







作者:MiTu_-_
KMP & IKMP_pre _cur 算法详细讲解
前言
KMP 到底是怎么实现的呢?它的原理是什么呢?为什么网上的 KMP 算法五花八门,算法实现都各不相同呢?为什么 next[0] 有的为 0,有的又为 1呢?
相信大家都被 KMP 算法困扰过,我也是其中的一个受害者。为此我花了几天的时间将KMP算法进行了深度的研究,在此把我的经验分享给大家,不从数学公式入手,直接从例子讲解,到代码讲解。话不多说,进入正题。
注意,我这里所讲的字符串和 next[] 数组都是从下标为 0 开始存储的。和严版不同,后面我会提到严版的算法实现。
1. Brute-Force
传统暴力匹配算法基本思想是:从主串 S 的第 i 个字符起,和模式串的第 j 个字符进行匹配,若相等,则 i、j 各指向下一个字符,再匹配;否则从主串的下一个字符 i + 1和模式串的第一个字符再重新比较。直至匹配所有模式串字符算匹配成功,否则匹配失败。下图为该算法实现的详图和具体算法实现。
int Index(SString S, SString T)
{
//返回字串T在主串S中的位置,否则函数返回0
int i, j; //i->主串 j->模式串
i = 0; j = 0;
while (i < S.length && j < S.length)
{
if (S.data[i] == T.data[j])
{
++i; ++j; //继续匹配后面的字符
}
else
{
i = i - j + 2; //主串的指针后退,指向该匹配的下一位
j = 0; //模式串的指针指向第一个字符,从头继续和主串比较
}
}
if (j >= T.length) //若在主串中匹配出模式串的所有字符
return i - T.length;
else
return 0;
}

这是最简单也是最容易想到的一个算法,但是效率太低。设主串长度为 n,模式串长度为 m,此算法的最坏时间复杂度为 O(m*n)。
2. KMP
于是 K、M、P 三位看不下去了,便想出 KMP 算法。
我们规定:当主串字符 i 和模式串字符 j 匹配成功时,你就相当于知道了 i 是什么字符;否则不知道。
我们看下图,当第一趟匹配时,i=2、j=2 时,字符不匹配,这时无须将 i 后退到 1,j 后退到 0 重新匹配,因为你已经知道了 i=1(这个最大后缀字符串)的字符是 b 了,而( 后缀字符串)b 是不可能和模式串的 a 进行匹配,因此进行重新匹配,即 i=2、j=0 进行匹配。
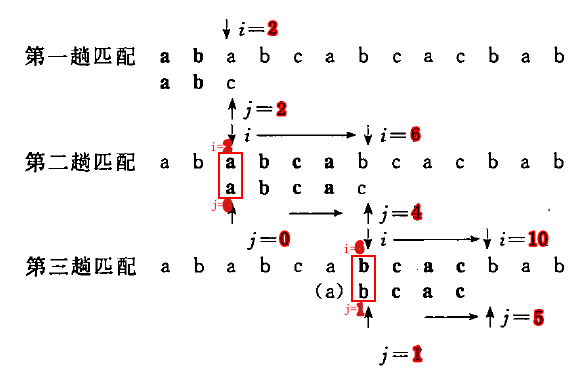
当第二趟匹配时,i=6、j=4 时,字符不匹配,同样的道理,你已经知道了 i=3~5 (这个最大后缀字符串)的所有字符,而且(后缀字符串) i=5 的字符是 a,刚好是模式串所能匹配的最大前缀字符串 a 了,因此进行重新匹配,即 i=6 、j=1 进行匹配。
大家注意我上面用了几个词:“前缀字符串”,“后缀字符串”,“最大前缀字符串”,“最大后缀字符串”。
没错,KMP 算法就是让模式串指针 j 回溯到什么位置,而这关键就在于找最大相等前后缀字符串长度。
KMP 算法的基本思想是:每一趟匹配过程中出现字符比较不等时,不需要回溯 i 指针,而只需回溯 j 指针,利用已经得到的 “部分匹配串” 将模式串向右 “滑动” 尽可能远的距离后,进行再匹配。
而这个 “部分匹配串” 就是最大相等前后缀字符串。
(1)前缀、后缀是什么?
可能有小伙伴还不知道前缀串和后缀串是什么,我就来讲解一下。
- 前缀字符串:包含首字符而不包含尾字符的字符串。
- 后缀字符串:包含尾字符而不包含首字符的字符串。
例如字符串 ‘abaabcac’,那么
- 前缀字符串的所有集合:{a,ab,aba,abaa,abaab,abaabc,abaabca}
- 后缀字符串的所有集合:{c,ac,cac,bcac,abcac,aabcac,baabcac}
相信这么讲解大家应该能明白什么是前缀字符串和后缀字符串了,那么 KMP 算法的关键为什么是找最大相等前后缀字符串呢?
可以再回顾前面的例子,我们每次匹配不等时,都是让模式串的前缀字符串和主串从 i 的上次起始位置到 i-1的这部分的后缀字符串 让它们最大匹配相等,即最大相等前后缀字符串。
设主串长度为 n,模式串长度为 m,此算法改进就在于无须再回溯 i,只需比较 n 次,直接将模式串与主串的最大前后缀字符串相匹配后,再比较下一位即可。且求 next [ ] 数组时间复杂度为 n,因此 KMP 的最坏时间复杂度为 O(m+n)。
手算 next[ ]:
我们先来手算一下最大相等前后缀字符串长度。在此我就用 MES 表示最大相等前后缀字符串长度了
- ‘a’:因为它就没有前后缀字符串,MES 恒等于 0
- ‘ab’:前缀字符串集合 {a},后缀字符串集合 {b},MES=0
- ‘aba’:前缀字符串集合 {a,ab},后缀字符串集合 {a,ba},MES=1
- ‘abaa’:前缀字符串集合 {a,ab,aba},后缀字符串集合 {a,aa,baa},MES=4
- ‘abaab’:前缀字符串集合 {a,ab,aba,abaa},后缀字符串集合 {b,ab,aab,baab},MES=2
- ‘abaabc’:前缀字符串集合 {a, ab,aba,abaa,abaab},后缀字符串集合 {c,bc,abc,aabc,baabc},MES=0
- ‘abaabca’:前缀字符串集合 {a,ab,aba,abaa,abaabc},后缀字符串集合 {a,ca,bca,abca,aabca,baabca},MES=1
- ‘abaabcac’:前缀字符串集合 {a,ab,aba,abaa,abaabc,abaabbca},后缀字符串集合 {c,ac,bca,abcac,aabcac,baabcac},MES=0
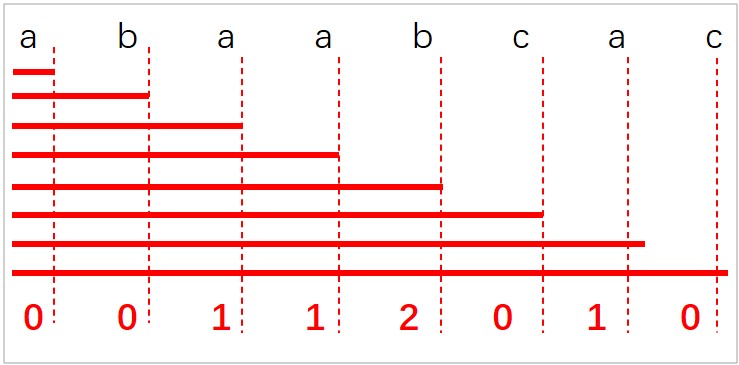
我们用一个 next[] 数组把这些最大相等前后缀字符串长度存储起来,如下图所示:

