






 本文是一篇针对Python爬虫初学者的教程,通过实例演示如何爬取Bangumi网站上的游戏角色信息,包括角色名、日文名、CV等,并介绍了正则表达式在数据筛选中的应用。文章还强调了爬虫的合法使用以及如何根据需求修改代码以适应不同网站的爬取任务。
本文是一篇针对Python爬虫初学者的教程,通过实例演示如何爬取Bangumi网站上的游戏角色信息,包括角色名、日文名、CV等,并介绍了正则表达式在数据筛选中的应用。文章还强调了爬虫的合法使用以及如何根据需求修改代码以适应不同网站的爬取任务。
本人与知乎用户间宫羽咲sama是同一人,内容同步更新在CSDN和知乎上,以方便大家查阅。(知乎对markdown兼容做得太差了,这一点还是CSDN好)
0、前言
本文相当于简易的爬虫教程,可以让小白使用爬虫轻易地爬取想要的资讯。(稍微改一下代码,就能爬其他内容了,后面我会讲怎么改)
寒假闲得没事干,想写点galgame的感想。galgame的相关资讯在bangumi上挺容易找到的,但是自己手动搬运实在是费时费力。于是打算做一个爬虫,顺便做了一个爬虫教程。
本文参考了这些文章123 ,主要参考的是文章2,在此基础上补充了详尽的注释,以让小白更容易明白每一行代码的意义。
如果不想知道原理,只想直接用的话,可以看完1/2(爬虫使用须知部分),直接看6就行,那里有现成的代码,以及具体使用说明。
1、什么是爬虫?
在浩瀚无垠的互联网中,有着无数的信息。但通常而言,你只关心你想要的信息。例如,如果你想知道「酒店」的信息,你可以在百度/bing/google上搜索酒店,它们就会把关键词为「酒店」的信息呈报给你。
这一过程是如何实现的呢?其实就是采用的爬虫。当你给出了你想要检索的关键词后,搜索引擎就会派出它们的侦察兵——爬虫去各大网站寻找,找到「酒店」关键词后,就会给你呈报上来。当然,这里面其实有很多复杂的知识,例如找到的内容应当如何排序,这涉及到大型稀疏矩阵的求解,但这些都不是本文要谈到的内容,不予赘述。让我们将目光再回到“爬虫”身上。
我们可以看到,爬虫只是一个工具,它可以帮你找寻你想要的信息。但是,假设你是网站的所有者,你不一定希望所有的信息(例如隐私信息)被人爬取。而且网站爬虫过大,也会导致服务器压力过大(如火车票售卖网站)。
因此,我们必须明确:爬虫只是一个工具,它可以是善意的,也可以是恶意的。所以,如果不正确地使用爬虫的话,可能构成违法行为,请大家千万不要这么做!
2、什么东西可以爬?
那么,我们如何知道:什么内容是可以爬的呢?
许多网站都有 robots.txt 的文件,这个文件里面讲了什么内容可以爬取,什么内容不可爬取。
例如我们范例中的 http://bgm.tv/ 网站,通过访问 http://bgm.tv/robots.txt ,就能看到网站哪些内容是不允许爬的了。
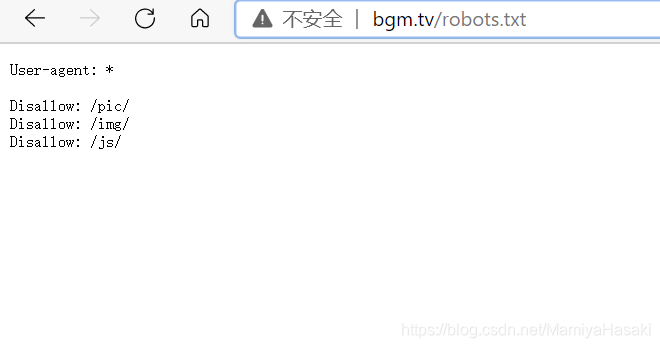
Disallow的部分代表禁止爬取。
3、简易爬虫示例
说了这么多,让我们来试试用一个十分简易的爬虫,来爬一下 http://bgm.tv/robots.txt 的信息吧。
首先你需要安装一个Python3,如果没有,请自行百度。因为这个很容易,所以这里我偷一个懒~
然后我们要在cmd里键入
pip install requests
用以安装requests库,否则会出现如下报错:

使用如下Python代码:
import requests # 导入requests包
baseurl = 'http://bgm.tv/' # 网站名
filename = 'robots.txt' # 内容
# baseurl + filename相当于'http://bgm.tv/robots.txt'
response = requests.get(baseurl + filename) # Get方式获取网页数据
print(response.text) # 输出
效果如下图,我们容易发现,这个代码成功帮我们爬取了http://bgm.tv/robots.txt 的信息:
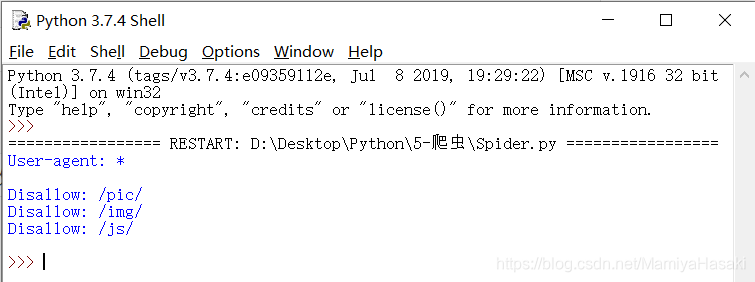
4、如何筛选数据?
