







 本文深入探讨聚类算法,涵盖K-Means、基于链接、DBSCAN等多种算法原理,分析聚类过程中的难点与挑战,讲解尺度不变性、丰富性等聚类公理,以及数据挖掘对聚类算法的泛化要求。
本文深入探讨聚类算法,涵盖K-Means、基于链接、DBSCAN等多种算法原理,分析聚类过程中的难点与挑战,讲解尺度不变性、丰富性等聚类公理,以及数据挖掘对聚类算法的泛化要求。
见聚类算法总结分析-原理,代码,对比分析
一、聚类的描述、目的
直观上讲,聚类是将对象进行分组的一项任务,使相似的对象归为一类,不相似的对象归为不同类。即使同一类对象的相似度尽可能地大,不同类对象之间的相似度尽可能地小。
聚类过程中存在的几个很困难的问题
1. 上述提及的两个目标在很多情况下是互相冲突的。从数学上讲,虽然聚类共享具有等价关系甚至传递关系,但是相似性(或距离)不具有传递关系。具体而言,假定有一对象序列,X1,…,Xm,所有相邻元素(Xi-1、Xi+1)两两都非常相似,但是X1和Xm非常不相似。这种情况常常发生在cluster超过一定尺寸的时候,元素之间的传递性假设在这些场景下不一定100%符合真实规律。
2. 另一个基本问题是聚类缺乏实际情况,这是无监督学习的共同问题。聚类是一种无监督学习,即我们不能预测label,因此对于聚类,我们没有明确的成功评估过程。
另一方面,对于一个给定的对象集合,可以有多种有意义的划分方式,这可能是因为对象间的距离(或相似性)有多种隐式的定义,例如将演讲者的录音根据演讲者的口音聚类或根据内容聚类。所以,给定一个数据集,有多种不同的聚类解决方案
聚类的公理化描述
对于各种各样的聚类算法,有没有一些基本性质是独立于具体算法或任务的呢?很多人尝试对聚类提出一个公理化的定义,让我们讨论Kleninberg(2003)提出的尝试方法:
考虑一个聚类函数F,将任意有限域X及不相似函数d作为输入,返回X的一个划分,考虑这类函数的三种特性:
1. 尺度不变性(SI)
对任意的域集 X,不相似函数 d,以及任意的 a > 0,下式成立:
尺度不变性是一种非常自然的要求,因为如果聚类函数输出的结果依赖于测量点之间的距离测度单元,那将显得十分奇怪和不合理。
2. 丰富性(Ri)
对任意的有限集 X 和划分 C = (C1,C2,…,Ck)(划分到非空子集),存在多种不相似函数 d 使得 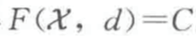 。
。
丰富性要求主要想说明聚类函数的输出是由函数 d 全权决定,也是一种十分直观的特征。
3. 一致性(Co)
如果 d 和 d’ 都是 X 上的不相似函数,对任一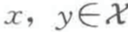 根据 F(X,d):
根据 F(X,d):
如果 x,y 属于同一类,则
如果 x,y 属于不同类,则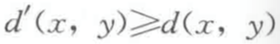
那么 。
。
一致性要求是和聚类基本定义相关的要求,我们希望相似的点聚到一类,不相似的点分属不同类,因此共享同类的点更相似,已经分离的点不相似,聚类函数应当对之前的聚类决策有很强的“支撑”作用。
值得注意的是,Kleinberg在2003已经给出了下述“不可能”结论!
不存在一个函数F同时满足上述三种属性:尺度不变性,丰富性,一致性。
例如,如果讨论含固定数量参数的聚类函数,很自然地将丰富性改为 k-丰富性(即,将域划分到k个子集,这个限制比丰富性RI原则更松散一些)。k-均值聚类满足k-丰富性、尺度不变性和一致性,因此能够达到一致。或者可以放松一致性属性
这反过来告诉我们。给定一项任务,聚类函数的选取必须考虑该任务的特定属性(是否可以放松要求,又是否有一些地方是需要强要求)。没有统一的聚类解决方案,就像没有一种分类算法能够对每一项可学习任务都能学习(no free lunch定理)。和其他分类预测一样,聚类必须考虑特定任务的先验知识。
二、数据挖掘对聚类的典型泛化要求
不同的算法有着不同的应用背景,有的适合大数据集,可以发现任意形状的聚类;有的算法思想简单直观,适用于小数据集。总的来说,算法都试图从不同途径实现对数据集进行高效、可靠的聚类。数据挖掘对聚类的典型要求包括:
1. 可伸缩性:
当聚类对象由几百上升到几百万,我们希望最后的聚类结果的准确度能保持一致。
2. 处理不同类型属性的能力:
有些聚类算法,其处理对象的属性的数据类型只能是数值类型,但是在实际应用场景中,我们往往会遇到其他类型的数据(例如二元数据),分类数据等等,虽然我们也可以在预处理数据时将这些其他类型的数据转换成数值型数据,但是在聚类效率上或者聚类准确度上往往会有折损。
3. 发现任意形状的类簇:
因为许多聚类算法是基于距离(例如欧式距离或曼哈顿距离)来量化实例对象之间的相似度的,基于这种方式,我们往往只能发现相似尺寸和密度的球状类簇或者凸形类簇。但是在很多场景下,类簇的形状可能是任意的。
4. 对聚类算法初始化参数的知识需求的最小化:
很多算法在分析过程中需要开发者提供一定的参数(例如期望的类簇K个数、类簇初始质心),这导致了聚类结果对这些参数是十分敏感的,这不仅加重了开发者的负担,也非常影响聚类结果的准确性。
5. 处理噪声数据的能力:
所谓的噪声数据,可以理解为影响聚类结果的干扰数据,这些噪声数据的存在会造成聚类结果的“畸变”,最终导致低质量的聚类。
6. 增量聚类和对输入次序的不敏感:
一些聚类算法不能将新加入的数据插入到已有的聚类结果,输入次序的敏感是指,对于给定的数据对象集合,以不同的次序提供输入对象时,最终产生的聚类结果的差异会比较大。
7. 高维性:
有些算法只适合处理2维或者3维的数据,而对高维数据的处理能力很弱,因为在高维空间中数据的分布可能十分稀疏,而且高度倾斜。
8. 基于约束的聚类:
在实际应用中可能需要在各种条件下进行聚类,因为同一个聚类算法,在不同的应用场景中所带来的聚类结果也是各异的,因此找到满足“特定约束”的具有良好聚类特性的数据分组是十分有挑战的。这里最困难的问题就在于如何是识别我们要解决的问题中隐含的“特定约束”具体是什么,以及该使用什么算法来最好的“适配”这种约束。
9. 可解释性和可用性:
我么希望得到的聚类结果都能用特定的语义、知识进行解释,和实际的应用场景相联系。
三、聚类算法的分类
按照聚类的尺度,聚类方法大致可被分为以下三种
1. 基于距离的聚类算法: 基于距离的聚类算法是用各式各样的距离来衡量数据对象之间的相似度;
2. 基于密度的聚类方法: 基于密度的聚类算法主要是依据合适的密度函数等;
3. 基于互连性的聚类算法: 基于互连性的聚类算法通常基于图或超图模型,将高度连通的对象聚为一类;
又可以具体细分如下:
1.基于划分
给定一个有N个元组或者纪录的数据集,分裂法将构造K个分组,每一个分组就代表一个聚类,K<N。
特点: 计算量大。很适合发现中小规模的数据库中小规模的数据库中的球状簇。
算法: K-MEANS算法、K-MEDOIDS算法、CLARANS算法
2.基于层次
对给定的数据集进行层次似的分解,直到某种条件满足为止。具体又可分为“自底向上”和“自顶向下”两种方案。
特点: 较小的计算开销。然而这种技术不能更正错误的决定。
算法: BIRCH算法、CURE算法、CHAMELEON算法
3.基于密度
只要一个区域中的点的密度大过某个阈值,就把它加到与之相近的聚类中去。
