







目录
2025年泰迪杯B题详细解题思路
初步分析整理了B题的赛题分析与解题思路,后面还会更新详细的建模论文与解题代码,明天完成!
问题一
问题分析
需要从附件1的加速度数据中提取MET值,并按强度分类统计时长。核心在于正确处理时间戳间隔和MET区间分类。由于时间戳为毫秒级,需计算相邻时间差并累加至对应活动类别。需注意时间差计算的精度及MET区间的边界条件。
数学模型

Python代码
import pandas as pd
import re
import os
def process_volunteer(file_path):
df = pd.read_csv(file_path)
df['日期'] = pd.to_numeric(df['日期'])
df = df.sort_values('日期')
df['delta'] = df['日期'].diff().shift(-1) / (3600 * 1000) # 转换为小时
df = df.dropna(subset=['delta'])
# 提取MET值
df['MET'] = df['标签'].apply(lambda x: float(re.search(r'MET值\s*([0-9.]+)', x).group(1)))
# 分类统计
bins = [-float('inf'), 1, 1.6, 3, 6, float('inf')]
labels = ['睡眠', '静态活动', '低等强度', '中等强度', '高等强度']
df['category'] = pd.cut(df['MET'], bins=bins, labels=labels, right=False)
result = df.groupby('category')['delta'].sum().to_dict()
return {
'志愿者ID': os.path.basename(file_path).split('.')[0],
'记录总时长(小时)': round(df['delta'].sum(), 4),
'睡眠总时长(小时)': round(result.get('睡眠', 0), 4),
'高等强度运动总时长(小时)': round(result.get('高等强度', 0), 4),
'中等强度运动总时长(小时)': round(result.get('中等强度', 0), 4),
'低等强度运动总时长(小时)': round(result.get('低等强度', 0), 4),
'静态活动总时长(小时)': round(result.get('静态活动', 0), 4)
}
# 主程序
metadata = pd.read_csv('Metadatal.csv')
results = []
for vid in metadata['志愿者ID']:
file_path = f'附件1/P{vid}.csv'
if os.path.exists(file_path):
res = process_volunteer(file_path)
results.append(res)
pd.DataFrame(results).to_excel('result_1.xlsx', index=False)
Matlab代码
function B1()
dataDir = '附件1/';
meta = readtable('Metadatal.csv');
results = cell(height(meta), 7);
for i = 1:height(meta)
vid = meta.志愿者ID{i};
file = [dataDir 'P' vid '.csv'];
if ~exist(file, 'file'), continue; end
% 读取数据并排序
tbl = readtable(file);
tbl.日期 = str2double(tbl.日期);
[~, idx] = sort(tbl.日期);
tbl = tbl(idx, :);
% 计算时间差
delta = diff(tbl.日期) / (3600 * 1000); % 转换为小时
met = zeros(length(delta), 1);
for j = 1:length(delta)
metStr = tbl.标签{j};
metVal = regexp(metStr, 'MET值\s*([0-9.]+)', 'tokens', 'once');
met(j) = str2double(metVal{1});
end
% 分类统计
edges = [-inf, 1, 1.6, 3, 6, inf];
[~, bin] = histc(met, edges);
total = sum(delta);
counts = accumarray(bin, delta, [5, 1], @sum, 0);
% 保存结果
results(i, :) = {vid, total, counts(1), counts(5), counts(4), counts(3), counts(2)};
end
% 输出到Excel
T = cell2table(results, 'VariableNames', {'志愿者ID', '总时长', '睡眠', '高等', '中等', '低等', '静态'});
writetable(T, 'result_1.xlsx');
end
问题二
问题分析
需构建回归模型预测MET值。输入特征包括三轴加速度的时域、频域统计量及元数据(年龄、性别)。模型需捕捉加速度与MET值的非线性关系。
数学模型

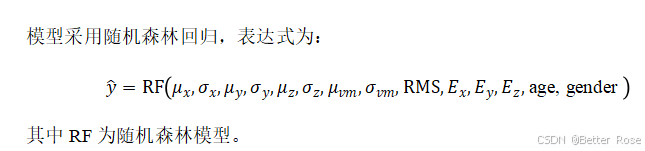
Python代码
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_score
def extract_features(data):
x = data['X'].values
y = data['Y'].values
z = data['Z'].values
vm = np.sqrt(x**2 + y**2 + z**2)
