







Chisel学习——设计n位超前进位加法器生成器(Carry-Lookahead Adder Generator)
文章目录
一,项目简介
本项目是复旦大学《嵌入式处理器与芯片系统设计(H)》的一项练习,旨在练习使用Chisel进行电路设计,并感受Chisel的便利。笔者基于超前进位加法器(CLA),设计了一个最高可达64位的加法器生成器。
本项目源代码见GitHub:AdderGen
二,理论基础
2.1 Chisel
Chisel(Constructing Hardware In a Scala Embedded Language)是UC Berkeley开发的一种开源硬件构造语言。它是建构在Scala语言之上的领域专用语言(DSL),兼顾面向对象和函数式编程两大特性,并支持高度参数化的硬件生成器。Chisel的便利使得硬件设计、模块例化大大简化。因此,本项目将使用Chisel而非Verilog进行电路设计,当然,最后的Chisel代码也会被转译成Verilog。
2.1 硬件生成器(Hardware Generator)
硬件生成器是一类带参数的Module,这些参数是我们在设计电路时可以故意留下的,可供用户选择。常见的IP core便是典型的硬件生成器。由于Chisel中每个Module都是一个类,而类是可以传入参数的,因此使用Chisel设计硬件生成器相当方便。
以下是使用Chisel设计带参加法器的示例:
class ParamAdde r ( n: Int ) extends Module {
val io = IO ( new Bundle {
val a = Input(UInt(n.W))
val b = Input(UInt(n.W))
val c = Output(UInt(n.W))
} )
io.c : = io.a + io.b
}
在例化时传入对应的参数即可
val add8 = Module(new ParamAdder(8))
val add16 = Module(new ParamAdder(16)
2.2 常规行波进位加法器(RCA,Ripple-Carry Adder)
2.2.1 设计方法
为了更好理解超前进位加法器的优越性,我们先简单了解最为基础的行波进位加法器。
最基本的全加器如下:
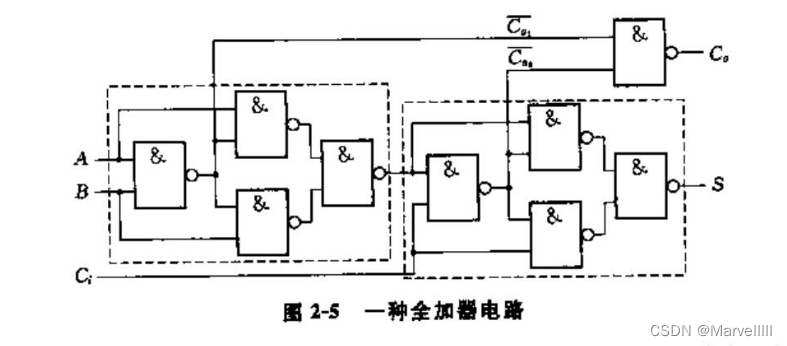
其逻辑函数为
S = A ⊕ B ⊕ C i C o = A B + ( A ⊕ B ) C i S = A \oplus B \oplus C_i\\C_o = AB + (A \oplus B)C_i S=A⊕B⊕CiCo=AB+(A⊕B)Ci
注:式中的+号表示或运算,x号表示与运算。
而n位的加法器可以由n个一位加法器串联,如图所示。
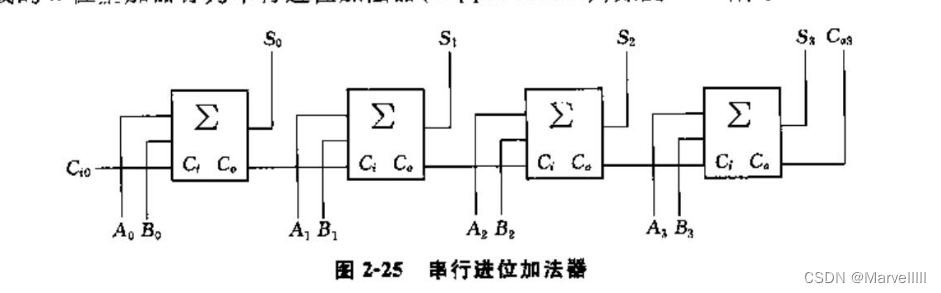
2.2.2 性能评估
上述电路在设计上相当便利,不管多少位,设计者只要傻瓜式地串联即可。但这是以系统速度的降低为代价的。
由一位全加器的电路图可知,该电路的关键路径为:
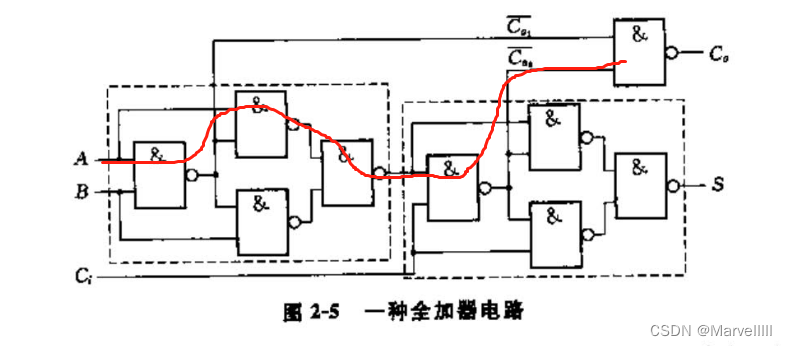
一共有5级门电路的时延。
后续串接的高位全加器中,从低位的 C o C_o Co以 C i C_i Ci的身份传进来(此时高位全加器的关键路径中的前三级时延早已完成),到得出本 位的 C o C_o Co,还需要再经历2级时延。因此对于n位行波进位加法器,时延为 5 + 2 ( n − 1 ) = 2 n + 3 5+2(n-1)=2n+3 5+2(n−1)=2n+3级。16位的RCA时延就是35级,不 可忍受!
由此可见,高位的RCA中时延相当高,并不符合现代人类对高速运算的要求。
2.3 超前进位加法器(CLA,Carry-Lookahead Adder)
2.3.1 超前进位
为了改善多位加法器电路的速度问题,需要仔细研究影响加法器速度的因素。由上述讨论可知:全加器的本位算术和不造成延时,系统的延时问题只是由于串行进位的延时造成。并行处理是计算机体系架构的一个重要方向。如果将进位由串行处理改成并行处理,即信号刚输入时,就能根据所有的输入算出每一位的进位,那么由串行进位导致的高时延就可以被避免。这种技术称为超前进位(Look-ahead Carry)技术。
全加器的逻辑函数为:
S i = A i ⊕ B i C i = A i B i + A i C i − 1 + B i C i − 1 S_i = A_i \oplus B_i\\C_i = A_iB_i+A_iC_{i-1}+B_iC_{i-1} Si=Ai⊕BiCi=AiBi+AiCi−1+BiCi−1
研究进位的表达式,将其改写为: C i = A i B i + ( A i + B i ) C i − 1 = G i + P i C i C_i = A_iB_i+(A_i+B_i)C_{i-1}= G_i+P_iC_i Ci=AiBi+(Ai+Bi)Ci−1=Gi+PiCi
其中 G i = A i B i G_i = A_iB_i Gi=AiBi,称为进位产生信号(Carry Generate); P i = A i + B i P_i=A_i+B_i Pi=Ai+Bi,称为进位传播信号(Pass)
可以看出,每一位的信号都与低一位的进位信号有关,但我们可以将低一位信号进一步拆解,不断递归,直至表达式里只有输入信号。
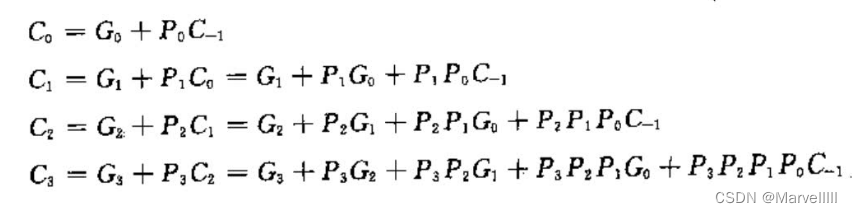
将式中的 G i G_i Gi和 P i P_i Pi展开便可发现:利用上式,我们可以在一开始,仅经历一级门电路的延时,就计算出每一位的进位。
基于这种预判进位的思想,我们便可着手设计一个免受进位延时限制的加法器。
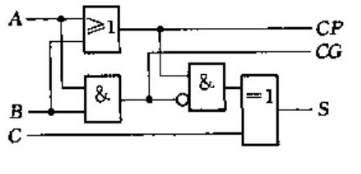
2.3.2 全加器迭代单元
按照国家标准,我们将 G G G和 P P P分别记为 C G CG CG和 C P CP CP。 { C G = A B C P = A + B S = ( C G ‾ × C P ) ⊕ C \begin{cases}CG = AB\\CP=A+B\\S=(\overline{CG}\times CP)\oplus C\end{cases} ⎩ ⎨ ⎧CG=ABCP=A+BS=(CG×CP)⊕C
超前进位加法器最基本的迭代单元如下,它是一个一位全加器,只不过进位信号 C O CO CO被拆成了 C P CP CP和 C G CG CG。若想复原,只需再进行两级运算 C O = C G + C P × C CO = CG + CP\times C CO=CG+CP×C即可
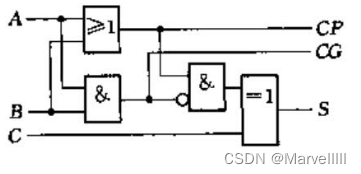
2.3.3 全加器迭代结构
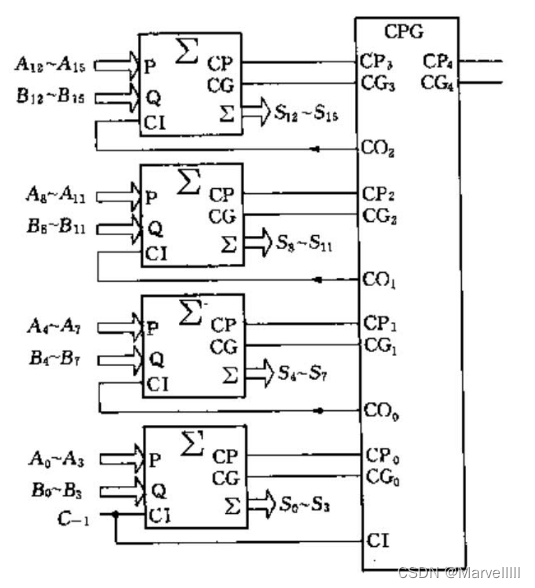
根据2.2.2.1节中的公式,我们进位信号的“预判”模块电路图如下:
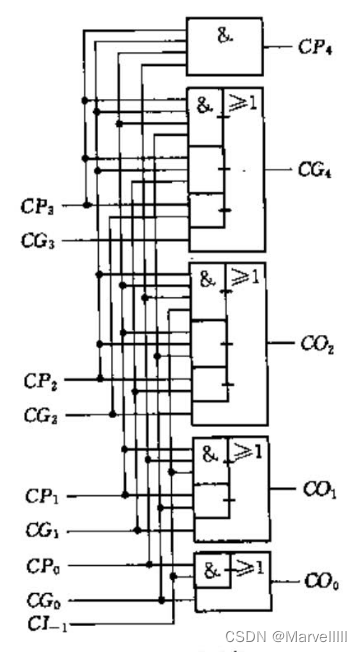
其中, { C P 4 = C P 3 × C P 2 × C P 1 × C P 0 C G 4 = C G 3 + C P 3 × C G 2 + C P 3 × C P 2 × C G 1 + C P 3 × C P 2 × C P 1 × C G 0 \begin{cases}CP_4 = CP_3\times CP_2 \times CP_1 \times CP_0\\CG_4=CG_3+CP_3\times CG_2+CP_3\times CP_2 \times CG_1 + CP_3\times CP_2 \times CP_1\times CG_0\end{cases} {CP4=CP3×CP2×CP1×CP0CG4=CG3+CP3×CG2+CP3×CP2×CG1+CP3×CP2×CP1×CG0,是为了进一步迭代而预留的接口信号,具体作用详见后续16位和64位的加法器设计。
将其封装为CPG模块:

2.3.4 超前进位加法器(4位)
将4个迭代单元和一个CPG模块相连,便可得到一个4位超前进位全加器。
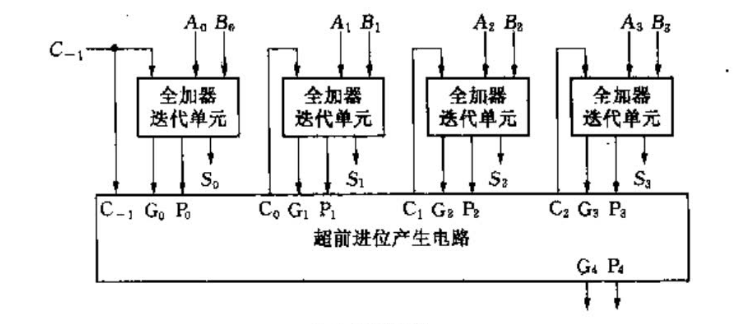
我们复原进位信号 C 4 = C G 4 + C P 4 × C − 1 C_4 = CG_4 + CP_4\times C_{-1} C4=CG4+CP4×C−1,即可得到一个完整的四位加法器。
2.3.5 性能评估
分析电路图可知,每一位 C G CG CG和 C P CP CP信号的产生需要一级门电路时延,而从 C G CG CG和 C P CP CP产生进位信号 C C C需要2级时延,因此每个进位信号总共只需要3级时延。而从 C C C产生结果信号 S S S,只需要1级时延。因此整个4位超前进位加法器一共只有4级门电路时延。
但该加法器的缺陷也很明显,由CLU的公式可知,随着位数的增加,实现CLU的门电路数量会急剧增加,导致电路面积开销过大;另一方面,位数的增加也会使扇入飞速增大,导致时延增加。
因此,这是一个“用空间换时间”的设计思路。我们应该尽可能在复杂度和速度间取得平衡。用量化的思路来看, 性能 = F ( 复杂度,速度 ) 性能=F(复杂度,速度) 性能=F(复杂度,速度) 我们应该找到这个性能函数的极大值点。
2.3.6 超前进位加法器(16位)
由上述分析可知,在位数增大时,单纯的递归并非良计。我们必须另寻出路。
一个简单的办法是,在设计完4位CLA后,回归传统的行波进位加法器RCA,将一个个4位CLA串联起来。低4位的单元的进位信号有3级时延,其他都是2级(因为 C P CP CP和 C G CG CG的产生在第一个单元还在延时的时候便已完成),因此,这样一个n位加法器的时延就是 3 + 2 × ( n 4 − 1 ) 3+2\times (\frac{n}{4}-1) 3+2×(4n−1)级。比如,一个16位加法器的时延便是9级。已经很低,但我们还可以进一步探索其他设计思路。
不难发现,4位加法器的最终进位信号 C 4 = C G 4 + C P 4 × C − 1 C_4 = CG_4 + CP_4\times C_{-1} C4=CG4+CP4×C−1,和最低位的进位信号 C 0 = C G 0 + C P 0 × C − 1 C_0=CG_0+CP_0\times C_{-1} C0=CG0+CP0×C−1形式相同。因此,要想构建16位加法器,我们似乎可以使用“嵌套”的思想,将一个4位CLA作为迭代单元,仿照4位CLA的结构,构建出16位CLA。