特点: 能克服基于距离的算法只能发现“类圆形”的聚类的缺点。
算法: DBSCAN算法、OPTICS算法、DENCLUE算法
4.基于网格
将数据空间划分成为有限个单元(cell)的网格结构,所有的处理都是以单个的单元为对象的。
特点: 处理速度很快,通常这是与目标数据库中记录的个数无关的,只与把数据空间分为多少个单元有关。
算法: STING算法、CLIQUE算法、WAVE-CLUSTER算法
四、信息瓶颈 :关于聚类的更一般化的原理讨论
信息瓶颈是由 Tishby,Pereira和 Bialek 提出的聚类技术,其概念来源于信息论。
用一个文本聚类的问题来解释这个概念,假设我们将每个文本表示为一个词袋,即每个文档都是一个向量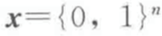 ,其中 n 是字典的长度,
,其中 n 是字典的长度,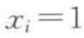 当且仅当第 i 个词在文档中出现。给定一个有 m 个文档的集合,我们可以将 m 个文档的词袋表示理解为随机变量 x 的联合概率分布,指示文档的身份,以及一个随机变量 y,指示单词在词典中的身份。
当且仅当第 i 个词在文档中出现。给定一个有 m 个文档的集合,我们可以将 m 个文档的词袋表示理解为随机变量 x 的联合概率分布,指示文档的身份,以及一个随机变量 y,指示单词在词典中的身份。
根据这种解释,信息瓶颈是指:将聚类属性表示为另一个随机变量C(归纳到具体的类别 k 中)(其中 k 同样由方法确定)。一旦将 x,y,C 表述为随机变量,我们可以使用信息论中的方法来表示聚类目标。
信息瓶颈的目标是: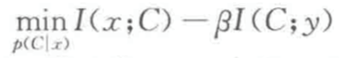
其中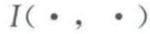 是两个随机变量的互信息,在每个点分属聚类的所有可能概率分布中求取极小值。
是两个随机变量的互信息,在每个点分属聚类的所有可能概率分布中求取极小值。
直观上讲,我们希望达到两个矛盾的目标。
**1)**一方面,我们希望文档属性和聚类属性的互信息尽可能小,这反映了我们希望对原始数据进行强压缩。
**2)**另一方面,我们希望聚类变量和词属性的互信息尽可能大,这反映了保留文档信息(用词在文档中出现来表示)的目标。将参数统计中的最小充分统计量推广到了任意分布。
解信息瓶颈准则下的最优化问题通常是非常困难的,解决方案思路上类似EM准则。
五、典型聚类算法分析
1. K-Means算法(K-means clustering K均值聚类算法) - 基于划分的聚类
1.2 K-means算法模型
一种流行的聚类算法是首先对可能的聚类定义一个代价函数,聚类算法的目标是寻找一种使代价最小的划分。
在这类范例中,聚类任务转化为一个优化问题,目标函数是一个从输入(X,d)和聚类方案 C = (C1,C2,…,Ck)映射到正实数(即损失值)的函数。
给定这样一个目标函数,我们将其表示为 G,对于给定的一个输入(X,d),聚类算法的目标被定义为寻找一种聚类 C 使 G((X,d),C)最小。
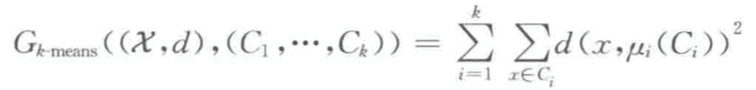
其中,Ci 中心点被定义为:
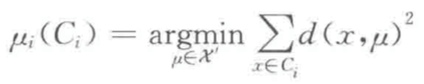
注:argmin 表示使目标函数取最小值时的变量值。
所以上式也可以写成如下形式:
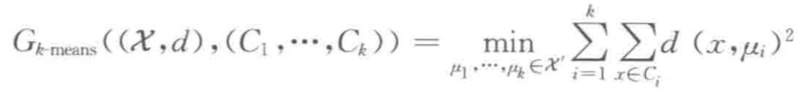
为了达到上述目标,需要运行一些合适的搜索算法。
但是要注意的是,理论和实际的工程化是存在一定的差距的。k均值目标函数在实际的聚类应用中很常见。然而,事实证明寻找k均值(k-means)算法的最优解通常是计算不可行的(NP问题,甚至接近常数近似解的求解是NP问题)。 所以通常会用下面这种简单的迭代算法加粗样式作为替代算法。

因此,多数情况下,k均值聚类值得是这种算法的结果而不是最小化 k 均值目标函数的结果。
需要注意的是,k均值算法的目标函数优化过程是单调非增的(也就是每次的迭代至少不会让结果更糟),但是 k均值算法本身对达到收敛的迭代次数并没有给出理论保证。
此外,算法给出的 k均值目标函数输出值和目标函数的最小可能值之差,并没有下界,实际上,k均值可能会收敛到局部最小值。为了提高 k均值的结果,通常使用不同的随机初始化中心点,将该程序运行多次,并选取最优的结果。
除此之外,有一些无监督的算法可以作为 k均值算法的前置算法,用来选取初始化中心。
1.2 K-means算法过程
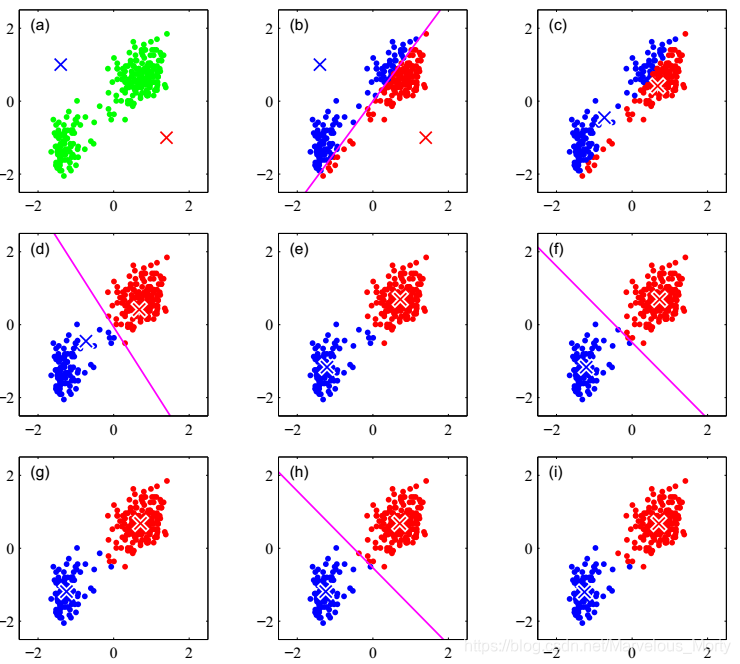
kMeans聚类算法是数据挖掘十大算法之一,算法需要接受参数 k(k 个初始聚类中心)(也可由算法随机产生指定),即将数据集进行聚类的数目和k个簇的初始聚类“中心”,结果是同一类簇中的对象相似度最高,不同类簇中的数据相似度最低,其聚类过程可以用下图表示:
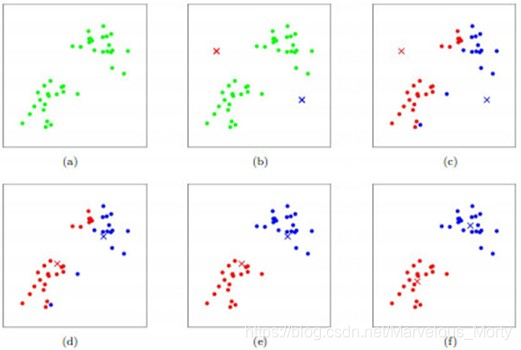
如图所示,数据样本用圆点表示,每个簇的中心点用叉叉表示。
1.2.1 聚类中心个数K
聚类中心的个数K需要事先给定,但在实际中这个 K 值的选定是非常难以估计的,很多时候,事先并不知道给定的数据集应该分成多少个类别才最合适。这个过程会是一个漫长的调试过程,我们通过设置一个[k, k+n]范围的K类值,然后逐个观察聚类结果,最终决定该使用什么K值对当前数据集是最佳的
在实际情况中,往往是对特定的数据集有对应一个最佳的K值,而换一个数据集,可能原来的K值效果就会下降。但是同一个项目中的一类数据,总体上来说,通过一个抽样小数据集确定一个最佳K值后,对之后的所有K值都能获得较好的效果。
1.2.2 初始聚类中心(质心)的选择
刚开始时是原始数据,杂乱无章,没有label,看起来都一样,都是绿色的。Kmeans需要人为地确定初始聚类中心,不同的初始聚类中心可能导致完全不同的聚类结果。在实际使用中我们往往不知道我们的待聚类样本中哪些是我们关注的label,人工事先指定质心基本上是不现实的,在大多数情况下我们采取随机产生聚类质心这种策略假设数据集可以分为两类,令K = 2,随机在坐标上选两个点,作为两个类的中心点(聚类质心)。
1.2.3. 确定了本轮迭代的质心后,将余下的样本点根据距离度量标准进行归类
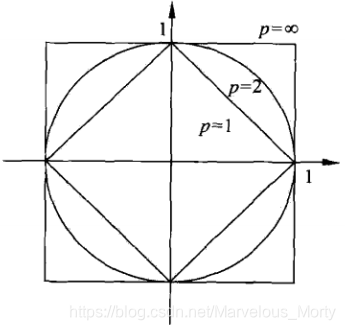
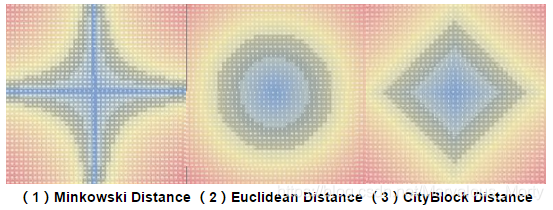
p = 1:Manhattan Distance距离(曼哈顿距离):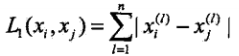
p = 2:Euclidean Distance距离(欧拉距离):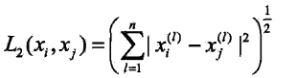
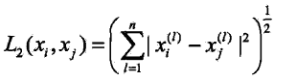
p = λ( 3 <= λ <= 正无穷 ) - Lp距离
p = 正无穷:距离等于各个坐标点的最大值
为了帮助理解,下图展示了二维空间中p取不同值时,与原点的Lp距离为1(Lp = 1)的点的图形
1.2.4. 算法收敛(终止/停机)条件是什么?
