sleep',
r'33' : 'need_attention',
r'[3-4][4-5]' : 'loyal_customers',
r'41' : 'promising',
r'51' : 'new_customers',
r'[4-5][2-3]' : 'potential_loyalists',
r'5[4-5]' : 'champions'}
data_for_RFM["RF_score"] = data_for_RFM["Recency_score"].astype("str")+data_for_RFM["Frequncy_Score"].astype("str")
data_for_RFM["segment"] = data_for_RFM["RF_score"].replace(seg_map,regex=True)
layout = go.Layout(title="RFM Segmentation")
tmp = Counter(data_for_RFM["segment"])
go.Figure(go.Pie(labels=list(tmp.keys()),values=list(tmp.values()),
textposition='inside',textinfo="label"),layout=layout)
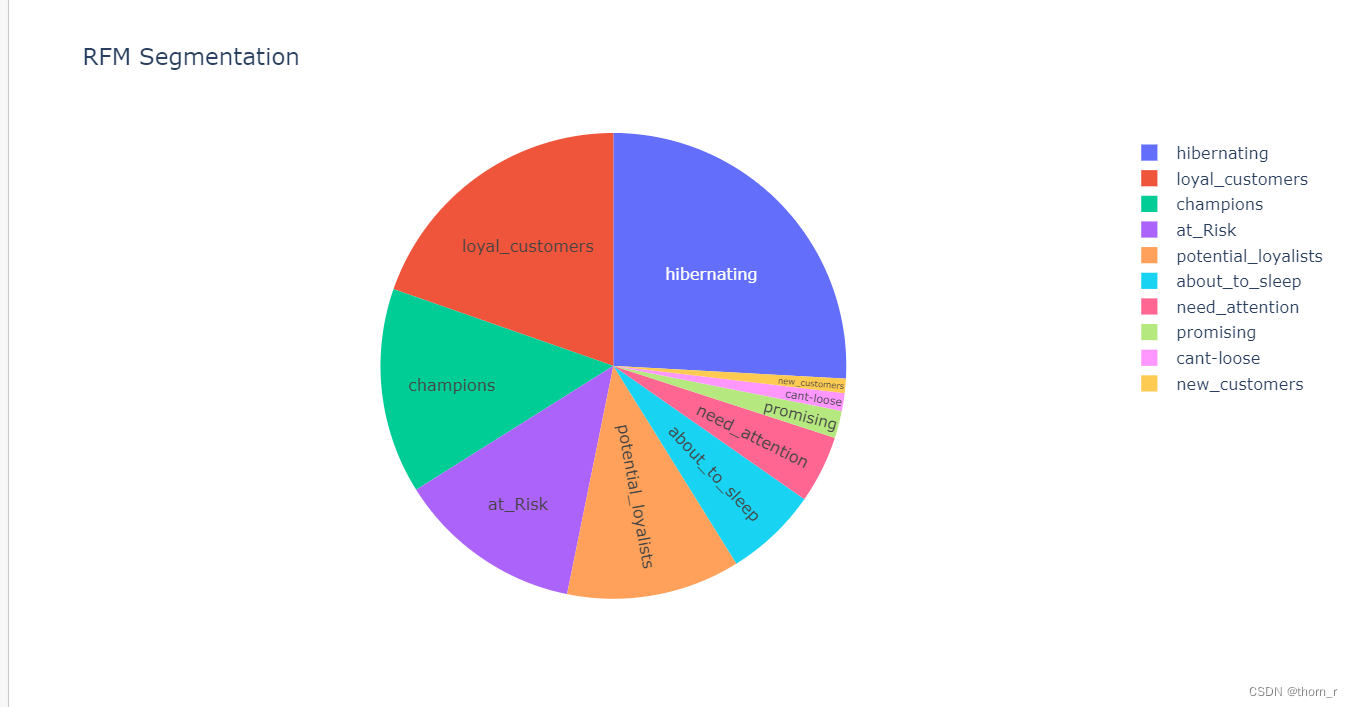
从上图可以看出,“冬眠中”的客户占了很大的比重(25.9%),这与之前“大多数用户都是只进行有限次数的交易”的结论相同。而排名第二的“忠诚客户”与“冠军客户”,是会长期来交易的,很有可能是创造了绝大多数盈利的客户,我们应当注重对于这部分用户的留存。而在这之后的“风险用户”和“潜力客户”,有机会转换为忠诚客户,或许可以通过短信回访或是折扣促销鼓励他们重新活跃。
weight = {
"recency_scaled":0.4,
"monetary_scaled":0.2,
"recency_scaled":0.4
}
for col in ["monetary","frequncy","recency"]:
max_value = max(data_for_RFM[col])
min_value = min(data_for_RFM[col])
data_for_RFM[col+"_scaled"] = (data_for_RFM[col] - min_value)/(max_value-min_value)
data_for_RFM["RFM_value"]=0
for key in weight.keys():
data_for_RFM["RFM_value"] += weight[key]*data_for_RFM[key].astype("float")
go.Figure(go.Scatter(x=data_for_RFM["recency_scaled"],y=data_for_RFM["frequncy_scaled"],mode='markers',
marker=dict(color=data_for_RFM["RFM_value"]*100,size=data_for_RFM["RFM_value"]*100,cmin=0,cmax=40
,showscale=True)),
layout=go.Layout(coloraxis=dict(cmin=0,cmax=40)))
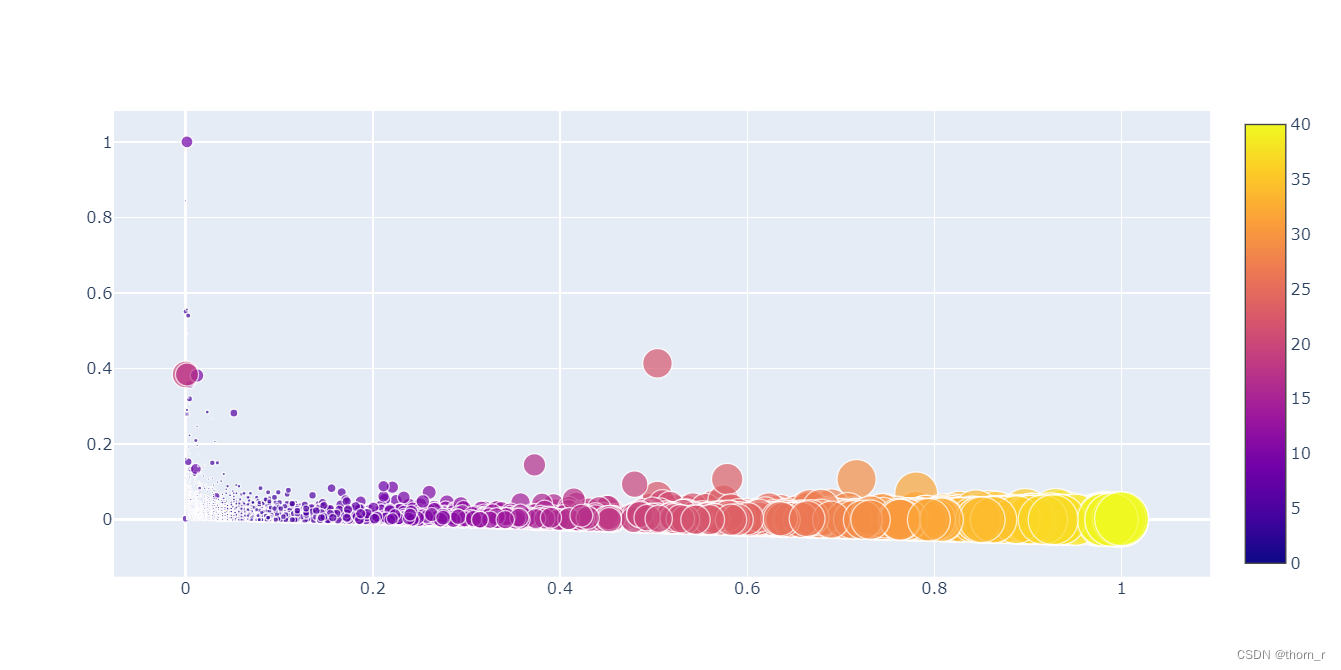
接下来,我对R、F、M分别加权求一个最终的RFM值,我个人理解零售业中的R和F的重要性比M更大,所以此处将M的比重设得更低了一点。注意这只是我个人“一拍脑袋”的结果,如果希望得到更有价值的权重,可以向业界专家进行咨询,或者使用层次分析法(APH)。
通过将RFM分数作气泡图可以看出,R对于RFM评估分数的贡献明显高于F值,这或许是因为大部分的用户都并非“长期购买”的客户。
4 生存分析
我们可以将用户的流失作为一个事件的结果,对于用户流失,有这2个特点:
1、我们需要再观察到所有数据(用户流失)之前采取行动
2、用户流失的时间(也就是用户的生命周期)很重要
因此,我们可以对用户流失进行生存分析
在此需要强调一下,笔者对于生存分析只有较为浅显的理解,没有系统的学习过生存分析课程,因此如果这里的分析有误还望海涵,如果能够指出错误将不胜荣幸。
首先,我们需要对“用户流失”进行一个定义。
