







DBMS Implementation 笔记 01
本篇课程主要围绕 DBMS 的底层实现和建立。至于常规的 SQL 语句和数据库其他相关操作,我们只会在第一篇笔记中进行粗略的回顾,默认读者已经掌握相关的知识。同时,课程中使用的所有数据库均为 PostgreSQL
DBMS Overview
首先回顾一下,什么是 DBMS。DBMS 的全程是 Data Base Management System(数据库管理系统)。可以明确地看到,DBMS 是一个 “管理系统”,换句话说,它是用以管理数据库(DB, Data Base)的一个软件系统。因此,我们需要明确地将 DBMS 和 DB 进行区分。
我们可以将 DBMS 简单地看作一个黑匣子:
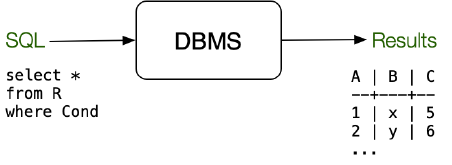
将一系列 SQL 查询喂给这个黑匣子,得到一系列元组 (Tuple) 组成的结果。这个黑匣子支持以下操作:

需要注意的是,上述地这些操作在 DBMS 种会有多种不同地实现方式以供选择。 以 SELECTION 操作为例:DBMS 提供的 SELECTION 操作并不是只有一个版本,有线性扫描 (Linear Scan),使用索引(比如 B-Tree)等。所以我们需要铭记,上述的这些操作都会有不同的版本/实现方式,通过不同的组合我们可以得到相同的结果,但是运行的效率是会有显著差异的,这主要体现在产生的“中间结果”的规模差异上。
如果我们跟随一个 SQL 查询进入 DBMS 进行观察,就可以看到它会经过以下流程:
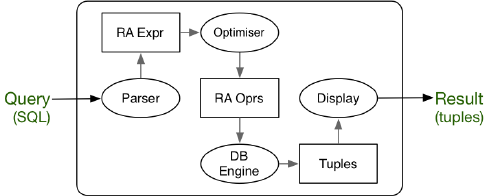
整个过程简单来说就是:将 SQL 查询转换为一系列的关系操作表达式 (Relational Algebra Expression),DBMS 会选择较为高效的一个指令组合执行,最后得到一系列 Tuples 作为结果返回。

下面给出 2 个例子来具体理解方式的选择:
例 1:
给定一个 SQL 查询:
select s.sid, s.code
from Course c join Subject s on (c.sid=s.sid)
join Enrolment e on (c.cid=e.cid)
group by s.sid, s.code
having count(*) > 100;
DBMS 会将这个查询映射为下面两种 RA 表达式组合:
这两者的差异主要在于 Join 的顺序,我们可以根据“中间结果”的规模来判断优劣。可以看到,如果先 Join Enrolment,中间结果将会有 3 种属性 (Attributes),但是如果先 Join Subject
中间结果有 2 种属性,这就意味着消耗的时间和空间会更小,因此更优
例 2:
给定一个 Execution Plan:σc (R ⨝d S ⨝e T)
可以得到如下所示的 3 种 RA 表达式组合:
此时第三组的代价是最低的,这也体现了对于查询优化的一种启发性思想:“优先使用 Filtering 操作来减小中间结果的规模”


最后,我们来看看 DBMS 的具体结构

上述对于 SQL 查询的解析、映射以及优化都在最顶层的 Query Evaluation 实现。
到此为止,对于一般的 DBMS 使用者来说,了解了 SQL 语句以及这些内容就已经足够了。接下来的笔记会根据这幅结构图,从下到上去看一看每一层的具体实现与操作。
PostgreSQL
PostgreSQL 即我们常说的 PSQL,对于这个数据库,我们现在只需要进行一个大致的了解。在这里我们只提一下它比较关键的 3 个地方。
第一,PostgreSQL 使用 MVCC (multi-version concurrency control),多版本并发控制机制来管理并发操作。即会有多个版本的数据库(数据库对象)同时存在,每个 Transaction 开始时,都只能看到对于其来说 “合法” 的版本,并在其上进行操作。该机制的好处在于,由于数据库会有多个版本,所以多个用户之间的 writer 和 reader 之间不会相互干涉,降低了 “锁(Lock)” 的需求。但缺点在于需要额外的存储空间以存储 “旧版本” 的 Tuples,同时每当从数据库中获取了一个 Tuple,都需要检查当前进行的 Transaction 是否被允许访问该元组。因此,旧版本无法被消去,需要一直维持。这一部分的内容会在后续的笔记中进行更详细的介绍。
第二,PostgreSQL 有一个定义完善且开放的可扩展性模型。因此,用户可以自定义数据类型 (Data Type),以及与该数据类型配套的一系列操作和算子。
第三,PostgreSQL 种,所有数据库对象(Relation, Attribute, Tuples, Constraints, Assertions, Views, Triggers…)的元数据 (Metadata) 全部都被存储在 Catalog 种,而 Catalog 也是以表格(Table)的形式表现的。