我们前面说过,计算K-means问题的目标函数最优解是一个NP问题,我们大多数时候都是针对聚类结果施加一些约束,得到一个终止/停止条件,例如一种比较常用的停止条件:
这样不断进行"划分—更新—划分—更新",直到每个簇的中心不在移动为止。
1.3 Kmeans算法步骤图示描述
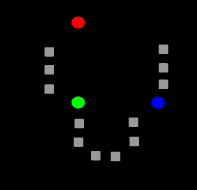
1.3.1 步骤一 - 选取质心
在输入数据集里面随机选择三个向量作为初始中心点(下图中的红绿蓝三个圆点),这里的K值为3, 也就是一开始从数据集里面选择了三个向量,这算作第一次迭代。
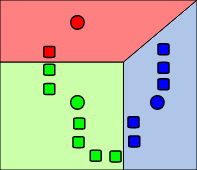
1.3.2 步骤二 - 距离聚类
将每个向量分配到离各自最近的中心点,从而将数据集分成了K个类。
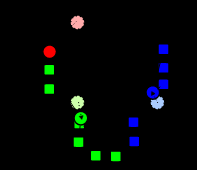
1.3.3 步骤三 - 重选新质心
计算得到上步得到聚类中每一聚类观测值的均值作为新的质心。这里体现的思想是这样的:因为我们是无监督学习,对于待分类的样本集群我们没有任何的先验知识,完全不知道该怎么分类,那么我们就暴力地、勇敢地、随机地踏出第一步,然后不断地去修正我们的分类器,不得不说,这和人生的很多的做人做事的道理是类似的。
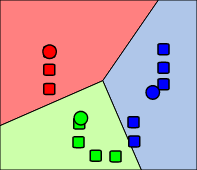
1.3.4.步骤四
重复步骤三,直至结果收敛,这里的收敛是指所有点到各自中心点的距离的和收敛
用sklearn python 对2维数据点进行kMeans聚类
# -*- coding: utf-8 -*-
from sklearn.cluster import KMeans
import numpy as np
if __name__ == '__main__':
X = np.array([
[1, 2], [1, 4], [1, 0],
[4, 2], [4, 4], [4, 0]
])
kmeans = KMeans(n_clusters=2, random_state=0).fit(X)
print kmeans.labels_
kmeans.predict([[0, 0], [4, 4]])
print kmeans.cluster_centers_

kMeans这种无监督聚类进行一次无监督聚类后,也可以得到一个分类器(classifier),它是对当前train set的一个特征空间划分,基于这个分类器可以用于之后对新样本点的分类预测,这种就是有监督聚类。
1.3.4 不同K值、不同的初始化中心点方式对Kmeans分类效果的影响
我们知道,K-mean的3大核心要素是:K值、距离度量公式、初始质心的选择。我们这个小节用一小代码来讨论下这些值是如何影响算法的分类效果
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from sklearn.cluster import KMeans
from sklearn import datasets
if __name__ == '__main__':
np.random.seed(5)
centers = [[1, 1], [-1, -1], [1, -1]]
iris = datasets.load_iris()
X = iris.data
y = iris.target
estimators = {'k_means_iris_3': KMeans(n_clusters=3),
'k_means_iris_8': KMeans(n_clusters=8),
'k_means_iris_bad_init': KMeans(n_clusters=3, n_init=1, init='random')}
fignum = 1
for name, est in estimators.items():
fig = plt.figure(fignum, figsize=(4, 3))
plt.clf()
ax = Axes3D(fig, rect=[0, 0, .95, 1], elev=48, azim=134)
plt.cla()
est.fit(X)
labels = est.labels_
ax.scatter(X[:, 3], X[:, 0], X[:, 2], c=labels.astype(np.float))
ax.w_xaxis.set_ticklabels([])
ax.w_yaxis.set_ticklabels([])
ax.w_zaxis.set_ticklabels([])
ax.set_xlabel('Petal width')
ax.set_ylabel('Sepal length')
ax.set_zlabel('Petal length')
fignum = fignum + 1
# Plot the ground truth
fig = plt.figure(fignum, figsize=(4, 3))
plt.clf()
ax = Axes3D(fig, rect=[0, 0, .95, 1], elev=48, azim=134)
plt.cla()
for name, label in [('Setosa', 0),
('Versicolour', 1),
('Virginica', 2)]:
ax.text3D(X[y == label, 3].mean(),
X[y == label, 0].mean() + 1.5,
X[y == label, 2].mean(), name,
horizontalalignment='center',
bbox=dict(alpha=.5, edgecolor='w', facecolor='w'))
# Reorder the labels to have colors matching the cluster results
y = np.choose(y, [1, 2, 0]).astype(np.float)
ax.scatter(X[:, 3], X[:, 0], X[:, 2], c=y)
ax.w_xaxis.set_ticklabels([])
ax.w_yaxis.set_ticklabels([])
ax.w_zaxis.set_ticklabels([])
ax.set_xlabel('Petal width')
ax.set_ylabel('Sepal length')
ax.set_zlabel('Petal length')
plt.show()
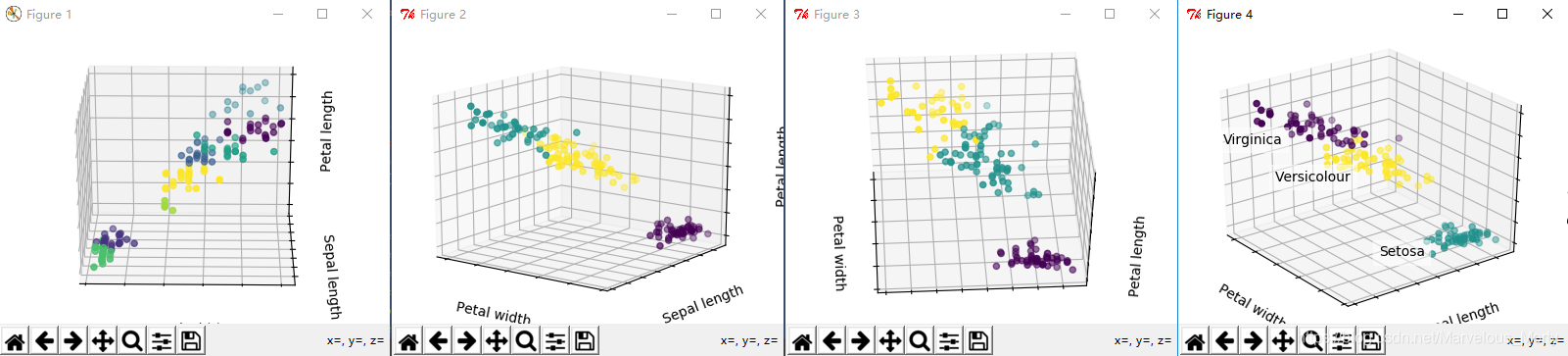
可以看到,Kmeans这种无监督学习的算法并不能保证聚类出来的"族群"是有"实际意义"的,即Kmeans得到的分类族群可能只是在欧式空间上相近的点集,但是实际上它们并不一定真的就属于同一个类别。另外一方面,Kmeans的分类结果和K值有强关联,如果我们传入了一个"不合理"的K值,有可能导致Kmeans的过拟合,最后得到一个"错误"的分类结果
在思考的深层次一些,这其实和Kleinberg对聚类算法的公理化定义有关,标准的聚类公理化定义是需要满足丰富性(Ri)原则的,但是这个条件太强了,所以k-means是一个满足k-丰富性原则的算法,k-丰富性原则是一个弱约束,不同的k值下,产生的分类结果也自然是不同的。
1.3.5 K-means在图像处理上的应用
这个例子要求做的是从96615真彩色"降维"到64种色彩,这里我个人理解聚类和降维的本质有共通的地方,聚类的目标是把相似的数据集归纳到同一个类别里,如果归纳完之后直接用这个新的类别代表该类别所有的样本集,那这个聚类就是一次降维过程。同样,回到这个例子,如果我们对一副真彩色的高维度像素的图像进行相似像素色聚类,本质上就是把原始图像降维成了一个低纬度低彩色图.