from lifelines import KaplanMeierFitter
from scipy.interpolate import make_interp_spline
data_for_lifetime_for_gaps = data_filtered.filter(~data["Customer ID"].isin([99999])).groupby(["Customer ID","InvoiceDate"]).agg(F.sum(F.col("Total Price")).alias("Total Price")).toPandas()
data_for_lifetime_for_gaps["Seq"] = data_for_lifetime_for_gaps.groupby("Customer ID")["InvoiceDate"].rank()
data_for_lifetime_sub = data_for_lifetime_for_gaps.copy().drop("Total Price",axis=1).rename(columns={"InvoiceDate":"InvoiceDate_next"})
data_for_lifetime_sub["Seq"] = [i-1 for i in data_for_lifetime_sub["Seq"]]
data_for_lifetime_sub = data_for_lifetime_for_gaps.merge(data_for_lifetime_sub,on=["Customer ID","Seq"])
Gaps = [i.days for i in data_for_lifetime_sub["InvoiceDate_next"]-data_for_lifetime_sub["InvoiceDate"]]
data_for_lifetime_sub["Gaps"] = Gaps
Gaps = dict(Counter(Gaps))
Gaps = {key:Gaps[key] for key in sorted(Gaps)}
x = list(Gaps.keys())
y = np.array(list(Gaps.values()))/np.sum(list(Gaps.values()))
for i in range(1,len(y)):
y[i] += y[i-1]
layout = go.Layout(title="Accumulate Recall Rate after transaction X days",showlegend=False,yaxis={"tickformat":"0%"})
ax = go.Figure(layout=layout)
ax.add_scatter(x=x,y=y)
idx_90 = np.argmin(np.abs(y-0.9))
ax.add_scatter(x=[idx_90],y=[y[idx_90]])
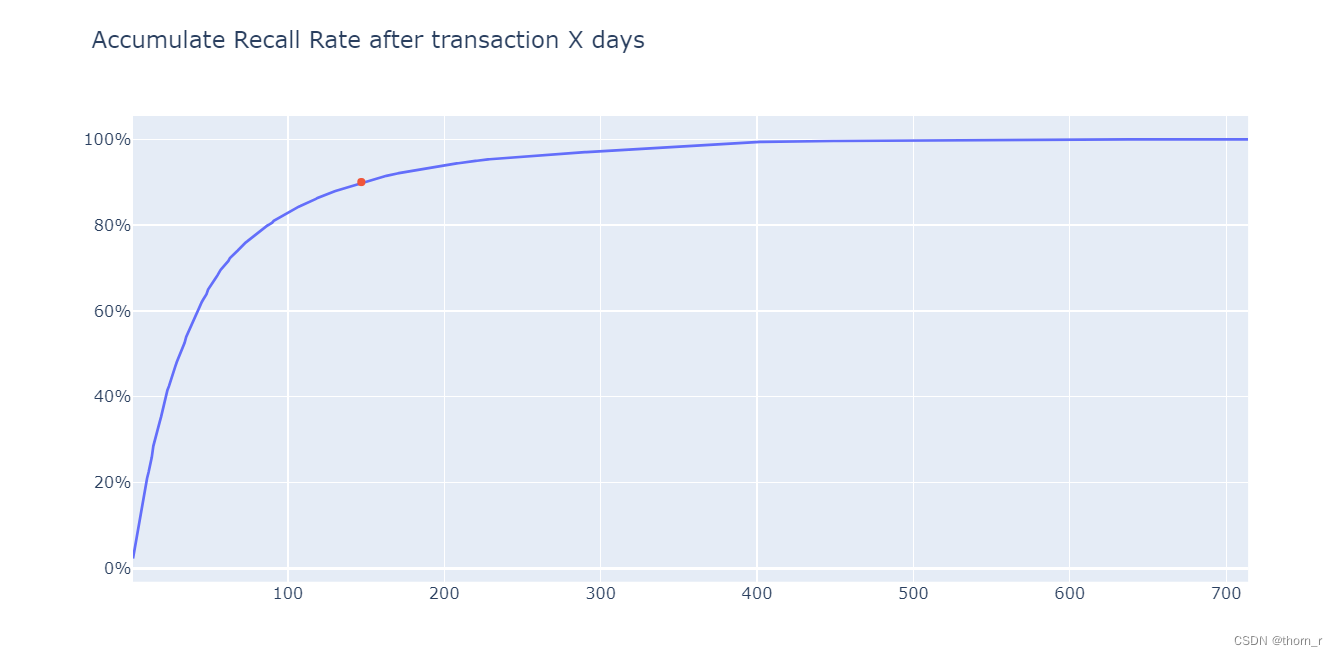
我将同一个客户前后2次交易的时间间隔统计并累加,发现在所有的客户交易中,有90%的“再次交易”都是在147天以内发生的。因此,我们将大于147天没有进行任何交易的客户视作是“不再活跃”的客户。
Kaplan-Meier
Kaplan-Meier生存分析是一种非参数的生存分析方法,它能够根据已有的历史数据推断出一个生存函数 𝑆(𝑡)
,而且能够画出阶梯形的图像让使用者能够直观感受生存率随着时间的改变。但是它没有实际的函数形式,无法估算风险比。
data_for_RFM["Dead"] = [1 if i>idx_90 else 0 for i in data_for_RFM["recency"]]
data_for_RFM["Tenture"] = (pd.to_datetime(data_for_RFM["MaxInvoiceDate"]) - pd.to_datetime(data_for_RFM["MinInvoiceDate"])).dt.days
km = KaplanMeierFitter()
km.fit(data_for_RFM["Tenture"]/30.5,data_for_RFM["Dead"])
survival_rate = km.survival_function_at_times(range(26))
