







 文章介绍了命名实体识别(NER)的基本概念,它作为NLP任务的基础,常常使用BIO等标注法。随着技术发展,从早期的HMM、CRF到深度学习的CNN、RNN,再到BERT模型与CRF的结合,NER方法不断进步。CRF在序列标注中起到关键作用,通过学习标签转移关系提高预测准确性。
文章介绍了命名实体识别(NER)的基本概念,它作为NLP任务的基础,常常使用BIO等标注法。随着技术发展,从早期的HMM、CRF到深度学习的CNN、RNN,再到BERT模型与CRF的结合,NER方法不断进步。CRF在序列标注中起到关键作用,通过学习标签转移关系提高预测准确性。
介绍
命名实体识别(Named Entity Recognition,NER)是NLP领域中一项基础的信息抽取任务,NER 是关系抽取、知识图谱、问答系统等其他诸多NLP任务的基础。NER从给定的非结构化文本中识别命名实体,并对实体分类,如时间、人名、地名、机构名等类型的实体。
NER 常转化为序列标注问题,利用BIO、BIOES和BMES等常用的标注规则对经过分词的文本进行token标注。以BIO标注模式为例,下图为对文本进行token-level的命名实体标注实例,通过构建模型对文本的每个token标签进行预测,进行实体识别。
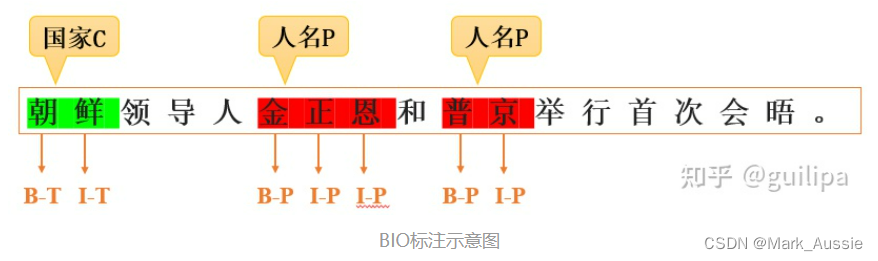
基于序列标注的命名实体识别
序列标注的命名实体识别方法中,CNN、RNN和BERT等深度模型与条件随机场CRF结合已经成为最主流和普遍的方法。
基于序列标注的命名实体识别的发展大致经历了以下三个历程:
- [机器学习]:早期传统机器学习时代,除了利用人工规则的方法外,往往利用隐马尔科夫链HMM和条件随机场CRF进行实体标注;
- [深度学习]:随着深度学习的发展,将CNN和RNN做为基本的文本特征编码器,更好的学习token或word的隐层表示,再利用CRF进行实体标签分类,Bi-LSTM-CRF是最常用和普遍的实体识别模型;
- [预训练模型]:最近BERT为代表的预训练模型表现出了强大的文本表示和理解能力,目前最流行的方法是将BERT或BERT-Bi-LSTM作为底层的文本特征编码器,再利用CRF进行实体标签预测。现在,对于许多命名实体识别任务可以将BERT-Softmax、BERT-CRF、BERT-Bi-LSTM-CRF这几个模型作为baseline,而且能达到很好的效果,这几乎得益于BERT模型的强大文本表征建模能力。
CRF与NER
基于序列标注的命名实体识别方法利用CNN、RNN和BERT等模型对文本token序列进行编码表征,再利用全连接层对序列每个token分类,最后利用Softmax或CRF进行最终标签判断确定。
假设数据集的实体类别为 k个,以 BIO 作为标注模式,命名实体识别的过程如下:

假设数据的实体类别为 2:人名(P)和国家(C), label_set = {B-C, I-C, B-P, I-P, O}。以“朝鲜领导人和普京举行会晤”句子为例,下图为命名实体识别的整个过程。

