







基于Detectron2 & AdelaiDet的BlendMask训练 BlendMask环境配置 COCO数据集
博客参考:https://blog.csdn.net/weixin_43796496/article/details/125179243
博客参考:https://blog.csdn.net/weixin_43823854/article/details/108980188
训练的数据为:竞赛数据集
配置环境为:windows环境 pytorch1.10.0 cuda11.3 显卡 GTX 1650S 单卡
一、下载Detectron2
在github搜索BlendMask,出现的界面为AdelaiDet
AdelaiDet是基于Detectron2之上,可以包含多个实例级识别任务的开源工具箱,所以它也可以看作是Detectron2的一个拓展插件。BlendMask也是属于AdelaiDet其中一个任务。
二、配置步骤
1.基础环境配置
在终端中输入
conda create -n detectron2 python=3.8 #创建虚拟环境
conda activate detectron2 #激活虚拟环境
nvcc --sersion #查看cuda版本
详细配置请参考Pytorch环境配置
2.安装Detectron2
按照官方安装步骤进行安装
基本需求
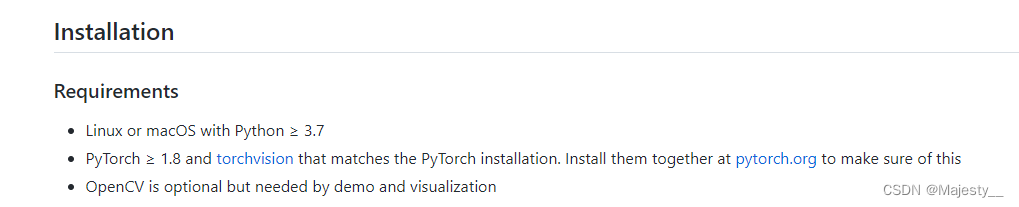
官方文档
https://github.com/facebookresearch/detectron2/blob/main/INSTALL.md
下载Detectron2相关代码
git clone https://github.com/facebookresearch/detectron2.git #用git下载代码
python -m pip install -e detectron2 #安装detectron2
出现问题,参考博客 https://blog.csdn.net/iracer/article/details/125755029
3.安装AdelaiDet
windows下
git clone https://github.com/aim-uofa/AdelaiDet.git
cd AdelaiDet
python setup.py build develop
如果你正在使用docker,一个预构建的映像可以用:
docker pull tianzhi0549/adet:latest
如果torch版本大于1.11.0
会出现以下错误,原因是新版pytorch移除了 THC/THC.h
fatal error: THC/THC.h: No such file or directory
将路径下的 AdelaiDet/adet/layers/csrc/ml_nms/ml_nms.cu 改为以下内容
具体参考:https://github.com/aim-uofa/AdelaiDet/issues/550 & https://github.com/aim-uofa/AdelaiDet/pull/518
// Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
#include <ATen/ATen.h>
#include <ATen/cuda/CUDAContext.h>
// #include <THC/THC.h>
#include <ATen/cuda/DeviceUtils.cuh>
#include <ATen/ceil_div.h>
#include <ATen/cuda/ThrustAllocator.h>
#include <vector>
#include <iostream>
int const threadsPerBlock = sizeof(unsigned long long) * 8;
__device__ inline float devIoU(float const * const a, float const * const b) {
if (a[5] != b[5]) {
return 0.0;
}
float left = max(a[0], b[0]), right = min(a[2], b[2]);
float top = max(a[1], b[1]), bottom = min(a[3], b[3]);
float width = max(right - left + 1, 0.f), height = max(bottom - top + 1, 0.f);
float interS = width * height;
float Sa = (a[2] - a[0] + 1) * (a[3] - a[1] + 1);
float Sb = (b[2] - b[0] + 1) * (b[3] - b[1] + 1);
return interS / (Sa + Sb - interS);
}
__global__ void ml_nms_kernel(const int n_boxes, const float nms_overlap_thresh,
const float *dev_boxes, unsigned long long *dev_mask) {
const int row_start = blockIdx.y;
const int col_start = 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8214
8214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









