






逻辑回归的似然函数: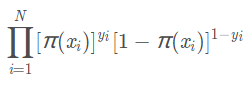
其中yi代表1或0,如果某一样本的结果为正例则其对应概率为pi(x),如未负例则对应概率为1-pi(x)
总体的样本概率为每个样本的概率乘积。



注:这里的似然函数和构建的逻辑回归的损失函数形式类似,容易搞混。
如果是直接使用最大似然估计的似然函数得到目标函数,则需要使用梯度上升;
如果是使用负对数似然函数,则需要使用梯度下降算法。
——无论上升还是下降,本质都是一样的。

LR的优缺点
优点
一、预测结果是界于0和1之间的概率;
二、可以适用于连续性和类别性自变量;
三、容易使用和解释;
缺点
一、对模型中自变量多重共线性较为敏感,例如两个高度相关自变量同时放入模型,
可能导致较弱的一个自变量回归符号不符合预期,符号被扭转。
需要利用因子分析或者变量聚类分析等手段来选择代表性的自变量,以减少候选变量之间的相关性;
二、预测结果呈“S”型,因此从log(odds)向概率转化的过程是非线性的,在两端随着log(odds)值的变化,概率变化很小,边际值太小,slope太小,
而中间概率的变化很大,很敏感。 导致很多区间的变量变化对目标概率的影响没有区分度,无法确定阀值。
LR和SVM
相同点:
都是监督的分类算法
都是线性分类方法
都是判别模型:判别模型和生成模型是两个相对应的模型。
判别模型是直接生成一个表示P(Y|X)P(Y|X)或者Y=f(X)Y=f(X)的判别函数(或预测模型)
生成模型是先计算联合概率分布P(Y,X)P(Y,X)然后通过贝叶斯公式转化为条件概率。
SVM和LR,KNN,决策树都是判别模型,而朴素贝叶斯,隐马尔可夫模型是生成模型。
生成算法尝试去找数据是怎么生成的,再对一个信号进行分类。基于生成假设,那么那个类别最有可能产生这个信号,这个信号就属于那个类别。
判别模型不关心数据是怎么生成的,只关心信号之间的差别,然后用差别来简单对给定的一个信号进行分类。
不同点:

LR基于概率理论,假设样本为0或者1的概率可以用sigmoid函数来表示,
通过极大似然估计的方法估计出参数的值,或者从信息论的角度来看,其是让模型产生的分布 P(Y|X)P(Y|X)尽可能接近训练数据的分布,
相当于最小化KL距离【因为KL距离展开后,后一项为常数,剩下的一项就是cross entropy】。
支持向量机基于几何间隔最大化原理,认为存在最大几何间隔的分类面为最优分类面
所以 SVM只考虑分类面上的点,而LR考虑所有点,SVM中,在支持向量之外添加减少任何点都对结果没有影响,而LR则是每一个点都会影响决策。
Linear SVM不直接依赖于数据分布,分类平面不受一类点影响
LR则是受所有数据点的影响,所以受数据本身分布影响的,如果数据不同类别strongly unbalance,一般需要先对数据做balancing。
SVM不能产生概率,LR可以产生概率
LR本身就是基于概率的,所以它产生的结果代表了分成某一类的概率,
而SVM则因为优化的目标不含有概率因素,所以其不能直接产生概率。虽
然现有的工具包,可以让SVM产生概率,但是那不是SVM原本自身产生的,而是在SVM基础上建立了一个别的模型,当其要输出概率的时候,还是转化为LR
SVM甚至是SVR本质上都不是概率模型,因为其基于的假设就不是关于概率的
SVM依赖于数据的测度,而LR则不受影响
因为SVM是基于距离的,而LR是基于概率的,所以LR是不受数据不同维度测度不同的影响,
而SVM因为要最小化12||w||2所以其依赖于不同维度测度的不同,如果差别较大需要做normalization
如果LR要加上正则化时,也需要normalization
SVM自带结构风险最小化,LR则是经验风险最小化
SVM本身就是优化12||w||2最小化的,所以其优化的目标函数本身就含有结构风险最小化,所以不需要加正则项
而LR不加正则化的时候,其优化的目标是经验风险最小化,所以最后需要加入正则化,增强模型的泛化能力。
SVM会用核函数而LR一般不用核函数
SVM转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,在进行复杂核函数计算时优势很明显,能够大大简化模型和计算量。
而LR则每个点都需要两两计算核函数,计算量太过庞大。
LR和SVM在实际应用的区别
根据经验来看,对于小规模数据集,SVM的效果要好于LR,但是大数据中,SVM的计算复杂度受到限制,
而LR因为训练简单,可以在线训练,所以经常会被大量采用。
总结:
1、LR采用log损失,SVM采用合页损失。
2、LR对异常值敏感,SVM对异常值不敏感。
3、在训练集较小时,SVM较适用,而LR需要较多的样本。
4、LR模型找到的那个超平面,是尽量让所有点都远离他,而SVM寻找的那个超平面,是只让最靠近中间分割线的那些点尽量远离,即只用到那些支持向量的样本。
5、对非线性问题的处理方式不同,LR主要靠特征构造,必须组合交叉特征,特征离散化。SVM也可以这样,还可以通过kernel。
6、svm 更多的属于非参数模型,而logistic regression 是参数模型,本质不同。其区别就可以参考参数模型和非参模型的区别
一些建议(来自网上)
如果Feature的数量很大,跟样本数量差不多,这时候选用LR或者是Linear Kernel的SVM
如果Feature的数量比较小,样本数量一般,不算大也不算小,选用SVM+Gaussian Kernel
如果Feature的数量比较小,而样本数量很多,需要手工添加一些feature变成第一种情况。(LR和不带核函数的SVM比较类似。)
参考:
https://blog.csdn.net/hao5335156/article/details/82388151(理解yi的意思)
https://www.cnblogs.com/God-Li/p/8999023.html(使用梯度下降的推导)
https://zhuanlan.zhihu.com/p/27188969(解释odds)
https://blog.csdn.net/haolexiao/article/details/70191667(LR和SVM比较)















 2401
2401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