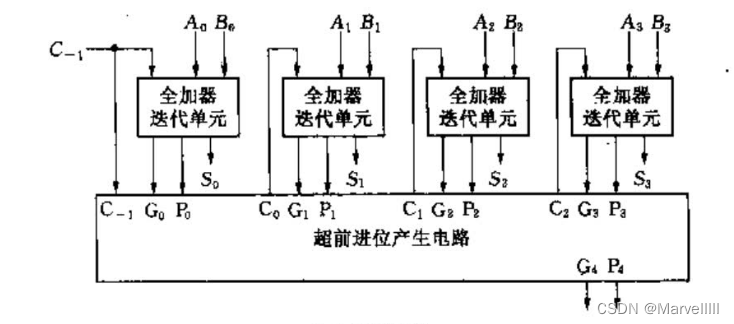
这样一来,电路的主要时延已不再是进位信号,因为该电路连最终的 C P 4 CP_4 CP4和 C G 4 CG_4 CG4都只需要4级(4位CLA内部的 C P 4 、 C G 4 CP_4、CG_4 CP4、CG4需要2级,产生最终的 C P 4 、 C G 4 CP_4、CG_4 CP4、CG4也是2级)。此时电路的关键路径应该是从 C − 1 C_{-1} C−1到 S i S_i Si这一条。从信号输入到图中的 C O i CO_i COi产生,共历4级时延(4位CLA内部的 C P 4 、 C G 4 CP_4、CG_4 CP4、CG4需要2级,由它们产生图中的 C O i CO_i COi又要2级),此后,在4位CLA内部,低位进位信号 C O i CO_i COi又历经1级门电路才产生结果信号 S S S。因此,该电路总时延为 4 + 1 = 5 4+1=5 4+1=5级。速度又进一步提升。
但是,由于一个CPG模块有18个门电路,而这种16位2级CLA用到了5个CPG模块,因此比最原始的16位行波进位加法器多了90个门电路,比刚刚提到的4个4位CLA串行多了18个门电路。可见,这确实是一种用空间换时间的设计方法。
2.3.7 超前进位加法器(64位)
仿照上述“递归+嵌套”的2级CLA,我们可以再加一级,设计一个3级CLA。即将16位CLA作为迭代单元,嵌入到同样的结构中,构成64位CLA。
三,项目设计
3.1 全加器迭代单元
就是这个图,无难度。
package test
import chisel3._
class FullAdder extends Module {
val io = IO(new Bundle {
val A = Input(UInt(1.W))
val B = Input(UInt(1.W))
val C = Input(UInt(1.W))
val S = Output(UInt(1.W))
val CG = Output(UInt(1.W))
val CP = Output(UInt(1.W))
})
io.CG := io.A & io.B
io.CP := io.A | io.B
io.S := (io.CP & (~io.CG)) ^ io.C
}
3.2 超前进位逻辑模块
电路图如下
代码如下:
package test
import Chisel.Cat
import chisel3._
class CPG extends Module {
val io = IO(new Bundle {
val CI = Input(UInt(1.W))
val CG = Input(Vec(4,UInt(1.W)))
val CP = Input(Vec(4,UInt(1.W)))
val CO = Output(Vec(3,UInt(1.W)))
val CP4 = Output(UInt(1.W))
val CG4 = Output(UInt(1.W))
})
io.CO(0) := io.CG(0) | (io.CP(0) & io.CI)
io.CO(1) := io.CG(1) | (io.CP(1) & io.CG(0)) | (io.CP(1) & io.CP(0) & io.CI)
io.CO(2) := io.CG(2) | (io.CP(2) & io.CG(1)) |
(io.CP(2) & io.CP(1) & io.CG(0)) |
(io.CP(2) & io.CP(1) & io.CP(0) & io.CI)
io.CP4 := io.CP(0) & io.CP(1) & io.CP(2) & io.CP(3)
io.CG4 := io.CG(3) | (io.CP(3) & io.CG(2)) |
(io.CP(3) & io.CP(2) & io.CG(1)) |
(io.CP(3) & io.CP(2) & io.CP(1) & io.CG(0))
}
这里将 C G CG CG 声明为 V e c ( 4 , U I n t ( 1. W ) ) Vec(4,UInt(1.W)) Vec(4,UInt(1.W)),一个由4个1位宽的UInt类组成的向量,而没有直接声明为一个4位UInt类,是因为每个 C G i CG_i CGi的逻辑函数都不一样,必须逐个赋值。而Chisel中信号一般定义为val,只能赋值一次。一个4位UInt类为一个整体,对单个位上赋值视为对整体赋值,该位赋完后其他位就不能赋了。而Vec类没有这个问题,我们可以对Vec中的元素挨个赋值。
定义为UInt(4.W)类会出现如下error:

此外,为了方便调用,我们在伴生对象里定义了apply方法:
object CPG{
def apply(CI:UInt,CG:Vec[UInt],CP:Vec[UInt])={
val m = Module(new CPG).io
m.CI := CI
m.CP := CP
m.CG := CG
(m.CO,m.CG4,m.CP4)
}
}
3.3 n位超前进位加法器
有了迭代单元和CPG模块,我们就可以着手连接多位CLA了。
一开始我还是沿用设计Verilog的思路,将4、16位CLA的模块一个个写出来,然后再慢慢连线,如图。
一通操作下来,感觉并没有比Verilog便利…这是因为我们没有利用到Chisel高级语言的特点。
应该如何优化呢?我们先观察4位加法器的代码:
val S = Wire(Vec(4,UInt(1.W)))
val CG = Wire(Vec(4,UInt(1.W)))
val CP = Wire(Vec(4,UInt(1.W)))
val (co,cg4,cp4) = CPG(io.CI,CG,CP)
for(i <- 0 to 3) {
if (i == 0) {
val (s, cg, cp) = FullAdder(io.A(i), io.B(i), io.CI)
S(i) := s
CG(i) := cg
CP(i) := cp
}
else {
val (s, cg, cp) = FullAdder(io.A(i), io.B(i), co(i - 1))
S(i) := s
CG(i) := cg
CP(i) := cp
}
}
再观察16位加法器的代码:
val S = Wire(Vec(4,UInt(4.W)))
val CG = Wire(Vec(4,UInt(1.W)))
val CP = Wire(Vec(4,UInt(1.W)))
val (co,cg4,cp4) = CPG(io.CI,CG,CP)
for (i <- 0 to 3) {
if (i == 0) {
val (s, cg, cp) = CLAdder4(A(3+4*i,4*i), B(3+4*i,4*i), CI)
S(i) := s
CG(i) := cg
CP(i) := cp
}
else {
val (s, cg, cp) = CLAdder4(A(3+4*i,4*i), B(3+4*i,4*i), co(i - 1))
S(i) := s
CG(i) := cg
CP(i) := cp
}
}
val S_UInt = Cat(S(3),S(2),S(1),S(0))
(S_UInt,cg4,cp4)
不难发现,4位和16位加法器最顶层的那一级结构是相同的,都是4个迭代单元+1个CPG模块的形式:
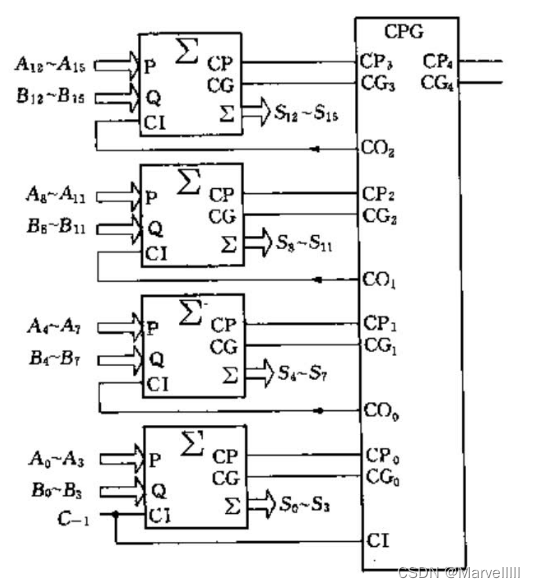
只不过在参数和迭代单元方面有一些区别。4位CLA的迭代单元是1位全加器,16位CLA的迭代单元是4位CLA;4位CLA给每个Unit传入一位数字,而16位CLA给每个Unit传入4位数字。既然结构相同,参数有规律可循,那我们大可以利用Chisel的高级语言特性,将各级CLA的数据通路给整合成一个模板。
优化后的代码如下:
package test
import chisel3._
// n是加法器位数,可取4、16、64
class AdderGen (n:Int) extends Module {
val io = IO(new Bundle() {
val A = Input(UInt(n.W))
val B = Input(UInt(n.W))
val CI = Input(UInt(1.W))
val S = Output(UInt(n.W))
val CO = Output(UInt(1.W))
})
// 定义一个FullAdder函数,调用最基本的一位全加器迭代单元
def FullAdder(A: UInt, B: UInt, C: UInt = 0.U): (UInt, UInt, UInt) = {
val m = Module(new FullAdder).io
m.A := A
m.B := B
m.C := C
(m.S, m.CG, m.CP)
}
// AdderX,类似模板函数,是CLA中某一级的数据通路,根据传入的Adder函数,生成不同的函数
def AdderX(A:UInt,B:UInt,CI:UInt,Adder:(UInt,UInt,UInt)=>(UInt,UInt,UInt),n:Int)={
val k = n/4 //3级嵌套结构中,每一个迭代单元的输入和输出都有16位;2级有4位;1级有1位。
val S_Vec = Wire(Vec(4, UInt(k.W))) //每一级里都由4个迭代单元和一个CPG组成,所以都切成4段
val CG = Wire(Vec(4, UInt(1.W)))
val CP = Wire(Vec(4, UInt(1.W)))
val (co, cg4, cp4) = CPG(CI, CG, CP)
for (i <- 0 to 3) {
val (s, cg, cp) = Adder(A(k-1+k*i,k*i), B(k-1+k*i,k*i), if (i == 0) CI else co(i - 1))
S_Vec(i) := s //模板函数参数较多,可读性较差,读者可将具体值代进去试试
CG(i) := cg //比如4位CLA,k=1,那便是A(i);
CP(i) := cp //16位CLA,k=4,即A(3+4i,4i),因为16位CLA以4位CLA为迭代单元,所以每次输入4位
} //64位CLA,k=16,以16位CLA为迭代单元,所以A(15+16i,16i),每次传入16位
val S = S_Vec.asUInt