当我们进行匹配时,就可以用这个数组直接让模式串的指针 j 进行回溯了,如下图所示:
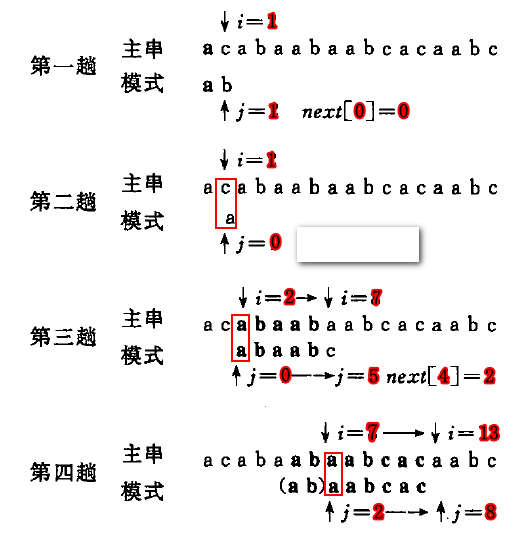
(1)第一趟:当 i=1,j=1 不匹配时,看 i=1~1 的 MES,即 next[0] = 0,因此让 j 回溯到 0
(2)第二趟:当 i=1,j=0 不匹配时,由于还没和模式串进行匹配,无法让 j 再往前回溯了,只能让主串向后移动一位
(3)第三趟:当 i=7,j=5 不匹配时,看 i=3~7 的MES,即 next[4] = 2,因此让 j 回溯到 2
大家可以发现,j 和 next[ ] 数组有着某种关联,对了:
- ① next[j - 1] 里存储着主串从 i 的上次起始位置到 i-1的这部分的最大相等前后缀长度
- ② 即 j 要回溯的位置
我们要注意,当模式串指针 > 0 时,等主串和模式串不匹配时,j 要回溯的位置是它前面一位的 next 值,即 next[j - 1]
(2)KMP_pre(0)
明白了上面两层含义,那么你对 KMP 算法就算了解的差不多了,就可以看下面的代码了。没懂得也可以自己思考思考,或者看看下面的代码,也可以对你前面的知识进行一个反馈,让你豁然开朗。
KMP_pre 算法
typedef struct {
char data[MAXSIZE];
int length;
} SString;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 534
534











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