如果仅仅是收集数据,这样笨笨的爬虫意义也不大。我们希望爬虫聪明一点,能够按照我们的需求,精准地把数据呈报上来。
但是,代码毕竟是代码,你想要它干活,就得要把需求给它说清楚。例如你想要代码找所有游戏的“评分”,但程序并不能听懂这一点。你应该用程序能听得懂的语言告诉它。
实际上,我们用爬虫爬到的内容 response.text ,其实就是网站的html代码。 浏览器看到html代码,就会将其翻译为我们看到的浏览器的样子。这里我就不再详细介绍原理了,直接讲该怎么用吧。
首先,找到你要爬的内容,右键单击,选择审查元素(检查),如下图所示:
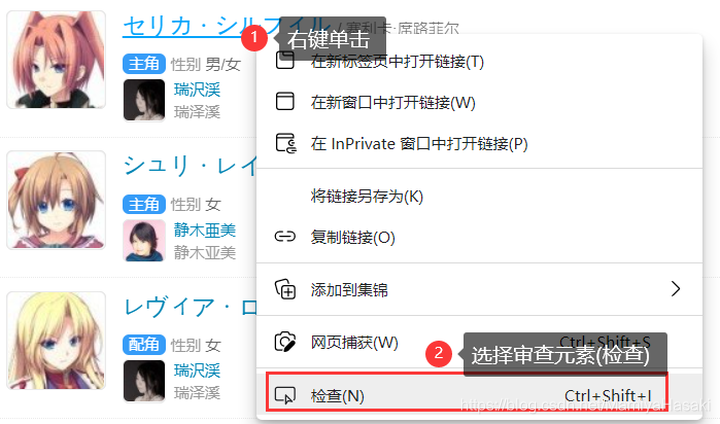
然后你的浏览器右边就会多出一个框框,这里面的内容就是html代码,里面存放有我们想要的内容
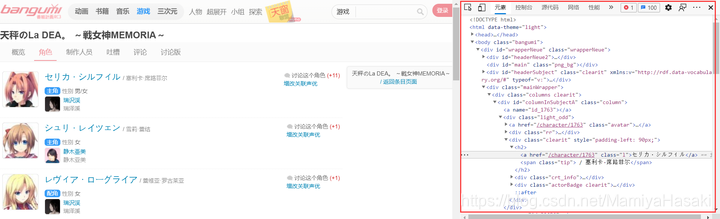
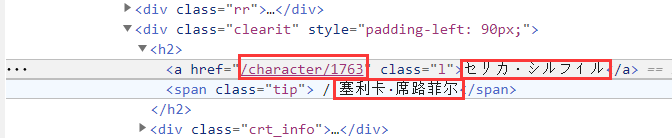
例如下图画圈的地方,就是我们想要爬取的数据。我们可以发现,这些数据都有一些固定前缀和后缀,例如:
/character/1763的前缀是<a href=",后缀是" class=“l”
塞利卡·席路菲尔的前缀是<span class=“tip”> / ,后缀是</span>
于是,我们就可以告诉程序:「你帮我去这个网页里找数据,看见前缀为<a href=",后缀为" class="l"的内容,就把中间的部分给我搬运下来」
那么如何告诉呢?这里我们就要用到一个叫做正则表达式的东西了。
5、正则表达式
关于正则表达式的使用方式,可以参考这篇文章4。正则表达式的库是自带的,所以不需要 pip install 。
我们用匹配角色的中文名作为例子
我们假设字符串 chara 中有我们的目标字符串,那么通过下面的Python代码,我们就可以实现对内容的提取。
findCharaChinese = re.compile(r'<span class="tip"> / (.*?)</span>')
charachinese = re.findall(findCharaChinese, chara)
让我们来分析一下这段代码。
首先,r' ' 代表 ' '里面的字符串照原样输出,即使是特殊字符也不需要转义。
然后, (.*?) 代表匹配任意字符串0/1次,前缀和后缀是正确的的前提下,findall 函数就会把 (.*?) 的内容返回到变量 charachinese 里。
这样,我们就通过正则表达式,实现了对字符串的匹配并提取功能了。
6、最终代码
首先还是在cmd中安装输入这几个命令,安装对应的库
pip install bs4
pip install lxml
这里我的代码是基于这篇文章4改的(因为这篇文章没用responses库,所以我也跟着没用,毕竟在别人代码上改比自己从头造轮子快多了~),思路是一致的。如果觉得我这篇文章写得很烂的话,也可以看看我参考的这篇文章。
我的代码如下(想要进行适当修改,以爬取其他文章,请看本代码后我的讲解)——
# -*- codeing = utf-8 -*-
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式,进行文字匹配
import urllib.request, urllib.error # 制定URL,获取网页数据
import xlwt # 进行excel操作
gamename = '战女神M'
subjectname = '88429' # 就是你要爬的内容的subject号
baseurl = "http://bgm.tv" # bangumi链接
url = baseurl + "/subject/"+ subjectname +"/characters" # 要爬取的网页链接
col = ("角色详情链接", "角色日文名", "角色中文名", "CV详情链接", "CV中译名")
# 创建正则表达式对象
findChara = re.compile(r'<h2>(.*?)</h2>') # 角色信息
findCharaLink = re.compile(r'<a class="l" href="(.*?)">') # 0.角色详情链接
findCharaJapanese = re.compile(r'">(.*?)</a>') # 1.角色日文名
findCharaChinese = re.compile(r'<span class="tip"> / (.*?)</span>') # 2.角色中文名
findCvLink = re.compile(r'<a class="avatar" href="(.*?)">') # 3.CV详情链接
findCvName = re.compile(r'<small class="grey">(.*?)</small>') # 4.CV名字
# 得到指定一个URL的网页内容
def askURL(url):
head = { # 模拟浏览器头部信息,这段我抄的https://blog.csdn.net/bookssea/article/details/107309591