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import pairwise_distances_argmin
from sklearn.datasets import load_sample_image
from sklearn.utils import shuffle
from time import time
if __name__ == '__main__':
n_colors = 64
# Load the Summer Palace photo
china = load_sample_image("china.jpg")
# Convert to floats instead of the default 8 bits integer coding. Dividing by
# 255 is important so that plt.imshow behaves works well on float data (need to
# be in the range [0-1])
china = np.array(china, dtype=np.float64) / 255
# Load Image and transform to a 2D numpy array.
w, h, d = original_shape = tuple(china.shape)
assert d == 3
image_array = np.reshape(china, (w * h, d))
# 用1000张图像来训练出一个Kmeans分类器
print("Fitting model on a small sub-sample of the data")
t0 = time()
image_array_sample = shuffle(image_array, random_state=0)[:1000]
kmeans = KMeans(n_clusters=n_colors, random_state=0).fit(image_array_sample)
print("done in %0.3fs." % (time() - t0))
# 用训练好的Kmeans分类器对本例中的"夏宫"图像进行聚类处理,实际上就是在降维
# Get labels for all points
print("Predicting color indices on the full image (k-means)")
t0 = time()
labels = kmeans.predict(image_array)
print("done in %0.3fs." % (time() - t0))
codebook_random = shuffle(image_array, random_state=0)[:n_colors + 1]
print("Predicting color indices on the full image (random)")
t0 = time()
labels_random = pairwise_distances_argmin(codebook_random,
image_array,
axis=0)
print("done in %0.3fs." % (time() - t0))
def recreate_image(codebook, labels, w, h):
"""Recreate the (compressed) image from the code book & labels"""
d = codebook.shape[1]
image = np.zeros((w, h, d))
label_idx = 0
for i in range(w):
for j in range(h):
image[i][j] = codebook[labels[label_idx]]
label_idx += 1
return image
# Display all results, alongside original image
plt.figure(1)
plt.clf()
ax = plt.axes([0, 0, 1, 1])
plt.axis('off')
plt.title('Original image (96,615 colors)')
plt.imshow(china)
plt.figure(2)
plt.clf()
ax = plt.axes([0, 0, 1, 1])
plt.axis('off')
plt.title('Quantized image (64 colors, K-Means)')
plt.imshow(recreate_image(kmeans.cluster_centers_, labels, w, h))
plt.figure(3)
plt.clf()
ax = plt.axes([0, 0, 1, 1])
plt.axis('off')
plt.title('Quantized image (64 colors, Random)')
plt.imshow(recreate_image(codebook_random, labels_random, w, h))
plt.show()

把原始图像的96615像素点聚类为64像素点,中间的图像就是Kmeans聚类后的结果,可以看到,从肉眼视觉角度看,图像并没有明显地失真。
1.3.6 从混合模型和EM算法的角度来谈Kmeans聚类
实际上,混合模型和EM算法又是另一块非常庞大的主题,我们这里不深入讨论,只讨论kmeans更高层次的抽象概括,混合模型除了提供一个构建更复杂的概率分布的框架之外,混合模型也可以用于数据聚类。本质上来说,K均值算法对应于用于高斯混合模型的EM算法的一个特定的非概率极限.
用形式化方式描述Kmeasn
引入一组 D 维向量 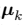 其中,
其中,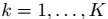 且
且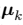 是与第 k 个聚类关联的一个代表。我们可以认为
是与第 k 个聚类关联的一个代表。我们可以认为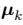 示了聚类的中心,我们的目标是找到所有数据点分别属于的聚类,以及一组向量
示了聚类的中心,我们的目标是找到所有数据点分别属于的聚类,以及一组向量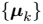 ,使得每个数据点和它最近的向量
,使得每个数据点和它最近的向量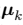 之间的距离的平方和最小。对于每个数据点
之间的距离的平方和最小。对于每个数据点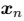 ,我们引入一组对应的二值指示变量,其中,表示数据点属于 K 个聚类中的哪一个(指示函数)
,我们引入一组对应的二值指示变量,其中,表示数据点属于 K 个聚类中的哪一个(指示函数)
有了以上定义,之后我们可以定义一个目标函数,也被称为失真度量(distortion measure)
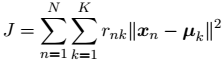 (公式9.1)
(公式9.1)
它表示每个数据点与它被分配的向量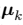 之间的距离的平方和。我们的目标是找到
之间的距离的平方和。我们的目标是找到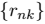 和
和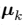 的值,使得 J 达到最小值。我们可以用一种迭代的方法完成这件事,其中每次迭代涉及到两个连续的步骤,分别对应:
的值,使得 J 达到最小值。我们可以用一种迭代的方法完成这件事,其中每次迭代涉及到两个连续的步骤,分别对应:
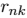 的最优化(E期望):首先,我们
的最优化(E期望):首先,我们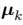 为选择一些初始值。然后在第一阶段,我们保持
为选择一些初始值。然后在第一阶段,我们保持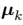 固定,关于
固定,关于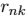 最小化 J
最小化 J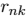 的最优化(M最大化):在第二阶段,我们保持
的最优化(M最大化):在第二阶段,我们保持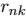 固定,关于最小化 J。不断重复这2个阶段优化直到收敛
固定,关于最小化 J。不断重复这2个阶段优化直到收敛
我们看到,在EM步骤中,每次都是固定其中一个变量,求另一个变量的极值,避免直接对二元变量直接求极值的计算困难问题。为了说明这一点,我们在K均值算法中使用 E步骤和 M步骤的说法
首先考虑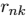 最优化,公式(9.1)给出的 J 是
