







DBMS Implementation 笔记 02
Tuple Representation
再次强调:一个数据库 (Database) 中的表格 (Relations/Tables) 用一个或多个数据文件 (Data File) ,每个文件由一系列 pages/blocks 组成,每个 page/block 包含多个元组/记录 (tuples/records)。
但实际上,tuple 和 record 还是存在一定区别的。本节就需要对这种区别进行了解。首先是 tuple,tuple 实际上基于 schema 的一系列属性值 (Attributes):
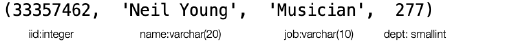
而 record 则是一个由字节组成的序列,包含来自一个 tuple 的所有数据:

records 中的字节需要相对于模式 (Schema) 进行解释以获得 tuple。所以,record 就是存储于 page 中的实际数据,而 tuple 使我们作为用户希望看到的数据呈现的形式。
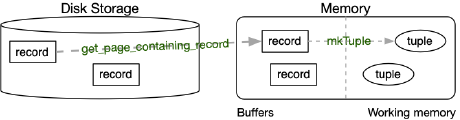
通过从磁盘 (Disk) 中读取包含 record 的 page,得到我们想要的 record,将其读入内存 (Memory),然后将其释译为 tuple。这就需要一个合适的释译方式,而进行释译的信息可能会被存储在各种地方,比如:
- 包含在 DBMS catalog 的 schema 数据中(Fixed-size Record)
- 存储在 page directory 中
- 存储在 record header 中
- 一部分存储在 record header,一部分存储在 schema 中
对于变长 record (variable-length record),需要将一部分信息存储在 record 或 page directory 中,比如某个 attribute 的类型为 varchar(20),这就会使得每个 record 的尺寸不定,那么我们就需要将这种信息记录在和 record 直接相关的某些地方,page directory/record 是很直觉的选择。
现在,我们就知道了从数据库中使用某个 tuple 的具体过程:首先从磁盘中读取包含所需 record 的 page,然后使用 mkTuple(rel, rec) 将 record 释译为 tuple。之后使用 getTypField(Tuple i, int t) 来获取其中的各 attribute 值。
Fixed-length Records
对于定长 records,一种比较可能的格式如下图所示:
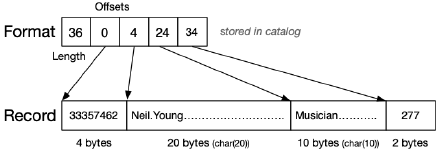
即:
- Record 的格式信息存储在 catalog 中,格式为 (length, offset1, offset2, …)
- Record 的具体数据存储在某个 page 中
由于格式信息 (Format Info) 需要经常使用,所以缓存在内存中
Variable-length Records
对于变长的 records,有 3 种方式在其中表示每个 attribute 的起止:
-
用一个前缀来表示每个 attribute 的长度:

-
用一个后缀来表示每个 attribute 的终止:
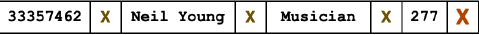
-
用一个 offset 数组放在开头来表示(这里第一个 offset 为 10 是因为 header 中存储了 5 个数字,每个数是 2 Byte,因此占用了 10 Bytes,所以第一个 attribute 从 10 开始):

下面具体来看 tuple 的结构。tuple 实际上一个由多个字段描述器 (Field Descriptor) 组成的列表,它包含:
- 一个字段描述器列表,
FieldDesc它给出 (offset, length, type) 信息 - 指向 record 实例数据的指针

具体形式如下图所示:

注意,这里的 data_off 表示指向实例数据的指针的位置,而 fields 中的 offset 指的是在实例数据 (record) 中,每个 attribute 的起始位置
当然也可以直接将 tuple data 添加在 tuple structure 中:
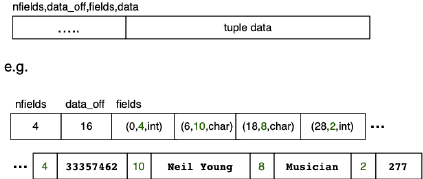
PostgreSQL Tuples
PostgreSQL 通过以下几个要素实现 tuple:
- 连续的内存块 (a contiguous chunk of memory)
- 以 header 开头 (header 包含字段的数量等)
- 接着是数据值 (一个数据序列)
HeapTupleData 包含一个存储的 tuple 的所有信息。

具体的结构如下图所示:

简单的来说,每个 tuple = header + data。 tuple 的具体结构如下:

这里解释一下什么是 command ID,每个事务 (Transaction) 都由一系列 command 组成,其中进行了删除操作的 command 的 ID 被记录下来,之后留下一个指向新的 tuple 版本的指针。所以上述结构中的前三项决定了 MVCC 下 tuple 的可见性
Relational Operations
回顾一下 DBMS 的结构:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KliyOVMl-1620641090092)(E:\课程文件\COMP9315\Week 3\Note\Relational Operations.bmp)]
我们目前为止已经了解了如何从磁盘获取数据,以及在 buffer 中如何管理这些获取的数据(即 Disk/File Management 和 Buffer Management)。现在我们来关注 Access Methods 和 Relational Operators。
Relational Operations
回顾一下 DBMS 的结构:

我们目前为止已经了解了如何从磁盘获取数据,以及在 buffer 中如何管理这些获取的数据(即 Disk/File Management 和 Buffer Management)。现在我们来关注 Access Methods 和 Relational Operators。
我们已经知道,DBMS 的核心就是一个关系引擎 (Relational Engine),用以实现 SELECTION, PROJECTION, JOIN, SCANNING, SORTING 等逻辑操作。现在我们需要把目光放在检查实现每个操作的方法,为每个实现构建一个成本模型 (Cost Model) 以及确定每种方法最有效的时间上 (Query Optimizer) 。
再次回顾一下几个专业术语:
- Tuple:服从某些模式 (schema) 的数据值集合 ≈ Record
- Page = Block:一系列 Tuples + Management Data,这是最小的读/写单位
- Relation = Table: 由一到多个 File 组成,File 是一系列 Tuples 的集合
每当我们进行一次查询 (Query) 时,实际上是从两个维度定义了查询方法 (Query Method):
- 关系逻辑操作 (Relational Operation):比如是 SELECTION, PROJECTION 还是 JOIN 等
- 访问方式 (Access Method):定义了文件结构,是索引式 (Indexed),哈希 (Hashed) 等
举一个具体的例子:
我们最感兴趣的莫过于查询方法的代价 (Cost)。同时,DBMS 中的 Relational Operators 由一个 SQL Query 触发,比如:
SELECT ... FROM R WHERE C即为在 Table R 的数据文件 (Files) 中找到满足条件 C 的 Tuples
Cost Model
正如前文所述,我们需要分析不同查询方法 (Query Method) 的代价 (Cost)。这里的代价 (Cost) 可以主要由两部分组成:
- Time cost:执行该查询方法所用的总时间
- Page cost:执行该查询方法过程中读写的总 page 数量
对于我们的代价模型 (Cost Model),我们有一些基本的假设:
- RAM (Memory) 比较小,但是读写速度很快,一次读写一个 Byte
- Disk 比较大,但是读写较慢,一次读写一个 page
在代价分析中,因为 Time cost 会被多种因素影响,比如硬件因素,机器的加载速度等,所以我们更多关注 Page cost。因为识别查询方法 (Query Method) 所施加的工作量很方便,但是它也会受到 Buffering 的影响,比如有多少个 Buffer,选择了什么 Replacement Stragegy。因此,我们在分析 Page cost 的时候,会不考虑 Buffering 带来的影响,简单地认为每次读/写/更新操作都会直接产生 Disk I/O。 需要注意的是,我们的模型只是进行 “粗略” 的估计
Scanning
这一节我们主要来看所有关系逻辑操作中最简单的一种:Scanning。首先看一个最简单的例子:
这里 Table Rel 的文件结构 (File Structure) 为:

上述查询会扫描所有 page 中的所有 tuple,即:
for each page P in file of relation Rel {
for each tuple T in page P {
add tuple T to result set
}
}
因此这里的 Page cost = Number of all pages = b。下面考虑 Data File 拥有 Overflow Page 的情况:

此时的 Page cost = b + bOV (bOV 表示 overflow page 的总数)
目前我们所考虑的都是完全扫描,现在我们来看另一个例子:
这是一个条件查询,我们保证该查询只有一个答案,可能在任意 page 中。

