







在coursera上python课程,刚好看到以前也学过的python网络程序这一部分。
上一篇文章是利用python的socket包来实现TCP/IP网络程序,本篇我们可以采用一个更成熟的包:urllib。
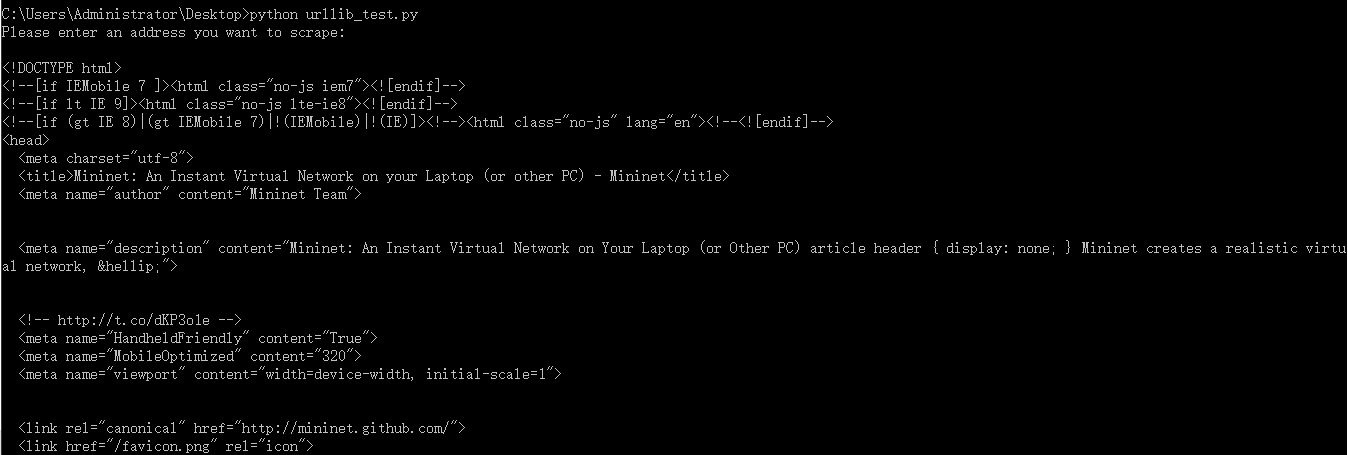
抓取网页并打印原始html格式内容的代码如下(默认抓取某英文网址网页内容):
# !/user/bin/python2.7
# -*- coding : utf-8 -*-
author = 'Meditator_hkx'
import urllib
import re
url = raw_input("Please enter an address you want to scrape:")
if len(url) < 1:url = 'http://mininet.org/'
data = urllib.urlopen(url).read()
print data
如果我们对网页中的某些特定元素比如链接网址感兴趣,可以使用正则表达式来筛选出特定内容,代码如下所示:
# !/user/bin/python2.7
# -*- coding : utf-8 -*-
author = 'Meditator_hkx'
import urllib
import re
url = raw_input("Please enter an address you want to scrape:")
if len(url) < 1:url = 'http://mininet.org/'
data = urllib.urlopen(url).read()
links = re.findall('"(http:.+?)"',data)
for link in links:
print link

然而,在抓取中文网页时还会面临乱码问题,下一篇我们会尝试用BeautifulSoup来解决!















 434
434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