最优化,公式(9.1)给出的 J 是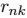 的一个线性函数,因此最优化过程可以很容易地进行,得到一个解析解。与不同的 n 相关的项是独立的,因此我们可以对每个 n 分别进行最优化,只要 k 的
的一个线性函数,因此最优化过程可以很容易地进行,得到一个解析解。与不同的 n 相关的项是独立的,因此我们可以对每个 n 分别进行最优化,只要 k 的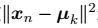 值使最小,我们就令
值使最小,我们就令 等于1。换句话说,我们可以简单地将数据点的聚类设置为最近的聚类中心,更形式化地,这可以表达为:
等于1。换句话说,我们可以简单地将数据点的聚类设置为最近的聚类中心,更形式化地,这可以表达为: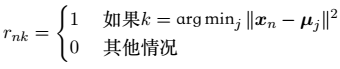
现在考虑固定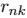 时,关于
时,关于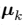 的最优化。目标函数 J 是
的最优化。目标函数 J 是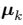 的一个二次函数,令它关于
的一个二次函数,令它关于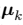 的导数等于零,即可达到最小值,即
的导数等于零,即可达到最小值,即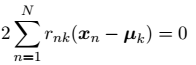
求导结果为: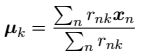 ,这个表达式的分母等于单个聚类 k 中数据点的数量,因此这个结果有一个非常简单直观的含义,即令
,这个表达式的分母等于单个聚类 k 中数据点的数量,因此这个结果有一个非常简单直观的含义,即令 等于单个类别 k 的所有数据点的均值
等于单个类别 k 的所有数据点的均值
上述两个步骤合起来称为K均值(K-means)算法
重新为数据点分配聚类的步骤以及重新计算聚类均值的步骤重复进行,直到聚类的分配不改变(或者直到迭代次数超过了某个最大值)。由于每个阶段都减小了目标函数 J 的值,因此算法的收敛性得到了保证,但是要注意的是,算法可能收敛到 J 的一个局部最小值而不是全局最小值
http://blog.itpub.net/12199764/viewspace-1479320/
https://blog.yueyu.io/p/1614
http://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html
http://scikit-learn.org/stable/auto_examples/cluster/plot_cluster_iris.html#sphx-glr-auto-examples-cluster-plot-cluster-iris-py
http://scikit-learn.org/stable/auto_examples/cluster/plot_color_quantization.html#sphx-glr-auto-examples-cluster-plot-color-quantization-py
http://scikit-learn.org/stable/auto_examples/cluster/plot_face_compress.html#sphx-glr-auto-examples-cluster-plot-face-compress-py
http://blog.csdn.net/gamer_gyt/article/details/51244850
http://scikit-learn.org/stable/auto_examples/cluster/plot_kmeans_assumptions.html#sphx-glr-auto-examples-cluster-plot-kmeans-assumptions-py
http://scikit-learn.org/stable/auto_examples/cluster/plot_kmeans_digits.html#sphx-glr-auto-examples-cluster-plot-kmeans-digits-py
http://chunqiu.blog.ustc.edu.cn/?p=435#comment-3556
http://f.dataguru.cn/thread-639729-1-1.html
http://www.cnblogs.com/bourneli/p/3645049.html
http://www.cnblogs.com/bourneli/p/3645049.html
https://en.wikipedia.org/wiki/Silhouette_(clustering)
https://kapilddatascience.wordpress.com/2015/11/10/using-silhouette-analysis-for-selecting-the-number-of-cluster-for-k-means-clustering/
http://scikit-learn.org/stable/auto_examples/cluster/plot_kmeans_silhouette_analysis.html#sphx-glr-auto-examples-cluster-plot-kmeans-silhouette-analysis-py
http://scikit-learn.org/stable/auto_examples/cluster/plot_kmeans_stability_low_dim_dense.html#sphx-glr-auto-examples-cluster-plot-kmeans-stability-low-dim-dense-py
http://scikit-learn.org/stable/modules/clustering.html#mini-batch-kmeans
http://scikit-learn.org/stable/auto_examples/cluster/plot_mini_batch_kmeans.html#sphx-glr-auto-examples-cluster-plot-mini-batch-kmeans-py
http://scikit-learn.org/stable/auto_examples/text/document_clustering.html#sphx-glr-auto-examples-text-document-clustering-py
http://coolshell.cn/articles/7779.htm
1.4 K-Means++算法
从爬山法问题中切入谈kmeans的缺陷以及kmeans++缓解了什么问题
假设我们的目标是到达山顶,我们采用的算法如下
- 从山上的某个随机位置出发开始
- Repeast
- 每次都都沿着“更高”的方向走一步
- Until直到某一步发现无论往任何方向走都不会更高
这个算法看起来十分合理,但是我们考虑下面这个图上运行上述算法
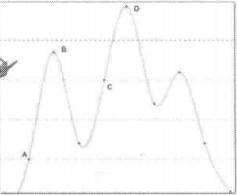
我们如何从A点出发,只会到达B点而不会到达最高顶点D点,即我们到达的是局部最优点而不是全局最优点。
k-means算法和上面的爬山法类似,不能保证最后能够找到最优的划分簇。这是因为算法一开始选择的是随机质心,基于随机质心,算法只能找到局部最优化分簇(例如图像的B点)
可以看到,对于kmeans这种EM过程来说,最终的聚类结果严重依赖于初始中心点的选择。
K-Means主要有两个最重大的缺陷 - 都和初始值有关 - K是事先给定的,这个K值的选定是非常难以估计的。很多时候,事先并不知道给定的数据集应该分成多少个类别才最合适
- K-Means算法需要用初始随机种子点来搞,这个随机种子点太重要,不同的随机种子点会有得到完全不同的结果
但是k-means++算法从一定程度上解决了该问题,k-means++选择初始seeds的基本思想就是:
初始的聚类中心之间的相互距离要尽可能的远
k-Means++算法步骤
1. 从输入的数据点集合中随机选择一个点作为第一个种子点(聚类中心)
2. 对于数据集中的每一个点x,计算它与最近聚类中心(指已选择的聚类中心)的距离D(x)并保存在一个数组里,然后把这些距离加起来得到Sum(D(x))
3. 选择一个新的数据点作为新的聚类中心,选择的原则是: D(x)较大的点被选取作为聚类中心的概率较大(kMeans不同类别的距离越远越好)
1) 先取一个能落在Sum(D(x))中的随机值Random
2) 然后用Random -= D(x),直到其结果 <= 0
3) 选取在这个"递减过程"中D(x)最大的点,此时的点就是下一个"种子点"
4. 重复2和3直到k个聚类中心被选出来
5. 利用这k个初始的聚类中心来运行标准的k-means算法
可以看到算法的第三步选取新中心的方法,这样就能保证距离D(x)较大的点,会被选出来作为聚类中心了。
同时k-measn这里并不直接用“hard方式”通过遍历每次选取D(x)最大的值作为下一个中心点,而是引入了随机过程,通过随机过程,柔和地体现了:
以正比于D(x)的概率(概率由距离决定)随机选择一个数据点作为新的中心点.