上图就是 PostgreSQL 的文件系统结构。更通俗的说就是你在安装了 PostgreSQL 之后,电脑上就会出现上图中的这些路径 (Directory)。
这里我们主要说一下 base 和 pg_wal 以及 base 下的 db 三个路径。base 路径下存储了所有的 Data Base,其下的每一个 db 就是一个 Data Base,对应一个路径,在这个路径下,包含众多 Relations/Tables,每个 Relation/Table 可能由多个/单个文件 (Data File) 组成。
每当我们对 Data Base 进行操作时,都会留下操作记录,这些记录就保存在 pg_wal 。这些操作日志可以帮助进行回滚/恢复等操作。每个日志文件大约有 16 Megabytes,但是我们不能对它们进行随意的改变,这样会导致系统崩溃,因为每当我们运行 Data Base Server,它做的第一件事就是检查所有的日志文件以发现有哪些操作需要进行,一旦有日志缺失,Server 就会认定无法还原,就不会启动。
Storage Management

这属于 DBMS 结构的最底层。DBMS 种的 Storage Management 主要:
- 提供数据视图作为页面 (Pages) /元组 (Tuples) 的集合。
- 从数据库对象(例如 Table)映射到磁盘文件
- 管理与磁盘存储之间的数据传输
- 使用缓冲区 (Buffer) 来最大程度地减少磁盘/内存传输
- 将加载的数据解释为元组 (Tuples) /记录 (Records)
下图是一个 SQL Query 从顶层到底层的一个完整流程:

Buffer Pool(缓存池)

在前面我们已经了解了 DBMS 中的存储管理(Storage Management)模块,该模块会访问存储于磁盘上的数据(Stored Data),它会计算出特定表格(Relation/Table)对应的文件(File),并且从磁盘上抓取所需的数据,这些数据以 “块 (Blocks/Pages)” 为单位。这些数据最终都会到达 Files and Access Methods,它将以每次一块 (One page a time) 的形式来处理这些数据。
而在存储管理(Storage Management)和 Files and Access Methods 之间的就是缓存管理(Buffer Management)模块。这个模块会将一些在未来使用频率更高的数据存储在内存 (Memory) 中,以方便读取和操作,降低磁盘 I/O。通过这样的描述,我们可以得到缓存池(Buffer Pool)的意义:
- 将一些数据块(Pages)保存在内存(Memory)中,以便于后续的再次使用,从而避免反复从磁盘读取
- 主要为访问模块(Access Method)所用,用以应对读(Read)/ 写(Write)数据块以及顺序扫描(Sequential Scan)等
- 主要使用一些文件管理函数(File Manager Function)去访问数据文件
可以用下图来表示其基本功能:

缓存池中常用的一些 API: request_page(pid), release_page(pid), … 一般会用 request_page() 替代 getBlocks(),release_page() 替代 releaseBlocks()
缓存池中的数据结构:
- 用 “帧(Frame)” 来表示一个 “块(Pages/Blocks)” 的集合 - Page frames[NBUFS]
- 每个 “路径(Directory)” 对应一个 “帧(Frame)”,并且会为我们提供 “帧(Frame)” 中内容的一些信息 - FrameData directory[NBUFS]
上述的两个数据结构可用下图表示:

可以看到,Frame 中包含了从磁盘中读取的数据,这些数据的相关信息会被保存在 Directory 中,这些信息包括:
- Frame 包含了哪些 Pages,以及 Frame 是否为空
- 自从被载入之后,是否有被修改过(是否存在 Dirty Bits)
- 当前有多少个事务 (Transaction) 正在使用其中的 Pages (Pin Count)
- Page 最近一次被访问的时间戳,这有助于系统判断是否需要将一部分 Pages 替换,可以将不常用的 Pages 进行替换
PostgreSQL Buffer Manager
对于 PostgreSQL 的 Buffer Manager,有两个特别重要的点需要注意:
- PostgreSQL 为所有的后端 (Backends) 提供了一个共享的内存缓冲池
- 所有访问方法都通过缓冲区管理器 (Buffer Manager) 从磁盘获取数据
当 PostgreSQL Server 运行时,它会将内存 (Memory) 中的一大块区域用作缓存区(Buffer)。同时,每个后端 (Backend) 都可以使用 Buffer Code 去为自己请求一个私有的缓冲池 (Private Buffer Pool)。PostgreSQL 中的 Buffer Pool 由以下几个组成部分:
- BufferDescriptors:在一个缓冲池(Buffer Pool)中,会有多个缓冲区(Buffer),这里就需要一个由多个 Buffer Descriptors 组成的数组,每个 Buffer Descriptor 会描述存储于 Buffer Blocks 中的对应的 Page Frame
- BufferBlocks:一个定长的数组,该数组由 8KB 的 Frame 组成
- Buffer:用以表示上面两个数组的 Index Values。比如,一个 Buffer 类型的变量数值为 1,就表示其为 Buffer Pool 中的第一个 Buffer。局部缓冲区(Local Buffer)会有负的 Buffer Index Value

如图所示,在内存中,我们会有一大块共享区域作为 Buffer Pool,所有的后端进程都可以使用 request_page() 和 release_page() 访问这块区域。如果某个后端想要创建其自己的私有 Buffer Pool,需要将其存在该进程自己的局部内存中。
Page Internals
从磁盘和缓冲管理的角度来看,数据文件 (Data File) 由一系列的 blocks/pages 组成,page 可通过 PageID 来进行访问,每个 page 包含 0 或多个 tuples。这些 records/tuples 可以借助 TupleID/RecordID/RID 来进行访问。TupleID = (PageID + TupleIndex)。
- PageID:告诉我们该 tuple 在哪个 page 中
- TupleIndex:告诉我们该 tuple 在 page 的哪个位置
所以借助上述两个参数,我们可以访问任意一个 tuple。我们可以用下图来表示上述的结构:
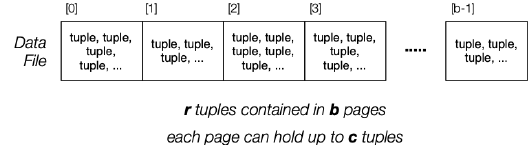
这里共有 b 个 pages,每个 page 至多包含 c 个 tuples,总共有 r 个 tuples。在 PostgreSQL 中,每个 Data File 对应一个表 (Table/Relation),换言之,一个 Data File 中的所有 tuples 都有着相同的 attributes,即同样的结构,但是,不一定有着相同的尺寸,因为可能会有空值。
本质上来说,Page 是一个由字节 (Byte) 组成的数组,但是我们希望将其解释为 tuples 的集合。因为我们需要知道,绝大多数对于 page 以及 tuples 的操作都是借助 PageID 和 TupleIndex 实现的,比如(时刻牢记,TupleID/RecordID = (PageID + TupleIndex)):
request_page(pid)- 通过使用 PageID 来获取一个 pageget_record(rid)- 通过使用 TupleID 来获取一个 tuple/recordrid = insert_record(pid, rec)- 添加一个新的 record/tupleupdate_record(rid, rec)- 更新一个 tuple/recorddelete_record(rid)- 从 page 移除一个 record
下面来看一个 page 的具体结构,page = tuples + 保证 tuples 可以被找到的其他数据结构。
对于尺寸固定的 tuples/records (fixed-length reocrds),使用 record slots:

Packed Page 是一种比较理想的存储情况,所有的 tuple 都被打包在该 Page 的最前面的一方空间,这里的 N 是一个计数器,用以记录当前有多少空间被使用了。另外一种方式就是 Unpacked Page,这种情况下的存储显得更自由,但相对的,我们需要一种方式来记录每个 slot 是否存储了一个 tuple,这就需要使用位图 (Bitmap),它会用一个 bit 来显示每个 slot 的使用情况。
此时的添加(Add)操作就是在第一个可用 slot 中放置新记录。而删除 (Delete) 操作也类似,不过需要根据存储方式的不同有所区别。
对于尺寸变化的 tuples/records (variable-length records),使用 slot directory:
与之前一样,我们同样可以将变长 tuples 存储在一起或者分散存储,即:
- compacted (紧凑存储):仅有一方空闲空间,所有的 tuple 都被存储在一起
- fragmented (零散存储):tuples 自由存储,不需要存储在一起
在实际情况中,通常会结合两者使用,即平时使用 fragmented,这样方便维护,比如删除某个 tuple 时,只需要将其所在区域标记为空闲即可。但是当删除了一定数量的 tuples 之后,我们可以去进行 compact。 特别需要注意的一点是,在使用 slot directory 时,tuple 的 index 始终不会变化,即使 tuple 会在 page 中到处移动,比如某个 tuple 被标记为第二个 tuple,那么不管该 tuple 在 page 内如何移动,都不会改变它是第二个 tuple 的事实,即 TupleID 不会改变。

