








推荐系统导读三部曲之筑基篇
本笔记资料源自课程 Building Recommender Systems with Machine Learning and AI - Frank Kane
推荐系统的目的
推荐系统的目的是为了准确分析出用户的喜好,推荐TOP-N商品,做出精准营销,我们的目的是为了帮助用户找出用户喜欢的是什么,从而提升转化率,增强用户粘性
推荐系统的信息来源
获取用户喜好的信息来源一般分为显式信息来源与隐式信息来源两种。
显示信息来源(explict rating)一般主要为用户对某项内容进行打分,通过打分来体现用户兴趣,在这方面本文不加赘述。
隐式信息来源(implicit rating)主要有三种信息渠道:
鼠标单击信息
人们单击一些广告或者单击某项商品的信息在一定程度上显示了用户对这项内容感兴趣。同时,由于单击事件发生的数量很大,我们不太需要担心发生所获取数据稀疏性,但是,由于单击事件的可靠性相对较低,人们单击物品可能存在误触,或者是一些其它不可描述的原因(比如标题党小编或者擦边球广告)。同时,一些机器人也可以通过重复进行请求访问来刷浏览次数。在这些情况下,单击事件可能会产生很多的噪声,从而对之后的系统性能产生负面影响。
用户购买信息
与单击事件相比,用户购买信息相对而言要稳定的多,投入宝贵的金钱能够明显说明用户对某样物品具有喜好,一般而言,各个电商平台把该指标作为进行推荐的主要信息来源。
用户浏览信息
另外一种信息来源就是你在某个页面停留的时间长短,由于用户在这个地方投入了大量的时间,很大程度能够说明用户对此事物具有明显兴趣,开发者可以选取某几个特定值作为阈值来界定兴趣程度,一旦超过某几个阈值就界定为用户对某项产品产生了兴趣。
推荐系统性能评测
构建方法要分为两种:训练测试集(在推荐系统中一般采取八二开或者九一开),或者N-fold交叉验证(把数据分为N个Fold,对1 ~ N-1个fold分别训练并取平均值,用第N个fold进行测试)。
训练测试集方法相对而言节省资源,但容易导致过拟合,而N-Fold交叉验证的方法特别消耗资源,但是不易过拟合。
准确率评估方法:
常规计算方法有两周,所得值越小,代表性能越好
MAE (Mean Absoulte Error)
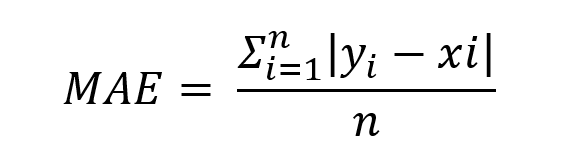
RMSE(Root Mean Square Error)

历史小插曲
NETFLIX在2006年召开了一场大赛,第一个能够将NETFLIX自身的RMSE得分降低10%的参赛者将获得获得一百万美刀。BellKor在2009年获得了该项奖励,然而NETFLIX最终却停止科研并采用他们实现的推荐系统,原因在于NETFLIX发现RMSE分数在实际中并不起到举足轻重的作用,真正起作用的是用户是否真的喜欢所推荐条目。
HIT RATE
由此,Hit Rate应运而生,我们假设每次把TOP-N的栏目推荐给某个用户,倘若用户对着个栏目列表中的一个或者多个栏目进行了评分(显式隐式皆可),我们视作为产生了一次Hit。Hit Rate的公式很简单,等价于总Hit次数/用户的总数。然而有一个弊端在,不可避免的,TOP-N栏目中很容易会涵盖到训练集的数据,用户必然会喜欢它从而评分,这在一定程度上是作弊,因此,我们要考虑另一种办法,LEAVE ONE OUT CROSS VALIDATION。
RATING HIT RATE
这个方法是用来把每一个Rating的Hit Rate用来排序,它的意义在于通过把整个Hit Rate分开来展现,可以让你更直观的看出你的推荐系统的性能如何。
LEAVE ONE OUT CROSS VALIDATION
这种方法是将在训练集中出现过的栏目不列入统计范畴,只有用户对测试集的数据进行了评价,才列为发生了一次Hit,然而这种方法依然存在某些弊端,倘若数据量不够大,可能TOP-N栏目大多都是训练集的数据,从而导致效果不佳。
AVERAGE RECIPROCAL HIT RATE