(S,cg4,cp4)
}
//利用scala特性———部分应用函数,将AdderX例化为具体的函数
val CLAdder4 = AdderX(_:UInt,_:UInt,_:UInt,FullAdder,4)
val CLAdder16 = AdderX(_:UInt,_:UInt,_:UInt,CLAdder4,16)
val CLAdder64 = AdderX(_:UInt,_:UInt,_:UInt,CLAdder16,64)
// 对n进行判断,生成对应位数的加法器
if(n == 4){
val (s, cg, cp) = CLAdder4(io.A,io.B,io.CI)
io.S := s
io.CO := cg | (cp & io.CI)
}
else if(n == 16){
val (s, cg, cp) = CLAdder16(io.A,io.B,io.CI)
io.S := s
io.CO := cg | (cp & io.CI)
}
else if(n == 64){
val (s, cg, cp) = CLAdder64(io.A, io.B, io.CI)
io.S := s
io.CO := cg | (cp & io.CI)
}
else{
println("error")
}
}
可以看到,我们尽情地使用了循环语句等控制结构,参数满天飞。至于具体要生成什么样的硬件,交给用户选择,交给编译器判断。
3.4 考试凳子(testbench)
Testbench的编写如下:
package test
import chisel3._
import chisel3.stage.ChiselStage
import chisel3.tester._
import chiseltest.WriteVcdAnnotation
import org.scalatest._
class Testbench extends FreeSpec with ChiselScalatestTester{
//生成Verilog代码
(new ChiselStage).emitVerilog(new AdderGen(4),Array("--target-dir",s"generated/adder4"))
(new ChiselStage).emitVerilog(new AdderGen(16),Array("--target-dir",s"generated/adder16"))
(new ChiselStage).emitVerilog(new AdderGen(64),Array("--target-dir",s"generated/adder64"))
//定义test函数模板,可以对4、16和64位的CLA进行测试
def test(n:Int): Unit = {
test(new AdderGen(n)).withAnnotations(Seq(WriteVcdAnnotation)) { c =>
val rnd = new scala.util.Random //使用随机数进行测试
val k = if(n<30) n else 30
//k不能大于30,因为下面随机数参数要求是Int类型,而Int的范围是-2^31 ~ 2^31 - 1,同时两个数相加不能溢出,所以也不能取31
//因此无法测试两个64位相加的结果,最多只能测试两个30位数相加,但也足够了,一定程度上可以验证64位CLA
for (i <- 1 to 10) {
val A = rnd.nextInt(math.pow(2, k).toInt) //2的k次方
val B = rnd.nextInt(math.pow(2, k).toInt)
val CI = rnd.nextInt(2)
val ans = A + B + CI
val S = ans & (if(n==4) 0xF else if(n==16) 0xFFFF else ans)
//ans最高为n+1位,我们需要将前n位取出来,64位不需要,因此ans与自己
val CO = if(n!=64) (ans >> n) else 0 //将最高位取出来,64位CLA进位恒为0
c.io.A.poke(A.U)
c.io.B.poke(B.U)
c.io.CI.poke(CI.U)
c.io.S.expect(S.U)
c.io.CO.expect(CO.U)
println(s"${c.io.A.peek.litValue} + ${c.io.B.peek.litValue} + ${c.io.CI.peek.litValue} = ${c.io.S.peek.litValue}, CO = ${c.io.CO.peek.litValue}")
}
}
}
//分别测试4、16和64位的CLA
"test adder4" in {
println("测试4位超前进位加法器")
test(4)
}
"test adder16" in {
println("测试16位超前进位加法器")
test(16)
}
"test adder64" in {
println("测试64位超前进位加法器")
test(64)
}
}
测试结果如下:
测试4位超前进位加法器
7 + 3 + 0 = 10, CO = 0
10 + 10 + 1 = 5, CO = 1
6 + 15 + 0 = 5, CO = 1
0 + 2 + 0 = 2, CO = 0
0 + 8 + 1 = 9, CO = 0
8 + 3 + 0 = 11, CO = 0
15 + 3 + 1 = 3, CO = 1
2 + 14 + 1 = 1, CO = 1
5 + 0 + 0 = 5, CO = 0
13 + 4 + 0 = 1, CO = 1测试16位超前进位加法器
22678 + 11018 + 1 = 33697, CO = 0
47775 + 18645 + 1 = 885, CO = 1
8644 + 51901 + 0 = 60545, CO = 0
2403 + 37372 + 1 = 39776, CO = 0
18956 + 22419 + 0 = 41375, CO = 0
10718 + 57154 + 1 = 2337, CO = 1
41532 + 559 + 0 = 42091, CO = 0
42872 + 65247 + 0 = 42583, CO = 1
40731 + 59009 + 1 = 34205, CO = 1
409 + 48921 + 0 = 49330, CO = 0测试64位超前进位加法器
223374353 + 436534592 + 1 = 659908946, CO = 0
146277248 + 642089187 + 0 = 788366435, CO = 0
760035841 + 1058256319 + 1 = 1818292161, CO = 0
535379425 + 1065848976 + 0 = 1601228401, CO = 0
830466278 + 428384683 + 1 = 1258850962, CO = 0
217153501 + 286658337 + 0 = 503811838, CO = 0
954551388 + 950931423 + 1 = 1905482812, CO = 0
891177935 + 63934487 + 1 = 955112423, CO = 0
887409168 + 1067866945 + 0 = 1955276113, CO = 0
729642159 + 160779941 + 1 = 890422101, CO = 0Process finished with exit code 0
测试通过。
3.5 Verilog与电路图
生成的Verilog代码如下:
module CPG(
input io_CI,
input io_CG_0,
input io_CG_1,
input io_CG_2,
input io_CG_3,
input io_CP_0,
input io_CP_1,
input io_CP_2,
input io_CP_3,
output io_CO_0,
output io_CO_1,
output io_CO_2,
output io_CP4,
output io_CG4
);
wire _io_CO_2_T_2 = io_CP_2 & io_CP_1; // @[CPG.scala 20:25]
wire _io_CO_2_T_3 = io_CP_2 & io_CP_1 & io_CG_0; // @[CPG.scala 20:36]
wire _io_CO_2_T_4 = io_CG_2 | io_CP_2 & io_CG_1 | _io_CO_2_T_3; // @[CPG.scala 19:48]
wire _io_CO_2_T_7 = _io_CO_2_T_2 & io_CP_0 & io_CI; // @[CPG.scala 21:47]
wire _io_CG4_T_2 = io_CP_3 & io_CP_2; // @[CPG.scala 25:23]
wire _io_CG4_T_3 = io_CP_3 & io_CP_2 & io_CG_1; // @[CPG.scala 25:34]
wire _io_CG4_T_4 = io_CG_3 | io_CP_3 & io_CG_2 | _io_CG4_T_3; // @[CPG.scala 24:46]
wire _io_CG4_T_7 = _io_CG4_T_2 & io_CP_1 & io_CG_0; // @[CPG.scala 26:45]
assign io_CO_0 = io_CG_0 | io_CP_0 & io_CI; // @[CPG.scala 17:24]
assign io_CO_1 = io_CG_1 | io_CP_1 & io_CG_0 | io_CP_1 & io_CP_0 & io_CI; // @[CPG.scala 18:48]
assign io_CO_2 = _io_CO_2_T_4 | _io_CO_2_T_7; // @[CPG.scala 20:48]
assign io_CP4 = io_CP_0 & io_CP_1 & io_CP_2 & io_CP_3; // @[CPG.scala 23:44]
assign io_CG4 = _io_CG4_T_4 | _io_CG4_T_7; // @[CPG.scala 25:46]