"User-Agent": "Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 80.0.3987.122 Safari / 537.36"
}
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
print("URL内容请求成功")
return html
# 给链接添加baseurl前缀,如果为空就返回空,否则返回baseurl + content
def reshapeLink(content):
if content == "":
return ""
else:
return baseurl + content
# 如果正则表达式返回为空列表,则返回"",否则返回第0个元素
def getContent(content):
if content == []:
return ""
else:
return content[0]
# 爬取网页
def getData(url):
datalist = [] # 用来存储爬取的网页信息
html = askURL(url) # 保存获取到的网页源码
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('div', class_="light_odd"): # 查找符合要求的字符串
data = [] # 保存角色的对应信息
# 通过正则表达式查找
chara = re.findall(findChara, str(item))[0] # 角色信息
charalink = getContent(re.findall(findCharaLink, chara)) # 0.角色链接
data.append(reshapeLink(charalink))
charajapanese = getContent(re.findall(findCharaJapanese, chara)) # 1.角色中文名
data.append(charajapanese)
charachinese = getContent(re.findall(findCharaChinese, chara)) # 2.角色日文名
data.append(charachinese)
cv = getContent(item.find_all('div', class_="actorBadge clearit")) # cv信息
cvlink = getContent(re.findall(findCvLink, str(cv))) # 3.cv链接
data.append(reshapeLink(cvlink))
cvname = getContent(re.findall(findCvName, str(cv))) # 4.cv中译名
data.append(cvname)
# 将信息添加到datalist里去
datalist.append(data)
#print(datalist)
return datalist
# 保存数据到表格
def saveData(datalist, savepath):
print("save excel.......")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) # 创建workbook对象
sheet = book.add_sheet(gamename, cell_overwrite_ok=True) # 创建工作表
for i in range(0, len(col)):
sheet.write(0,i,col[i]) # 列名
for i in range(0, len(datalist)):
#print("第%d条" %(i+1)) # 输出语句,用来测试
data = datalist[i]
for j in range(0, len(col)):
sheet.write(i+1,j,data[j]) # 数据
book.save(savepath) # 保存
# 保存数据到txt
def saveTxt(datalist, savepath):
print("save txt.......")
txtfile = open(savepath, 'w', encoding='utf-8')
for i in range(0, len(datalist)):
txtfile.write(datalist[i][2]+"("+datalist[i][1]+")\n")
txtfile.write("别名:\n")
txtfile.write("CV:"+datalist[i][4]+datalist[i][3]+"\n")
txtfile.write("CV介绍:\n\n")
txtfile.close()
# main函数
if __name__ == "__main__":
# 1.爬取网页+解析数据
datalist = getData(url)
print("爬取完毕!")
