










CNN网络结构
本文使用的卷积网络共4层:2层卷积层(Conv+MaxPool),2层全连接层(Fully-Connected)。
注意事项
1.网络中加入了dropout层和batchnorm;
2.在输入图片经过卷积层处理后,进入全连接层之前需要进行展平(Flatten)操作:x.view(x.size(0),-1),相当于将向量铺平,便于传入全连接层,具体解释可参考关于x.view()的理解_echo_gou的博客-CSDN博客
代码实现
该代码将没训练100次后的Loss和Accuracy输出,并绘制了训练损失、训练准确率、测试损失图,代码及运行结果如下(共训练了5轮):
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as np
#MNIST包含70,000张手写数字图像: 60,000张用于培训,10,000张用于测试。图像是灰度的,28x28像素的,并且居中的,以减少预处理和加快运行。
transforms_fn=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=(0.1307,),std=(0.3081,)) #
]) # Normalize()转换使用的值0.1307和0.3081是MNIST数据集的全局平均值和标准偏差,这里我们将它们作为给定值
#训练集
train_data=torchvision.datasets.MNIST('./mnist_data',train=True,transform=transforms_fn,download=True)
#测试集
test_data=torchvision.datasets.MNIST('./mnist_data',train=False,transform=transforms_fn,download=True)
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练数据集的长度为{}".format(train_data_size))
print("测试数据集的长度为{}".format(test_data_size))
#利用dataloader来加载数据集
train_data=DataLoader(train_data,batch_size=64)
test_data=DataLoader(test_data,batch_size=64)
examples = enumerate(test_data) #将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
batch_idx, (example_data, example_targets) = next(examples)
fig = plt.figure()
for i in range(6):
plt.subplot(2,3,i+1)
plt.tight_layout()
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title("Ground Truth: {}".format(example_targets[i]))
plt.xticks([])
plt.yticks([])
plt.show()
#构建CNN网络
class mnist_cnn(nn.Module):
def __init__(self):
super(mnist_cnn, self).__init__()
self.model_conv=nn.Sequential(
#(n-f+2*p)/s+1,n=28
#layer1
nn.Conv2d(in_channels=1,out_channels=32,kernel_size=5,stride=1,padding=0), #n=24
nn.ReLU(),
nn.BatchNorm2d(32), #卷积层之后总会添加BatchNorm2d进行数据的归一化处理,这使得数据在进行Relu之前不会因为数据过大而导致网络性能的不稳定
#对于所有的batch中的同一个channel的数据元素进行标准化处理,即如果有C个通道,无论有多少个batch,都会在通道维度上进行标准化处理,一共进行C次。
nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,stride=1,padding=0), #n=20
nn.ReLU(),
nn.BatchNorm2d(32),
nn.MaxPool2d(kernel_size=2,stride=2), #n=10
nn.Dropout(0.25),
#layer2
nn.Conv2d(in_channels=32,out_channels=64,kernel_size=3,stride=1,padding=0), #n=8
nn.ReLU(),
nn.BatchNorm2d(64),
nn.Conv2d(in_channels=64,out_channels=64,kernel_size=3,stride=1,padding=0), #n=6
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=2, stride=2), #n=3
nn.Dropout(0.25)
)
self.model_linear =nn.Sequential(
#Fully-connected layer1 n=3*3*64=576
nn.Linear(3*3*64,256),
nn.ReLU(),
nn.Dropout(0.5),
#Fully-connected layer2
nn.Linear(256,10) #因为输出10个数字0-9
)
def forward(self,x):
x=self.model_conv(x)
# Flatten拉平操作
x=x.view(x.size(0),-1) #注意在进入全连接层之前要进行这一操作,否则会出现维度错误;即矩阵中一行对应一张图片
x=self.model_linear(x)
# x=F.log_softmax(x,dim=1) #当dim=1时, 是对某一维度的列进行softmax运算;dim=2/-1时, 是对某一维度的行进行softmax运算
return x
#网络模型
model=mnist_cnn()
#损失函数
loss_fn=nn.CrossEntropyLoss() #对于cross_entropy来说,他首先会对input进行log_softmax操作,然后再将log_softmax(input)的结果送入nll_loss;而nll_loss的input就是input。
#在多分类问题中,如果使用nn.CrossEntropyLoss(),则预测模型的输出层无需添加softmax层!!!
#如果是F.nll_loss,则需要添加softmax层!!!
