







 本文介绍了K-近邻(KNN)算法的基本原理,通过实例展示了如何利用KNN进行分类预测。KNN算法简单有效,但存在计算量大、类别评分非规范化等缺点。同时,文章提供了KNN算法的Python实现代码,帮助读者更好地理解和应用KNN。
本文介绍了K-近邻(KNN)算法的基本原理,通过实例展示了如何利用KNN进行分类预测。KNN算法简单有效,但存在计算量大、类别评分非规范化等缺点。同时,文章提供了KNN算法的Python实现代码,帮助读者更好地理解和应用KNN。
最近在学习机器学习,查阅了很多人的博客,受益颇多,因此自己也试着将过学的内容做一个总结,一方面可以提高自己对学习过的算法的认识,再者也希望能帮助到初学者,共勉。。。
1. K-近邻算法原理
K最近邻(kNN,k-NearestNeighbor)分类算法,见名思意:找到最近的k个邻居(样本),在前k个样本中选择频率最高的类别作为预测类别,什么?怎么那么拗口,没图说个JB,下面举个例子,图解一下大家就会显而易见了,如下图:
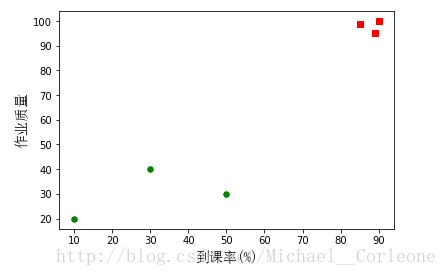
我们的目的是要预测某个学生在数学课上的成绩。。。
先来说明几个基本概念:图中每个点代表一个样本(在这里是指一个学生),横纵坐标代表了特征(到课率,作业质量),不同的形状代表了类别(即:红色代表A(优秀),绿色代表D(不及格))。我们现在看(10,20)这个点,它就代表着:在数学课上,某个学生到课率是10%,交作业质量是20分,最终导致了他期末考试得了D等级(不佳)。同理,这6个点也就代表了6个往届学生的平时状态和最终成绩,称之为训练样本。。。。
现在要来实现我们的预测目的了,想象一下现在一学期快过完了,张三同学马上要考试了,他想知道自己能考的怎么样,他在数学老师那里查到了自己的到课率85%,作业质量是90,那么怎么实现预测呢?张三可以看做是(85,90)这个点–也被称之为测试样本,首先,我们计算张三到其他6位同学(训练样本)的距离,点到点的距离相信我们初中就学了吧(一般用的欧氏距离)。再选取前K个最近的距离,例如我们选择k
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