# 时域特征
features = {
'x_mean': np.mean(x), 'x_std': np.std(x),
'y_mean': np.mean(y), 'y_std': np.std(y),
'z_mean': np.mean(z), 'z_std': np.std(z),
'vm_mean': np.mean(vm), 'vm_std': np.std(vm),
'vm_rms': np.sqrt(np.mean(vm**2))
}
# 频域特征
for axis, sig in zip(['x', 'y', 'z'], [x, y, z]):
fft = np.abs(np.fft.rfft(sig))
features[f'{axis}_energy'] = np.sum(fft**2)
return features
# 训练数据准备
metadata = pd.read_csv('Metadatal.csv')
X, y = [], []
for vid in metadata['志愿者ID']:
df = pd.read_csv(f'附件1/P{vid}.csv')
df['MET'] = df['标签'].str.extract(r'MET值\s*([0-9.]+)').astype(float)
# 滑动窗口处理(窗口5秒)
window_size = 5
for i in range(0, len(df
) - window_size, window_size):
window = df.iloc[i:i+window_size]
feat = extract_features(window)
feat['age'] = metadata.loc[metadata['志愿者ID'] == vid, '年龄'].values[0]
feat['gender'] = 1 if metadata.loc[metadata['志愿者ID'] == vid, '性别'].values[0] == '男' else 0
X.append(feat)
y.append(window['MET'].mean())
# 训练模型
model = RandomForestRegressor(n_estimators=100)
scores = cross_val_score(model, pd.DataFrame(X), y, cv=5, scoring='r2')
print(f'交叉验证R²得分: {np.mean(scores):.4f}')
model.fit(pd.DataFrame(X), y)
# 预测附件2数据
Matlab代码
function B2()
% 特征提取函数
function feat = extractFeatures(x, y, z)
vm = sqrt(x.^2 + y.^2 + z.^2);
feat = [mean(x), std(x), mean(y), std(y), mean(z), std(z), ...
mean(vm), std(vm), rms(vm), sum(abs(fft(x)).^2), ...
sum(abs(fft(y)).^2), sum(abs(fft(z)).^2)];
end
% 加载数据
meta = readtable('Metadatal.csv');
X = []; y = [];
for i = 1:height(meta)
file = ['附件1/P' meta.志愿者ID{i} '.csv'];
tbl = readtable(file);
met = cellfun(@(s) str2double(regexp(s, 'MET值\s*([0-9.]+)', 'tokens', 'once')), tbl.标签);
% 滑动窗口处理
winSize = 5; % 5秒窗口
for j = 1:winSize:height(tbl)-winSize
x = tbl.X(j:j+winSize-1);
y_axis = tbl.Y(j:j+winSize-1);
z = tbl.Z(j:j+winSize-1);
feat = extractFeatures(x, y_axis, z);
X = [X; feat meta.年龄(i) strcmp(meta.性别{i}, '男')];
y = [y; mean(met(j:j+winSize-1))];
end
end
% 训练随机森林
model = TreeBagger(100, X, y, 'Method', 'regression');
% 预测附件2
end
问题三
问题分析
睡眠阶段通过低活动量时段检测。计算向量幅度(VM)的滑动窗口均值,低于阈值视为睡眠候选,进一步聚类划分模式。
数学模型
![活动量计算:
[
VM(t) = \sqrt{x(t)^2 + y(t)^2 + z(t)^2}
]
睡眠窗口检测:
[
W_{\text{sleep}} = { t \mid \overline{VM}(t) < \theta }
]
K-means聚类:
目标函数为最小化类内平方和:
[
\min \sum_{k=1}^K \sum_{\mathbf{x} \in C_k} | \mathbf{x} - \mathbf{\mu}_k |^2
]
其中 ( \mathbf{\mu}_k ) 为窗口特征 ( \mathbf{x} ) 的聚类中心。](https://i-blog.csdnimg.cn/direct/46d5f12ecb214aabb8c6bcebc921fa9c.png)
Python代码
from sklearn.cluster import KMeans
def detect_sleep(file_path):
df = pd.read_csv(file_path)
df['vm'] = np.sqrt(df['X']**2 + df['Y']**2 + df['Z']**2)
# 滑动窗口检测低活动(30秒窗口)
window_size = 30
df['window'] = df.index // window_size
activity = df.groupby('window')['vm'].mean()