# # SGD 就是随机梯度下降
# opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
# # momentum 动量加速,在SGD函数里指定momentum的值即可
# opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
# # RMSprop 指定参数alpha
# opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
# # Adam 参数betas=(0.9, 0.99)
# opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
learning_rate=0.001
optimizer=torch.optim.SGD(params=model.parameters(),lr=learning_rate)
#记录训练的次数
total_train_step=0
#记录测试的次数
total_test_step=0
#记录测试的准确率
total_accuracy=0
#训练的轮数
epochs=5
#训练损失
train_loss=[]
#测试损失
test_loss=[]
#训练准确度
train_acces = []
for epoch in range(epochs):
print("-----第{}轮训练开始------".format(epoch + 1))
total,correct=0,0
# 训练步骤开始
for batch_idx,(data,target) in enumerate(train_data):
optimizer.zero_grad()
output = model(data)
loss=loss_fn(output,target)
loss.backward()
optimizer.step()
_, predicted = torch.max(output.data, 1) # 选择最大的(概率)值所在的列数就是他所对应的类别数,
total += target.size(0)
correct += (predicted == target).sum().item() #正确分类的个数
total_train_step+=1
if total_train_step%100==0:
train_loss.append(loss.item()) # 使用.item()精度更高
train_acces.append(correct/total)
print("训练次数:{} , Loss:{},Accuracy:{:.2f}%".format(total_train_step, loss,100 * correct / total))
#测试步骤开始
total_test_loss = 0
total_accuracy = 0
model.eval() #在测试集上时关闭dropout
with torch.no_grad():
for data,target in test_data:
output=model(data)
loss=loss_fn(output,target)
total_test_loss+=loss.item()
accuracy=(output.argmax(1)==target).sum()
total_accuracy+=accuracy
test_loss.append(total_test_loss)
print("整体测试集上的准确率:{:2f}%".format(100*total_accuracy.float() / test_data_size))
# 保存网络
torch.save(model,"MNIST_cpu_model_cnn(epoch={}).ckpt".format(epochs))
plt.figure(1)
plt.plot(np.squeeze(train_loss))
plt.ylabel('Train_Loss')
plt.xlabel('iterations (per 100)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
plt.figure(2)
plt.plot(np.squeeze(train_acces))
plt.ylabel('Train_Accuracy')
plt.xlabel('iterations (per 100)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
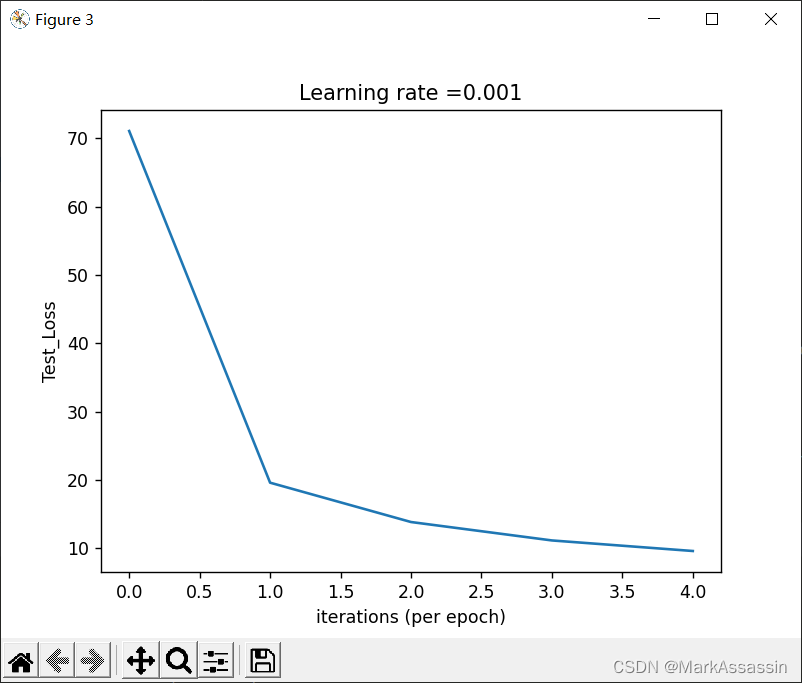
plt.figure(3)
plt.plot(np.squeeze(test_loss))
plt.ylabel('Test_Loss')
plt.xlabel('iterations (per epoch)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()

















 3355
3355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