go.Figure(go.Line(x=survival_rate.index,y=survival_rate.values,line_shape="hvh"),layout=go.Layout(title="Survival Rate",yaxis={"tickformat":"0%"}))
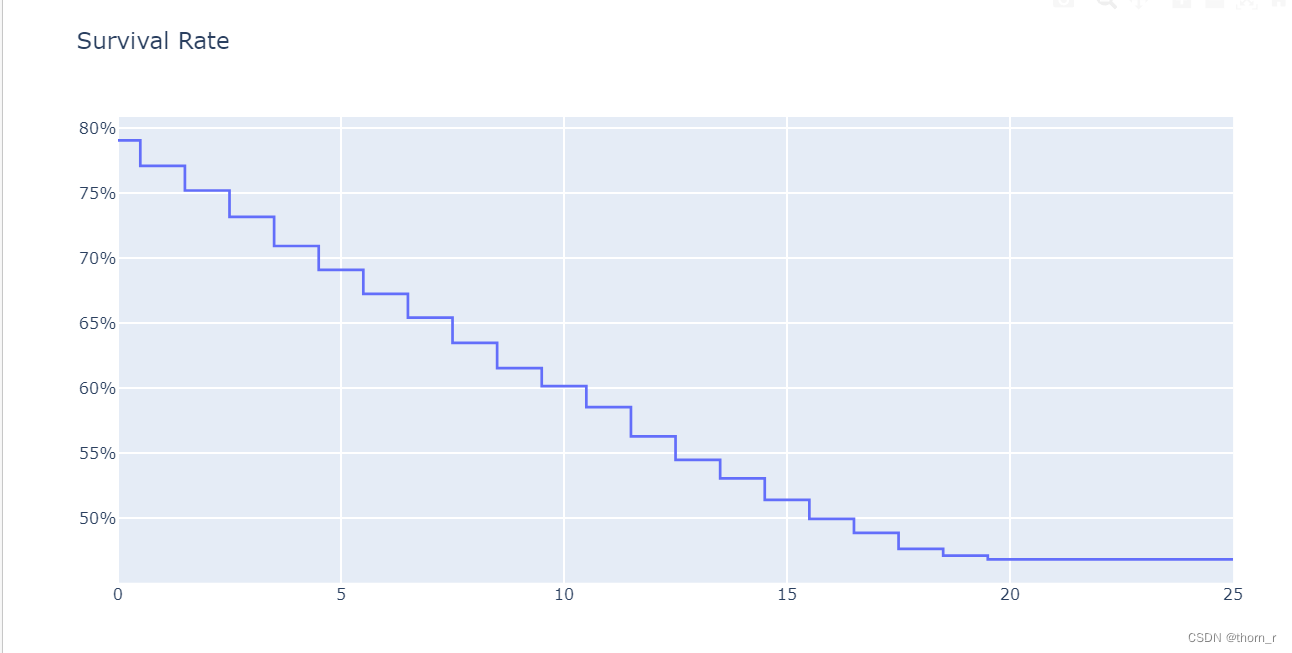
从图中可以看出,用户的生存率从第一次交易后以大约每月2%的速度在平缓下降。
Cox回归
Cox回归是一种半参数的生存分析方法,能够根据生存时间估计风险比。既能够处理离散类型的变量也能处理连续类型的变量,但是无法像Kaplan-Meier那样估计出一个生存函数 𝑆(𝑡)
。
此处将“客户是否为英国人”与“客户的消费金额”作为自变量,进行Cox回归,观察这两个自变量对于客户生存的风险比。
customer_Country = data_filtered.filter(~data["Customer ID"].isin([99999])).groupby(["Customer ID"]).agg(F.max(F.col("Country")).alias("Country")).toPandas()
customer_Country["IsUK"] = [1 if i == "United Kingdom" else 0 for i in customer_Country["Country"]]
data_for_RFM = data_for_RFM.merge(customer_Country,on="Customer ID",how="left")
data_for_cox = data_for_RFM[["Tenture","Dead","IsUK","monetary"]]
data_for_cox.loc[:,"Tenture"] = data_for_cox["Tenture"]/30.5
data_for_cox.loc[:,"monetary"] = np.log(data_for_cox["monetary"].astype(int))
from lifelines import CoxPHFitter
cox = CoxPHFitter()
cox.fit(data_for_cox,duration_col="Tenture",event_col="Dead")
cox.print_summary()
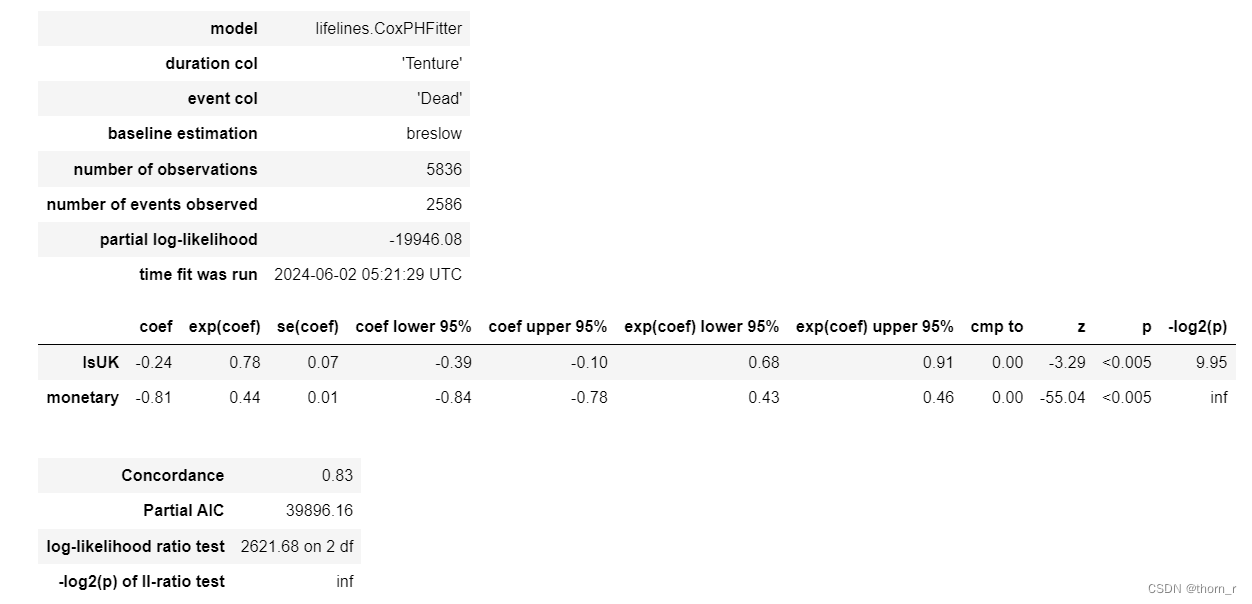
P值均小于0.05,表明客户是否为英国人、客户的消费量这2个指标均对于是否流失对有显著的影响。而他们的风险(表格中的exp(coef))比小于1,表明英国客户更不容易流失,消费越多越不容易流失。
5 Customer Lifetime Value
我们期望能够根据客户过去的购买行为用以预测每个客户未来的价值,以此作为企业下一步的销售方针。此处采用BG-NBD模型。它对于有如下的数学假设:
1、用户在活跃状态下,一个用户在时间段t内完成的交易数量服从交易率为
λ
\lambda
λ的泊松过程,这相当于假设了交易与交易之间的时间随交易率
λ
\lambda
λ呈指数分布
f
(
t
j
∣
t
j
−
1
;
λ
)
=
λ
e
−
λ
(
t
j
−
t
j
−
1
)
f(t_j|t_{j-1};\lambda) = \lambda e^{-\lambda(t_j-t_{j-1})}
f(tj∣tj−1;λ)=λe−λ(tj−tj−1) , t_j>t_{j-1}>=0
2、用户的交易率
λ
\lambda
λ服从如下的gamma分布
f
(
λ
∣
r
,
α
)
=
α
r
λ
r
−
1
e
−
λ
α
Γ
(
r
)
,
λ
>
0
f(\lambda | r,\alpha)=\frac{\alpha^r\lambda ^{r-1}e^{-\lambda\alpha}}{\Gamma(r)} , \lambda>0
f(λ∣r,α)=Γ(r)αrλr−1e−λα,λ>0
其中
Γ
(
r
)
=
∫
0
+
∞
t
r
−
1
e
−
t
d
t
\Gamma(r)=\int_0^{+\infty}t^{r-1}e^{-t}dt
Γ(r)=∫0+∞tr−1e−tdt,是gamma函数
3、每个用户在第j次交易完之后流失的概率服从参数为p的二项分布,p为发生任何交易后用户流失的概率
P
(
在第
j
次交易后不再活跃
)
=
p
(
1
−
p
)
j
−
1
,
j
=
1
,
2
,
3
,
.
