







此次的数据集来自kaggle的关于在线零售业务的交易数据,该公司主要销售礼品,大部分出售对象是面向批发商。
数据链接
数据集字段介绍
数据包含541910行,8个字段,字段内容为:
InvoiceNo: 订单编号,每笔交易有6个整数,退货订单编号开头有字母’C’。
StockCode: 产品编号,由5个整数组成。
Description: 产品描述。
Quantity: 产品数量,有负号的表示退货
InvoiceDate: 订单日期和时间。
UnitPrice: 单价(英镑),单位产品的价格。
CustomerID:客户编号,每个客户编号由5位数字组成。
Country: 国家的名称,每个客户所在国家/地区的名称。
数据处理
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import seaborn as sns
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
import datetime
plt.rcParams['font.sans-serif']=['Simhei']
data=pd.read_csv('data.csv')
data.info()
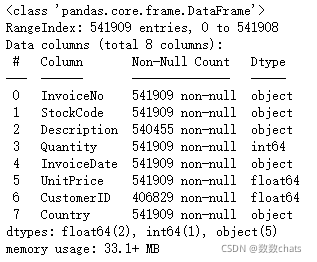
缺失值处理
#缺失值占比
data.isnull().mean()

CustomerID 约25%的数据记录是空的,这意味着有约25%的数据记录没有分配给任何客户。而我们不可能把这些记录的值映射到任何客户。所以这些对于目前是没有用的,因此我们可以将其删除。
data.dropna(axis = 0, subset = ['CustomerID'],inplace = True)
删除重复值
print('重复的数据条目: {}'.format(data.duplicated().sum()))
data.drop_duplicates(inplace = True)
异常值处理
data.describe()
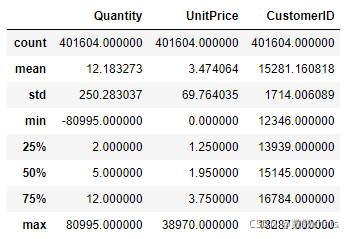
quantity指的是购买的数量,不可能存在负数;UnitPrice是单价,不可能存在负值。将异常值直接删除。
data=data.loc[(data['Quantity']>0) & (data['UnitPrice']>0)]
RFM划分用户群
data['total_sales'] = data['UnitPrice'] * data['Quantity']
rfm=data.groupby(['CustomerID']).agg({
'InvoiceDate':'max',
'InvoiceNo':'nunique',
'total_sales':'sum'
}).sort_index()
rfm.InvoiceDate=rfm.InvoiceDate.dt.date
#创建一个新的变量,计算R(recency)的时候用
Nowdate=max(rfm 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 880
880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