上图是一个 Compacted Free Space 的示例,可以看到,所有的 tuple 都被存储在一方空间,free space 有自己的一方空间。Slot Directory 中存储了所有 tuple 的位置信息。值得一提的是,Slot Directory 的尺寸会随着 tuple 的添加而越来越大。

上图是一个 Fragmented Free Space 的示例,可以看到,我们没有一整块空闲区域。
下面来看 Compacted Free Space 内部随着 tuple 的添加而变化的过程:
首先,最开始的情况如下图所示:
nrecs=0 表示目前没有存入任何一个 tuple。freeTop=1023 表示当前的空闲空间。
当我们已经存入 6 个 tuples,马上要存入第 7 个时:
存入第 7 个(大小为 80 Bytes)之后,变为:
接下来同样看看 Fragmented Free Space 的变化情况:
首先一样是起始状态:
同样存入 6 个 tuples:
现在存入第 7 个:
这种情况下,FreeList 就需要存储所有空闲区域的位置以及各自的大小。除此以外,当要存入新的 tuple 时,需要找到最小的能够容纳该 tuple 的 free space 以进行存储






既然我们已经清楚了 tuple 如何存储于 page 当中,那么一个很重要的点在于,我们该如何知道一个 page 最多能容纳多少个 records? 这个问题涉及很多的因素,比如:
- page size:page 的尺寸,典型的值有 1KB, 2KB …
- record size:record/tuple 的尺寸
- page header size:page 头文件的尺寸(4B - 32B)
- slot directory:取决于有多少个 tuples
我们用 R 来表示 tuple 的平均尺寸,C 来表示容量,SlotSize 表示 SlotDirectory 中的 Slot 尺寸,那么就有如下的一个关系式:
有时我们会发现无法向一个 page 存入一个 tuple,这可能有多种原因:
- 没有对应尺寸的 Fragmented Free Space
- 总体的 Free Space 不足
- tuple 尺寸大于 page
- page 中的 free directory slot 不足
对于第一种情况可以尝试 Compact page 中的 Free Space,如果还不行需要一个备用计划。对于后三种情况,具体如何解决取决于 File Organization,可能需要使用 Overflow File
PostgreSQL Page Representation
在 PostgreSQL 中,每个 page 的尺寸为 8KB,它包含:
- 头文件 (Header File)
- tuple 的 (offset, length) 对组成的数组
- 空闲空间 (Free Space Region) - 在 array 和 tuple data 之间
- tuple data
- 存储一些特殊数据(比如索引数据)的区域
PostgreSQL 主要使用 Compacted Free Space 策略:

每个 tuple 的位置都存储在 offset 中,尺寸用 length 表示
PostgreSQL 有两种 page:
- Heap Page 包含 tuples
- Index Page 包含 index entries
最主要的区别在于,Heap Page 包含的 tuples 多为变长的,而 Index Page 包含的 index entries 一般相比 tuple 更小,且是定长的 (Fixed-length)
TOAST = The Oversized-Attribute Storage Technique (超大属性存储技术)
用以处理大属性值的存储,怎么判定属性过大呢?如果该属性值 > 2KB,那么就属于超大属性,比如 long text
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-d652QFNG-1620640157133)(E:\课程文件\COMP9315\Week 2\Note\PostgreSQL Page Internals 2.bmp)]
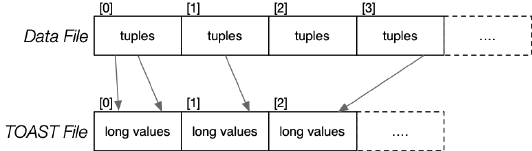
某些 tuple 可能会包含超大属性,这是就需要访问 TOAST File。换言之,超大属性的值会存储在主要数据文件之外。PostgreSQL 可以对 TOAST 中的值进行压缩,同时,TOAST 中的超大属性值并不是以一个长序列 Bytes 进行存储,而是分为多个 2K 的块















 2219
2219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