endmodule
module FullAdder(
input io_A,
input io_B,
input io_C,
output io_S,
output io_CG,
output io_CP
);
assign io_S = io_CP & ~io_CG ^ io_C; // @[FullAdder.scala 18:31]
assign io_CG = io_A & io_B; // @[FullAdder.scala 16:17]
assign io_CP = io_A | io_B; // @[FullAdder.scala 17:17]
endmodule
module AdderGen(
input clock,
input reset,
input [15:0] io_A,
input [15:0] io_B,
input io_CI,
output [15:0] io_S,
output io_CO
);
wire CPG_io_CI; // @[CPG.scala 32:19]
wire CPG_io_CG_0; // @[CPG.scala 32:19]
wire CPG_io_CG_1; // @[CPG.scala 32:19]
wire CPG_io_CG_2; // @[CPG.scala 32:19]
wire CPG_io_CG_3; // @[CPG.scala 32:19]
wire CPG_io_CP_0; // @[CPG.scala 32:19]
wire CPG_io_CP_1; // @[CPG.scala 32:19]
wire CPG_io_CP_2; // @[CPG.scala 32:19]
wire CPG_io_CP_3; // @[CPG.scala 32:19]
wire CPG_io_CO_0; // @[CPG.scala 32:19]
wire CPG_io_CO_1; // @[CPG.scala 32:19]
wire CPG_io_CO_2; // @[CPG.scala 32:19]
wire CPG_io_CP4; // @[CPG.scala 32:19]
wire CPG_io_CG4; // @[CPG.scala 32:19]
wire CPG_1_io_CI; // @[CPG.scala 32:19]
wire CPG_1_io_CG_0; // @[CPG.scala 32:19]
wire CPG_1_io_CG_1; // @[CPG.scala 32:19]
wire CPG_1_io_CG_2; // @[CPG.scala 32:19]
wire CPG_1_io_CG_3; // @[CPG.scala 32:19]
wire CPG_1_io_CP_0; // @[CPG.scala 32:19]
wire CPG_1_io_CP_1; // @[CPG.scala 32:19]
wire CPG_1_io_CP_2; // @[CPG.scala 32:19]
wire CPG_1_io_CP_3; // @[CPG.scala 32:19]
wire CPG_1_io_CO_0; // @[CPG.scala 32:19]
wire CPG_1_io_CO_1; // @[CPG.scala 32:19]
wire CPG_1_io_CO_2; // @[CPG.scala 32:19]
wire CPG_1_io_CP4; // @[CPG.scala 32:19]
wire CPG_1_io_CG4; // @[CPG.scala 32:19]
wire FullAdder_io_A; // @[AdderGen.scala 16:19]
wire FullAdder_io_B; // @[AdderGen.scala 16:19]
wire FullAdder_io_C; // @[AdderGen.scala 16:19]
wire FullAdder_io_S; // @[AdderGen.scala 16:19]
wire FullAdder_io_CG; // @[AdderGen.scala 16:19]
wire FullAdder_io_CP; // @[AdderGen.scala 16:19]
wire FullAdder_1_io_A; // @[AdderGen.scala 16:19]
wire FullAdder_1_io_B; // @[AdderGen.scala 16:19]
wire FullAdder_1_io_C; // @[AdderGen.scala 16:19]
wire FullAdder_1_io_S; // @[AdderGen.scala 16:19]
wire FullAdder_1_io_CG; // @[AdderGen.scala 16:19]
wire FullAdder_1_io_CP; // @[AdderGen.scala 16:19]
wire FullAdder_2_io_A; // @[AdderGen.scala 16:19]
wire FullAdder_2_io_B; // @[AdderGen.scala 16:19]
wire FullAdder_2_io_C; // @[AdderGen.scala 16:19]
wire FullAdder_2_io_S; // @[AdderGen.scala 16:19]
wire FullAdder_2_io_CG; // @[AdderGen.scala 16:19]
wire FullAdder_2_io_CP; // @[AdderGen.scala 16:19]
wire FullAdder_3_io_A; // @[AdderGen.scala 16:19]
wire FullAdder_3_io_B; // @[AdderGen.scala 16:19]
wire FullAdder_3_io_C; // @[AdderGen.scala 16:19]
wire FullAdder_3_io_S; // @[AdderGen.scala 16:19]
wire FullAdder_3_io_CG; // @[AdderGen.scala 16:19]
wire FullAdder_3_io_CP; // @[AdderGen.scala 16:19]
wire CPG_2_io_CI; // @[CPG.scala 32:19]
wire CPG_2_io_CG_0; // @[CPG.scala 32:19]
wire CPG_2_io_CG_1; // @[CPG.scala 32:19]
wire CPG_2_io_CG_2; // @[CPG.scala 32:19]
wire CPG_2_io_CG_3; // @[CPG.scala 32:19]
wire CPG_2_io_CP_0; // @[CPG.scala 32:19]
wire CPG_2_io_CP_1; // @[CPG.scala 32:19]
wire CPG_2_io_CP_2; // @[CPG.scala 32:19]
wire CPG_2_io_CP_3; // @[CPG.scala 32:19]
wire CPG_2_io_CO_0; // @[CPG.scala 32:19]
wire CPG_2_io_CO_1; // @[CPG.scala 32:19]
wire CPG_2_io_CO_2; // @[CPG.scala 32:19]
wire CPG_2_io_CP4; // @[CPG.scala 32:19]
wire CPG_2_io_CG4; // @[CPG.scala 32:19]
wire FullAdder_4_io_A; // @[AdderGen.scala 16:19]
wire FullAdder_4_io_B; // @[AdderGen.scala 16:19]
wire FullAdder_4_io_C; // @[AdderGen.scala 16:19]
wire FullAdder_4_io_S; // @[AdderGen.scala 16:19]
wire FullAdder_4_io_CG; // @[AdderGen.scala 16:19]
wire FullAdder_4_io_CP; // @[AdderGen.scala 16:19]
wire FullAdder_5_io_A; // @[AdderGen.scala 16:19]
wire FullAdder_5_io_B; // @[AdderGen.scala 16:19]
wire FullAdder_5_io_C; // @[AdderGen.scala 16:19]
wire FullAdder_5_io_S; // @[AdderGen.scala 16:19]
wire FullAdder_5_io_CG; // @[AdderGen.scala 16:19]
wire FullAdder_5_io_CP; // @[AdderGen.scala 16:19]
wire FullAdder_6_io_A; // @[AdderGen.scala 16:19]
wire FullAdder_6_io_B; // @[AdderGen.scala 16:19]
wire FullAdder_6_io_C; // @[AdderGen.scala 16:19]
wire FullAdder_6_io_S; // @[AdderGen.scala 16:19]
wire FullAdder_6_io_CG; // @[AdderGen.scala 16:19]
wire FullAdder_6_io_CP; // @[AdderGen.scala 16:19]
wire FullAdder_7_io_A; // @[AdderGen.scala 16:19]
wire FullAdder_7_io_B; // @[AdderGen.scala 16:19]
wire FullAdder_7_io_C; // @[AdderGen.scala 16:19]
wire FullAdder_7_io_S; // @[AdderGen.scala 16:19]
wire FullAdder_7_io_CG; // @[AdderGen.scala 16:19]
wire FullAdder_7_io_CP; // @[AdderGen.scala 16:19]
