







C 题 天然气水合物资源量评价
解题思路
首先,对题目所给数据进行数据预处理。在附件1所给txt文件中存在多余空格,需要提前进行删除,否则将导致读入数据时出现4列。然后,对附件1中值为-9999的数据对进行删除或进行标记,以避免在后续统计中影响统计结果。
第一问
对于问题一,题目要求根据附件勘探井位信息确定天然气水合物资源分布范围。该题有两个求解思路。一是只使用“附件2:井位信息”中的数据,对勘探点绘制散点图表示其分布。二是结合“附件1:钻井测量数据”中的数据,先建立若干与天然气水合物资源量有关的指标,然后分别对各个勘探点的数据进行统计,得到各指标的值;然后建立TOPSIS评价模型,计算各个勘探点的得分,最后绘制热力图以表征各个地区的资源量得分分布。
第二问
对于问题二,题目要求确定研究区域内天然气水合物资源参数有效厚度、地层孔隙度和饱和度的概率分布及其在勘探区域内的变化规律。针对概率分布的求解,可以使用核密度估计的方法,核密度估计是一种非参数统计方法,用于估计随机变量的概率密度函数。这种方法通过在每个数据点周围放置一个核(通常是一个概率密度函数),然后将这些核函数叠加起来,从而得到对概率密度函数的估计,由此得出各特征的概率分布。然后对于各个勘探点都可以提取其均值、方差等数据特征,绘制热力图表征变化规律。同时,可以针对于不同的勘探深度分别进行探讨,以细化讨论的结果。
第三问
对于问题三,题目要求求出天然气水合物资的概率分布,以及估计天然气水合物资源量。对于这个问题,可以考虑对第一问所求得的TOPSIS得分基于K-means算法进行聚类,并计算各个类别的勘探点群所围成的面积。由此得出若干个有效面积,根据题目所给的天然气水合物计算公式计算出各个类别勘探点群的资源量。然后,可以对所考虑的区域进行网格划分,得到各个网格内对应的资源估计量,进一步基于核密度估计算法计算出概率分布。最后,将各个网格内的资源估计量累加即可得到总的天然气水合物估计量。
第四问
对于问题四,为了得到更精细的勘探结果,可以考虑以最小化勘探点间距离的方差为优化目标,建立单目标优化模型。并基于遗传算法等智能优化算法或Gurobi等求解器对模型进行求解。
技术文档
1 数据预处理
首先,需要对提供的数据进行数据预处理。在附件1所提供的txt文件中存在多余的空格,因此在读取数据时,需要提前删除这些多余的空格,以避免导致数据被错误地解释为包含4列而非实际的3列。
同时,识别并处理缺失值、异常值和重复值。包括填充缺失值、删除重复记录以及识别并处理异常数值或离群点。
2 第一问
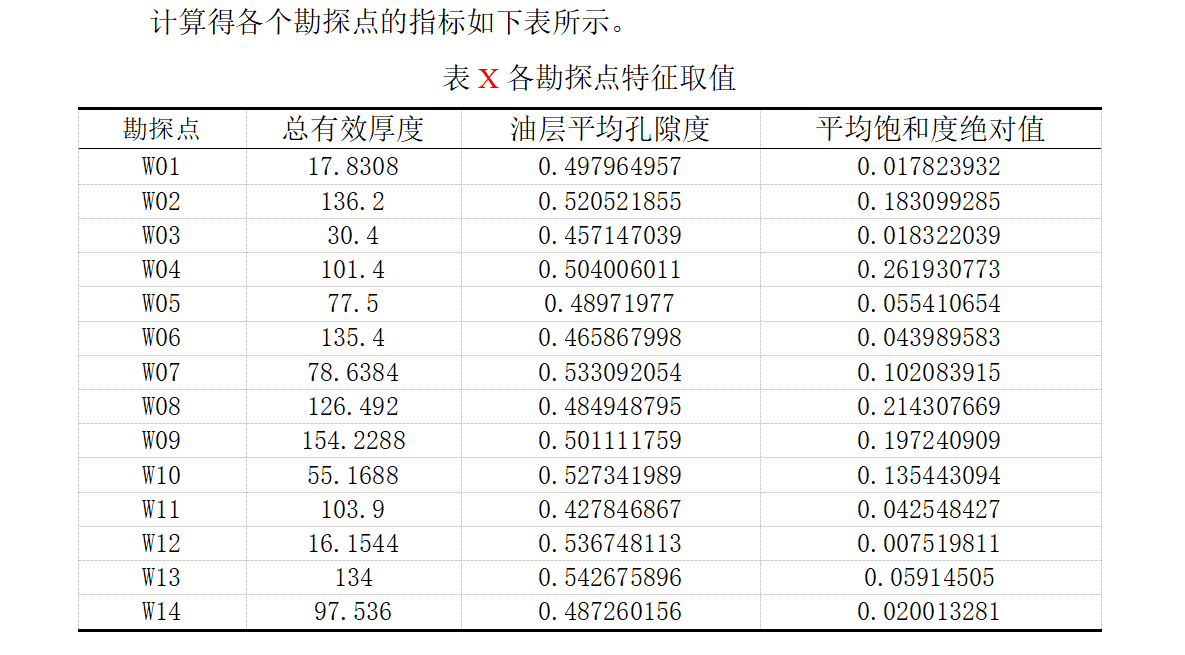
2.1 评价指标的构建及计算


2.2 基于克里金插值算法的空间插值
2.2.1 模型的建立





2.2.2 模型的求解
2.3 基于TOPSIS算法的勘探井位天然气水合物资源含量评价
完整文档看最后哦~
数据与代码
- 部分代码分享
clc
clear
close all
%% 读取数据
filename = '附件1:钻井测量数据.xlsx';
% 获取Excel文件中的所有工作表名称
sheets = sheetnames(filename);
% 创建一个cell数组来存储读取的矩阵数据
data = cell(numel(sheets), 1);
% 循环读取每个工作表中的数据
for i = 1:numel(sheets)
data{i} = readmatrix(filename, 'Sheet', sheets{i});
end
%% 计算特征
f_set = []; %最终的特征表
for n=1:14 % 遍历每一个勘探点
site = data{n};
thick = 0; %记录厚度
num = 0; %记录有效点数
sum_porosity = 0; %记录总孔隙度
sum_saturation = 0; %记录总饱和度
flag = 0; %上一个探索点是否为油层,0则不是,非0则为该油层开始高度
for i=1:size(site,1) % 遍历所有深度
if site(i,2)==-9999||site(i,3)==-9999
if flag~=0 %如果上一个是油层
thick = thick+site(i,1)-site(flag,1);
end
flag=0;
continue %如果是无效数据就直接跳过
else
if site(i,3)~=0 %如果是油层
num = num+1;
if flag==0 %如果是油层开始点
flag = i;
end
sum_porosity = sum_porosity+site(i,2); %更新总孔隙度
sum_saturation = sum_saturation+abs(site(i,3)); %更新总饱和度
if i==size(site,1)
thick = thick+site(i,1)-site(flag,1);
end
else
if flag~=0 %如果上一个是油层
thick = thick+site(i,1)-site(flag,1);
end
flag=0;
end
end
end
f_set(n,1) = thick;
f_set(n,2) = sum_porosity/num;
f_set(n,3) = sum_saturation/num;
end

资料获取

扫描下方任一二维码,添加助理学长学姐微信
即可获取助攻资料!
















 981
981











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