此时,就不需要在进行完全扫描,只要找到匹配的结果,就可以立即终止扫描。即:
for each page P in relation Employee {
for each tuple t in page P {
if (t.id == 762288) return t
} }
这时考虑 Page cost 就会有三种情况:
- 最坏的情况 (Worst Case):完全扫描/找不到答案,Cost=b
- 最好的情况 (Best Case):一发几种,Cost=1
- 平均情况 (Averagr Case):平均扫描半数的 page,Cost=b/2
上述的扫描,我们一般都需要使用迭代器 (Iterator) 来实现,一般 scan 就是一个迭代器的实例:
Scan s = start_scan(Relation r, ...)确定对 Table r 进行扫描,后面的 … 表示可以添加一些条件,比如 WHERE 语句
这里还需要另一个函数来结束扫描:
Tuple next_tuple(Scan s)该函数在访问完最后一个 Tuple 后,会立刻返回 Tuple。如果没有更多的 Tuple 则返回 NULL
下面是一个具体的例子,实现 SELECT name FROM Employee;
DB db = openDatabase("myDB");
Relation r = openRelation(db,"Employee",READ);
Scan s = start_scan(r);
Tuple t; // current tuple
while ((t = next_tuple(s)) != NULL) {
char *name =
getStrField(t,2);
printf("%s\n", name);
}
Scan 实际上是一个指向 Struc Scandata 的指针,这个 Struc 会保有一些进行扫描的关键信息
typedef ScanData *Scan;
typedef struct {
Relation rel;
Page *curPage; // Page buffer
int curPID; // current pid
int curTID; // current tid
} ScanData;
Copying
考虑如下的一个语句:
该语句实际上将一个 Table 中的数据全部复制给一个新的 Table。所以它的实际操作流程为:
make empty relation T
s = start scan of S
while (t = next_tuple(s)) {
insert tuple t into relation T
}
该操作最后得到的 Table T 可能会小于原始的 Table S。其原因在于,原本的 Table S 的 Pages 中,可能会有一些 Tuple 被删除了,它们空出了一部分空间,而在复制的过程中,系统实际上是不断向新的 Table T 中 append Tuple,因此会变得比较紧密 (Compact)。
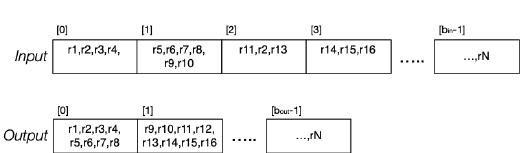
Sorting
现在来看另一种非常常见的逻辑关系操作 - 排序 (Sorting)。在使用 SQL 查询时,可以使用 ORDER BY 来显式地使用查询操作。
但是,某些操作中也会隐式地使用排序,比如:
- 消除重复的元组以进行 projection
- 对文件排序以提高 SELECT 效率
- 实现各种风格的 JOIN
- 使用 GROUP BY 来进行聚合
快速排序等排序方法是针对内存中数据 (In-memory data) 设计的。对于磁盘上的大数据,需要外部排序 (External sort),例如合并排序 (Merge sort)。 下面给出 2 路归并算法的示意图:

首先在每个 page 中进行内部排序,之后再两两归并。在这个过程中,我们于内存 (Memory) 中至少需要有 3 个 buffer:
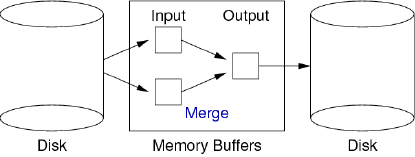
我们假设在内存中,两个 buffer 的合并操作的代价约为 0。上述的这个方法中,很显然我们需要不断进行比较 (Comparision)。因此,我们可以想象一个比较函数 tupCompare(r1, r2, f):
int tupCompare(r1,r2,f)
{
if (r1.f < r2.f) return -1;
if (r1.f > r2.f) return 1;
return 0;
}
在这个函数中,我们指定需要进行对比的两个 tuples,以及按照哪个属性 (attribute) 来进行对比。但是在实际情况中,我们往往需要基于多个属性 (attributes) 来进行对比。
这时函数应当变为:
int tupCompare(r1,r2,criteria)
{
foreach (f,ord) in criteria {
if (ord == ASC) {
if (r1.f < r2.f) return -1;
if (r1.f > r2.f) return 1;
}
else {
if (r1.f > r2.f) return -1;
if (r1.f < r2.f) return 1;}
}
return 0;
}
Cost Analysis
对于一个包含 b pages 的 file:
- 需要 ceiling(log2b) 轮次去进行排序
- 每一轮需要读取 (read) b pages,以及写 (write) b pages
所以,total cost = 2b * ceiling(log2b)
下面来看 n 路归并,在 n 路归并的一开始,需要进行一轮初始化操作:

在这一轮操作中,使用全部的 B 个 Buffer 来读取文件中的 pages,之后对读取的这些 pages 进行内排序,之后将排序后的结果整体打包,存入文件,该文件中,每一个 Run 的尺寸即为 B pages。这一环节就被称为初始 Runs 的生成。输出文件中会有多个这样的 Runs。
接下来,进行递归的合并操作:

此时不再使用全部的 B 个 Buffer,而是使用 B- 1 个 Buffer,这样将 N - 1 个 Runs 进行合并,得到一个新的排好序的 Run,也就是 N-1路归并 (N-1 - way Merge),每个新的 Run 的尺寸即为 N*(N - 1) Pages。之后不断重复此操作,最终得到一个排好序的文件。
N-路归并的总代价为:
2*b * (1 + ceiling(logNb0))
这里的 1 就是初始轮次,b0 = ceiling(b/B), N = B-1















 1015
1015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