.
.
P(在第j次交易后不再活跃)=p(1-p)^{j-1},j=1,2,3,...
P(在第j次交易后不再活跃)=p(1−p)j−1,j=1,2,3,...
4、每个用户的流失率p服从形状参数为a,b的beta分布
f
(
p
∣
a
,
b
)
=
p
a
−
1
(
1
−
p
)
b
−
1
B
(
a
,
b
)
,
0
<
=
p
<
=
1
f(p|a,b)=\frac{p^{a-1}(1-p)^{b-1}}{B(a,b)},0<=p<=1
f(p∣a,b)=B(a,b)pa−1(1−p)b−1,0<=p<=1
其中,B(a,b)是贝塔函数,
B
(
a
,
b
)
=
Γ
(
a
)
Γ
(
b
)
Γ
(
a
+
b
)
=
∫
0
1
x
a
−
1
(
1
−
x
)
b
−
1
d
x
B(a,b)=\frac{\Gamma(a)\Gamma(b)}{\Gamma(a+b)}=\int_0^1x^{a-1}\left(1-x\right)^{b-1}dx
B(a,b)=Γ(a+b)Γ(a)Γ(b)=∫01xa−1(1−x)b−1dx
5、交易率
λ
\lambda
λ和流失率p互相独立
根据这些假设,我们就可以推导出每个独立客户在未来活跃的概率以及未来某段时间内的期望购买次数。具体的数学推到过程可以看:https://www.brucehardie.com/notes/039/bgnbd_derivation__2019-11-06.pdf
from lifetimes.utils import summary_data_from_transaction_data,calibration_and_holdout_data
from lifetimes import BetaGeoFitter
from sklearn.metrics import mean_squared_error
data_for_lifetime = data_filtered.filter(~data["Customer ID"].isin([99999])).groupby(["Customer ID","InvoiceDate"]).agg(F.sum(F.col("Total Price")).alias("monetary")
,F.countDistinct(F.col("Invoice")).alias("frequncy"))\
.toPandas()
data_for_lifetime["InvoiceDate"] = pd.to_datetime(data_for_lifetime["InvoiceDate"])
predict_days = int(np.floor((max(data_for_lifetime["InvoiceDate"])-min(data_for_lifetime["InvoiceDate"])).days*0.2))
calibration_period_end = max(data_for_lifetime["InvoiceDate"]) - pd.Timedelta(days=predict_days)
data_for_bgnbd = summary_data_from_transaction_data(data_for_lifetime,customer_id_col="Customer ID",
datetime_col="InvoiceDate",monetary_value_col="monetary",
observation_period_end="2011-12-10"
,freq="W"
)
data_for_lifetime_holdout = calibration_and_holdout_data(
data_for_lifetime,
