







 本文通过分析kaggle上的E-Commerce Data数据集,进行了数据清洗和预处理,包括查看数据类型、处理空值、删除重复值、处理标点符号和大小写问题,以及对特定特征如Countries、负值Quantity、InvoiceNo等的深入分析。通过对数据的探索,发现并解决了Quantity的负值、描述信息的格式问题和CustomerID的缺失值等挑战。
本文通过分析kaggle上的E-Commerce Data数据集,进行了数据清洗和预处理,包括查看数据类型、处理空值、删除重复值、处理标点符号和大小写问题,以及对特定特征如Countries、负值Quantity、InvoiceNo等的深入分析。通过对数据的探索,发现并解决了Quantity的负值、描述信息的格式问题和CustomerID的缺失值等挑战。
熟练一下pandas和数据处理
项目地址
参考:Python数据清洗指南
Customer Segmentation with XGBoost (97.92%)
项目描述:
这是一个跨国数据集,包含2010年12月1日至2011年12月9日期间英国注册的非商店在线零售的所有交易。该公司主要销售独特的万能礼品。公司的许多客户都是批发商。
Part 1 分析数据,探索数据,清洗数据
导入数据
data = pd.read_csv("C:\\Users\\Nihil\\Documents\\pythonlearn\\data\\kaggle\\E-Commerce Data.csv",encoding='ISO-8859-1',dtype=str)
## encoding = "ISO-8859-1" -- 用什么解码,一般会默认系统的编码,如果是中文就用 "utf-8"
1. 分析数据
1.1查看数据类型
print(data.info())
Out:
Data columns (total 8 columns):
InvoiceNo 541909 non-null object
StockCode 541909 non-null object
Description 540455 non-null object
Quantity 541909 non-null object
InvoiceDate 541909 non-null object
UnitPrice 541909 non-null object
CustomerID 406829 non-null object
Country 541909 non-null object
dtypes: object(8)
1.2数据具体
print(data.head())

图中可获取的信息:
- InvoiceDate的时间出现具体时分,可以删去(时序数据的处理)
- Description大概率是人工填写的数据,一般都会有比较多格式问题。比如第一行就出现了‘-’。
1.3数据描述
print(data.describe())
Quantity UnitPrice
count 536641.000000 536641.000000
mean 9.620029 4.632656
std 219.130156 97.233118
min -80995.000000 -11062.060000
25% 1.000000 1.250000
50% 3.000000 2.080000
75% 10.000000 4.130000
max 80995.000000 38970.000000
Quantity出现了负值。显然不正常
1.4 转换数据类型
data['CustomerID'] = data['CustomerID'].astype('int64')
print(data.dtypes)
2.检查空值
2.1第一种方法
out = data.isnull().sum().sort_values(ascending=False)
Out:
CustomerID 135080
Description 1454
Country 0
UnitPrice 0
InvoiceDate 0
Quantity 0
StockCode 0
InvoiceNo 0
dtype: int64
2.2用图表示
plt.figure(figsize=(5,5))
data.isnull().mean(axis=0).plot.barh()
plt.title("Ratio of missing values per columns")
plt.show()
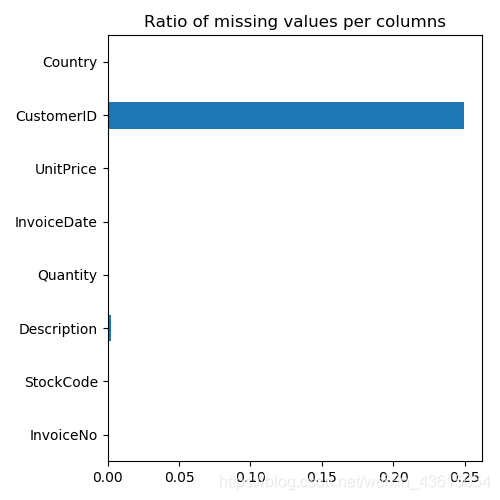
2.3 查看缺失数据的比例
missing_percentage = data.isnull().sum()/data.shape[0]*100
print(missing_percentage)
InvoiceNo 0.000000
StockCode 0.000000
Description 0.268311
Quantity 0.000000
InvoiceDate 0.000000
UnitPrice 0.000000
CustomerID 24.926694
Country 0.000000
dtype: float64
2.4 缺失值描述
2.4.1 深入了解缺失数据,看到哪些行缺失
nan_rows = data[data.isnull().T.any().T]
print(nan_rows.head(5))
Out:
InvoiceNo StockCode ... CustomerID Country
622 536414 22139 ... NaN United Kingdom
1443 536544 21773 ... NaN United Kingdom
1444 536544 21774 ... NaN United Kingdom
1445 536544 21786 ... NaN United Kingdom
1446 536544 21787 ... NaN United Kingdom
- any(iterable): 查看iterable (元组或列表)是否有空值,如果有空值,返回True
Python any() 函数
data[data.isnull().T.any().T]的目的:
可以返回哪一行出现了空值。
一个详细讲解:How to return rows with missing values in Pandas DataFrame
2.4.2 挑出缺失的某一行,查看其信息
print(data[data.InvoiceNo == '536414'])

print(data[data.InvoiceNo == '536544'][:5])

缺失值主要存在于CustomerID,这个特征好像无法用其他方式处理。所以去掉。
去掉缺失值的列方法
data = data.drop(['CustomerID'],axis=1)#简单粗暴去掉这一列了
print(data.columns.values)
['InvoiceNo' 'StockCode' 'Description' 'Quantity' 'InvoiceDate'
'UnitPrice' 'Country']
再检查一遍
plt.figure(figsize=( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1852
1852

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









