







《迁移学习问题与方法研究》-清华龙鸣盛博士学位论文研读(一)
第一章 绪论
迁移学习(Transfer Learning),或称归纳迁移,领域适配,是机器学习中一个重要问题。其目标是将某个领域或者任务上的知识或者模型应用到不同但是相关的任务或者领域中。
1.1 研究背景和意义
迁移学习是机器学习的前沿领域之一,有充足的理论和应用价值:
-
理论价值
1.1 解决标注数据稀缺性
1.2 非平稳泛化误差分析
经典统计学习和PAC需要服从独立同分布,但在非平稳环境中,不同数据领域不服从独立同分布。广义上看,迁移学习是经典学习在非平稳环境上的推广。 -
应用价值
1.1 自然语言处理
在NPL和文本挖掘都有很好的应用,例如从TWiKipedia的长文本到twitter的短文本,从WWW的网页知识到Flicker的图像信息。
1.2 计算机视觉
已有标签源域数据和无标签目标域数据的不同数据属性和分布特性。比如光照特性,模糊,大雾。
1.3 医疗健康和生物信息学
在医疗健康和生物信息学领域,对数据进行标注代价极高(需要专业医师或生物学家给出),因而标注数据十分宝贵且十分稀缺
1.2 问题描述

1.3 国内外研究现状
- 迁移学习类型
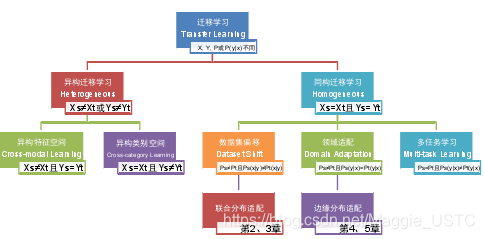
迁移学习类型
| 同构or异构 | 具体类型 | 分布情况 | 应用 |
|---|---|---|---|
| 异构迁移 | 异构特征空间 | 特征空间不同 | 跨语言文本搜索 |
| 异构迁移 | 异构类别空间 | 类别空间不同 | 文本挖掘 |
| 同构迁移 | 数据集偏移 | 领域间的边缘概率分布和条件概率分布都不相同即 | 较难的迁移学习场景 |
| 同构迁移 | 邻域适配 | 领域间边缘概率分布不同 | 侧重目标领域任务上的学习性能 |
| 同构迁移 | 多任务学习 | 域间条件概率分布不同 | 侧重学习算法在所有领域任务上的综合性能 |
在异构特征空间进行迁移学习,通常必须依赖领域特定的先验知识,包括特
征空间之间的关联关系(如双语词典)、多模数据每个视图之间的对应关系(如网
页中的文本和图像)、或社交关联关系(如文本和图像的情感评价来自同一个用
户),等等。
数据集偏移通常要求目标领域存在少量标注数据;邻域适配仅要求辅助领域存在标注数据;
多任务学习多任务学习要求每个任务都存在部分标注数据。
- 迁移学习方法
本节对统计机器学习领域与迁移学习相关的已有工作进行综述,主要侧重无监督迁移学习即目标领域没有标注数据的迁移学习任务。涉及两类主流方法:实例权重法和特征表示法。
2.1实例权重法
源域和目标域的生成概率分布不知道,希望进行加权之后源域和目标域概率分布更加相似。缺陷:希望源域和目标域有相似的分布。
2.2 特征表示法
找到一个新的特征,这个新的特征使得源域和目标域的分布差异最小,且条件分布相同的假设更加相同。本节对统计机器学习领域与迁移学习相关的已有工作进行综述,主要侧重无监督迁移学习即目标领域没有标注数据的迁移学习任务。涉及两类主流方法:实例权重法和特征表示法。特征表示法可以进一步分为两个子类:隐含表征学习法和概率分布适配法。隐含表征学习法通过分析辅助领域和目标领域的大量无标样例来构建抽象特征表示,从而隐式地缩小领域间的分布差异[8,35,36,39,42]。概率分布适配法通过惩罚或移除在领域间统计可变的特征[23,41]、或通过学习子空间嵌入表示来最小化特定距离函数[40,43,45–47],从而显式地提升辅助领域和目标领域的样本分布相似度。本文第二章属于隐含表征学习法,第三至第五章属于概率分布适配法。与已有工作不同,本文重点研究了隐含表征学习中的负迁移问题和概率分布适配中的欠适配问题。
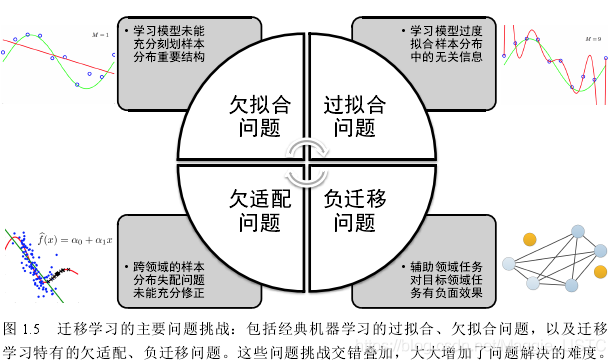
1.4 有待解决问题















 328
328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