customer_id_col="Customer ID",datetime_col="InvoiceDate",monetary_value_col="monetary",observation_period_end="2011-12-10"
,calibration_period_end=calibration_period_end
,freq="W"
)
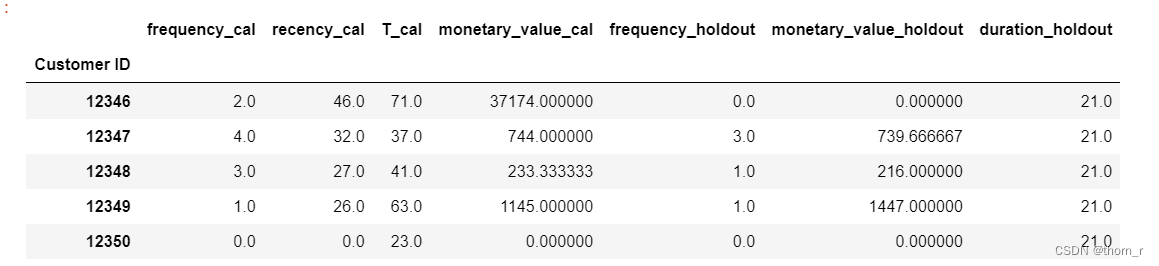
data_for_lifetime_holdout.head()
超参数选择
np.random.seed(42)
scores = pd.DataFrame(columns=["penalizer","score"])
data_for_lifetime_holdout["n_transactions_holdout_real"] = data_for_lifetime_holdout["frequency_holdout"]
for i in np.linspace(0,1,100):
penalizer_coef = i
model=BetaGeoFitter(penalizer_coef=penalizer_coef)
model.fit(frequency=data_for_lifetime_holdout["frequency_cal"],
recency=data_for_lifetime_holdout["recency_cal"],
T=data_for_lifetime_holdout["T_cal"])
predicted = model.predict(t=data_for_lifetime_holdout["duration_holdout"].values[0],
frequency=data_for_lifetime_holdout["frequency_cal"],
recency=data_for_lifetime_holdout["recency_cal"],
T=data_for_lifetime_holdout["T_cal"],)
predicted[pd.isna(predicted)]=0
score = mean_squared_error(y_true=data_for_lifetime_holdout["frequency_holdout"],y_pred=predicted,squared=False)
score = pd.DataFrame({"penalizer":[i],"score":[score]})
scores = pd.concat([score,scores],axis=0)
scores = scores.reset_index(drop=True)
go.Figure(go.Line(x=scores["penalizer"],y=scores["score"]),layout=go.Layout(title="penalizer-score"))
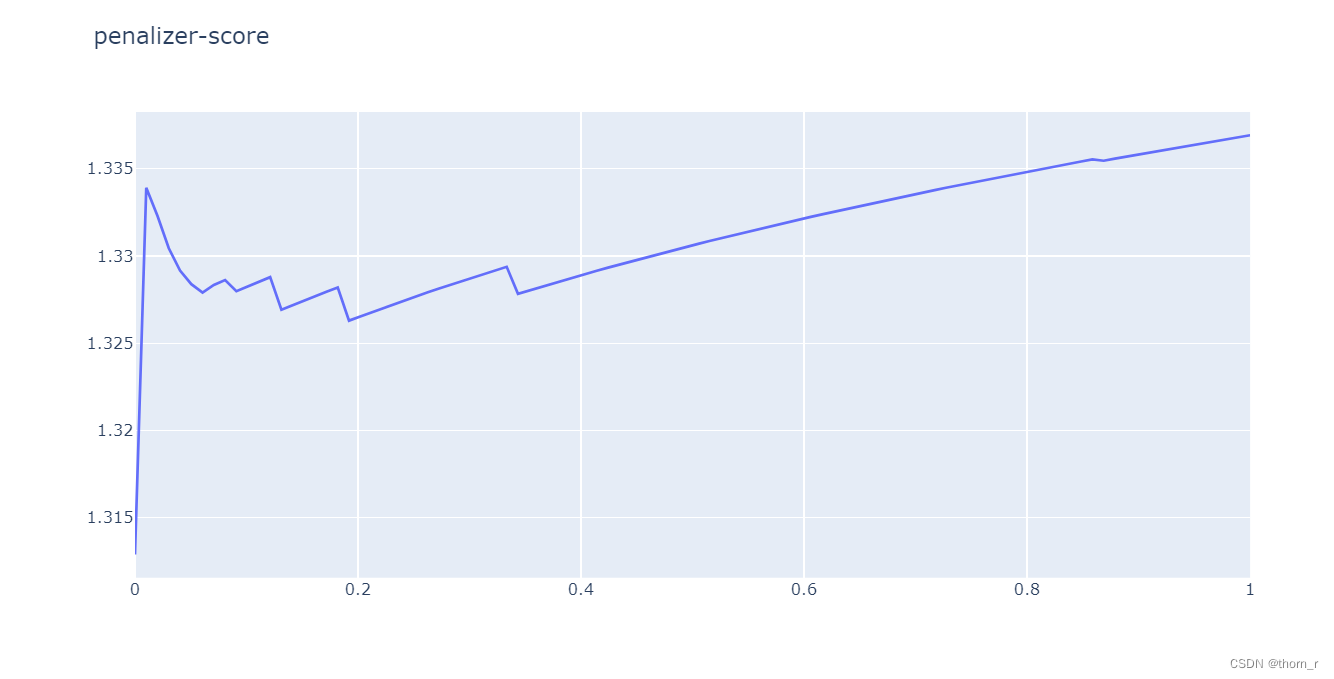
首先,我们使用calibration_and_holdout_data方法来将数据集分为训练集和验证集。由于只有1个超参数:L2惩罚项,我们直接将其分段枚举以此作超参数搜索。根据上图的结果,我们可以看出,在惩罚项为0时,模型在验证集上的效果最好(RMSE最低)。于是在下文使用这个超参数在全部的数据上重新建模进行分析。
模型参数解读
penalizer_coef = scores.loc[np.argmin(scores["score"]),"penalizer"]
model=BetaGeoFitter(penalizer_coef=penalizer_coef)
model.fit(frequency=data_for_bgnbd["frequency"],