wire CPG_3_io_CI; // @[CPG.scala 32:19]
wire CPG_3_io_CG_0; // @[CPG.scala 32:19]
wire CPG_3_io_CG_1; // @[CPG.scala 32:19]
wire CPG_3_io_CG_2; // @[CPG.scala 32:19]
wire CPG_3_io_CG_3; // @[CPG.scala 32:19]
wire CPG_3_io_CP_0; // @[CPG.scala 32:19]
wire CPG_3_io_CP_1; // @[CPG.scala 32:19]
wire CPG_3_io_CP_2; // @[CPG.scala 32:19]
wire CPG_3_io_CP_3; // @[CPG.scala 32:19]
wire CPG_3_io_CO_0; // @[CPG.scala 32:19]
wire CPG_3_io_CO_1; // @[CPG.scala 32:19]
wire CPG_3_io_CO_2; // @[CPG.scala 32:19]
wire CPG_3_io_CP4; // @[CPG.scala 32:19]
wire CPG_3_io_CG4; // @[CPG.scala 32:19]
wire FullAdder_8_io_A; // @[AdderGen.scala 16:19]
wire FullAdder_8_io_B; // @[AdderGen.scala 16:19]
wire FullAdder_8_io_C; // @[AdderGen.scala 16:19]
wire FullAdder_8_io_S; // @[AdderGen.scala 16:19]
wire FullAdder_8_io_CG; // @[AdderGen.scala 16:19]
wire FullAdder_8_io_CP; // @[AdderGen.scala 16:19]
wire FullAdder_9_io_A; // @[AdderGen.scala 16:19]
wire FullAdder_9_io_B; // @[AdderGen.scala 16:19]
wire FullAdder_9_io_C; // @[AdderGen.scala 16:19]
wire FullAdder_9_io_S; // @[AdderGen.scala 16:19]
wire FullAdder_9_io_CG; // @[AdderGen.scala 16:19]
wire FullAdder_9_io_CP; // @[AdderGen.scala 16:19]
wire FullAdder_10_io_A; // @[AdderGen.scala 16:19]
wire FullAdder_10_io_B; // @[AdderGen.scala 16:19]
wire FullAdder_10_io_C; // @[AdderGen.scala 16:19]
wire FullAdder_10_io_S; // @[AdderGen.scala 16:19]
wire FullAdder_10_io_CG; // @[AdderGen.scala 16:19]
wire FullAdder_10_io_CP; // @[AdderGen.scala 16:19]
wire FullAdder_11_io_A; // @[AdderGen.scala 16:19]
wire FullAdder_11_io_B; // @[AdderGen.scala 16:19]
wire FullAdder_11_io_C; // @[AdderGen.scala 16:19]
wire FullAdder_11_io_S; // @[AdderGen.scala 16:19]
wire FullAdder_11_io_CG; // @[AdderGen.scala 16:19]
wire FullAdder_11_io_CP; // @[AdderGen.scala 16:19]
wire CPG_4_io_CI; // @[CPG.scala 32:19]
wire CPG_4_io_CG_0; // @[CPG.scala 32:19]
wire CPG_4_io_CG_1; // @[CPG.scala 32:19]
wire CPG_4_io_CG_2; // @[CPG.scala 32:19]
wire CPG_4_io_CG_3; // @[CPG.scala 32:19]
wire CPG_4_io_CP_0; // @[CPG.scala 32:19]
wire CPG_4_io_CP_1; // @[CPG.scala 32:19]
wire CPG_4_io_CP_2; // @[CPG.scala 32:19]
wire CPG_4_io_CP_3; // @[CPG.scala 32:19]
wire CPG_4_io_CO_0; // @[CPG.scala 32:19]
wire CPG_4_io_CO_1; // @[CPG.scala 32:19]
wire CPG_4_io_CO_2; // @[CPG.scala 32:19]
wire CPG_4_io_CP4; // @[CPG.scala 32:19]
wire CPG_4_io_CG4; // @[CPG.scala 32:19]
wire FullAdder_12_io_A; // @[AdderGen.scala 16:19]
wire FullAdder_12_io_B; // @[AdderGen.scala 16:19]
wire FullAdder_12_io_C; // @[AdderGen.scala 16:19]
wire FullAdder_12_io_S; // @[AdderGen.scala 16:19]
wire FullAdder_12_io_CG; // @[AdderGen.scala 16:19]
wire FullAdder_12_io_CP; // @[AdderGen.scala 16:19]
wire FullAdder_13_io_A; // @[AdderGen.scala 16:19]
wire FullAdder_13_io_B; // @[AdderGen.scala 16:19]
wire FullAdder_13_io_C; // @[AdderGen.scala 16:19]
wire FullAdder_13_io_S; // @[AdderGen.scala 16:19]
wire FullAdder_13_io_CG; // @[AdderGen.scala 16:19]
wire FullAdder_13_io_CP; // @[AdderGen.scala 16:19]
wire FullAdder_14_io_A; // @[AdderGen.scala 16:19]
wire FullAdder_14_io_B; // @[AdderGen.scala 16:19]
wire FullAdder_14_io_C; // @[AdderGen.scala 16:19]
wire FullAdder_14_io_S; // @[AdderGen.scala 16:19]
wire FullAdder_14_io_CG; // @[AdderGen.scala 16:19]
wire FullAdder_14_io_CP; // @[AdderGen.scala 16:19]
wire FullAdder_15_io_A; // @[AdderGen.scala 16:19]
wire FullAdder_15_io_B; // @[AdderGen.scala 16:19]
wire FullAdder_15_io_C; // @[AdderGen.scala 16:19]
wire FullAdder_15_io_S; // @[AdderGen.scala 16:19]
wire FullAdder_15_io_CG; // @[AdderGen.scala 16:19]
wire FullAdder_15_io_CP; // @[AdderGen.scala 16:19]
wire S_Vec_1_1 = FullAdder_1_io_S; // @[AdderGen.scala 28:21 36:18]
wire S_Vec_1_0 = FullAdder_io_S; // @[AdderGen.scala 28:21 36:18]
wire S_Vec_1_3 = FullAdder_3_io_S; // @[AdderGen.scala 28:21 36:18]
wire S_Vec_1_2 = FullAdder_2_io_S; // @[AdderGen.scala 28:21 36:18]
wire S_Vec_2_1 = FullAdder_5_io_S; // @[AdderGen.scala 28:21 36:18]
wire S_Vec_2_0 = FullAdder_4_io_S; // @[AdderGen.scala 28:21 36:18]
wire S_Vec_2_3 = FullAdder_7_io_S; // @[AdderGen.scala 28:21 36:18]
wire S_Vec_2_2 = FullAdder_6_io_S; // @[AdderGen.scala 28:21 36:18]
wire S_Vec_3_1 = FullAdder_9_io_S; // @[AdderGen.scala 28:21 36:18]
wire S_Vec_3_0 = FullAdder_8_io_S; // @[AdderGen.scala 28:21 36:18]
wire S_Vec_3_3 = FullAdder_11_io_S; // @[AdderGen.scala 28:21 36:18]
wire S_Vec_3_2 = FullAdder_10_io_S; // @[AdderGen.scala 28:21 36:18]
wire S_Vec_4_1 = FullAdder_13_io_S; // @[AdderGen.scala 28:21 36:18]
wire S_Vec_4_0 = FullAdder_12_io_S; // @[AdderGen.scala 28:21 36:18]
