






 研究了在线学习中数据中毒攻击的新挑战,提出半在线和完全在线的攻击设置,通过优化问题和梯度计算探讨了攻击策略,包括增量、间隔和教导强化攻击。实验显示在线对手对学习率敏感,且学习者越能适应环境,越易受攻击。
研究了在线学习中数据中毒攻击的新挑战,提出半在线和完全在线的攻击设置,通过优化问题和梯度计算探讨了攻击策略,包括增量、间隔和教导强化攻击。实验显示在线对手对学习率敏感,且学习者越能适应环境,越易受攻击。
1 Introduction
随着机器学习算法越来越多地在安全关键型应用中使用,越来越需要在设计时考虑到活跃的对手。备受关注的一类针对机器学习的对抗性攻击是数据中毒攻击 [21,20,19,4,7,11]。在这里,对手知道学习者的训练数据和算法,并且有能力改变一小部分训练数据,以使经过训练的分类器满足某些目标。例如,作为工业破坏活动的一部分,破坏对手可能会试图降低经过训练的分类器的整体准确性,或者以利润为导向的对手可能会试图毒害训练数据,以便最终的模型有利于它——例如,通过推荐其产品优于其他产品。
虽然之前有很多关于数据中毒的工作 [21,20,19,4,7,11,3,8],但其中大部分都集中在离线环境中,其中训练分类器或其他模型在固定输入上。然而,在机器学习的许多应用中,当数据按顺序到达流中时,训练是在线完成的。这种情况下的数据中毒攻击尚不清楚。
在这项工作中,我们对在线学习的数据中毒攻击发起了系统调查。我们首先将问题形式化为两种设置:半在线和完全在线,这反映了在线学习算法的两个不同用例。在半在线设置中,下游仅使用训练结束时获得的分类器,因此对手的目标仅涉及最终的分类器。在完全在线的设置中,分类器不断更新和评估,对应于代理不断学习和适应不断变化的环境的应用程序——例如,预测股票市场价格变化的工具。在这种情况下,对手的目标涉及在整个在线窗口中积累的分类器。
接下来我们考虑通过在线梯度下降进行在线分类,并将对手的攻击策略制定为优化问题;我们的公式涵盖了半在线和完全在线设置,并进行了适当的修改,并且非常普遍地适用于许多攻击目标。我们表明,该公式与相应的离线公式[11]有两个关键差异,导致解决方法的差异。第一个是,与离线情况不同,离线情况下估计的分类器是经验风险的最小者,这里的分类器是数据流的一个更复杂的函数,这使得梯度计算非常耗时。第二个区别是数据顺序现在很重要,这意味着修改流中某些位置的训练点可能会产生很高的收益;成功的攻击可能会利用此属性来减少搜索空间。
然后,我们提出一个使用三个关键步骤的解决方案。
首先,我们通过平滑目标函数并在需要时使用称为标签反转的新颖技巧来简化优化问题。
其次,我们使用链式法则递归计算梯度。
第三步也是最后一步是通过修改输入流中某些位置的数据点来缩小梯度上升的搜索空间。
我们提出了三种这样的修改方案——增量攻击,对应于贪婪方案的在线版本,
间隔攻击,对应于找到要修改的最佳连续序列,
最后是教导和强化攻击,旨在教导分类器通过有选择地修改数据流开头的输入来遵循对手的目标,然后通过沿流的其余部分统一修改输入来强化教学。
最后,我们进行了详细的实验,在对手的背景下评估这些攻击,对手试图降低四个数据集、两种设置(半在线和完全在线)以及三种学习率风格的分类错误。我们的实验表明,在这种情况下,在线对手确实比那些忽视问题在线性质的对手更强大。此外,我们表明攻击的严重程度取决于学习率和设置;学习率快速下降的在线学习者更容易受到攻击,半在线环境也是如此。最后,我们简要讨论了我们的工作对构建有效防御的影响。
相关工作。之前关于数据中毒的工作主要关注离线学习算法。这包括对垃圾邮件过滤器 [13] 和恶意软件检测 [15] 的攻击,以及最近关于情感分析 [14] 和协作过滤 [8] 的工作。 [2]开发了第一个针对离线SVM的基于梯度上升的中毒攻击;该技术后来扩展到神经网络[12]。 Mei和Zhu[11]提出了一种离线环境下中毒攻击的通用优化框架;他们展示了如何使用 KKT 条件来有效计算梯度上升的梯度。虽然我们的工作受到 [2] 和 [11] 的启发,但我们案例中的优化问题要复杂得多,并且 [11] 中的 KKT 条件不再适用。最后,斯坦哈特等人。 [17]提出了针对离线数据中毒攻击的经过认证的防御。