recency=data_for_bgnbd["recency"],
T=data_for_bgnbd["T"])
import scipy.stats as stats
x_gamma = np.linspace(0, 20, 1000)
y_gamma = stats.gamma.pdf(x_gamma, a=model.params_["alpha"], scale=model.params_["r"])
x_beta = np.linspace(0, 1, 1000)
y_beta = stats.beta.pdf(x_beta, a=model.params_["a"], b=model.params_["b"])
go.Figure(go.Line(x=x_gamma,y=y_gamma),layout=go.Layout(title="Gamma Distribution"))
go.Figure(go.Line(x=x_beta,y=y_beta),layout=go.Layout(title="Beta Distribution"))
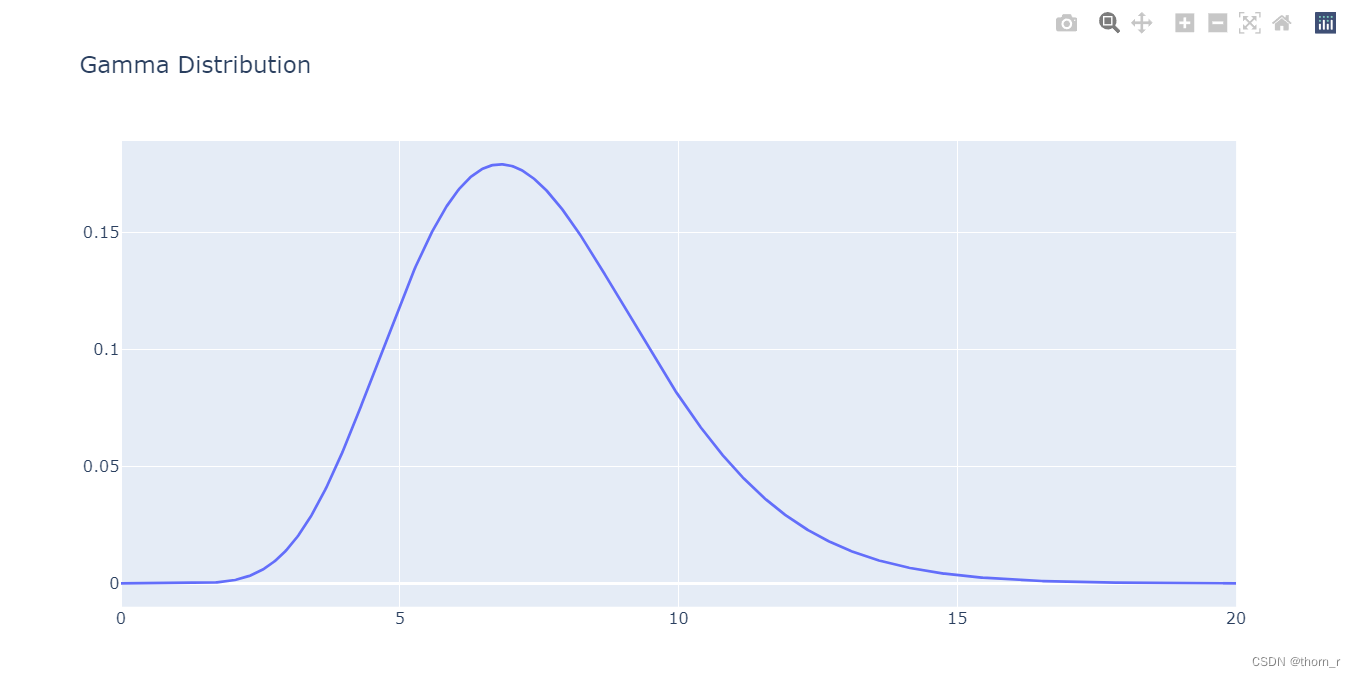
模型参数
α
\alpha
α和
r
r
r是模型假设中用户交易率
γ
\gamma
γ的参数;从上图中可以看到,Gamma分布在x=7处有一个明显的峰顶,可以认为有相当一部分的客户会有每周购买7次的频率。但是这并不能说客户大多数有着一周7次的高频交易,因为实际上这个峰顶的绝对值只有约0.17,用户实际的交易率并没有集中在某个特定的频率上。
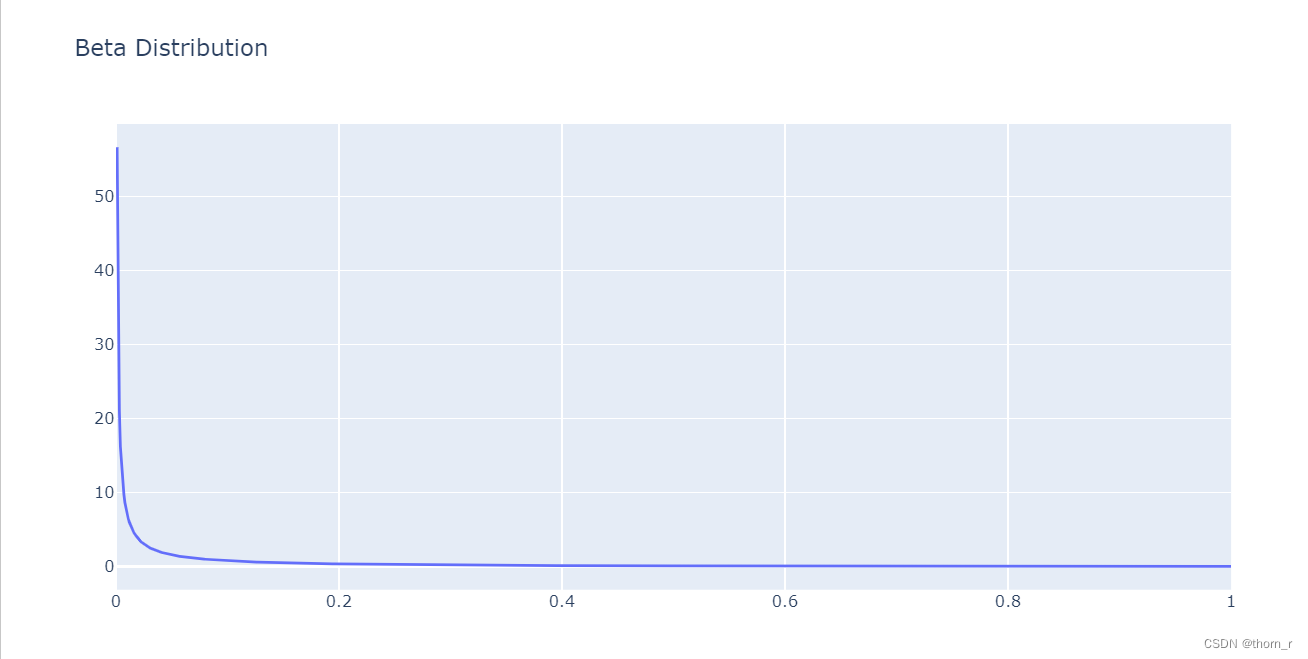
模型参数
a
a
a和
b
b
b是模型假设中用户每次交易后的流失率
p
p
p的参数;从上图中可以看到,大部分的流失率都集中在0附近,表明客户不会太快流失。
但是请注意,这里实际上是有一个“陷阱”的:lifetimes默认不会将用户的“第一次交易”带入模型内,也就是说,对于只有1次交易然后就不再购买的客户而言,这个用户仅仅是注册了一下而已。而对于BG-NBD模型而言,像这样没有过任何交易的客户,其流失率应该给为0(不可能流失)。
from lifetimes.plotting import plot_frequency_recency_matrix,plot_probability_alive_matrix
plot_frequency_recency_matrix(model)
plt.show()
plot_probability_alive_matrix(model)
plt.show()
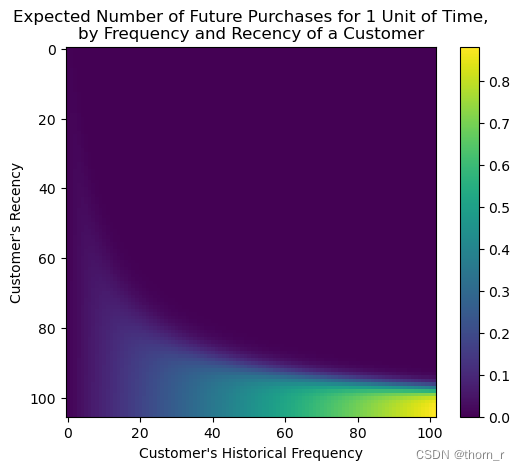
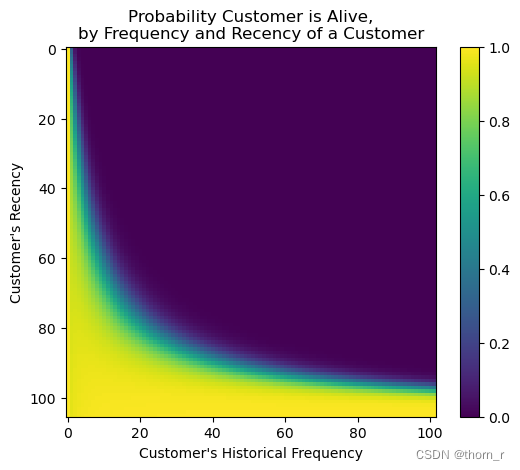
用户价值预测
我们训练出来了一个BG-NBD模型,可以用以预测用户的生存概率以及接下来k期的购买数量。根据这2个预测,我们可以对客户在未来k个时期客户价值:
C
V
k
=
存活概率
∗
交易数
k
∗
购买价值
CV_k=\text{存活概率}*\text{交易数}_k*\text{购买价值}
CVk=存活概率∗交易数k∗购买价值
但是需要注意的是,这个估计是基于2个较为薄弱的假设的:
1、存活概率在下一个时刻保持不变
2、在接下来的k个时期,购买的平均价值等于观察期的平均价值
这2个假设在现实情况下未必成立,因此可以使用更为复杂的模型,如Gamma-Gamma模型进行更为严格的估计。
# next 10 weeks
data_for_bgnbd["n_transaction_10"] = model.predict(t=10,
frequency=data_for_bgnbd["frequency"],