wire S_Vec_4_3 = FullAdder_15_io_S; // @[AdderGen.scala 28:21 36:18]
wire S_Vec_4_2 = FullAdder_14_io_S; // @[AdderGen.scala 28:21 36:18]
wire [7:0] S_lo_4 = {S_Vec_2_3,S_Vec_2_2,S_Vec_2_1,S_Vec_2_0,S_Vec_1_3,S_Vec_1_2,S_Vec_1_1,S_Vec_1_0}; // @[AdderGen.scala 41:19]
wire [7:0] S_hi_4 = {S_Vec_4_3,S_Vec_4_2,S_Vec_4_1,S_Vec_4_0,S_Vec_3_3,S_Vec_3_2,S_Vec_3_1,S_Vec_3_0}; // @[AdderGen.scala 41:19]
CPG CPG ( // @[CPG.scala 32:19]
.io_CI(CPG_io_CI),
.io_CG_0(CPG_io_CG_0),
.io_CG_1(CPG_io_CG_1),
.io_CG_2(CPG_io_CG_2),
.io_CG_3(CPG_io_CG_3),
.io_CP_0(CPG_io_CP_0),
.io_CP_1(CPG_io_CP_1),
.io_CP_2(CPG_io_CP_2),
.io_CP_3(CPG_io_CP_3),
.io_CO_0(CPG_io_CO_0),
.io_CO_1(CPG_io_CO_1),
.io_CO_2(CPG_io_CO_2),
.io_CP4(CPG_io_CP4),
.io_CG4(CPG_io_CG4)
);
CPG CPG_1 ( // @[CPG.scala 32:19]
.io_CI(CPG_1_io_CI),
.io_CG_0(CPG_1_io_CG_0),
.io_CG_1(CPG_1_io_CG_1),
.io_CG_2(CPG_1_io_CG_2),
.io_CG_3(CPG_1_io_CG_3),
.io_CP_0(CPG_1_io_CP_0),
.io_CP_1(CPG_1_io_CP_1),
.io_CP_2(CPG_1_io_CP_2),
.io_CP_3(CPG_1_io_CP_3),
.io_CO_0(CPG_1_io_CO_0),
.io_CO_1(CPG_1_io_CO_1),
.io_CO_2(CPG_1_io_CO_2),
.io_CP4(CPG_1_io_CP4),
.io_CG4(CPG_1_io_CG4)
);
FullAdder FullAdder ( // @[AdderGen.scala 16:19]
.io_A(FullAdder_io_A),
.io_B(FullAdder_io_B),
.io_C(FullAdder_io_C),
.io_S(FullAdder_io_S),
.io_CG(FullAdder_io_CG),
.io_CP(FullAdder_io_CP)
);
FullAdder FullAdder_1 ( // @[AdderGen.scala 16:19]
.io_A(FullAdder_1_io_A),
.io_B(FullAdder_1_io_B),
.io_C(FullAdder_1_io_C),
.io_S(FullAdder_1_io_S),
.io_CG(FullAdder_1_io_CG),
.io_CP(FullAdder_1_io_CP)
);
FullAdder FullAdder_2 ( // @[AdderGen.scala 16:19]
.io_A(FullAdder_2_io_A),
.io_B(FullAdder_2_io_B),
.io_C(FullAdder_2_io_C),
.io_S(FullAdder_2_io_S),
.io_CG(FullAdder_2_io_CG),
.io_CP(FullAdder_2_io_CP)
);
FullAdder FullAdder_3 ( // @[AdderGen.scala 16:19]
.io_A(FullAdder_3_io_A),
.io_B(FullAdder_3_io_B),
.io_C(FullAdder_3_io_C),
.io_S(FullAdder_3_io_S),
.io_CG(FullAdder_3_io_CG),
.io_CP(FullAdder_3_io_CP)
);
CPG CPG_2 ( // @[CPG.scala 32:19]
.io_CI(CPG_2_io_CI),
.io_CG_0(CPG_2_io_CG_0),
.io_CG_1(CPG_2_io_CG_1),
.io_CG_2(CPG_2_io_CG_2),
.io_CG_3(CPG_2_io_CG_3),
.io_CP_0(CPG_2_io_CP_0),
.io_CP_1(CPG_2_io_CP_1),
.io_CP_2(CPG_2_io_CP_2),
.io_CP_3(CPG_2_io_CP_3),
.io_CO_0(CPG_2_io_CO_0),
.io_CO_1(CPG_2_io_CO_1),
.io_CO_2(CPG_2_io_CO_2),
.io_CP4(CPG_2_io_CP4),
.io_CG4(CPG_2_io_CG4)
);
FullAdder FullAdder_4 ( // @[AdderGen.scala 16:19]
.io_A(FullAdder_4_io_A),
.io_B(FullAdder_4_io_B),
.io_C(FullAdder_4_io_C),
.io_S(FullAdder_4_io_S),
.io_CG(FullAdder_4_io_CG),
.io_CP(FullAdder_4_io_CP)
);
FullAdder FullAdder_5 ( // @[AdderGen.scala 16:19]
.io_A(FullAdder_5_io_A),
.io_B(FullAdder_5_io_B),
.io_C(FullAdder_5_io_C),
.io_S(FullAdder_5_io_S),
.io_CG(FullAdder_5_io_CG),
.io_CP(FullAdder_5_io_CP)
);
FullAdder FullAdder_6 ( // @[AdderGen.scala 16:19]
.io_A(FullAdder_6_io_A),
.io_B(FullAdder_6_io_B),
.io_C(FullAdder_6_io_C),
.io_S(FullAdder_6_io_S),
.io_CG(FullAdder_6_io_CG),
.io_CP(FullAdder_6_io_CP)
);
FullAdder FullAdder_7 ( // @[AdderGen.scala 16:19]
.io_A(FullAdder_7_io_A),
.io_B(FullAdder_7_io_B),
.io_C(FullAdder_7_io_C),
.io_S(FullAdder_7_io_S),
.io_CG(FullAdder_7_io_CG),
.io_CP(FullAdder_7_io_CP)
);
CPG CPG_3 ( // @[CPG.scala 32:19]
.io_CI(CPG_3_io_CI),
.io_CG_0(CPG_3_io_CG_0),
.io_CG_1(CPG_3_io_CG_1),
.io_CG_2(CPG_3_io_CG_2),
.io_CG_3(CPG_3_io_CG_3),
.io_CP_0(CPG_3_io_CP_0),
.io_CP_1(CPG_3_io_CP_1),
.io_CP_2(CPG_3_io_CP_2),
.io_CP_3(CPG_3_io_CP_3),
.io_CO_0(CPG_3_io_CO_0),
.io_CO_1(CPG_3_io_CO_1),
.io_CO_2(CPG_3_io_CO_2),
.io_CP4(CPG_3_io_CP4),
.io_CG4(CPG_3_io_CG4)
);
FullAdder FullAdder_8 ( // @[AdderGen.scala 16:19]
.io_A(FullAdder_8_io_A),
.io_B(FullAdder_8_io_B),
.io_C(FullAdder_8_io_C),
.io_S(FullAdder_8_io_S),
.io_CG(FullAdder_8_io_CG),
.io_CP(FullAdder_8_io_CP)
);
FullAdder FullAdder_9 ( // @[AdderGen.scala 16:19]
.io_A(FullAdder_9_io_A),
.io_B(FullAdder_9_io_B),
.io_C(FullAdder_9_io_C),
.io_S(FullAdder_9_io_S),
.io_CG(FullAdder_9_io_CG),
.io_CP(FullAdder_9_io_CP)
);
FullAdder FullAdder_10 ( // @[AdderGen.scala 16:19]
.io_A(FullAdder_10_io_A),
.io_B(FullAdder_10_io_B),
.io_C(FullAdder_10_io_C),
.io_S(FullAdder_10_io_S),
.io_CG(FullAdder_10_io_CG),
.io_CP(FullAdder_10_io_CP)
);
FullAdder FullAdder_11 ( // @[AdderGen.scala 16:19]
.io_A(FullAdder_11_io_A),
.io_B(FullAdder_11_io_B),
.io_C(FullAdder_11_io_C),
.io_S(FullAdder_11_io_S),
.io_CG(FullAdder_11_io_CG),
.io_CP(FullAdder_11_io_CP)
);
CPG CPG_4 ( // @[CPG.scala 32:19]
.io_CI(CPG_4_io_CI),
.io_CG_0(CPG_4_io_CG_0),
.io_CG_1(CPG_4_io_CG_1),
.io_CG_2(CPG_4_io_CG_2),
.io_CG_3(CPG_4_io_CG_3),