以一段python代码模拟该过程。假设由包含数据点及其权重的元祖构成列表。roulette函数会基于随机过程以正比于某个数据点的权重的概率来选择点。
#-*- coding:utf-8 -*-
import collections
import random
random.seed()
def roulette(datalist):
i = 0
soFar = datalist[0][1]
ball = random.random()
while soFar < ball:
i += 1
soFar += datalist[i][1]
return datalist[i][0]
if __name__ == "__main__":
data = [
("dp1", 0.25),
("dp2", 0.4),
("dp3", 0.1),
("dp4", 0.15),
("dp5", 0.1)
]
results = collections.defaultdict(int)
for i in range(1000):
results[roulette(data)] += 1
print results
我们可以看到,在1000次选择中,函数按照正比于权重的方式柔和地进行了点的选择,k-means++聚类的基本思想就是:虽然第一个中心点仍然随机选择,但其他的点则优先选择那些彼此相距很远的点。
2. 基于链接的聚类算法 - 基于分层的聚类(自底向上)
这种类型的聚类方法不需要指定最终聚成的簇的数目(例如K值)。取而代之的是,算法一开始将每个实例都看成一个簇,然后在算法的每次迭代中都将最相似的两个簇合并在一起,该过程不断重复直到只剩下一个簇为止。该方法称为层次聚类。算法最终终止于单个簇,该簇由两个子簇构成,而其中的每个子簇又由两个更小的子簇构成,如此递归循环下去。
基于链接的聚类算法可能是最简单直观的聚类形式。这类算法需要一系列循环,从一些琐碎的聚类开始,将每个数据点作为一个单点聚类,然后,这类算法不断循环将前一阶段中“最近”的两个聚类合并。因此,聚类数目随着循环过程逐渐减少,如果一直进行下去,这类算法会将所有定义域数据点归为一个大类
为了将该类算法定义清楚,需要确定两个参数:
我们需要决定怎样测量(或定义)类间距离;
我们需要确定什么时候终止合并。
链接聚类模型
对这类链接聚类(自下而上聚类)有两个非常关键的因素就是距离度量和终止条件,它们共同决定了链接聚类算法的算法模型
- 域子集间距离度量公式
1.1 单链接聚类(single-linkage clustering):类间距离定义为两类元素间的最短距离(取两两组合最短距离的那个)。在单链接聚类中,如果簇A到簇B的距离要比簇C到簇B的距离更近,则会将A和B先合并成一个新簇。
1.2 最大链接聚类:类间距定义为两类元素间的最大距离(取两两组合最长距离的那个)。
1.3 平均链接聚类(average-linkage clustering):类间距离定义为两类元素之间距离的平均值。 - 合并终止条件
基于链接的聚类算法是凝聚式的,一开始,数据完全是碎片化的,然后逐步构建越来越大的聚类,如果我们没有加入停止规则,链接算法的结果可以用聚类系统树图来描述,即,一个域子集构成的树,其叶子节点是单元素集,根节点为全域。例如下图所示:
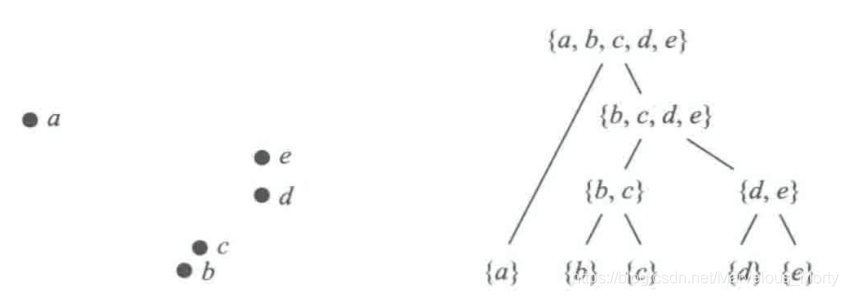
常用的停止准则包括:
1. 固定类的数量:固定参数 k,当聚类数目为 k 时停止聚类。
使用这种停止准则需要我们对我们的场景要有较强的领域知识,即预先知道需要聚类的数量
2. 设定距离上限:设定域子集间距最大上限,如果在某一轮迭代中,所有的组件距离都超过该阈值,则停止聚类
使用这种停止准则,实际上隐含了一种假设,即相似的样本在特征空间上距离很近,且聚集在一个较小的区域内,彼此之间距离较近。而不同类别的样本在族群上彼此会拉开距离。
所以通过设定一定的距离上限,可以在对一个族群聚集完毕后及时收敛停止,开启新族群的聚集
单链接/平均链接/最大链接聚类效果对比
# -*- coding:utf-8 -*-
from time import time
import numpy as np
from scipy import ndimage
from matplotlib import pyplot as plt
from sklearn import manifold, datasets
digits = datasets.load_digits(n_class=10)
X = digits.data
y = digits.target
n_samples, n_features = X.shape
np.random.seed(0)
def nudge_images(X, y):
# Having a larger dataset shows more clearly the behavior of the
# methods, but we multiply the size of the dataset only by 2, as the
# cost of the hierarchical clustering methods are strongly
# super-linear in n_samples
shift = lambda x: ndimage.shift(x.reshape((8, 8)),
.3 * np.random.normal(size=2),
mode='constant',
).ravel()
X = np.concatenate([X, np.apply_along_axis(shift, 1, X)])
Y = np.concatenate([y, y], axis=0)
return X, Y
X, y = nudge_images(X, y)
#----------------------------------------------------------------------
# Visualize the clustering
def plot_clustering(X_red, X, labels, title=None):
x_min, x_max = np.min(X_red, axis=0), np.max(X_red, axis=0)
X_red = (X_red - x_min) / (x_max - x_min)
plt.figure(figsize=(6, 4))
for i in range(X_red.shape[0]):
plt.text(X_red[i, 0], X_red[i, 1], str(y[i]),
color=plt.cm.spectral(labels[i] / 10.),
fontdict={'weight': 'bold', 'size': 9})
plt.xticks([])
plt.yticks([])
if title is not None:
plt.title(title, size=17)
plt.axis('off')
plt.tight_layout()
#----------------------------------------------------------------------
# 2D embedding of the digits dataset
print("Computing embedding")
X_red = manifold.SpectralEmbedding(n_components=2).fit_transform(X)
print("Done.")
from sklearn.cluster import AgglomerativeClustering
for linkage in ('ward', 'average', 'complete'):
clustering = AgglomerativeClustering(linkage=linkage, n_clusters=10)
t0 = time()
clustering.fit(X_red)
print("%s : %.2fs" % (linkage, time() - t0))
plot_clustering(X_red, X, clustering.labels_, "%s linkage" % linkage)
plt.show()
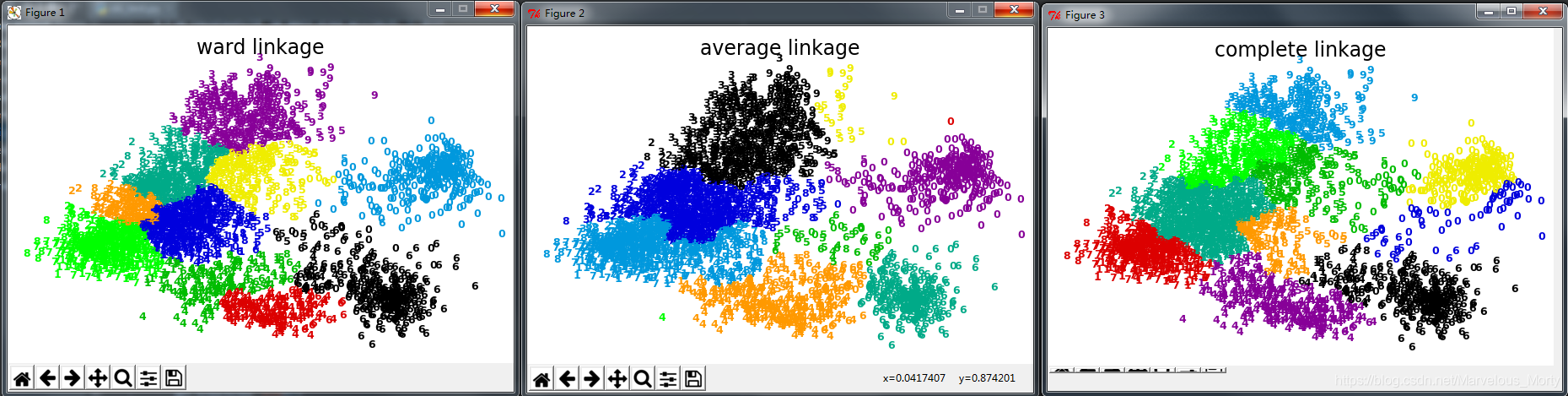
单纯就这个数字聚类的场景来看,平均链接聚类的效果最好。
链接算法模型
决定链接算法具体形式的最重要的因素就是“域间相似性度量函数”,因此可分为单链接、平均链接、最大链接 这3种。
- 单链接聚类算法
单链接算法和 Kruskal 算法很相似,目的是在加权图上找到一个最小生成树。
从图的视角来看单链接算法的算法运行过程,图的顶点是 X 中的元素,边(x,y)的权重是距离 d(x,y)。每次单链接算法将两个聚类进行合并,相当于在一颗树中添加一条边。
单链接算法得到的边集合和最小生成树是一致的。 - 平均链接聚类算法
- 最大链接聚类算法
- Relevant Link:
http://scikit-learn.org/stable/auto_examples/cluster/plot_digits_linkage.html#sphx-glr-auto-examples-cluster-plot-digits-linkage-py
http://scikit-learn.org/stable/modules/clustering.html#hierarchical-clustering