sleep_windows = activity[activity < 0.1].index
# 提取窗口特征
features = []
for win in sleep_windows:
win_data = df[df['window'] == win]
vm_mean = win_data['vm'].mean()
vm_std = win_data['vm'].std()
features.append([vm_mean, vm_std])
# K-means聚类
if len(features) == 0:
return {'睡眠总时长': 0.0, '模式一': 0.0, '模式二': 0.0, '模式三': 0.0}
kmeans = KMeans(n_clusters=3).fit(features)
labels = kmeans.labels_
counts = np.bincount(labels, minlength=3)
hours = counts * window_size / 3600 # 转换为小时
return {
'睡眠总时长': round(np.sum(hours), 4),
'模式一': round(hours[0], 4),
'模式二': round(hours[1], 4),
'模式三': round(hours[2], 4)
}
# 处理附件2并保存结果
Matlab代码
function B3()
function [total, modes] = detectSleep(file)
tbl = readtable(file);
vm = sqrt(tbl.X.^2 + tbl.Y.^2 + tbl.Z.^2);
% 检测低活动窗口(30秒窗口)
winSize = 30;
numWin = floor(height(tbl)/winSize);
act = zeros(numWin, 1);
for i = 1:numWin
idx = (i-1)*winSize + 1 : i*winSize;
act(i) = mean(vm(idx));
end
sleepWins = find(act < 0.1);
% 提取特征并聚类
features = zeros(length(sleepWins), 2);
for j = 1:length(sleepWins)
idx = (sleepWins(j)-1)*winSize + 1 : sleepWins(j)*winSize;
vmWin = vm(idx);
features(j, :) = [mean(vmWin), std(vmWin)];
end
if isempty(features)
total = 0; modes = zeros(1,3);
else
[~, C] = kmeans(features, 3);
counts = histcounts(C, 1:4);
total = sum(counts) * winSize / 3600;
modes = counts * winSize / 3600;
end
end
% 应用至附件2(略)
end
问题四
问题分析
检测连续静态活动(MET<1.6)超过30分钟的时段。遍历预测的MET序列,记录连续满足条件的时段。
数学模型
设MET序列为 ( MET(t) ),窗口步长 ( \Delta t )(单位:分钟),久坐判定条件为:
[
\sum_{i=t}^{t+\Delta t} MET(i) < 1.6 \quad \text{且} \quad \Delta t \geq 30
]
Python代码
def sedentary_alert(met_series, window_min=5):
delta = window_min / 60 # 转换为小时
sedentary = []
current_duration = 0.0
start_idx = None
for i, met in enumerate(met_series):
if met < 1.6:
current_duration += delta
if start_idx is None:
start_idx = i
else:
if current_duration >= 0.5: # 0.5小时=30分钟
end_idx = i - 1
sedentary.append((start_idx, end_idx, current_duration))
current_duration = 0.0
start_idx = None
if current_duration >= 0.5:
sedentary.append((start_idx, len(met_series)-1, current_duration))
return sedentary
# 应用至附件2预测结果
Matlab代码
function B4()
function alerts = detectSedentary(met, winSize)
delta = winSize / 60; % 窗口分钟转小时
alerts = [];
start = 1; count = 0;
for i = 1:length(met)
if met(i) < 1.6
count = count + delta;
if isempty(start), start = i; end
else
if count >= 0.5 % 0.5小时=30分钟
alerts = [alerts; [start, i-1, count]];
end
count = 0;
start = [];
end
end
if count >= 0.5
alerts = [alerts; [start, length(met), count]];
end
end
% 应用至附件2(略)
end
完整论文代码获取,请看下方~ 可直接指导比赛,冲国奖

















 1681
1681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