这种方式面向用户的喜好,通过为TOP-N栏目中的项目赋权,即对低rank施以惩罚来判断该推荐系统的合理性,这个公式中,rank i 是指所排次序,排行第五个,rank i就是5。U是指总用户的个数。举个栗子,加入一共有三个用户,这三个用户分别选择了各自TOP-N栏目中的第二个,第一个,第六个,那么AHRR的值就是1/2 + 1/1 + 1/6 = 1.67。
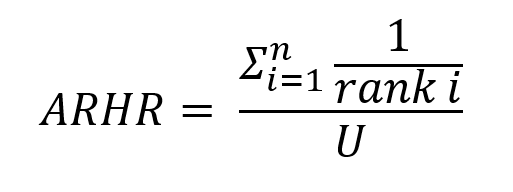
CUMULATIVE HIT RATE
假设我们的推荐系统模式为五星推荐系统,我们预先设定一个阈值,如果预测用户评级小于等于三星,那么我们不把这样的值计入Hit Rate。
COVERAGE
推荐系统的覆盖率对于评估它的初始性能也具有很重要的意义。覆盖率是指需要被预测的<User, Item> 键值对占据所有键值对的比例。某种程度来说,覆盖率与准确率具有强相关性,找到一个合适的Coverage Rate对提升推荐系统的性能具有显著的意义。
DIVERSITY
多样性代表了你的推荐系统推荐给用户项目的跨度,举个例子,当用户看完了哈利波特-魔法石,低多样性的推荐系统仅会推荐了下一系列的哈利波特-密室,而高多样性的系统还会推荐霍比特人。每个推荐系统运行的时候一般都会计算各个不同项之间的similarity score, 我们可以通过TOP-N里面的这些值来量化多样性。多样性的值讲究一个恰当,过高过低都是不可取的。
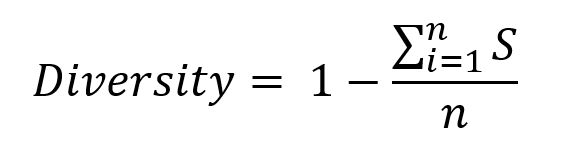
NOVELTY & LONG TAIL
新颖性代表的你推荐的TOP-N项目中高热度指数的平均值,人们倾向于看到所推荐项目是那些流行的,有一定知名度的,而不是鲜有耳闻的项目。否则人们会认为你的推荐系统并不理解他们。因此,我们需要在高知名项目与新项目之间做好平衡以满足用户期望。每个系统的项目一般而言都满足长尾效应,我们要做的是在做推荐的时候尽量推广一定数量的尾部项目以提升新作品/新产品的曝光度。Make a balance between novelty and trust!
CHURN
扰动值表示了你的推荐系统受到新评价的影响,一旦一个用户对一个新项目进行了评价,你对其的评价体系是否产生了显著的变化。如果用户发现你的推荐项目经常就是那几个,那么他可能会产生一定的厌倦。因此,一个有效的办法是对TOP-N显示的栏目进行随机排序以提升用户新鲜感。另外Churn也讲究一个平衡。
RESPONSIVENESS
这个指标代表了你的推荐系统的反应速度,一旦客户发生了新的用户行为,你的推荐系统是立刻更新了评价模型,还是在一定时间后完成了模型的更新。在实际的商业社会中,要达到及时性的推荐系统需要耗费巨量的资本进行系统构建和维护,因此,前期做好响应速度与简洁化的平衡预期很重要。
AB TEST
基于上文所述,我们有了大量的测评推荐系统性能的指标,那么如何选取呢?这个需要基于企业文化或者说产品特性来决定,比较常用的方法是采用AB测试。我们可以对用不同算法的推荐系统在不同的客户群体上进行测试。比较有趣的事情是,推荐系统线下的高性能并不完全代表线上的高性能,只有实际的用户行为可以代表最终的测试效果。YOUTUBE在进行测试的时候就发现了这种问题,称其为Surrogate Problem,并发表了一篇paper,其中表示" There is more art than science in selecting surrogate problem for recommendation." 这意味着我们并不能简简单单的使用准确率作为衡量推荐系统好坏的指标,只有实际的A/B测试出来的结论才是真正的衡量标准。
推荐系统评测指标的实现
我们采用Python 中的Surprise包来进行推荐系统的开发,Suprise是一个基于scikit-learn的一项集成化开发包。在这个包中,它已经完成了MAE与RMSE两种方法啊的具体实现我们直接引用即可。
安装指令 pip install surprise,安装前要先注意确保
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1027
1027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