.io_CP_0(CPG_4_io_CP_0),
.io_CP_1(CPG_4_io_CP_1),
.io_CP_2(CPG_4_io_CP_2),
.io_CP_3(CPG_4_io_CP_3),
.io_CO_0(CPG_4_io_CO_0),
.io_CO_1(CPG_4_io_CO_1),
.io_CO_2(CPG_4_io_CO_2),
.io_CP4(CPG_4_io_CP4),
.io_CG4(CPG_4_io_CG4)
);
FullAdder FullAdder_12 ( // @[AdderGen.scala 16:19]
.io_A(FullAdder_12_io_A),
.io_B(FullAdder_12_io_B),
.io_C(FullAdder_12_io_C),
.io_S(FullAdder_12_io_S),
.io_CG(FullAdder_12_io_CG),
.io_CP(FullAdder_12_io_CP)
);
FullAdder FullAdder_13 ( // @[AdderGen.scala 16:19]
.io_A(FullAdder_13_io_A),
.io_B(FullAdder_13_io_B),
.io_C(FullAdder_13_io_C),
.io_S(FullAdder_13_io_S),
.io_CG(FullAdder_13_io_CG),
.io_CP(FullAdder_13_io_CP)
);
FullAdder FullAdder_14 ( // @[AdderGen.scala 16:19]
.io_A(FullAdder_14_io_A),
.io_B(FullAdder_14_io_B),
.io_C(FullAdder_14_io_C),
.io_S(FullAdder_14_io_S),
.io_CG(FullAdder_14_io_CG),
.io_CP(FullAdder_14_io_CP)
);
FullAdder FullAdder_15 ( // @[AdderGen.scala 16:19]
.io_A(FullAdder_15_io_A),
.io_B(FullAdder_15_io_B),
.io_C(FullAdder_15_io_C),
.io_S(FullAdder_15_io_S),
.io_CG(FullAdder_15_io_CG),
.io_CP(FullAdder_15_io_CP)
);
assign io_S = {S_hi_4,S_lo_4}; // @[AdderGen.scala 41:19]
assign io_CO = CPG_io_CG4 | CPG_io_CP4 & io_CI; // @[AdderGen.scala 61:17]
assign CPG_io_CI = io_CI; // @[CPG.scala 33:10]
assign CPG_io_CG_0 = CPG_1_io_CG4; // @[AdderGen.scala 29:21 37:15]
assign CPG_io_CG_1 = CPG_2_io_CG4; // @[AdderGen.scala 29:21 37:15]
assign CPG_io_CG_2 = CPG_3_io_CG4; // @[AdderGen.scala 29:21 37:15]
assign CPG_io_CG_3 = CPG_4_io_CG4; // @[AdderGen.scala 29:21 37:15]
assign CPG_io_CP_0 = CPG_1_io_CP4; // @[AdderGen.scala 30:21 38:15]
assign CPG_io_CP_1 = CPG_2_io_CP4; // @[AdderGen.scala 30:21 38:15]
assign CPG_io_CP_2 = CPG_3_io_CP4; // @[AdderGen.scala 30:21 38:15]
assign CPG_io_CP_3 = CPG_4_io_CP4; // @[AdderGen.scala 30:21 38:15]
assign CPG_1_io_CI = io_CI; // @[CPG.scala 33:10]
assign CPG_1_io_CG_0 = FullAdder_io_CG; // @[AdderGen.scala 29:21 37:15]
assign CPG_1_io_CG_1 = FullAdder_1_io_CG; // @[AdderGen.scala 29:21 37:15]
assign CPG_1_io_CG_2 = FullAdder_2_io_CG; // @[AdderGen.scala 29:21 37:15]
assign CPG_1_io_CG_3 = FullAdder_3_io_CG; // @[AdderGen.scala 29:21 37:15]
assign CPG_1_io_CP_0 = FullAdder_io_CP; // @[AdderGen.scala 30:21 38:15]
assign CPG_1_io_CP_1 = FullAdder_1_io_CP; // @[AdderGen.scala 30:21 38:15]
assign CPG_1_io_CP_2 = FullAdder_2_io_CP; // @[AdderGen.scala 30:21 38:15]
assign CPG_1_io_CP_3 = FullAdder_3_io_CP; // @[AdderGen.scala 30:21 38:15]
assign FullAdder_io_A = io_A[0]; // @[AdderGen.scala 35:34]
assign FullAdder_io_B = io_B[0]; // @[AdderGen.scala 35:50]
assign FullAdder_io_C = io_CI; // @[AdderGen.scala 19:9]
assign FullAdder_1_io_A = io_A[1]; // @[AdderGen.scala 35:34]
assign FullAdder_1_io_B = io_B[1]; // @[AdderGen.scala 35:50]
assign FullAdder_1_io_C = CPG_1_io_CO_0; // @[AdderGen.scala 19:9]
assign FullAdder_2_io_A = io_A[2]; // @[AdderGen.scala 35:34]
assign FullAdder_2_io_B = io_B[2]; // @[AdderGen.scala 35:50]
assign FullAdder_2_io_C = CPG_1_io_CO_1; // @[AdderGen.scala 19:9]
assign FullAdder_3_io_A = io_A[3]; // @[AdderGen.scala 35:34]
assign FullAdder_3_io_B = io_B[3]; // @[AdderGen.scala 35:50]
assign FullAdder_3_io_C = CPG_1_io_CO_2; // @[AdderGen.scala 19:9]
assign CPG_2_io_CI = CPG_io_CO_0; // @[CPG.scala 33:10]
assign CPG_2_io_CG_0 = FullAdder_4_io_CG; // @[AdderGen.scala 29:21 37:15]
assign CPG_2_io_CG_1 = FullAdder_5_io_CG; // @[AdderGen.scala 29:21 37:15]
assign CPG_2_io_CG_2 = FullAdder_6_io_CG; // @[AdderGen.scala 29:21 37:15]
assign CPG_2_io_CG_3 = FullAdder_7_io_CG; // @[AdderGen.scala 29:21 37:15]
assign CPG_2_io_CP_0 = FullAdder_4_io_CP; // @[AdderGen.scala 30:21 38:15]
assign CPG_2_io_CP_1 = FullAdder_5_io_CP; // @[AdderGen.scala 30:21 38:15]
assign CPG_2_io_CP_2 = FullAdder_6_io_CP; // @[AdderGen.scala 30:21 38:15]
assign CPG_2_io_CP_3 = FullAdder_7_io_CP; // @[AdderGen.scala 30:21 38:15]
assign FullAdder_4_io_A = io_A[4]; // @[AdderGen.scala 35:34]
assign FullAdder_4_io_B = io_B[4]; // @[AdderGen.scala 35:50]
assign FullAdder_4_io_C = CPG_io_CO_0; // @[AdderGen.scala 19:9]
assign FullAdder_5_io_A = io_A[5]; // @[AdderGen.scala 35:34]
assign FullAdder_5_io_B = io_B[5]; // @[AdderGen.scala 35:50]
assign FullAdder_5_io_C = CPG_2_io_CO_0; // @[AdderGen.scala 19:9]
assign FullAdder_6_io_A = io_A[6]; // @[AdderGen.scala 35:34]
assign FullAdder_6_io_B = io_B[6]; // @[AdderGen.scala 35:50]
assign FullAdder_6_io_C = CPG_2_io_CO_1; // @[AdderGen.scala 19:9]
assign FullAdder_7_io_A = io_A[7]; // @[AdderGen.scala 35:34]
assign FullAdder_7_io_B = io_B[7]; // @[AdderGen.scala 35:50]