CRF实体标签判断
Softmax预测实体标签时是独立的,只由其对应token的输出所决定,同一序列中判断预测的多个标签也是独立的,没有关联和影响。而CRF是以标签路径为预测目标,可以在Logit基础上为最终的预测标签序列添加约束,确保预测的实体标签序列是有效的,约束可以由CRF层在训练过程中从训练数据集自动学习。
最终的输出可能会产生多种标签序列组合,如下图所示列举了三个标签路径组合,红色路径标签序列为 [B-C,I-C, ...,,B-P,I-P,...,O],蓝色标签序列为 [O,B-P,...,I-P,O,..., O],绿色标签序列为 [I-C,O,...,O,I-P,...,B-C],红色路径为真实正确的,其他两条为可能预测产生的路径。
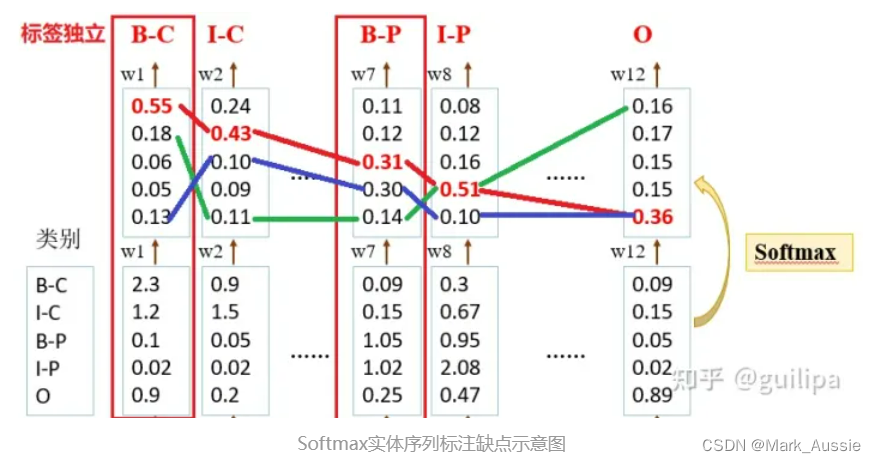
很多标签路径预测结果是错误的,比如绿色路径中,I-C不可能作为序列的起始标签,标签O后面不可能是I-P标签,所以标签之间的转移关系和标签本身的属性对实体标签预测作用很大。
CRF正是通过数据学习标签转移关系和一些约束条件,帮助模型选择正确合理的实体标签序列,减少无效的实体标签序列的预测判断,模式约束例举如下:
- 文本第一个单词的实体标签应该以 'B-' 、'O' 开头,而不是 'I-' ;
- ' B-label1 I-label2 I-label3 I-…'模式中,label1、label2、label3等应该是相同的实体标签;
- 一个命名实体的第一个标签应该以 'B-' 而不能是 'I-' 开头;
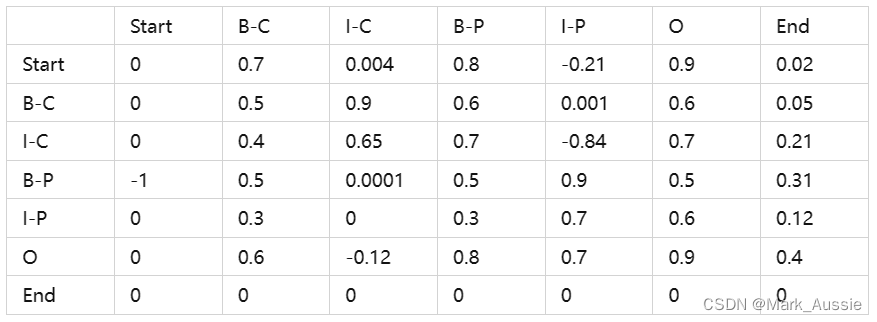
CRF在训练过程中通过数据学习一个标签转移关系关系矩阵 transaction ∈ (k*k),矩阵是CRF的参数,通过数据集训练学习,得到标签之间的关系和标签约束。

参考:

















 4031
4031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