3.DBSCAN(Density-Based Spatial Clustering of Application with Noise) - 基于密度的聚类算法
基于密度的聚类方法与其他方法的一个根本区别是:它不是基于各种各样的距离度量的,而是基于密度的。因此它能克服基于距离的算法只能发现“类圆形”的聚类的缺点。DBSCAN的指导思想是:
用一个点的∈邻域内的邻居点数衡量该点所在空间的密度,只要一个区域中的点的密度大过某个阈值,就把它加到与之相近的聚类中去
它可以找出形状不规则(oddly-shaped)的cluster,且聚类时不需要事先知道cluster的个数
3.1 DBSCAN模型
考虑数据集合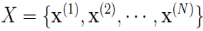 ,首先引入以下概念与数学记号:
,首先引入以下概念与数学记号:
1. ∈邻域(∈ neighborhood)
设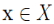 ,称
,称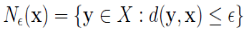 为 x 的∈邻域。显然,
为 x 的∈邻域。显然,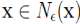 。
。
2. 密度(density)
设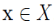 ,称
,称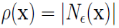 为 x 的密度。注意,这里的密度是一个整数值,且依赖于半径∈
为 x 的密度。注意,这里的密度是一个整数值,且依赖于半径∈
3. 核心点(core point)
设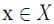 ,若(
,若( 核心点阈值 minimum numberof points required to form a cluster),则称 x 为 X 的核心点,即在半径Eps内含有超过MinPts数目的点。记由 X 中所有核心点构成的集合为
核心点阈值 minimum numberof points required to form a cluster),则称 x 为 X 的核心点,即在半径Eps内含有超过MinPts数目的点。记由 X 中所有核心点构成的集合为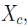 ,并记
,并记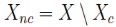 表示由 X 中的所有非核心点构成的集合。
表示由 X 中的所有非核心点构成的集合。
4. 边界点(border point)
若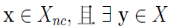 满足
满足 。即 x 的∈邻域中存在核心点,则称 x 为 X 的边界点。记由 X 中所有边界点构成的集合为
。即 x 的∈邻域中存在核心点,则称 x 为 X 的边界点。记由 X 中所有边界点构成的集合为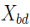 。
。
此外,边界点也可以这么定义,若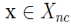 ,且 x 落在某个核心点的∈邻域内,则称 x 为 X 的一个边界点。一个边界点可能同时落入一个或多个核心点的∈邻域,即在半径Eps内点的数量小于MinPts,但是落在核心点的邻域内 。
,且 x 落在某个核心点的∈邻域内,则称 x 为 X 的一个边界点。一个边界点可能同时落入一个或多个核心点的∈邻域,即在半径Eps内点的数量小于MinPts,但是落在核心点的邻域内 。
5. 噪音点(noise point)
记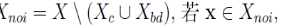 ,则称 x 为噪音点
,则称 x 为噪音点
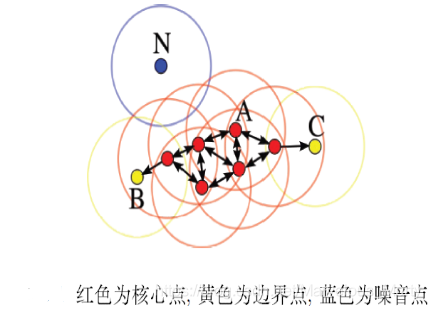
直观上来说,核心点对应稠密区域内部的点,边界点对应稠密区域边缘的点,而噪音点对应稀疏区域中的点。如下图所示:

需要注意的是,核心点位于簇的内部,它确定无误地属于某个特定的簇;噪音点是数据集中的干扰数据,它不属于任何一个簇;而边界点是一类特殊的点,它位于一个或几个簇的边缘地带,它可能属于一个簇,也可能属于另外一个簇,其簇归属并不明确。
6. 直接密度可达(directly density-reachable)
设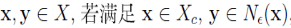 ,则称 y 是从 x 直接密度可达的。
,则称 y 是从 x 直接密度可达的。
7. 密度可达(density-reachable)
设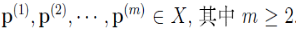 ,若它们满足
,若它们满足 直接密度可达的,
直接密度可达的,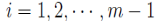 ,则称
,则称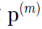 是从密度可达的
是从密度可达的
值得注意的是,当 m = 2时,密度可达即为直接密度可达。密度可达是直接密度可达的一种推广。事实上,密度可达是直接密度可达的传递闭包。
8. 密度相连(density-connected)
设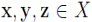 ,若 y 和 z 均是从 x 密度可达的,则称 y 和 z 是密度相连的。显然,密度相连具有对称性。
,若 y 和 z 均是从 x 密度可达的,则称 y 和 z 是密度相连的。显然,密度相连具有对称性。
9. 类(cluster)
称非空集合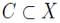 是 X 的一个类(cluster),如果它满足:对于
是 X 的一个类(cluster),如果它满足:对于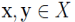
(1)Maximality:若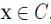 ,且 y 是从 x 密度可达的,则
,且 y 是从 x 密度可达的,则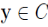
(2)Connectivity:若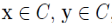 ,则 x,y 是密度相连的。
,则 x,y 是密度相连的。
3.2 DBSCAN算法过程
DBSCAN算法的核心思想如下:从某个选定的核心点出发,不断向密度可达的区域扩张,从而得到一个包含核心点和边界点的最大化区域,区域中任意亮点密度相连。
考虑数据集合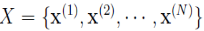 。DBSCAN算法的目标是将数据集合 X 分成 K 个cluster(k由算法自动推断得到,无需事先指定)及噪音点组成,为此,引入cluster标记数组:
。DBSCAN算法的目标是将数据集合 X 分成 K 个cluster(k由算法自动推断得到,无需事先指定)及噪音点组成,为此,引入cluster标记数组:
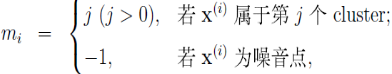
由此,DBSCAN算法的目标就是生成标记数组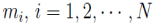 ,而 K 即为
,而 K 即为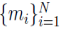 中互异的非负数的个数
中互异的非负数的个数
输入:样本集D=(x1,x2,…,xm)
,邻域参数
(ϵ,MinPts), 样本距离度量方式
输出: 簇划分C。

可以看到,DBSCAN在不断发现新的核心点的同时,还通过直接密度可达,发现核心点邻域内的核心点,并把这些邻域内的核心点都归纳到第 k 个聚类中。而噪音点没每轮 k 聚类中会被全局过滤不会参与下一轮启发式发现中,只有边界点在下一次跌打中会被再次尝试检验是否能够成为新聚类的核心点
# -*- coding:utf-8 -*-
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn import metrics
from sklearn.datasets.samples_generator import make_blobs
from sklearn.preprocessing import StandardScaler
# #############################################################################
# Generate sample data
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(n_samples=750, centers=centers, cluster_std=0.4,
random_state=0)
X = StandardScaler().fit_transform(X)
# #############################################################################
# Compute DBSCAN
db = DBSCAN(eps=0.3, min_samples=10).fit(X)
print db.labels_
core_samples_mask = np.zeros_like(db.labels_, dtype=bool)