assign FullAdder_7_io_C = CPG_2_io_CO_2; // @[AdderGen.scala 19:9]
assign CPG_3_io_CI = CPG_io_CO_1; // @[CPG.scala 33:10]
assign CPG_3_io_CG_0 = FullAdder_8_io_CG; // @[AdderGen.scala 29:21 37:15]
assign CPG_3_io_CG_1 = FullAdder_9_io_CG; // @[AdderGen.scala 29:21 37:15]
assign CPG_3_io_CG_2 = FullAdder_10_io_CG; // @[AdderGen.scala 29:21 37:15]
assign CPG_3_io_CG_3 = FullAdder_11_io_CG; // @[AdderGen.scala 29:21 37:15]
assign CPG_3_io_CP_0 = FullAdder_8_io_CP; // @[AdderGen.scala 30:21 38:15]
assign CPG_3_io_CP_1 = FullAdder_9_io_CP; // @[AdderGen.scala 30:21 38:15]
assign CPG_3_io_CP_2 = FullAdder_10_io_CP; // @[AdderGen.scala 30:21 38:15]
assign CPG_3_io_CP_3 = FullAdder_11_io_CP; // @[AdderGen.scala 30:21 38:15]
assign FullAdder_8_io_A = io_A[8]; // @[AdderGen.scala 35:34]
assign FullAdder_8_io_B = io_B[8]; // @[AdderGen.scala 35:50]
assign FullAdder_8_io_C = CPG_io_CO_1; // @[AdderGen.scala 19:9]
assign FullAdder_9_io_A = io_A[9]; // @[AdderGen.scala 35:34]
assign FullAdder_9_io_B = io_B[9]; // @[AdderGen.scala 35:50]
assign FullAdder_9_io_C = CPG_3_io_CO_0; // @[AdderGen.scala 19:9]
assign FullAdder_10_io_A = io_A[10]; // @[AdderGen.scala 35:34]
assign FullAdder_10_io_B = io_B[10]; // @[AdderGen.scala 35:50]
assign FullAdder_10_io_C = CPG_3_io_CO_1; // @[AdderGen.scala 19:9]
assign FullAdder_11_io_A = io_A[11]; // @[AdderGen.scala 35:34]
assign FullAdder_11_io_B = io_B[11]; // @[AdderGen.scala 35:50]
assign FullAdder_11_io_C = CPG_3_io_CO_2; // @[AdderGen.scala 19:9]
assign CPG_4_io_CI = CPG_io_CO_2; // @[CPG.scala 33:10]
assign CPG_4_io_CG_0 = FullAdder_12_io_CG; // @[AdderGen.scala 29:21 37:15]
assign CPG_4_io_CG_1 = FullAdder_13_io_CG; // @[AdderGen.scala 29:21 37:15]
assign CPG_4_io_CG_2 = FullAdder_14_io_CG; // @[AdderGen.scala 29:21 37:15]
assign CPG_4_io_CG_3 = FullAdder_15_io_CG; // @[AdderGen.scala 29:21 37:15]
assign CPG_4_io_CP_0 = FullAdder_12_io_CP; // @[AdderGen.scala 30:21 38:15]
assign CPG_4_io_CP_1 = FullAdder_13_io_CP; // @[AdderGen.scala 30:21 38:15]
assign CPG_4_io_CP_2 = FullAdder_14_io_CP; // @[AdderGen.scala 30:21 38:15]
assign CPG_4_io_CP_3 = FullAdder_15_io_CP; // @[AdderGen.scala 30:21 38:15]
assign FullAdder_12_io_A = io_A[12]; // @[AdderGen.scala 35:34]
assign FullAdder_12_io_B = io_B[12]; // @[AdderGen.scala 35:50]
assign FullAdder_12_io_C = CPG_io_CO_2; // @[AdderGen.scala 19:9]
assign FullAdder_13_io_A = io_A[13]; // @[AdderGen.scala 35:34]
assign FullAdder_13_io_B = io_B[13]; // @[AdderGen.scala 35:50]
assign FullAdder_13_io_C = CPG_4_io_CO_0; // @[AdderGen.scala 19:9]
assign FullAdder_14_io_A = io_A[14]; // @[AdderGen.scala 35:34]
assign FullAdder_14_io_B = io_B[14]; // @[AdderGen.scala 35:50]
assign FullAdder_14_io_C = CPG_4_io_CO_1; // @[AdderGen.scala 19:9]
assign FullAdder_15_io_A = io_A[15]; // @[AdderGen.scala 35:34]
assign FullAdder_15_io_B = io_B[15]; // @[AdderGen.scala 35:50]
assign FullAdder_15_io_C = CPG_4_io_CO_2; // @[AdderGen.scala 19:9]
endmodule
可以看到,由Chisel转译的Verilog代码里,不存在“数组”形式的信号。要实现一个16位的信号,就定义16个1位信号来组成。比较笨拙。同时,在16位CLA生成的Verilog代码中,并没有将4位CLA编写为一个模块。这是因为我们在之前的代码编写中,是吧AdderX作为一个function而非Module来编写。Chisel并没有将其优化成一个Module,这情有可原。
而64位CLA的Verilog代码足足有2035行,可读性非常差。
我们将生成的Verilog代码导入Vivado,看一下RTL电路图,以16位CLA为例:
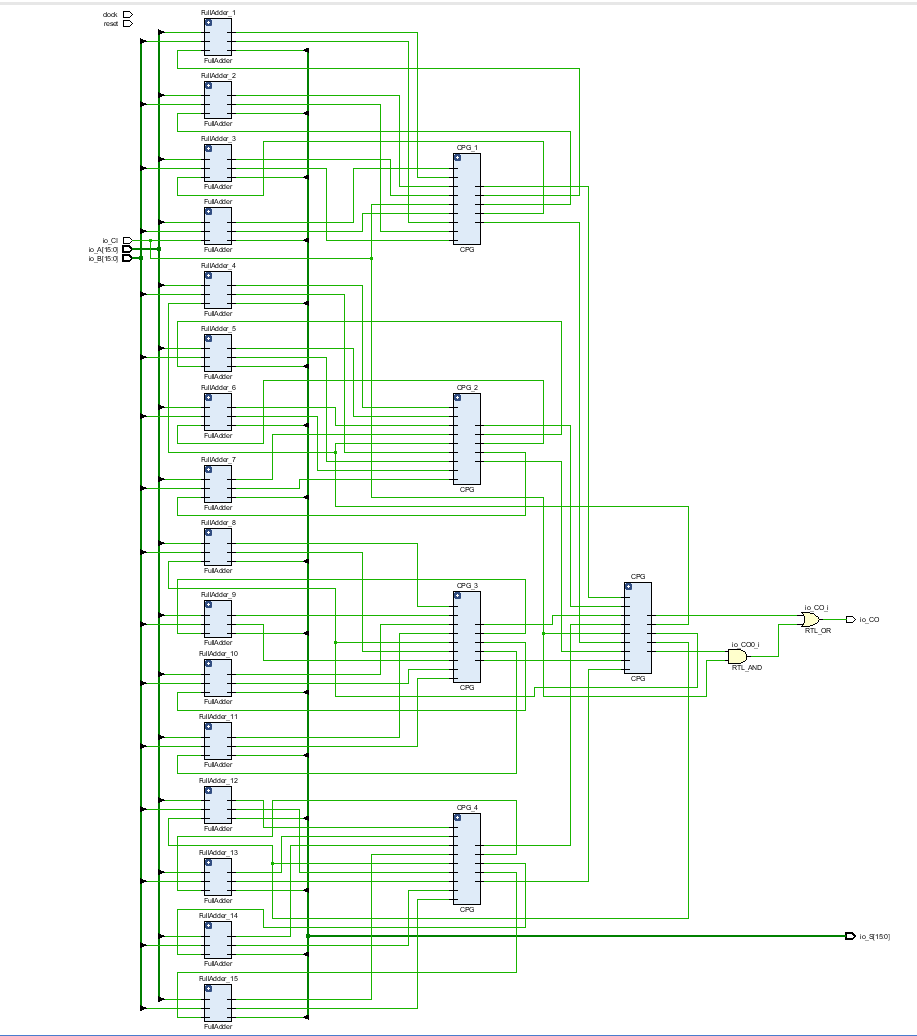
虽然没有将4位CLA封装起来,但层级结构还是很清晰的,一个16位CLA由4个4位CLA和1个CPG组成,而每个4位CLA又由一个1位全加器和1个CPG组成。
四,Chisel 评价
4.1 优点
-
高级而高效
依托Scala的各种高级语法,简化了电路设计流程,可以非常方便地设计硬件生成器。比如本项目中,我们用一个AdderX函数就准确描述了4位、16位和64位CLA的电路。放到Verilog里,我们必须非常机械地写三个模块。
-
代码可读性高,易于修改和维护。
4.2 缺点
-
设计人员的独角戏
Chisel现在主要是IC设计人员在使用,后端还是使用Verilog居多。尽管Chisel能够通过编译器翻译成Verilog,但这种自动翻译出来的代码可读性很差,很难让后端验证的人员阅读。所以在整个产业链上,Chisel暂时难以施展。
-
臃肿且别扭
在设计这么一个简单加法器的过程中,我确实体会到了Chisel的优越性,但也被其臃肿的语法和别扭的规则所折磨。要设计一个简单的模块,我首先得导入一堆库。设计完之后想要像Verilog那样直接使用模块名来调用模块,还得再定义一个apply方法。Verilog里,一个信号wire a[31:0]可以拆成多段分别赋值;而在Chisel里一个UInt(32.W)的信号做不到,要想拆开来赋值,必须定义成Vec(n,UInt(x.W))。
一言以蔽之,Chisel可能在生态上享受到了Scala30%的便利,但却在规则上受到了Scala100%的束缚。
4.3 一个可能的优化方向
在Verilog里,假如我设计了一个模块AdderX,那么后续要例化该模块时,直接调用其模块名即可。如Adder(…)。但在Chisel里,我们就必须写 Module(new Adder),然后再一根一根地把线连上。
假如我们想要像Verilog那样简单地例化模块,就必须在Object对象里再定义一个apply方法,或者在要例化该模块的时候再写一个函数,如本项目FullAdder中的:
def FullAdder(A: UInt, B: UInt, C: UInt = 0.U): (UInt, UInt, UInt) = {
val m = Module(new FullAdder).io
m.A := A
m.B := B
m.C := C
(m.S, m.CG, m.CP)
}
这个过程显然就比较繁琐。假如能像C++那样,在程序员定义完一个类后,如果没有编写构造函数,编译器就自动生成一个,Chisel也在我们写完一个模块后自动生成一个仿Verilog的apply方法,那我们的代码就可以更加简洁。
五,参考资料
- 《数字逻辑基础(第2版》,复旦大学 陈光梦
六,特别鸣谢
- 韩军老师,《嵌入式处理器与芯片系统设计(H)》的几位助教学长
- chatGPT














 2152
2152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