相比之下,人们对在线和自适应环境中的中毒攻击知之甚少。与我们最接近的工作是[4],它毒害了数据流,使得最终的分类器对预先指定的输入进行了错误分类;相比之下,我们的设置就比较笼统了。 [1] 通过改变初始输入来攻击自回归模型以产生所需的输出;然而,他们的攻击不会改变模型参数,也无法访问训练过程。斯坦哈特等人。 [17]使用在线学习框架来生成中毒数据集,但它们的攻击和认证防御都适用于离线学习算法。最后,[6]和[9]考虑了针对强化学习代理的攻击。然而,这些攻击仅在测试时使用梯度方法提供对抗性示例;策略已经被学习,攻击者无法访问训练过程。
2 设置
2.1 分类设置及算法
我们考虑二元线性分类的在线学习。具体来说,我们有从实例空间 Rd 中提取的实例 x,以及二进制标签 y ∈ {−1, +1}。线性分类器由权重向量w表示;对于实例 x,它预测标签 sgn(w>x)。对于特定的分类问题,该权重向量w是根据训练数据确定的。
在离线学习中,权重向量 w 是通过最小化训练数据上的凸经验损失 ` 加上正则化器 Ω(w) 来学习的。相反,在在线学习中(本文的设置),训练数据集 S 以流 {(x0, y0),... 的形式到达。 。 。 , (xt, yt), . 。 .};从初始 w0 开始,在时间 t,基于当前示例 St = (xt, yt),迭代地将权重向量 wt 更新为 wt+1。
自从[10]的经典工作以来,在许多环境中已经有大量关于在线学习的工作[5]。在这项工作中,我们考虑分布式环境中的在线学习,其中每个 (xt, yt) 都是从基础数据分布 D 中独立抽取的。作为我们的学习过程,我们选择流行的在线梯度下降 (OGD) 算法 [22],该算法在时间 t,执行以下更新:
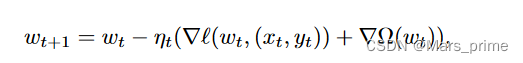
回想一下,这里 ` 是凸损失函数,Ω 是正则化器。例如,在流行的 L2 正则化逻辑回归中,` 是逻辑函数:`(w, (x, y)) = log(1 + e−yw>x) 和 Ω(w) = c/2 ‖w‖ 2 对于某个常数c。此外,ηt 是一个学习率,通常会随着时间的推移而减小。我们用T来表示数据流的长度。
2.2 The Attacker
----
攻击者
继之前关于数据中毒的研究[11, 7]之后,我们考虑一个白盒对手。具体来说,攻击者知道整个数据流(包括数据顺序)、模型类、训练算法、任何超参数以及可能采用的任何防御措施。有了这些知识,对手就有能力任意修改流中最多 K 个示例 (xt, yt)。虽然这是一个强有力的假设,但它已在许多先前的工作中使用过[11,7,2,4]。众所周知,默默无闻的安全是一种不好的做法,并且会导致陷阱 [3]。此外,攻击者通常可以对机器学习系统的参数进行逆向工程 [18, 16]。
我们考虑两种不同类型的攻击目标——半在线和完全在线——对应于在线学习的两种不同实际用途。接下来,我们使用符号 f (w) 来表示依赖于特定权重向量 w 的攻击目标函数。
半在线。这里,攻击者试图修改训练数据流,以便在训练结束时获得的分类器 wT 上最大化其目标 f (wT )。当使用在线或流式算法来训练分类器,然后直接在下游应用程序中使用时,此设置适用。
在这里,训练阶段使用在线算法,但目标的评估仅在流的末尾进行。与经典的离线数据中毒攻击设置 [2, 17] 相比,攻击者现在对训练数据的处理顺序有了额外的了解。
完全在线。在这里,攻击者试图修改训练数据,以便在整个在线学习窗口中最大化累积的目标。更具体地说,攻击者的目标现在是最大化 ΣT t=1 f (wt)。这种设置被称为完全在线,因为训练过程和目标的评估都是在线的。它对应于应用程序中的对手,其中代理不断在线学习,从而不断适应不断变化的环境;这种学习器的一个例子是预测股票市场价格变化的金融工具。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









