






 文章介绍了处理多幅影像镶嵌后色差的步骤,包括辐射定标、大气校正等预处理,使用ENVI的SeamlessMosaic功能,并通过HistogramMatching和调整接边线优化镶嵌效果,最终实现影像的无缝融合。
文章介绍了处理多幅影像镶嵌后色差的步骤,包括辐射定标、大气校正等预处理,使用ENVI的SeamlessMosaic功能,并通过HistogramMatching和调整接边线优化镶嵌效果,最终实现影像的无缝融合。
影像拍摄角度、波段等多种原因易造成色差,后续若进行反演则无法手动匀色以减小色差。
ENVI提供Seamless Mosaic以实现多景影像无缝镶嵌,但多数情况仍会存在色差。
以下提供三步,可以依次组合或分别使用,从而改善多幅影像镶嵌后所存在的色差问题。
影像以GF-2为例,4景覆盖研究区。
1.所有影像按照 “辐射定标-大气校正-正射校正-PAN与MSI融合-去除背景值-subset至研究区范围”进行预处理
2.Seamless Mosaic加载四景影像 查看色差问题
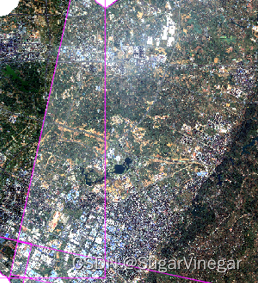
一般情况下,同一角度的影像直接进行mosaic就能得到较好的镶嵌效果。但如图,左右两边的影像存在明显色差。
3. 因为同一角度的影像,色差问题不大,所以先加载同一角度两景影像,以及另一角度一景影像进行镶嵌。完成后再次加入最后第四景影像进行镶嵌。【主要思想即少量多次】
其中:在main主面板中不断调整reference和adjust影像,并不断修改影像顺序[Order],以达到最优效果。在右上角[Show Preview]查看实时效果。
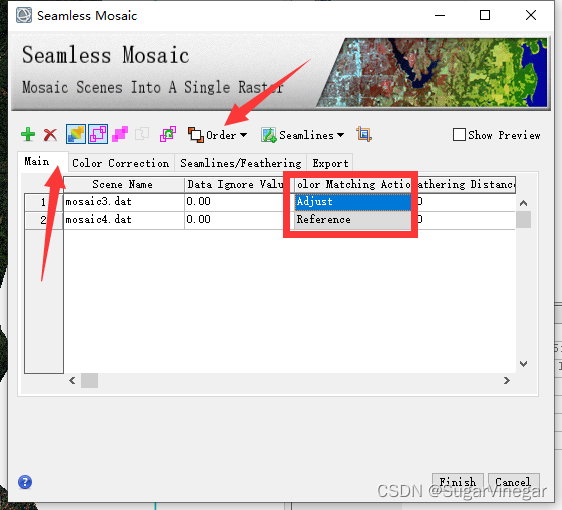
其次:勾选Histogram Matching,多次试验后,发现色差大的影像用Overlap Area Only可以有效减小色差。[并非绝对 根据自己影像决定]
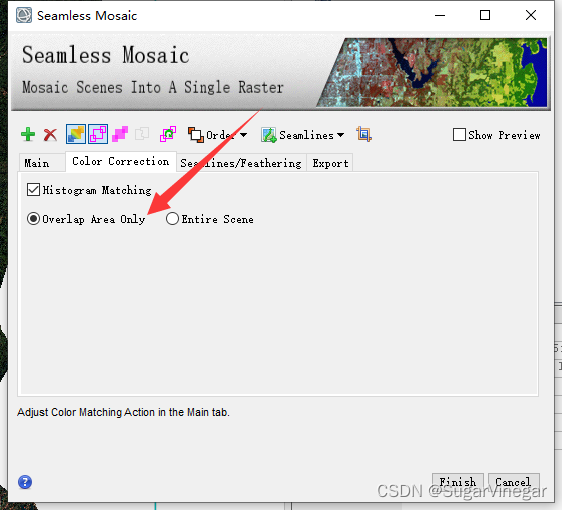
再次:自动生成线,选择羽化方式。这里选择不同羽化方式后可以看图像上拼接处是否存在黑边,如果有就更换方式或者更换图像重叠顺序。
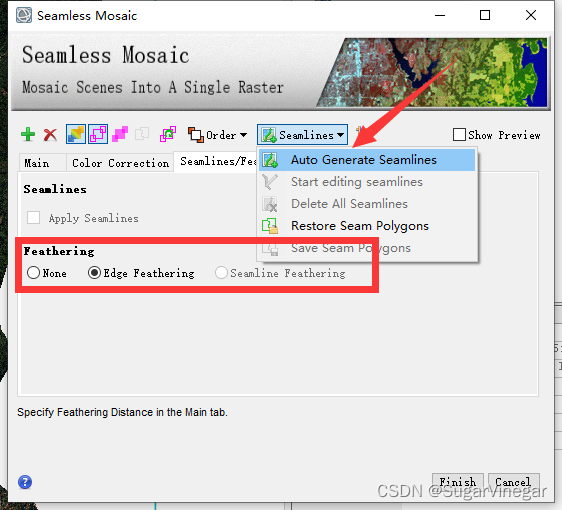
然后:人工修改自动生成的【绿色】接边线,沿着地物边界画。

选择导出路径-三次卷积-export。
结果展示:
前:

后:
最后,仅为个人经验及记录,叙述中不专业或者错误的地方,意会即可。

















 1992
1992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