recency=data_for_bgnbd["recency"],
T=data_for_bgnbd["T"])
data_for_bgnbd["alive_prob"] = model.conditional_probability_alive(frequency=data_for_bgnbd["frequency"],
recency=data_for_bgnbd["recency"],
T=data_for_bgnbd["T"])
data_for_bgnbd["CV_10"] = data_for_bgnbd["n_transaction_10"]*data_for_bgnbd["alive_prob"]*data_for_bgnbd["monetary_value"]
data_for_bgnbd_top10 = data_for_bgnbd.sort_values("CV_10",ascending=False).head(10)
go.Figure(go.Bar(x=data_for_bgnbd_top10.index.astype("str"),y=data_for_bgnbd_top10["CV_10"]),layout=go.Layout(title="Top 10 Customr Value in next 10 weeks"))
go.Figure(go.Histogram(x=data_for_bgnbd["CV_10"],nbinsx=10))
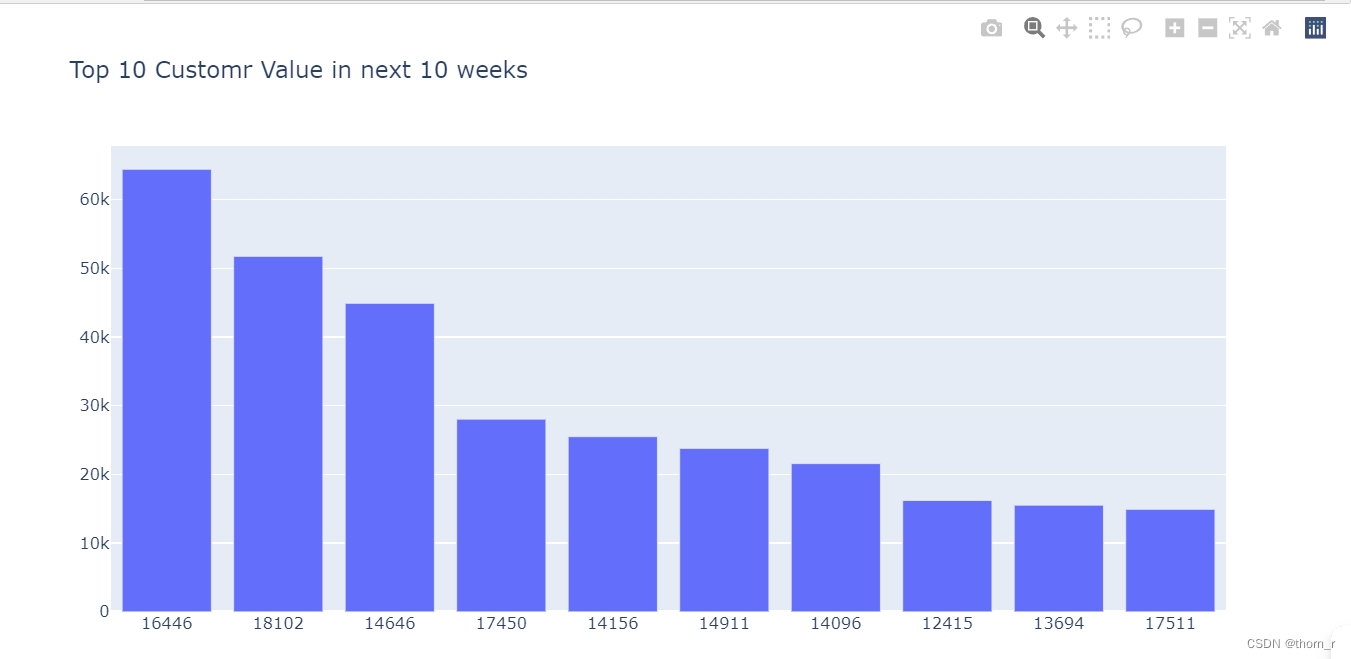
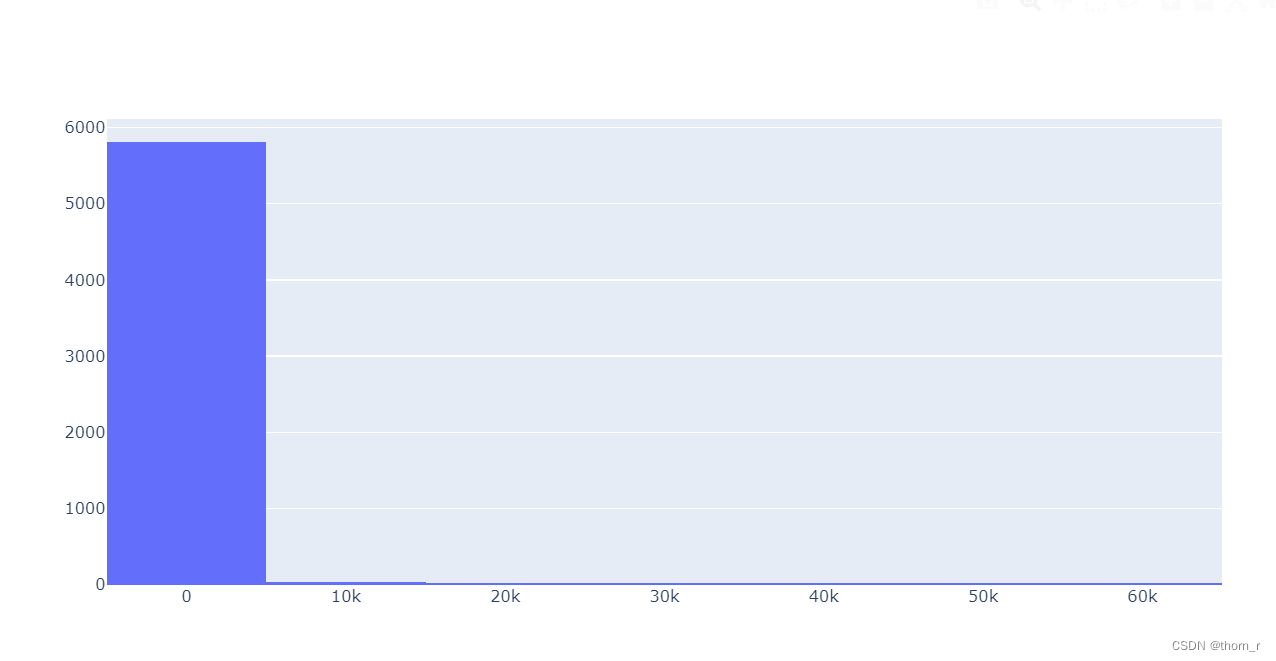
实际上大多数客户未来10周的价值都接近0,大多数的客户价值是由图片1中头部的这些客户驱动的。
需要挽回的客户
接下来,我希望能够找到“在过去有过很多消费,但是在未来可能要流失”的客户,期望能够找到这些更有挽回价值的客户。
data_for_bgnbd["alive_prob_rank"] = data_for_bgnbd["alive_prob"].rank(method="average",ascending=False)
data_for_bgnbd["monetary_value_rank"] = data_for_bgnbd["monetary_value"].rank(method="average",ascending=False)
data_for_bgnbd["rank_sub"] = data_for_bgnbd["alive_prob_rank"]-data_for_bgnbd["monetary_value_rank"]
data_for_bgnbd = data_for_bgnbd.sort_values("alive_prob",ascending=True)
go.Figure(go.Line(x = list(range(data_for_bgnbd.shape[0])),y=data_for_bgnbd["alive_prob"]),layout={"title":"Probability of Alive in next 10 Weeks"})
data_for_bgnbd_sub = data_for_bgnbd.sort_values("rank_sub",ascending=False).head(10)
data_for_bgnbd_sub
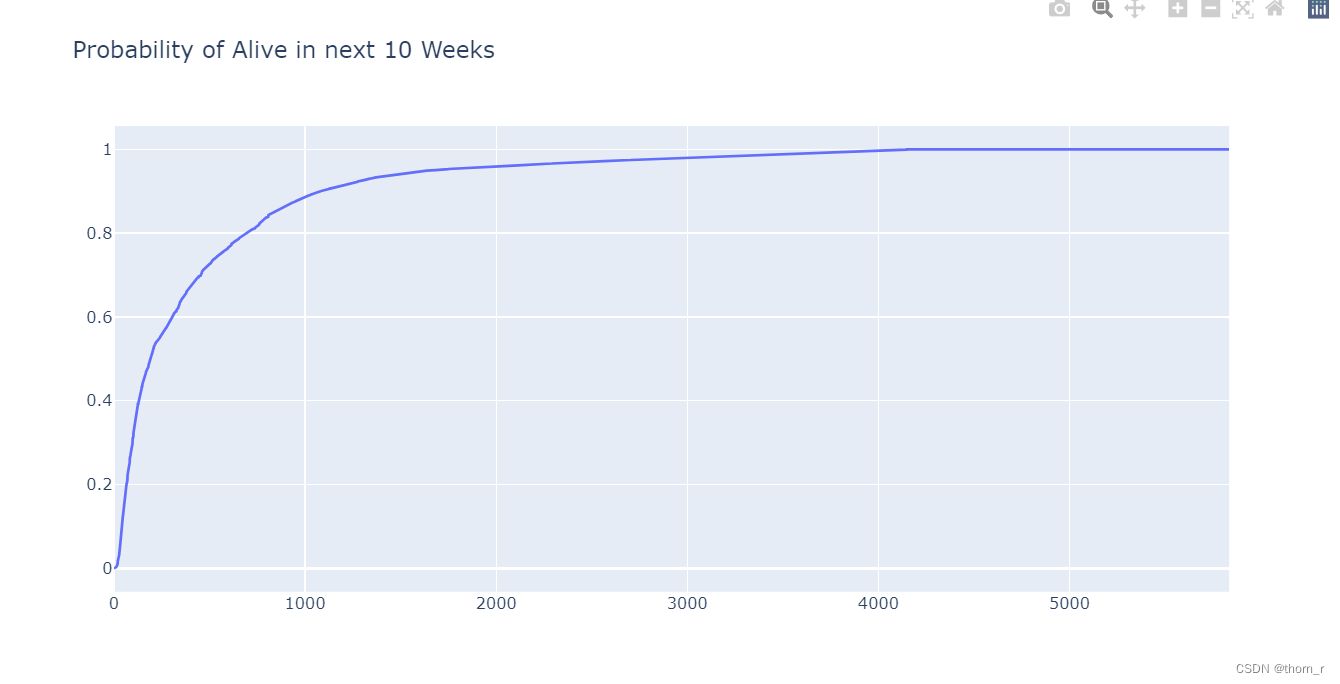
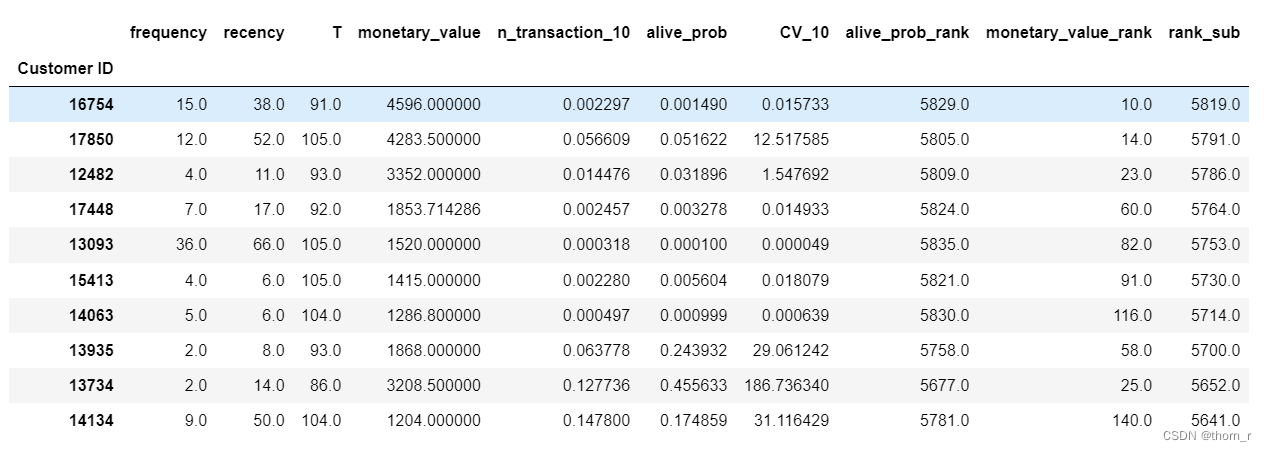
我将所有的顾客根据生存概率与历史消费分别进行了排名,将2个排名相减获得了这些顾客们生存概率排名-历史消费排名的差值。最后将差值进行排名,上表所显示的前10名可以看出,其历史消费很高,但是未来的生存概率很低。像这样的顾客或许更应该被挽回。