print core_samples_mask
core_samples_mask[db.core_sample_indices_] = True
labels = db.labels_
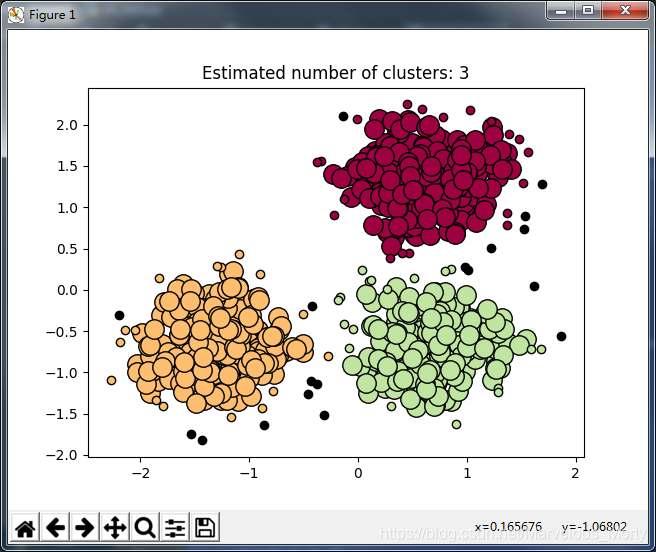
# Number of clusters in labels, ignoring noise if present.
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
print('Estimated number of clusters: %d' % n_clusters_)
print("Homogeneity: %0.3f" % metrics.homogeneity_score(labels_true, labels))
print("Completeness: %0.3f" % metrics.completeness_score(labels_true, labels))
print("V-measure: %0.3f" % metrics.v_measure_score(labels_true, labels))
print("Adjusted Rand Index: %0.3f"
% metrics.adjusted_rand_score(labels_true, labels))
print("Adjusted Mutual Information: %0.3f"
% metrics.adjusted_mutual_info_score(labels_true, labels))
print("Silhouette Coefficient: %0.3f"
% metrics.silhouette_score(X, labels))
# #############################################################################
# Plot result
import matplotlib.pyplot as plt
# Black removed and is used for noise instead.
unique_labels = set(labels)
colors = [plt.cm.Spectral(each)
for each in np.linspace(0, 1, len(unique_labels))]
for k, col in zip(unique_labels, colors):
if k == -1:
# Black used for noise.
col = [0, 0, 0, 1]
class_member_mask = (labels == k)
xy = X[class_member_mask & core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=14)
xy = X[class_member_mask & ~core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=6)
plt.title('Estimated number of clusters: %d' % n_clusters_)
plt.show()
http://shiyanjun.cn/archives/1288.html
https://en.wikipedia.org/wiki/DBSCAN
https://www.cnblogs.com/hdu-2010/p/4621258.html
http://blog.csdn.net/itplus/article/details/10088625
https://www.cnblogs.com/pinard/p/6208966.html
http://blog.csdn.net/xieruopeng/article/details/53675906
http://www.cnblogs.com/aijianiula/p/4339960.html
http://scikit-learn.org/stable/modules/generated/sklearn.cluster.DBSCAN.html
4. Clustering by fast search and find of density peaks(CFSFDP聚类)- 基于密度(Density)的聚类
该算法是Alex Rodriguez和Alessandro Laio在Science上发表的《Clustering by fast search and find of density peaks》所提出的一种新型的基于密度的聚类算法。
算法思想
该聚类算法的核心思想在于对聚类中心(cluster centers)的刻画上,算法认为聚类中心同时具有以下两个特点:
- 聚类中心本身密度大,即它被密度均不超过它的邻居包围,或者说聚类中心是整个簇中密度最大的点;
- 聚类中心与其他密度更大的数据点之间的“距离”相对更大;
算法模型
该算法的假设类簇(cluster centers)的中心由一些局部密度比较低的点围绕,并且这些点距离其他有高局部密度的点的距离都比较大。
对于样本集中的任何数据点s,可以定义两个值:局部密度ρi以及到高局部密度点的距离δi,这两个值仅仅取决于两点之间的距离dij。
3. 局部密度ρi
包括 Cut-off kernel 和 Gaussian kernel 两种计算方式:
1)Cut-off kernel:阶跃统计函数,只关注数据点是否在dc阈值范围内
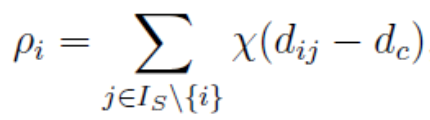 ,其中函数,
,其中函数,
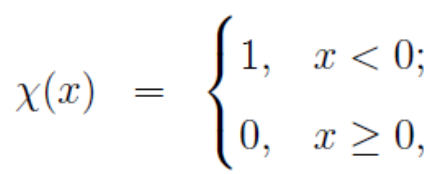
参数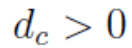 称为截断距离(cutoff distance),需要在算法启动时显式指定。
称为截断距离(cutoff distance),需要在算法启动时显式指定。
从该模型公式中可以看出,局部密度 ρi 表示的是样本集 S 中与数据点 xi 之间的的距离小于 dc 的数据点。
这里 dc 可以理解为一个边界阈值,dc 设置的越小,表示希望算法对聚类的敏感度越高,即在尽可能小的区域内发现聚类社区。
2)Gaussian kerne:柔性距离统计函数
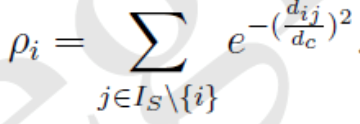
和 cut-off kernel一样,与 x 的距离小于 dc 的数据点越多,pi 的值越大。
对比上面两式可以看出,cut-off kernel为离散值,Gaussian kernel为连续值,因此,相对来说,Gaussian产生冲突(即不同的数据点具有相同的局部密度值)的概率更小。
-
到高局部密度点的距离δi
设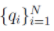 表示数据点局部密度
表示数据点局部密度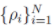 的一个降序排列下标序,即它满足:
的一个降序排列下标序,即它满足: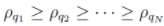 。
。
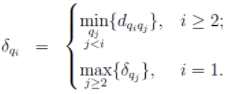
则可以定义:
这个公式非常优美,它定义了:
1)当 Xi 具有最大局部密度时,δi 表示 S 中与 Xi 距离最大的数据点与 Xi 之间的距离;
2)否则,δi 表示在所有局部密度大于 Xi 的数据点中(即其他cluster centers),与 Xi 距离最小的那个(或那些)数据点与 Xi 之间的距离。 -
聚类过程
至此,对于 S 中的每一个数据点 Xi,可以通过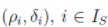 进行抽象表征。考虑下图的例子,其中包含28个二维数据点,将二元对在
进行抽象表征。考虑下图的例子,其中包含28个二维数据点,将二元对在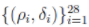 平面上画出来。
平面上画出来。
我们看到,1号和10号数据点由于同时具有较大的局部密度和类间距离,于是从数据集中“脱颖而出(pop up)”了,而这两个数据点恰好是左图中数据集的两个聚类中心。
此外,26,27,28这三个数据点在原始数据集中是“离群点”,它们在右图中也很有特点:其局部密度很小,类间距离很大。
从直观上来理解,上面右图对确定聚类中心(cluster centers)有决定性作用,因此也将这种由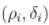 对应的图称为决策图(decision graph)。
对应的图称为决策图(decision graph)。
聚类中心确定之后,剩余点被分配给与其具有较高密度的最近邻居相同的类簇。与其他迭代优化的聚类算法不同,类簇分配在单个步骤中执行。
在聚类分析中, 通常需要确定每个点划分给某个类簇的可靠性。
在该算法中, 可以首先为每个类簇定义一个边界区域(border region), 亦即划分给该类簇但是距离其他类簇的点的距离小于dc的点,这个区域中的点集可以认为是圈出了聚类中心的整体。然后为每个类簇找到其边界区域的局部密度最大的点,该类簇中所有局部密度大于该点的局部密度的点被认为是类簇核心的一部分(亦即将该点划分给该类簇的可靠性很大),其余的点被认为是该类簇的光晕, 亦即可以认为是噪音(outlier)。
图A表示点分布,其中包含非球形点集和双峰点集。B和C分别表示4000和1000个点按照A中模式的分布,其中点根据其被分配的不同类簇着色,黑色的点属于类簇光晕。D和E是对应的决策图,而F表示的是不同点量下不正确聚类点的比率,误差线代表平均值的标准差。
下图是分别利用点集和Olivetti脸部图片集的聚类结果

-
算法形式化描述
设待聚类数据集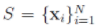 ,其包含个
,其包含个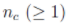 cluster。
cluster。

值得注意的是,该聚类算法得到的聚类中心可以作为其他聚类算法(例如k-means)的初始聚类中心。
Relevant Link:
http://science.sciencemag.org/content/344/6191/1492
https://segmentfault.com/a/1190000011337432
https://blog.csdn.net/itplus/article/details/38926837
5. SOM(Self-organizing Maps) - 基于模型的聚类(model-based methods)
基于模型的方法给每个聚类假定一个模型(预先设定),然后寻找能够很好地满足这个模型的数据集。这样一个模型可能是数据点在空间中的密度分布函数或者其他。它的一个潜在的假定就是:
目标数据集是由一系列的概率分布所决定的
通常有两种尝试方向:统计方案;和神经网络方案。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