# 2.当前目录创建XLS,保存数据
saveData(datalist, gamename+".xls")
# 3.当前目录创建TXT,保存数据
saveTxt(datalist, gamename+".txt")
print("输出完毕!")
如何修改代码,以适应自己的需求
当然,写爬虫的目的本身就是批量化操作,想要爬取其他文章,只需要改这两处就行
gamename (这个随便改,只影响输出文件名而已,不怕重名导致意外地覆盖的话,其实不改也行)
subjectname (这个必须改,改成你想爬的游戏的subject ID),如下图
为了防止大家翻来翻去,我把代码开头部分再复制下来,方便大家找到我上面说的 gamename 、 subjectname 在哪里:
# -*- codeing = utf-8 -*-
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式,进行文字匹配
import urllib.request, urllib.error # 制定URL,获取网页数据
import xlwt # 进行excel操作
gamename = '战女神M'
subjectname = '88429' # 就是你要爬的内容的subject号
baseurl = "http://bgm.tv" # bangumi链接
url = baseurl + "/subject/"+ subjectname +"/characters" # 要爬取的网页链接
col = ("角色详情链接", "角色日文名", "角色中文名", "CV详情链接", "CV中译名")
# 创建正则表达式对象
findChara = re.compile(r'<h2>(.*?)</h2>') # 角色信息
findCharaLink = re.compile(r'<a class="l" href="(.*?)">') # 0.角色详情链接
findCharaJapanese = re.compile(r'">(.*?)</a>') # 1.角色日文名
findCharaChinese = re.compile(r'<span class="tip"> / (.*?)</span>') # 2.角色中文名
findCvLink = re.compile(r'<a class="avatar" href="(.*?)">') # 3.CV详情链接
findCvName = re.compile(r'<small class="grey">(.*?)</small>') # 4.CV名字
如果想要爬其他的项目,请自己根据章节4/5讲的内容,设计对应的正则表达式形式
findXXX = re.compile(r'AAA(.*?)BBB') # 角色信息
然后在 getData 函数主循环中,添加对应的代码
XXX = getContent(re.findall(findXXX, item))
data.append(XXX)
最后,千万不要忘记了!开头的 col 里要加进去你的XXX (否则你的Excel不会输出XXX这一项)
col = ("角色详情链接", "角色日文名", "角色中文名", "CV详情链接", "CV中译名", "XXX")
建议把我main函数里写的 saveTxt 函数注释掉,因为这个是我按照我自己的需求进行的txt格式的格式化输出。当然,如果有打算输出为txt格式的话,也可以在上面改。
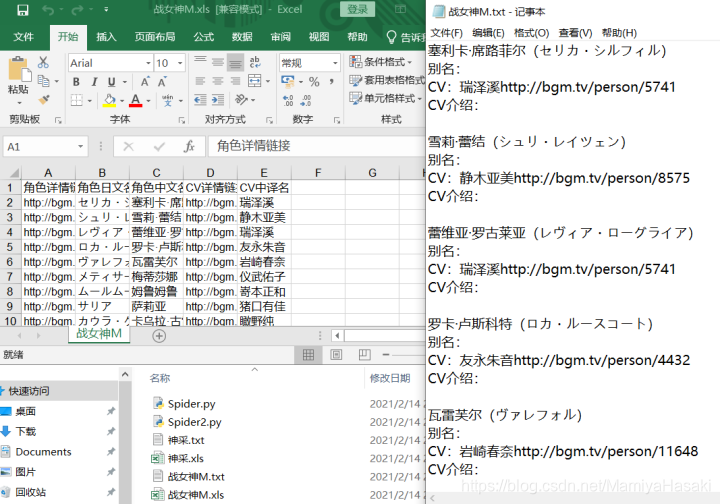
效果截图
7、彩蛋
期待有生之年能看到战女神2里盗狮子登场~


















 2915
2915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