追加:关联规则分析
关联规则分析为的就是发现商品与商品之间的关联。通过计算商品之间的支持度、置信度与提升度,分析哪些商品有正向关系,顾客愿意同时购买它们。
from pyspark.ml.fpm import FPGrowth,FPGrowthModel
df_for_association = data_filtered.groupby(["StockCode","Invoice"]).agg(F.sum("Quantity").alias("Quantity")).groupby("Invoice").agg(F.collect_list(F.col("StockCode")).alias("items"))
product_dict = data_filtered.groupby(["StockCode"]).agg(F.max("Description").alias("Description")).toPandas()
model_association = FPGrowth(minSupport=0.01,minConfidence=0.1)
model_association = model_association.fit(df_for_association.select("items"))
res = model_association.associationRules.toPandas()
code_desc = {product_dict.loc[i,"StockCode"]:product_dict.loc[i,"Description"] for i in product_dict.index}
def code_2_desc(series):
res = series.copy()
for i,x in enumerate(res):
tmp = []
for stock in x:
tmp.append(code_desc[stock.strip()])
res[i]=tmp
return res
res["antecedent"] = code_2_desc(res["antecedent"])
res["consequent"] = code_2_desc(res["consequent"])
res.sort_values("support",ascending=False).head(10)

上表是支持度(support)前五的商品组合(每2条实际上是同一组商品)。支持度指的是2件商品同时出现的概率。
P
(
A
∩
B
)
P(A\cap B)
P(A∩B)
res.sort_values("confidence",ascending=False).head(5)

上表是置信度(confidence)前5的商品组合,置信度指的是当商品A被购买时,商品B也被购买的概率。
P
(
B
∣
A
)
=
P
(
A
∩
B
)
P
(
A
)
P(B|A)=\frac{P(A\cap B)}{P(A)}
P(B∣A)=P(A)P(A∩B)
res.sort_values("lift",ascending=False).head(20)

上表是提升度(lift)前十的商品组合(每2条实际上是同一组商品)。 提升度可以看做是2件商品之间是否存在正向/反向的关系。
从表中我们可以看出,顾客最常购买的不同商品组合实际上就是相同商品的不同颜色/设计。
感谢您能够看看完我整个的分析,如果有发现什么不足或是错误的地方,请不吝赐教;如果本文有帮到你,我将不胜荣幸。期待与您在评论区相见。

















 1001
1001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









